Als Infrastrukturingenieur im Entwicklungsteam der Cloud-Plattform hatte ich die Möglichkeit, mit vielen verteilten Speichersystemen zu arbeiten, einschließlich der im Header angegebenen. Es scheint, dass es ein Verständnis für ihre Stärken und Schwächen gibt, und ich werde versuchen, meine Gedanken zu diesem Thema mit Ihnen zu teilen. Mal sehen, wer die Hash-Funktion länger hat.

Haftungsausschluss: Früher in diesem Blog konnten Sie Artikel über GlusterFS sehen. Ich habe nichts mit diesen Artikeln zu tun. Dies ist der Blog des Autors des Projektteams unserer Cloud, und jedes seiner Mitglieder kann seine Geschichte erzählen. Der Autor dieser Artikel ist Ingenieur unserer Betriebsgruppe und hat seine eigenen Aufgaben und Erfahrungen, die er geteilt hat. Bitte berücksichtigen Sie dies, wenn Sie plötzlich Meinungsverschiedenheiten feststellen. Ich nutze diese Gelegenheit, um dem Autor dieser Artikel meine Grüße zu übermitteln!
Was wird diskutiert
Lassen Sie uns über Dateisysteme sprechen, die auf der Basis von GlusterFS und CephFS erstellt werden können. Wir werden die Architektur dieser beiden Systeme diskutieren, sie aus verschiedenen Blickwinkeln betrachten und am Ende sogar riskieren, Schlussfolgerungen zu ziehen. Andere Ceph-Funktionen wie RBD und RGW sind davon nicht betroffen.
Terminologie
Um den Artikel für alle vollständig und verständlich zu machen, schauen wir uns die grundlegende Terminologie beider Systeme an:
Ceph-Terminologie:
RADOS (Reliable Autonomic Distributed Object Store) ist ein in sich geschlossener Objektspeicher, der die Grundlage des Ceph-Projekts bildet.
CephFS , RBD (RADOS Block Device), RGW (RADOS Gateway) - übergeordnete Gadgets für RADOS, die Endbenutzern verschiedene Schnittstellen zu RADOS bieten.
Insbesondere bietet CephFS eine POSIX-kompatible Dateisystemschnittstelle. Tatsächlich werden CephFS-Daten in RADOS gespeichert.
OSD (Object Storage Daemon) ist ein Prozess, der einen separaten Festplatten- / Objektspeicher in einem RADOS-Cluster bereitstellt.
RADOS-Pool (Pool) - mehrere OSDs , die durch ein gemeinsames Regelwerk vereint sind, z. B. eine Replikationsrichtlinie. Aus Sicht der Datenhierarchie ist ein Pool ein Verzeichnis oder ein separater Namespace (flach, keine Unterverzeichnisse) für Objekte.
PG (Placement Group) - Ich werde das Konzept von PG etwas später im Kontext vorstellen, um es besser zu verstehen.
Da RADOS die Grundlage ist, auf der CephFS basiert, werde ich oft darüber sprechen, und dies gilt automatisch für CephFS.
GlusterFS-Terminologie (im Folgenden gl):
Brick ist ein Prozess, der eine einzelne Festplatte bedient, ein Analogon von OSD in der RADOS-Terminologie.
Volumen - Volumen, in dem Steine vereint sind. Tom ist ein Pool-Analogon in RADOS und verfügt über eine spezifische Replikationstopologie zwischen Bausteinen.
Datenverteilung
Betrachten Sie zur Verdeutlichung ein einfaches Beispiel, das von beiden Systemen implementiert werden kann.
Das als Beispiel zu verwendende Setup:
- 2 Server (S1, S2) mit jeweils 3 Festplatten gleichen Volumens (sda, sdb, sdc);
- Volume / Pool mit Replikation 2.
Beide Systeme benötigen für den normalen Betrieb mindestens 3 Server. Aber wir machen ein Auge zu, da dies nur ein Beispiel für einen Artikel ist.
Im Fall von gl ist dies ein verteiltes repliziertes Volume, das aus 3 Replikationsgruppen besteht:

Jede Replikationsgruppe besteht aus zwei Bausteinen auf verschiedenen Servern.
Tatsächlich stellt sich heraus, welches Volume die drei RAID-1 kombiniert.
Wenn Sie es bereitstellen, das gewünschte Dateisystem herunterladen und mit dem Schreiben von Dateien beginnen, werden Sie feststellen, dass jede von Ihnen geschriebene Datei in eine dieser Replikationsgruppen als Ganzes fällt.
Die Verteilung der Dateien zwischen diesen verteilten Gruppen erfolgt über DHT (Distributed Hash Tables), eine Hash-Funktion (wir werden später darauf zurückkommen).
Auf dem "Diagramm" sieht es so aus:
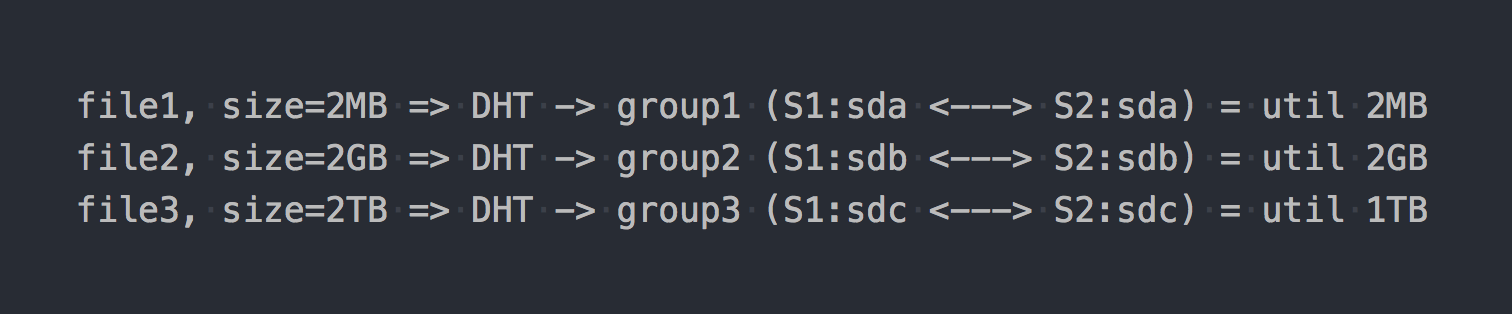
Als ob sich die ersten architektonischen Merkmale bereits manifestiert hätten:
- Platz in Gruppen ist ungleichmäßig entsorgt, es hängt von der Dateigröße ab;
- Beim Schreiben einer Datei geht IO nur an eine Gruppe, der Rest ist inaktiv.
