Der Einzelhandel hat einen sehr unterschiedlichen Kundenkreis. Es gibt viele von ihnen - verschiedene Berufe und Einkommensniveaus, von jungen Menschen bis zu Senioren. Eine solche Vielfalt kann nicht durch zwei oder drei Geschäftsregeln korrekt beschrieben werden, da Sie einfach nicht alle Kriterienkombinationen abdecken können und unweigerlich einige Kunden verlieren. Für den Einzelhandel ist es daher sehr wichtig, Ihr Publikum so genau wie möglich zu segmentieren, was die Modelle jedoch unweigerlich kompliziert. Hier helfen maschinelle Lerntechnologien, die Unternehmen genauere Prognosen und Antworten auf wichtige Fragen geben.
Welche Fragen meinst du? Zum Beispiel: Wird der Kunde gehen? Oft verlassen Kunden das Geschäft, wenn das Geschäft nicht das richtige Produkt hat. Zum Beispiel kauft eine Frau jeden Monat eine spezielle Creme für 10 Tausend Rubel und kann aus zwei Kosmetikgeschäften wählen. In einem von ihnen fehlt häufig das gewünschte Produkt, und in dem zweiten gibt es keine Probleme mit der Verfügbarkeit. Höchstwahrscheinlich wird sie ständig in der zweiten kaufen, wenn auch etwas teurer.
Eine weitere dringende Frage: Wie kann die Arbeit der Mitarbeiter optimiert werden? Beispielsweise müssen Sie Arbeitsschichten für Kassierer und Verkaufsberater planen. Eine Möglichkeit besteht in der Verwendung statistischer Analysen. Der Analyst bewertet die Aktivität der Kunden je nach Wochentag und stellt fest, dass sie am Samstag am meisten und am Freitag und Sonntag etwas weniger kaufen. Diese Hypothese wird durch statistische Tests überprüft und die Schlussfolgerungen an das Management weitergegeben.
Eine solche Analyse berücksichtigt jedoch möglicherweise nicht viele Kombinationen von Faktoren. Wenn zum Beispiel der 7. März am Mittwoch ist - kaufen sie an diesem Tag mehr als am Freitag (schließlich ist Freitag zu normalen Zeiten ein beliebterer Tag als an anderen Wochentagen)? Und Abschluss? Oder lokale Feiertage? Je mehr Faktoren, desto schwieriger ist es, sie alle mit Hilfe einfacher Regeln zu berücksichtigen. Und anstatt die Regeln unendlich zu komplizieren, können Sie ein Modell erstellen, das die Nachfrage für einen bestimmten Tag vorhersagt.
Unser Projekt im Non-Food-Einzelhandel
In diesem Fall war es notwendig, den Kundenstamm (ca. 2,5 Millionen Menschen) zu analysieren und vorherzusagen, welche von ihnen in den nächsten zwei Wochen in den Laden zurückkehren würden. Wir haben zwei Methoden der CatBoost-Bibliothek verwendet - CatBoostClassifier und CatBoostRegressor - die erste - um die Zusammensetzung des Publikums vorherzusagen, die zweite - um die beliebtesten Produkte in den nächsten 2 Wochen auszuwählen. CatBoost
kam zu Beginn unseres Projekts heraus, es war ein neuer Ansatz für die Arbeit mit kategorialen Attributen. Und da die Produktpalette unserer Kunden viele kategoriale Merkmale enthält, haben wir das neue Produkt gerne ausprobiert. Nach Auswahl der Parameter erfüllte das Modell sofort unsere Erwartungen mit genauen Prognosen. Kein Wunder, dass CatBoost heute eines der beliebtesten Modelle zur Erhöhung des Gradienten ist.
Für das Modell haben wir Statistiken für 2017 erstellt:
- Schecks: Wem gehört die Bonuskarte aus dem Scheck, wann der Kauf getätigt wurde, was sie gekauft haben, Rabattgröße, Kauf oder Rückerstattung.
- Demografie: Region und Wohnort des Kunden, Geburtsdatum und Geschlecht, Zustimmung zum Versand per Telefon oder Post.
- Produkte: Welche Kategorie oder welches Segment umfasst Einkäufe, Umfang usw.
