Übersetzung neuronaler NetzwerkarchitekturenAlgorithmen tiefer neuronaler Netze haben heute große Popularität erlangt, was weitgehend durch die durchdachte Architektur sichergestellt wird. Schauen wir uns die Geschichte ihrer Entwicklung in den letzten Jahren an. Wenn Sie an einer tieferen Analyse interessiert sind, lesen Sie
diese Arbeit .
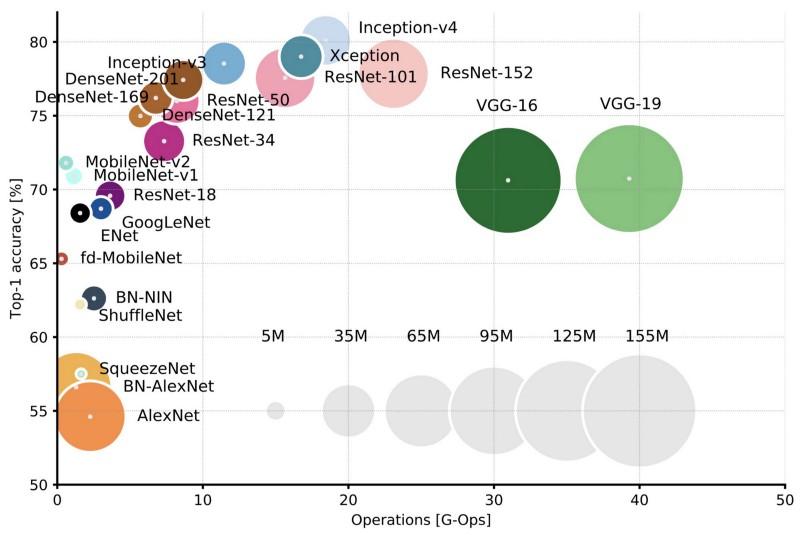 Vergleich gängiger Architekturen für die Top-1-Genauigkeit bei einer Ernte und der Anzahl der für einen direkten Durchgang erforderlichen Vorgänge. Weitere Details hier .
Vergleich gängiger Architekturen für die Top-1-Genauigkeit bei einer Ernte und der Anzahl der für einen direkten Durchgang erforderlichen Vorgänge. Weitere Details hier .Lenet5
1994 wurde eines der ersten Faltungsnetzwerke entwickelt, das den Grundstein für tiefes Lernen legte. Diese Pionierarbeit von Yann LeCun hieß nach vielen erfolgreichen Iterationen seit 1988
LeNet5 !

Die LeNet5-Architektur ist für das Deep Learning von grundlegender Bedeutung, insbesondere im Hinblick auf die Verteilung der Bildeigenschaften im gesamten Bild. Faltungen mit Lernparametern ermöglichten die Verwendung mehrerer Parameter, um dieselben Eigenschaften effizient von verschiedenen Stellen zu extrahieren. In jenen Jahren gab es keine Grafikkarten, die den Lernprozess beschleunigen könnten, und selbst die zentralen Prozessoren waren langsam. Daher war der Hauptvorteil der Architektur die Möglichkeit, Parameter und Berechnungsergebnisse zu speichern, im Gegensatz zur Verwendung jedes Pixels als separate Eingabedaten für ein großes mehrschichtiges neuronales Netzwerk. In LeNet5 werden Pixel in der ersten Ebene nicht verwendet, da Bilder stark räumlich korreliert sind. Wenn Sie also einzelne Pixel als Eingabeeigenschaften verwenden, können Sie diese Korrelationen nicht nutzen.
Funktionen von LeNet5:
- Ein Faltungsnetzwerk, das eine Folge von drei Schichten verwendet: Faltungsschichten, Poolschichten und Nichtlinearitätsschichten -> seit der Veröffentlichung von Lekuns Arbeit ist dies möglicherweise eines der Hauptmerkmale des tiefen Lernens in Bezug auf Bilder.
- Verwendet die Faltung, um räumliche Eigenschaften abzurufen.
- Unterabtastung unter Verwendung der räumlichen Kartenmittelung.
- Nichtlinearität in Form von hyperbolischer Tangente oder Sigmoid.
- Der endgültige Klassifikator in Form eines mehrschichtigen neuronalen Netzwerks (MLP).
- Die spärliche Konnektivitätsmatrix zwischen den Schichten reduziert den Rechenaufwand.
Dieses neuronale Netzwerk bildete die Grundlage vieler nachfolgender Architekturen und inspirierte viele Forscher.