- Sie können nicht die E / A des gesamten Volumes abrufen, wenn Sie eine einzelne Datei schreiben.
- Wenn in der Gruppe nicht genügend Speicherplatz zum Schreiben der Datei vorhanden ist, wird eine Fehlermeldung angezeigt. Die Datei wird nicht geschrieben und nicht an eine andere Gruppe weitergegeben.
Wenn Sie andere Datenträgertypen verwenden, z. B. Distributed-Striped-Replicated oder sogar Dispersed (Erasure Coding), ändert sich nur die Mechanik der Datenverteilung innerhalb einer Gruppe grundlegend. DHT wird auch Dateien vollständig in diese Gruppen zerlegen, und am Ende werden wir alle die gleichen Probleme bekommen. Ja, wenn das Volume nur aus einer Gruppe besteht oder wenn Sie alle Dateien ungefähr gleich groß haben, gibt es kein Problem. Wir sprechen jedoch von normalen Systemen mit Hunderten von Terabyte Daten, einschließlich Dateien unterschiedlicher Größe. Daher glauben wir, dass es ein Problem gibt.
Schauen wir uns nun CephFS an. Das oben erwähnte RADOS betritt die Szene. In RADOS wird jede Festplatte von einem separaten Prozess bedient - OSD. Basierend auf unserem Setup erhalten wir nur 6 davon, 3 auf jedem Server. Als nächstes müssen wir einen Pool für die Daten erstellen und die Anzahl der PGs und den Datenreplikationsfaktor in diesem Pool festlegen - in unserem Fall 2.
Angenommen, wir haben einen Pool mit 8 PG erstellt. Diese PGs werden ungefähr gleichmäßig über das OSD verteilt:
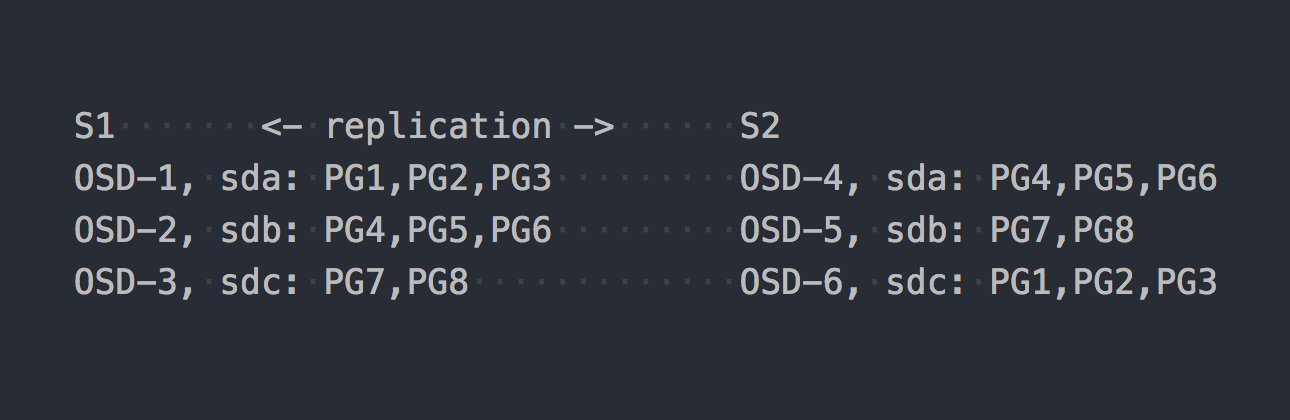
Es ist Zeit zu klären, dass PG eine logische Gruppe ist, die eine Reihe von Objekten kombiniert. Da wir Replikationsfaktor 2 festgelegt haben, verfügt jedes PG über ein Replikat auf einem anderen OSD auf einem anderen Server (standardmäßig). Zum Beispiel hat PG1, das sich auf OSD-1 auf Server S1 befindet, einen Zwilling auf S2 auf OSD-6. In jedem PG-Paar (oder Triple, wenn Replikation 3) befindet sich PRIMARY PG, das aufgezeichnet wird. Zum Beispiel ist PRIMARY für PG4 auf S1, aber PRIMARY für PG3 ist auf S2.
Nachdem Sie nun wissen, wie RADOS funktioniert, können wir Dateien in unseren brandneuen Pool schreiben. Obwohl RADOS ein vollwertiger Speicher ist, ist es nicht möglich, ihn als Dateisystem bereitzustellen oder als Blockgerät zu verwenden. Um Daten direkt darauf zu schreiben, müssen Sie ein spezielles Dienstprogramm oder eine Bibliothek verwenden.