Wir haben die Lärmdaten (Verkäuferkarten, Rücksendungen, Einkäufe von Dienstleistungen, keine Waren) bereinigt und die erforderlichen Kriterien (Prozentsatz des Rabatts, Alter) berechnet. Danach berechneten wir die größte und kleinste Quittung für jeden Kunden, den durchschnittlichen, mittleren und maximalen Rabatt, wie oft eine Person hereinkam und wie viele Produkte aus welchen Kategorien sie kaufte. Diese Parameter wurden in Intervallen gezählt: letzte Woche, zwei Wochen, ein Monat, drei Monate. Diese sorgfältige Arbeit ermöglichte es, Modelle mit hoher Prognosegenauigkeit zu erstellen.
Aggregierte Daten für Modelle und gestartete Berechnungen. Das erste Modell sagte voraus, welcher der Käufer in den nächsten zwei Wochen kommen würde, und das zweite gab Empfehlungen ab: Welche Produkte (bis zum Niveau des Artikels) würde eine bestimmte Person kaufen. Übrigens hat das Erfordernis, die Popularität bestimmter Artikel vorherzusagen, die Aufgabe erheblich erschwert (in der Regel erfordert das Unternehmen Prognosen, die eher auf Kategorien und Namen von Waren als auf Positionen basieren).
Kunden, die vom Modell für gezieltes Mailing empfohlen wurden, hatten einen größeren Median-Check für einen Besuch und kauften für den analysierten Zeitraum einen höheren Gesamtbetrag als andere Kunden.
Infolgedessen kauften etwa 30% der Kunden nach dem Versand mindestens eines der drei vom Modell vorhergesagten Produkte.
Jetzt kann das Unternehmen den Umsatz genauer vorhersagen: Der Einzelhändler weiß, wer in naher Zukunft zu ihm kommt und was er kauft. Dies hilft nicht nur, die Logistik zu optimieren, sondern auch die damit verbundenen Kosten zu senken. Wenn beispielsweise ein bestimmter Kunde im Winter normalerweise nichts kauft, müssen Sie ihm im Januar keine SMS senden. Modelle optimieren auch Mailings: Ein Spezialist, der auf einer Prognose basiert, versteht sofort, wer eine E-Mail senden soll und an wen - eine dringende SMS.
Fallstricke
Sie sind in jeder ML-Aufgabe - sie waren in unserer. Zum Beispiel haben wir getestet, ob Mailings mit Produktempfehlungen zur Umsatzsteigerung beitragen. Hierzu wurde das prognostizierte Kundensegment in drei Gruppen eingeteilt:
- Kontrolle - hat den Newsletter nicht erhalten.
- Gruppe mit Erinnerungen - erhielt einen gemeinsamen Text aus dem Geschäft.
- Gruppe mit Empfehlungen - SMS mit drei spezifischen Produkten erhalten, die vom Modell vorhergesagt wurden.
Es stellte sich heraus, dass Personen, die Empfehlungen erhielten, weniger kauften als Kunden, die keinen Newsletter erhielten. Die durchschnittliche Rechnung und die Menge der gekauften Waren waren geringer. Der T-Test zeigte, dass die Unterschiede statistisch signifikant waren (p-Wert = 0,017).
Um es milde auszudrücken, solche Ergebnisse entmutigten alle. Sie begannen nach dem Grund zu suchen und stellten fest, dass die Geschäfte Nachrichten an Kunden in einem bestimmten Messenger sendeten und die Benutzer in unserem Segment zunächst weniger kauften als andere Kunden. Selbst die Vermarkter des Kunden wussten nichts davon. Das Experiment stellte sich also als falsch heraus, aber gemäß den Ergebnissen haben wir dem Modell den Parameter „Messenger-Benutzer“ hinzugefügt. Dieser Fall zeigt, wie die Kanäle für die Kommunikation mit Kunden sorgfältig ausgewählt werden.
Welche anderen Schlussfolgerungen können gezogen werden?
- Es gibt nicht viele Daten.
- Manchmal führt der Blick des Analytikers von der Seite zu einer neuen Idee.
Kundensegmentierung
Mithilfe der Datenanalyse können Sie Muster erkennen, die in zuvor verfügbaren Informationen verborgen waren. Ein gutes Beispiel ist der Vergleich von Kundengruppen mithilfe der RFM-Segmentierung (Recency Frequency Monetary) und der Segmentierung mithilfe von ML-Algorithmen.
Die RFM-Segmentierung verwendet drei Schlüsselmetriken:
- Rezept des letzten Kaufs
- Häufigkeit der Einkäufe für den Zeitraum
- vom Kunden ausgegebener Betrag.