Wir schreiben die gleichen drei Dateien wie im obigen Beispiel:
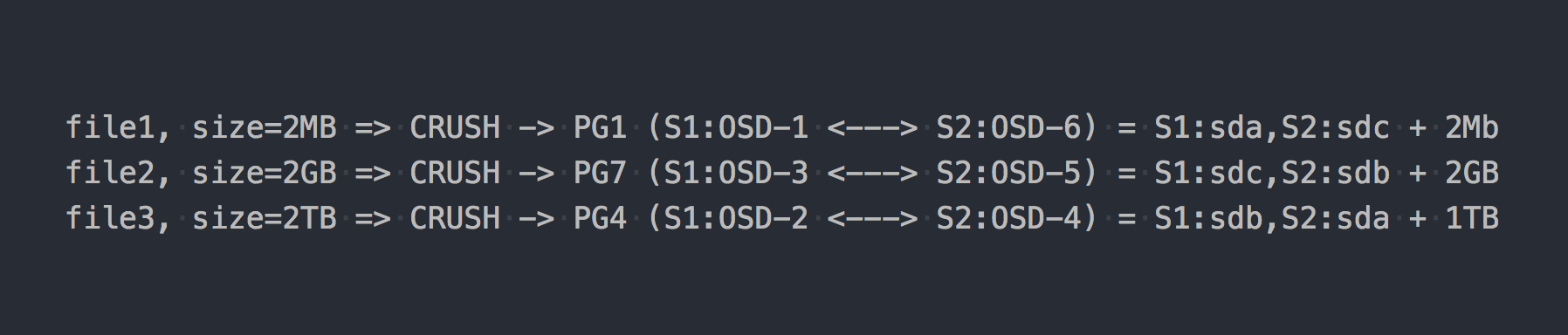
Im Fall von RADOS ist alles irgendwie komplizierter geworden, stimme zu.
Dann erschien CRUSH (Controlled Replication Under Scalable Hashing) in der Kette. CRUSH ist der Algorithmus, auf dem RADOS beruht (wir werden später darauf zurückkommen). In diesem speziellen Fall wird unter Verwendung dieses Algorithmus bestimmt, wo die Datei in welches PG geschrieben werden soll. Hier hat CRUSH die gleiche Funktion wie DHT in gl. Als Ergebnis dieser pseudozufälligen Verteilung von Dateien auf PG haben wir alle die gleichen Probleme wie gl, nur bei einem komplexeren Schema.
Aber ich habe absichtlich über einen wichtigen Punkt geschwiegen. Fast niemand benutzt RADOS in seiner reinen Form. Für eine bequeme Arbeit mit RADOS wurden die folgenden Schichten entwickelt: RBD, CephFS, RGW, die ich bereits erwähnt habe.
Alle diese Übersetzer (RADOS-Clients) bieten eine andere Client-Oberfläche, ähneln sich jedoch in ihrer Arbeit mit RADOS. Die wichtigste Ähnlichkeit besteht darin, dass alle Daten, die sie durchlaufen, in Stücke geschnitten und als separate RADOS-Objekte in RADOS abgelegt werden. Standardmäßig schneiden offizielle Clients den Eingabestream in 4 MB große Teile. Bei RBD kann die Streifengröße beim Erstellen des Volumes festgelegt werden. Bei CephFS ist dies das Attribut (xattr) der Datei und kann auf der Ebene einzelner Dateien oder für alle Katalogdateien verwaltet werden. Nun, RGW hat auch einen entsprechenden Parameter.
Nehmen wir nun an, wir haben CephFS auf den RADOS-Pool gestapelt, der im vorherigen Beispiel vorgestellt wurde. Jetzt sind die fraglichen Systeme völlig gleichberechtigt und bieten eine identische Dateizugriffsschnittstelle.
Wenn wir unsere Testdateien zurück in das brandneue CephFS schreiben, werden wir eine völlig andere, fast gleichmäßige Verteilung der Daten auf dem OSD finden. Zum Beispiel wird Datei2 mit einer Größe von 2 GB in 512 Teile unterteilt, die auf verschiedene PGs und infolgedessen nahezu gleichmäßig auf verschiedene OSDs verteilt werden, und dies löst praktisch die oben beschriebenen Probleme mit der Datenverteilung.
In unserem Beispiel werden nur 8 PG verwendet, obwohl empfohlen wird, ~ 100 PG auf einem OSD zu haben. Und Sie benötigen 2 Pools, damit CephFS funktioniert. Sie benötigen auch einige Service-Daemons, damit RADOS im Prinzip funktioniert. Denken Sie nicht, dass alles so einfach ist, ich lasse ausdrücklich viel weg, um die Essenz nicht zu verlassen.
Jetzt scheint CephFS interessanter zu sein, oder? Aber ich habe keinen weiteren wichtigen Punkt erwähnt, diesmal über gl. Gl hat auch einen Mechanismus zum Schneiden von Dateien in Blöcke und zum Ausführen dieser Blöcke durch DHT. Das sogenannte Sharding ( Sharding ).
Fünf Minuten Geschichte
Am 21. April 2016 veröffentlichte das Ceph-Entwicklungsteam "Jewel", die erste Ceph-Version, in der CephFS als stabil gilt.
Das ist jetzt alles links und rechts, was über CephFS schreit! Und vor 3-4 Jahren wäre es zumindest eine zweifelhafte Entscheidung, es zu benutzen. Wir haben nach anderen Lösungen gesucht, und die oben beschriebene Architektur war nicht gut. Aber wir glaubten mehr daran als an CephFS und warteten auf die Scherbe, die sich auf die Veröffentlichung vorbereitete.
Und hier ist X Tag:
4. Juni 2015 - Die Gluster Community gab heute die allgemeine Verfügbarkeit der offenen softwaredefinierten Speichersoftware GlusterFS 3.7 bekannt.
3.7 - die erste Version von gl, in der Sharding als experimentelle Gelegenheit angekündigt wurde. Sie hatten fast ein Jahr vor der stabilen Veröffentlichung von CephFS Zeit, um auf dem Podium Fuß zu fassen ...
Scherben heißt also. Wie alles in gl wird dies in einem separaten Übersetzer implementiert, der über dem DHT (auch Übersetzer) auf dem Stapel stand. Da es höher als DHT ist, empfängt DHT vorgefertigte Shards an der Eingabe und verteilt sie als reguläre Dateien auf die Replikationsgruppen. Das Sharding ist auf der Ebene der einzelnen Lautstärken aktiviert. Die Größe des Shards kann standardmäßig auf 4 MB eingestellt werden, wie bei Ceph-Lotionen.
Als ich die ersten Tests durchführte, war ich begeistert! Ich habe allen gesagt, dass gl jetzt das Beste ist und wir jetzt leben werden! Wenn Sharding aktiviert ist, erfolgt die Aufzeichnung einer Datei parallel zu verschiedenen Replikationsgruppen. Die Dekomprimierung nach der "On-Write" -Komprimierung kann schrittweise auf die Shard-Ebene erfolgen. Auch hier wird beim Cache-Shooting alles gut und separate Shards werden in den Cache verschoben und nicht in die gesamten Dateien. Im Allgemeinen freute ich mich, weil es schien, als hätte er ein sehr cooles Instrument in die Hände bekommen.
Es blieb auf die ersten Bugfixes und den Status "Ready for Production" zu warten. Aber alles ist nicht so rosig geworden ... Um den Artikel nicht mit einer Liste kritischer Fehler im Zusammenhang mit Sharding zu erweitern, die ab und zu in den nächsten Versionen auftreten, kann ich nur sagen, dass das letzte "Hauptproblem" mit der folgenden Beschreibung:
Das Erweitern eines Shuster-Volumes, das gespalten ist, kann zu einer Beschädigung der Datei führen. Sharded-Volumes werden normalerweise für VM-Images verwendet. Wenn solche Volumes erweitert oder möglicherweise verkleinert werden (d. H. Bricks hinzufügen / entfernen und neu ausgleichen), wird berichtet, dass VM-Images beschädigt werden.
wurde in Release 3.13.2 am 20. Januar 2018 geschlossen ... vielleicht ist dies nicht der letzte?
Kommentar zu einem unserer Artikel dazu sozusagen aus erster Hand.
RedHat stellt in seiner Dokumentation zum aktuellen RedHat Gluster Storage 3.4 fest, dass der einzige von ihnen unterstützte Sharding-Fall der Speicher für VM-Festplatten ist.
Sharding hat einen unterstützten Anwendungsfall: Im Zusammenhang mit der Bereitstellung von Red Hat Gluster Storage als Speicherdomäne für Red Hat Enterprise Virtualization wird Speicher für Live-Images virtueller Maschinen bereitgestellt. Beachten Sie, dass Sharding auch für diesen Anwendungsfall erforderlich ist, da es gegenüber früheren Implementierungen erhebliche Leistungsverbesserungen bietet.
Ich weiß nicht, warum eine solche Einschränkung vorliegt, aber Sie müssen zugeben, dass sie alarmierend ist.
Jetzt habe ich alles für dich da
Beide Systeme verwenden eine Hash-Funktion, um Daten pseudozufällig auf Festplatten zu verteilen.
Für RADOS sieht es ungefähr so aus:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
Gl verwendet das sogenannte konsistente Hashing . Jeder Baustein erhält einen "Bereich innerhalb eines 32-Bit-Hash-Bereichs". Das heißt, alle Bausteine teilen sich den gesamten linearen Adress-Hash-Raum, ohne Bereiche oder Löcher zu schneiden. Der Client führt den Dateinamen über die Hash-Funktion aus und bestimmt dann, in welchen Hash-Bereich der empfangene Hash fällt. Somit wird Ziegel ausgewählt. Wenn die Replikationsgruppe mehrere Bausteine enthält, haben alle denselben Hash-Bereich. Ungefähr so:
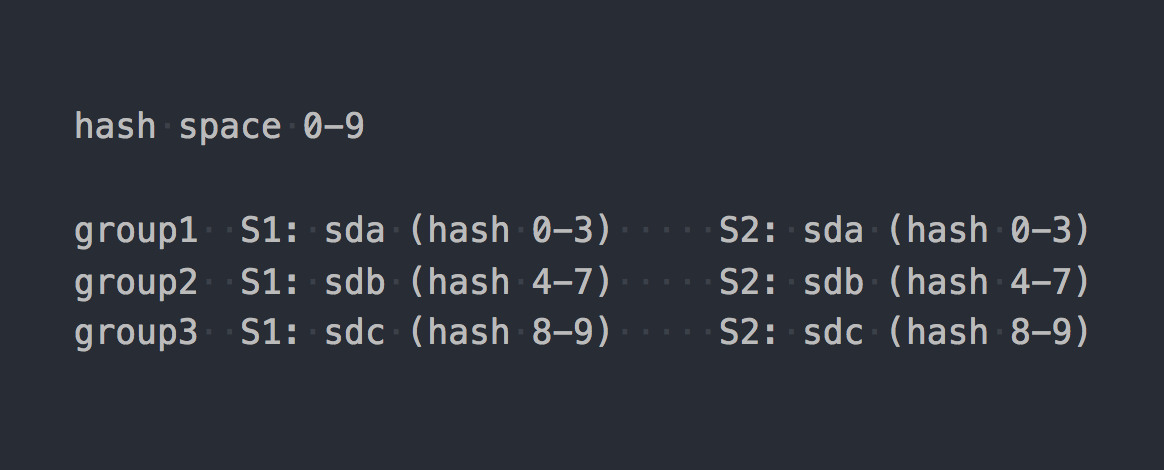
Wenn wir die Arbeit zweier Systeme auf eine bestimmte logische Form bringen, wird sich ungefähr so herausstellen:
file -> HASH -> placement_unit
Dabei ist placation_unit im Fall von RADOS PG und im Fall von gl eine Replikationsgruppe aus mehreren Bausteinen.