Basierend auf diesen Daten werden die Hauptgruppen unterschieden: "Verschwender", "treue Kunden", "fast verlorene Kunden" usw. Und Vermarkter nehmen die gewünschte Zielgruppe bereits in einen bestimmten Newsletter auf oder machen ein Angebot speziell für diese Gruppe.
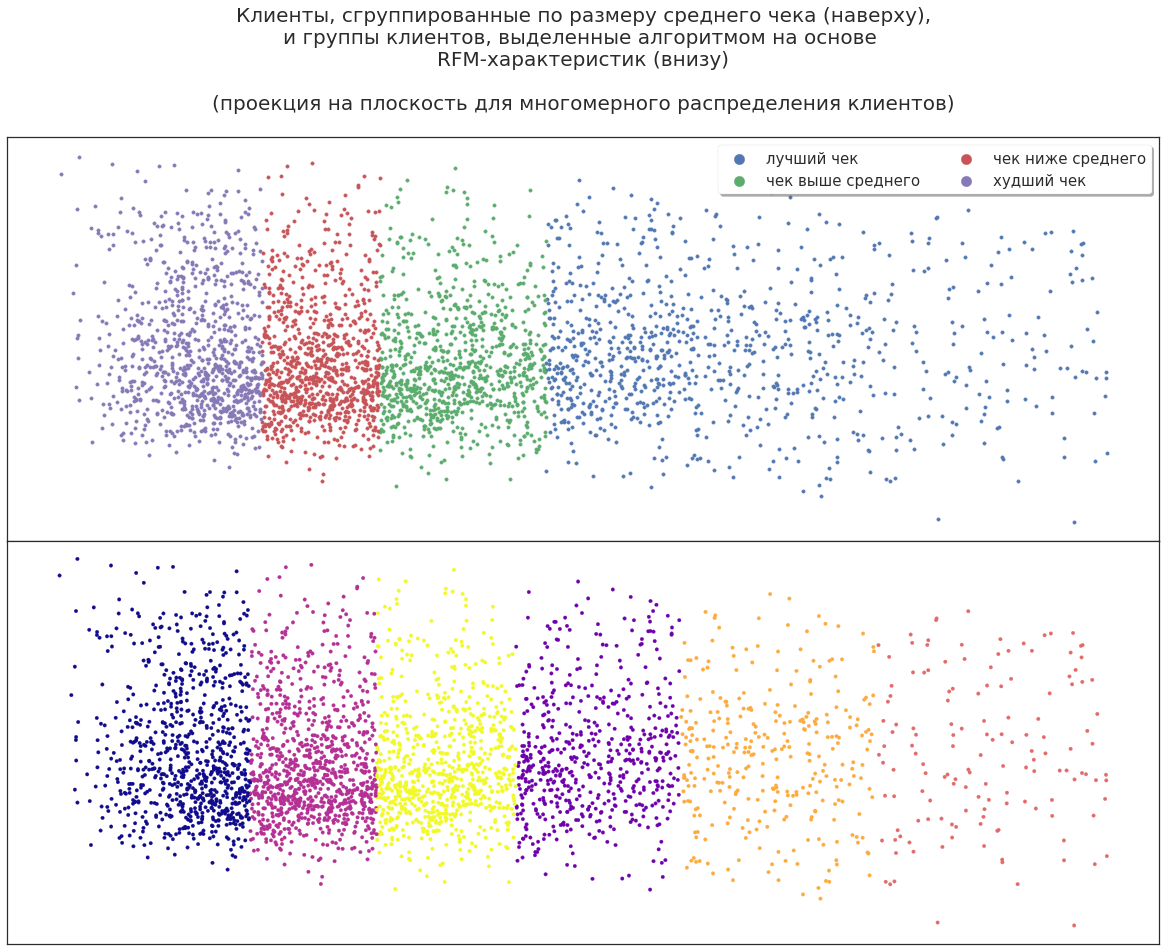
Mithilfe der RFM-Segmentierung können Sie beispielsweise Kundensegmente auswählen und als Punkte im dreidimensionalen Raum darstellen:
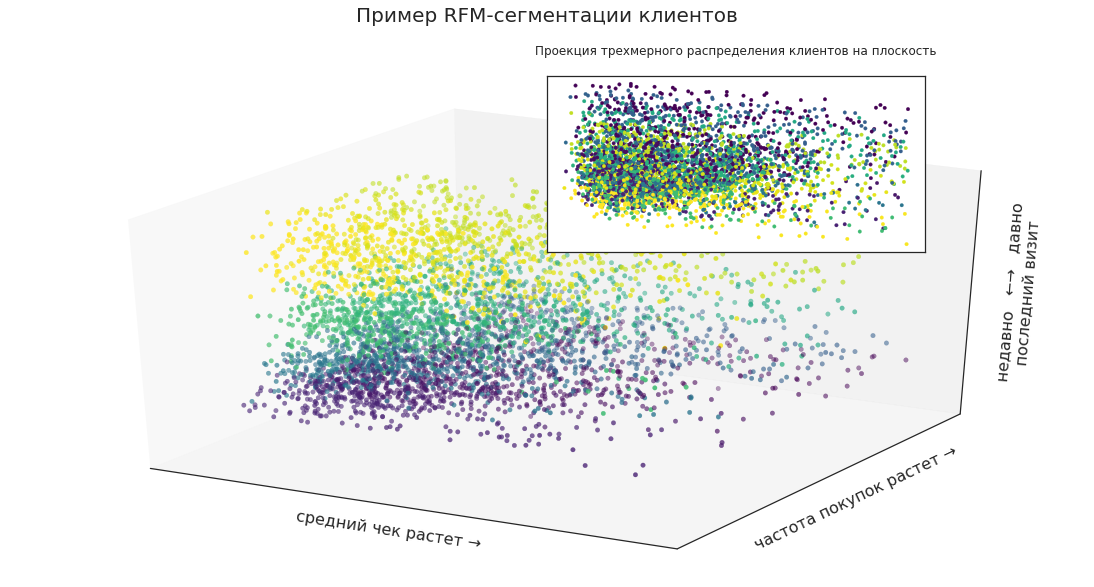
Auf diese Weise können Sie den Standort bestimmter Gruppen in der Gesamtmasse der Kunden, deren Proportionen und die Dynamik von Änderungen visuell anzeigen.
Projizieren Sie nun die dreidimensionale Verteilung der Segmente auf die Ebene. Kunden können durch die Einnahmen des Unternehmens geteilt werden, um die profitabelsten in Marketingkampagnen einzubeziehen. Reicht dies jedoch für eine effektive Planung aus?
Selbst in solchen Daten findet der Algorithmus für maschinelles Lernen zusätzliche Möglichkeiten: Er unterteilt Kunden in neue große Gruppen. Sie können diese Partition analysieren, um herauszufinden, warum der Algorithmus Clients auf diese Weise unterteilt hat. Einige hochprofitable Kunden sind