Also, eine Hash-Funktion, dann verteilt diese, verteilt Dateien und plötzlich stellt sich heraus, dass eine Placement_unit mehr als die andere verwendet wird. Dies ist das grundlegende Merkmal von Hash-Verteilungssystemen. Und wir stehen vor einer sehr häufigen Aufgabe - das Ungleichgewicht der Daten.
Gl kann neu erstellt werden. Aufgrund der oben beschriebenen Architektur mit Hash-Bereichen können Sie die Neuerstellung so oft ausführen, wie Sie möchten, aber kein Hash-Bereich (und infolgedessen Daten) rührt sich nicht. Das einzige Kriterium für die Umverteilung von Hash-Bereichen ist eine Änderung der Volumenkapazität. Und Sie haben noch eine Option - das Hinzufügen von Steinen. Wenn es sich um ein Volume mit Replikation handelt, müssen wir eine ganze Replikationsgruppe hinzufügen, dh zwei neue Bausteine in unserem Setup. Nach dem Erweitern des Volumes können Sie mit der Neuerstellung beginnen. Die Hash-Bereiche werden unter Berücksichtigung der neuen Gruppe neu verteilt und die Daten werden verteilt. Wenn eine Replikationsgruppe gelöscht wird, werden Hash-Bereiche automatisch zugewiesen.
RADOS hat eine ganze Reihe von Möglichkeiten. In einem Ceph- Artikel habe ich mich viel über das Konzept von PG beschwert, aber hier im Vergleich zu gl natürlich RADOS zu Pferd. Jedes OSD hat sein eigenes Gewicht. Normalerweise wird es basierend auf der Größe der Festplatte festgelegt. PGs werden wiederum von OSD abhängig von dessen Gewicht verteilt. Alles, dann ändern wir einfach das Gewicht des OSD nach oben oder unten und das PG (zusammen mit den Daten) beginnt sich auf andere OSDs zu verschieben. Außerdem verfügt jedes OSD über ein zusätzliches Anpassungsgewicht, mit dem Sie Daten zwischen den Festplatten eines Servers ausgleichen können. All dies ist CRUSH inhärent. Der Hauptgewinn besteht darin, dass die Poolkapazität nicht erweitert werden muss, um die Daten besser aus dem Gleichgewicht zu bringen. Es ist nicht erforderlich, Festplatten in Gruppen hinzuzufügen. Sie können nur ein OSD hinzufügen, und ein Teil von PG wird darauf übertragen.
Ja, es ist möglich, dass beim Erstellen eines Pools nicht genügend PG erstellt wurde und sich herausstellte, dass jedes der PGs ein ziemlich großes Volumen aufweist und das Ungleichgewicht überall dort bleibt, wo sie sich bewegen. In diesem Fall können Sie die Anzahl der PG erhöhen, und diese werden in kleinere aufgeteilt. Ja, wenn der Cluster voller Daten ist, tut es weh, aber die Hauptsache in unserem Vergleich ist, dass es eine solche Möglichkeit gibt. Jetzt ist nur eine Erhöhung der Anzahl der PGs zulässig, und dabei müssen Sie vorsichtiger sein. In der nächsten Version von Ceph - Nautilus wird jedoch die Reduzierung der Anzahl der PGs unterstützt (pg fusioning).
Datenreplikation
Unsere Testpools und Volumes haben einen Replikationsfaktor von 2. Interessanterweise verwenden die betreffenden Systeme unterschiedliche Ansätze, um diese Anzahl von Replikaten zu erreichen.
Im Fall von RADOS sieht das Aufzeichnungsschema ungefähr so aus:
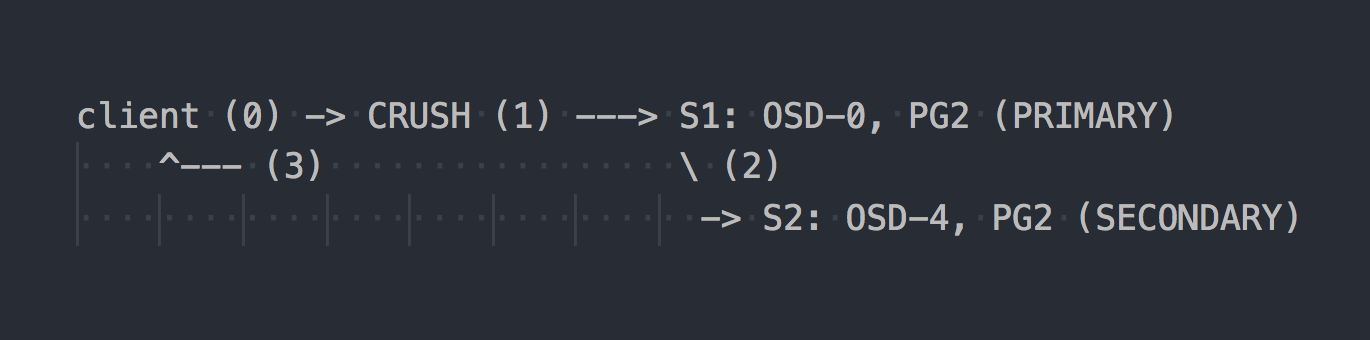
Der Client kennt die Topologie des gesamten Clusters, wählt mit CRUSH (Schritt 0) ein bestimmtes PG zum Schreiben aus, schreibt unter OSD-0 in PRIMARY PG (Schritt 1), repliziert dann OSD-0 synchron Daten nach SECONDARY PG (Schritt 2) und erst danach erfolgreicher / erfolgloser Schritt 2, OSD bestätigt / bestätigt dem Client den Vorgang nicht (Schritt 3). Die Datenreplikation zwischen zwei OSDs ist für den Client transparent. OSDs können im Allgemeinen ein separates "Cluster" -Netzwerk für die Datenreplikation verwenden.
Wenn die dreifache Replikation konfiguriert ist, wird sie auch synchron mit PRIMARY OSD auf zwei SECONDARY ausgeführt, die für den Client transparent sind. Nun, nur diese Letancy ist höher.
Gl funktioniert anders:
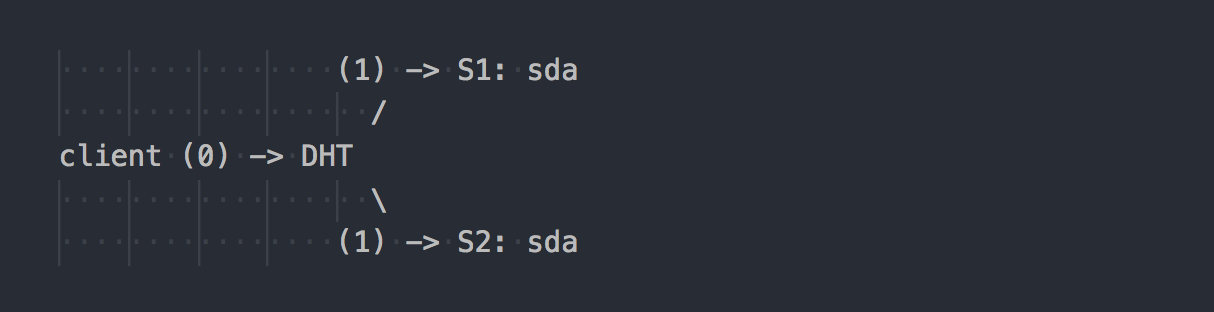
Der Client kennt die Topologie des Volumes, verwendet DHT (Schritt 0), um den gewünschten Baustein zu bestimmen, und schreibt dann darauf (Schritt 1). Alles ist einfach und klar. Hier erinnern wir uns jedoch daran, dass alle Bausteine in der Replikationsgruppe den gleichen Hash-Bereich haben. Und dieses kleine Merkmal macht den ganzen Urlaub. Der Client schreibt parallel zu allen Bausteinen, die einen geeigneten Hash-Bereich haben.
In unserem Fall führt der Client bei doppelter Replikation eine doppelte Aufzeichnung parallel auf zwei verschiedenen Bausteinen durch. Während der dreifachen Replikation wird jeweils eine dreifache Aufzeichnung durchgeführt, und 1 MB Daten werden ungefähr zu 3 MB Netzwerkverkehr vom Client zur Seite der gl-Server. Stimmen Sie zu, die Konzepte von Systemen sind senkrecht.
In einem solchen Schema wird dem gl-Client mehr Arbeit zugewiesen, und als Ergebnis benötigt er mehr CPU. Nun, ich habe bereits über das Netzwerk gesprochen.
Die Replikation erfolgt durch den AFP-Übersetzer (Automatic File Replication) - Ein clientseitiger Xlator, der eine synchrone Replikation durchführt. Repliziert Schreibvorgänge auf alle Bausteine des Replikats → Verwendet ein Transaktionsmodell.
Synchronisieren Sie bei Bedarf die Replikate in der Gruppe (Heilung), z. B. nach einer vorübergehenden Nichtverfügbarkeit eines Bausteins tun die Gl-Dämonen dies selbstständig mithilfe des integrierten AFP, das für Kunden transparent und ohne deren Teilnahme ist.
Es ist interessant, dass wir das gleiche Verhalten wie RADOS erhalten, wenn Sie nicht über den nativen gl-Client arbeiten, sondern über den in NF integrierten NFS-Server schreiben. In diesem Fall wird AFP in Gl-Daemons verwendet, um Daten ohne Client-Intervention zu replizieren. Das integrierte NFS ist jedoch in gl v4 gesichert. Wenn Sie dieses Verhalten wünschen, wird empfohlen, NFS-Ganesha zu verwenden.
Übrigens können Sie aufgrund des unterschiedlichen Verhaltens bei der Verwendung von NFS und des nativen Clients völlig unterschiedliche Leistungsindikatoren sehen.
Haben Sie den gleichen Cluster, nur "am Knie"?
Ich sehe im Internet oft Diskussionen über alle Arten von Kniescheiben-Setups, bei denen ein Datencluster aus dem Vorhandenen aufgebaut wird. In diesem Fall bietet Ihnen eine RADOS-basierte Lösung mehr Freiheit bei der Auswahl Ihrer Laufwerke. In RADOS können Sie Laufwerke fast jeder Größe hinzufügen. Jede Festplatte hat (normalerweise) ein Gewicht, das ihrer Größe entspricht, und die Daten werden fast proportional zu ihrem Gewicht auf die Festplatten verteilt. Im Fall von gl gibt es kein Konzept für "separate Festplatten" in Volumes mit Replikation. Festplatten werden paarweise bei doppelter Replikation oder dreifach bei dreifacher Replikation hinzugefügt. Wenn sich in einer Replikationsgruppe Festplatten unterschiedlicher Größe befinden, werden Sie auf eine Stelle auf der kleinsten Festplatte in der Gruppe stoßen und die Kapazität großer Festplatten aufheben. In einem solchen Schema geht gl davon aus, dass die Kapazität einer Replikationsgruppe gleich der Kapazität der kleinsten Festplatte in der Gruppe ist, was logisch ist. Gleichzeitig dürfen Replikationsgruppen vorhanden sein, die aus Festplatten unterschiedlicher Größe bestehen - Gruppen unterschiedlicher Größe. Größere Gruppen können im Vergleich zu anderen Gruppen einen größeren Hash-Bereich erhalten und erhalten daher mehr Daten.
Wir leben seit dem fünften Jahr bei Ceph. Wir haben mit Festplatten mit dem gleichen Volumen begonnen, jetzt führen wir größere ein. Mit Ceph können Sie die Festplatte entfernen und ohne architektonische Schwierigkeiten durch eine andere größere oder etwas kleinere ersetzen. Mit gl ist alles komplizierter - nehmen Sie eine 2-TB-Festplatte heraus - legen Sie bitte dieselbe ein. Nun, oder ziehen Sie die ganze Gruppe als Ganzes zurück, was nicht sehr gut ist, stimmen Sie zu.