beispielsweise Experten, die ihre Kunden beim Einkaufen begleiten und ihre Rabattkarten verwenden. Einige teilen ihre Karten aktiv mit Freunden und Bekannten. Das heißt, nach der ersten Verwendung von ML können Sie basierend auf denselben Daten zusätzliche Informationen über Ihre Kunden erhalten.
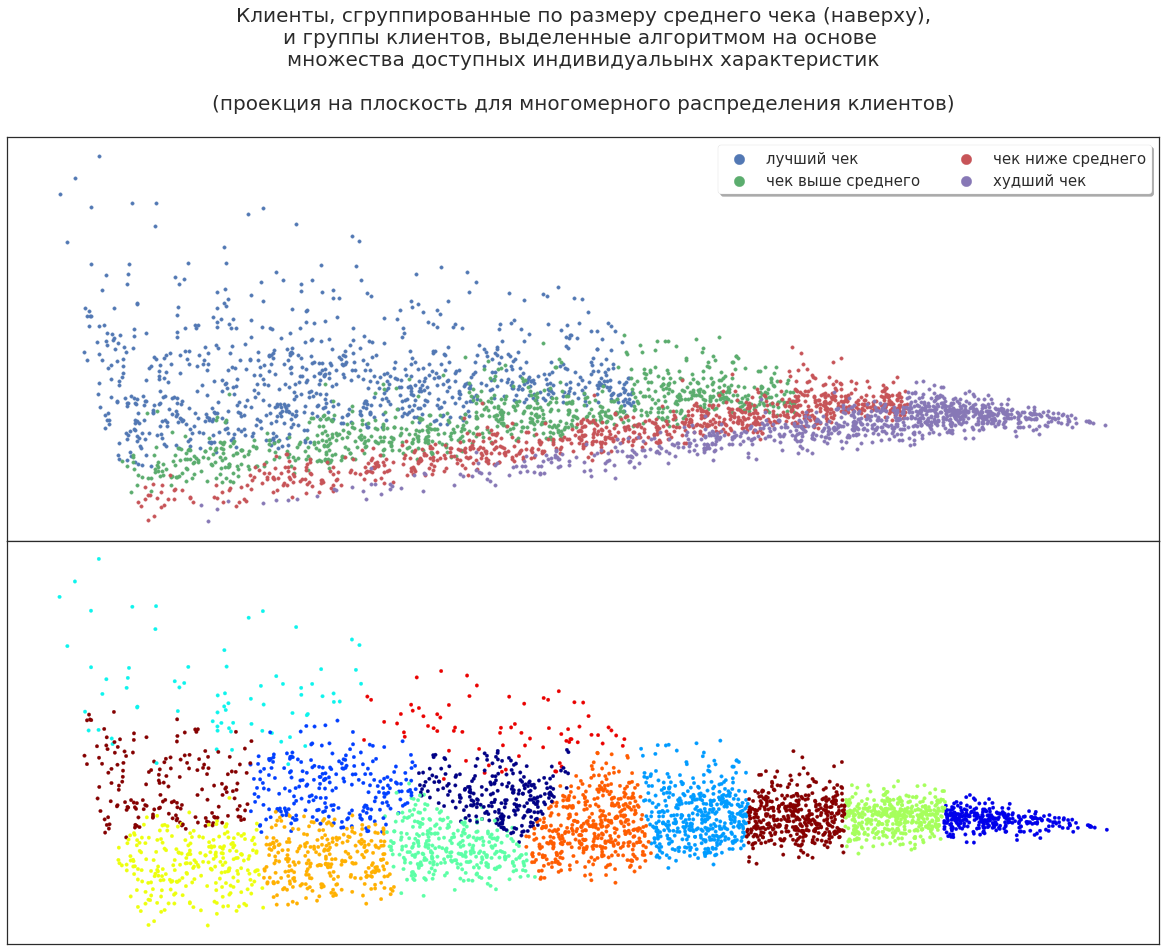
Erweitern wir die Kundenmerkmale: Fügen Sie Geschlecht, Alter, Verhalten und mehr hinzu. Wie wird der Algorithmus nun Käufer verteilen?
Zum Beispiel gibt es eine Gruppe, die sowohl die besten Kunden (die profitabelsten) als auch ihre „Nachbarn“ abdeckt, die weniger Gewinn bringen. Warum der Algorithmus diese Gruppe zugeordnet hat, ist eine Frage für den Analysten. Vielleicht zeigen diese Kunden mit zusätzlicher Anregung eine höhere Rentabilität. Oder im Gegenteil, diese Kunden sind nicht besonders vielversprechend, und die Steigerung der Rentabilität war eine zufällige Abweichung - sie zu stimulieren ist zusätzlich sinnlos. Es können verschiedene Theorien aufgestellt werden, die jedoch experimentell überprüft werden müssen.
Lagerplanung - Umsatzprognose