Failover
Wir haben uns bereits ein wenig mit der Architektur der beiden Lösungen vertraut gemacht und können nun darüber sprechen, wie wir damit leben sollen und welche Funktionen bei der Wartung zur Verfügung stehen.
Angenommen, wir haben sda auf s1 abgelehnt - eine häufige Sache.
Im Fall von gl:
- Eine Kopie der Daten auf der in der Gruppe verbleibenden Live-Festplatte wird nicht automatisch an andere Gruppen weitergegeben.
- Bis zum Ersetzen der Festplatte verbleibt nur eine Kopie der Daten.
- Wenn eine ausgefallene Festplatte durch eine neue ersetzt wird, wird die Replikation von einer funktionierenden Festplatte auf eine neue (1 zu 1) durchgeführt.
Dies ist wie das Servieren eines Regals mit mehreren RAID-1. Ja, bei dreifacher Replikation bleibt bei einem Ausfall eines Laufwerks nicht eine Kopie übrig, sondern zwei, aber dieser Ansatz weist schwerwiegende Nachteile auf, und ich werde sie anhand eines guten Beispiels mit RADOS zeigen.
Angenommen, wir haben sda auf S1 (OSD-0) fehlgeschlagen - eine häufige Sache:
- PGs, die sich auf OSD-0 befanden, werden nach 10 Minuten automatisch anderen OSDs zugeordnet (Standard). In unserem Beispiel auf OSD 1 und 2. Wenn mehr Server vorhanden waren, dann auf einer größeren Anzahl von OSD.
- PGs, die die zweite überlebende Kopie der Daten speichern, replizieren sie automatisch auf die OSDs, auf denen die wiederhergestellten PGs übertragen werden. Es stellt sich heraus, dass viele zu viele repliziert werden, nicht wie eins zu eins wie gl.
- Wenn eine neue Festplatte anstelle einer defekten Festplatte eingeführt wird, werden einige PGs entsprechend ihrem Gewicht im neuen OSD akkumuliert und Daten von anderen OSDs werden neu verteilt.
Ich denke, es macht keinen Sinn, die architektonischen Vorteile von RADOS zu erklären. Sie können nicht zucken, wenn Sie einen Brief erhalten, der besagt, dass das Laufwerk ausgefallen ist. Und wenn Sie morgens zur Arbeit kommen, stellen Sie fest, dass alle fehlenden Kopien bereits auf Dutzenden anderer OSDs oder in diesem Prozess wiederhergestellt wurden. In großen Clustern, in denen Hunderte von PGs auf mehrere Festplatten verteilt sind, kann die Datenwiederherstellung eines OSD mit einer Geschwindigkeit erfolgen, die viel höher ist als die Geschwindigkeit einer Festplatte, da Dutzende von OSDs beteiligt sind (Lesen und Schreiben). Nun, Sie sollten auch den Lastausgleich nicht vergessen.
Skalieren
In diesem Zusammenhang werde ich wahrscheinlich den Sockel gl geben. In einem Artikel über Ceph habe ich bereits über einige der Komplexitäten der RADOS-Skalierung geschrieben, die mit dem PG-Konzept verbunden sind. Wenn der Anstieg der PG mit dem Wachstum des Clusters immer noch zu beobachten ist, ist was mit Ceph MDS nicht klar. CephFS läuft auf RADOS und verwendet einen separaten Pool für Metadaten und einen speziellen Prozess, den Ceph-Metadatenserver (MDS), um Dateisystemmetadaten zu warten und alle Vorgänge mit dem FS zu koordinieren. Ich sage nicht, dass MDS die Skalierbarkeit von CephFS beeinträchtigt, nein, zumal Sie mehrere MDS im Aktiv-Aktiv-Modus ausführen können. Ich möchte nur erwähnen, dass gl architektonisch ohne all dies ist. Es hat kein PG-Gegenstück, nichts wie MDS. Gl skaliert wirklich perfekt, indem einfach Replikationsgruppen fast linear hinzugefügt werden.
In den Tagen vor CephFS haben wir die Lösung für Daten-Petabyte entwickelt und uns gl angesehen. Dann hatten wir Zweifel an der Skalierbarkeit von gl und fanden es durch die Mailingliste heraus. Hier ist eine der Antworten (F: meine Frage):
Ich verwende 60 Server mit jeweils 26 x 8 TB Festplatten, insgesamt 1560 Festplatten, 16 + 4 EC-Datenträger mit 9 TB nutzbarem Speicherplatz.
F: Verwenden Sie libgfapi oder FUSE oder NFS auf der Clientseite?
Ich benutze FUSE und habe fast 1000 Kunden.
F: Wie viele Dateien hat Ihr Volume?
F: Dateien sind größer oder kleiner?
Ich habe über 1 Million Dateien und% 13 des Clusters wird verwendet, was eine durchschnittliche Dateigröße von 1 GB ergibt.
Die minimale / maximale Dateigröße beträgt 100 MB / 2 GB. Jeden Tag werden 10 bis 20 TB neue Daten in das Volume eingegeben.
F: Wie schnell funktioniert "ls"?
Metadatenvorgänge sind erwartungsgemäß langsam. Ich versuche nicht mehr als 2-3K Dateien in ein Verzeichnis zu stellen. Mein Anwendungsfall ist das Sichern / Archivieren, daher führe ich selten Metadatenoperationen durch.
Dateien umbenennen
Zurück zu den Hash-Funktionen. Wir haben herausgefunden, wie bestimmte Dateien auf bestimmte Festplatten weitergeleitet werden, und jetzt wird die Frage relevant. Aber was passiert beim Umbenennen von Dateien?
Wenn wir den Namen der Datei ändern, ändert sich schließlich auch der Hash in ihrem Namen, dh der Speicherort dieser Datei auf einer anderen Festplatte (in einem anderen Hash-Bereich) oder bei RADOS auf einem anderen PG / OSD. Ja, wir denken richtig und hier bei zwei Systemen ist alles wieder senkrecht.
Im Fall von gl wird beim Umbenennen einer Datei der neue Name über eine Hash-Funktion ausgeführt, ein neuer Baustein definiert und ein spezieller Link zum alten Baustein erstellt, in dem die Datei wie zuvor verbleibt. Topovka, richtig? Damit die Daten wirklich an einen neuen Ort verschoben werden und der Client nicht unnötig auf den Link geklickt hat, müssen Sie eine Rebellion durchführen.
RADOS verfügt jedoch im Allgemeinen nicht über eine Methode zum Umbenennen von Objekten, da diese später verschoben werden müssen. Es wird vorgeschlagen, zum Umbenennen ein faires Kopieren zu verwenden, was zu einer synchronen Bewegung des Objekts führt. Und CephFS, das auf RADOS läuft, hat einen Trumpf in Form eines Pools mit Metadaten und MDS im Ärmel. Das Ändern des Dateinamens wirkt sich nicht auf den Inhalt der Datei im Datenpool aus.
Replikation 2.5
Gl hat eine sehr coole Funktion, die ich separat erwähnen möchte. Jeder versteht, dass Replikation 2 keine zuverlässige Konfiguration ist, sie findet jedoch regelmäßig statt, um durchaus gerechtfertigt zu sein. Zum Schutz vor Split-Brain in solchen Schemata und zur Gewährleistung der Datenkonsistenz können Sie mit gl Volumes mit Replikat 2 und einem zusätzlichen Arbiter erstellen. Der Arbiter ist für die Replikation von 3 oder mehr anwendbar. Dies ist derselbe Baustein in der Gruppe wie die beiden anderen, nur dass nur eine Dateistruktur aus Dateien und Verzeichnissen erstellt wird. Dateien auf einem solchen Baustein haben die Größe Null, aber ihre erweiterten Attribute des Dateisystems (erweiterte Attribute) werden mit Dateien voller Größe in derselben Replik synchronisiert. Ich denke, die Idee ist klar. Ich denke, das ist eine coole Gelegenheit.
Der einzige Moment ... die Größe des Ortes in der Replikationsgruppe wird durch die Größe des kleinsten Bausteins bestimmt. Dies bedeutet, dass der Arbiter eine Festplatte mit mindestens der gleichen Größe wie die anderen in der Gruppe verschieben muss. Zu diesem Zweck wird empfohlen, dünne (dünne) fiktive, große LV-Größen zu erstellen, um keine echte Festplatte zu verwenden.
Und was ist mit Kunden?
Die native API der beiden Systeme wird in Form der Bibliotheken libgfapi (gl) und libcephfs (CephFS) implementiert. Bindungen für beliebte Sprachen sind ebenfalls verfügbar. Im Allgemeinen ist bei Bibliotheken alles ungefähr gleich gut. Das allgegenwärtige NFS-Ganesha unterstützt beide Bibliotheken als FSAL, was ebenfalls die Norm ist. Qemu unterstützt auch die native gl-API über libgfapi.
Fio (Flexible I / O Tester) unterstützt libgfapi jedoch schon lange und erfolgreich, libcephfs jedoch nicht. Das ist ein Plus, weil mit fio ist es wirklich schön, gl direkt zu testen. Nur wenn Sie vom Userspace über libgfapi arbeiten, erhalten Sie alles, was gl von gl kann.
Wenn wir jedoch über das POSIX-Dateisystem und dessen Bereitstellung sprechen, kann gl nur den FUSE-Client und die CephFS-Implementierung im Upstream-Kernel anbieten. Es ist klar, dass Sie im Kernelmodul einen solchen Trick ausführen können, dass FUSE eine bessere Leistung zeigt. In der Praxis ist FUSE jedoch immer ein Overhead beim Kontextwechsel. Ich habe mehr als einmal persönlich gesehen, wie FUSE einen Dual-Socket-Server nur mit CSs verbog.
Irgendwie sagte Linus:
Userspace-Dateisystem? Das Problem ist genau dort. War schon immer so. Leute, die denken, dass Userspace-Dateisysteme für alles andere als Spielzeug realistisch sind, sind einfach irregeführt.
Im Gegensatz dazu finden Gl-Entwickler FUSE cool. Dies soll mehr Flexibilität bieten und sich von Kernelversionen lösen. Ich benutze FUSE, weil es bei gl nicht um Geschwindigkeit geht. Irgendwie ist es geschrieben - nun, es ist normal und es ist wirklich seltsam, sich mit der Implementierung im Kernel zu beschäftigen.
Leistung
Es wird keine Vergleiche geben).
Das ist zu kompliziert. Selbst bei identischem Aufbau ist es zu schwierig, objektive Tests durchzuführen. Wie auch immer, es wird jemanden in den Kommentaren geben, der 100500 Parameter angibt, die eines der Systeme „beschleunigen“ und sagen, dass die Tests Bullshit sind. Testen Sie sich daher bei Interesse bitte.
Fazit
Insbesondere RADOS und CephFS sind eine komplexere Lösung sowohl für das Verständnis, die Einstellung als auch für die Wartung.
Aber ich persönlich mag die Architektur von RADOS und die Ausführung auf CephFS mehr als auf GlusterFS. CephFS-Metadaten mit mehr Handles (PG, OSD-Gewicht, CRUSH-Hierarchie usw.) erhöhen die Komplexität, bieten jedoch mehr Flexibilität und machen diese Lösung meiner Meinung nach effektiver.
Ceph ist viel besser für aktuelle SDB-Kriterien geeignet und scheint mir vielversprechender. Aber das ist meine Meinung, was denkst du?