Darüber hinaus bietet das Projekt mehrere Entwicklungsoptionen. Beispielsweise können Sie Einkäufe in einem bestimmten Geschäft für den kommenden Zeitraum prognostizieren. Dann kann der Filialverwalter die erforderlichen Waren rechtzeitig im Zentrallager bestellen.
Die Analyse der Einkäufe in einer bestimmten Verkaufsstelle hilft bei der Formulierung der Warenanzeige in Schaufenstern. Wenn zum Beispiel viele männliche Käufer in den Laden kommen, sollte die Abteilung mit männlichen Produkten nicht in die hinterste Ecke gestellt werden.
Vergessen Sie nicht die sogenannte Kannibalisierung von Geschäften. Das heißt, wenn sich zwei Verkaufsstellen desselben Netzwerks in der Nähe befinden (z. B. an verschiedenen Enden derselben Straße), kann eine von ihnen Kunden abziehen, und die zweite bleibt im Leerlauf. Sie können ein Modell erstellen, das solche Phänomene verfolgt und darüber signalisiert.
***.
Kurz gesagt, maschinelles Lernen ist ein leistungsfähiges Werkzeug, das viel bewirken kann. Beim Erstellen von Modellen werden häufig nicht offensichtliche Muster aufgedeckt, von denen selbst Geschäftsanwender nichts wussten. Die Qualität des Modells hängt jedoch stark von der Qualität und Quantität der Daten ab.
Analysten der Direktion für die Entwicklung und Implementierung von Software, Jet Infosystems