Entwicklung
Von 1998 bis 2010 befanden sich die neuronalen Netze in einem Inkubationszustand. Die meisten Leute bemerkten ihre wachsenden Fähigkeiten nicht, obwohl viele Entwickler ihre Algorithmen schrittweise verfeinerten. Dank der Blütezeit der Handykameras und der Verbilligung der Digitalkameras stehen uns immer mehr Trainingsdaten zur Verfügung. Gleichzeitig wuchsen die Rechenkapazitäten, die Prozessoren wurden leistungsfähiger und Grafikkarten wurden zum Hauptrechner. Alle diese Prozesse ermöglichten die Entwicklung neuronaler Netze, wenn auch eher langsam. Das Interesse an Aufgaben, die mit Hilfe neuronaler Netze gelöst werden konnten, wuchs und schließlich wurde die Situation offensichtlich ...
Dan Ciresan Netz
Im Jahr 2010 veröffentlichten Dan Claudiu Ciresan und Jürgen Schmidhuber eine der ersten Beschreibungen der Implementierung
neuronaler GPU-Netze . Ihre Arbeit beinhaltete die direkte und umgekehrte Implementierung eines 9-lagigen neuronalen Netzwerks auf der
NVIDIA GTX 280 .
Alexnet
Im Jahr 2012 veröffentlichte Alexei Krizhevsky
AlexNet , eine ausführliche und erweiterte Version von LeNet, die im ImageNet-Wettbewerb mit großem Vorsprung gewann.
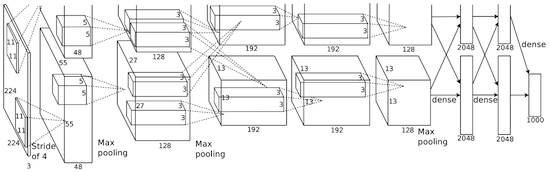
Bei AlexNet werden die Ergebnisse von LeNet-Berechnungen in ein viel größeres neuronales Netzwerk skaliert, das viel komplexere Objekte und ihre Hierarchien untersuchen kann. Merkmale dieser Lösung:
- Verwendung von linearen Gleichrichtungseinheiten (ReLU) als Nichtlinearitäten.
- Die Verwendung von Verwerfungstechniken zum selektiven Ignorieren einzelner Neuronen während des Trainings, wodurch ein Übertraining des Modells vermieden wird.
- Überlappen Sie das maximale Pooling, wodurch die Auswirkungen einer durchschnittlichen durchschnittlichen Poolbildung vermieden werden.
- Verwenden von NVIDIA GTX 580 , um das Lernen zu beschleunigen.
Zu diesem Zeitpunkt war die Anzahl der Kerne in Grafikkarten erheblich gestiegen, wodurch die Trainingszeit um das Zehnfache verkürzt werden konnte. Infolgedessen konnten viel größere Datensätze und Bilder verwendet werden.
Der Erfolg von AlexNet löste eine kleine Revolution aus. Faltungs-Neuronale Netze wurden zu einem Arbeitspferd des tiefen Lernens - dieser Begriff bedeutet jetzt "große Neuronale Netze, die nützliche Probleme lösen können".
Überfeature
Im Dezember 2013 veröffentlichte das NYU-Labor von Jan Lekun eine Beschreibung von
Overfeat , einer Variante von AlexNet. Der Artikel beschrieb auch die trainierten Begrenzungsrahmen, und anschließend wurden viele andere Arbeiten zu diesem Thema veröffentlicht. Wir glauben, dass es besser ist, das Segmentieren von Objekten zu lernen, als künstliche Begrenzungsrahmen zu verwenden.
Vgg
In
VGG- Netzwerken, die in Oxford entwickelt wurden, wurden in jeder Faltungsschicht zum ersten Mal 3 × 3-Filter verwendet, und sogar diese Schichten wurden in einer Folge von Faltungen kombiniert.
Dies widerspricht den in LeNet festgelegten Prinzipien, nach denen große Windungen verwendet wurden, um dieselben Bildeigenschaften zu extrahieren. Anstelle der in AlexNet verwendeten 9x9- und 11x11-Filter wurden viel kleinere Filter verwendet, die gefährlich nahe an 1x1-Windungen lagen und die LeNet-Autoren zumindest in den ersten Schichten des Netzwerks zu vermeiden versuchten. Der große Vorteil von VGG war jedoch die Feststellung, dass mehrere 3x3-Faltungen, die in einer Sequenz kombiniert werden, größere Empfangsfelder emulieren können, beispielsweise 5x5 oder 7x7. Diese Ideen werden später in den Inception- und ResNet-Architekturen verwendet.
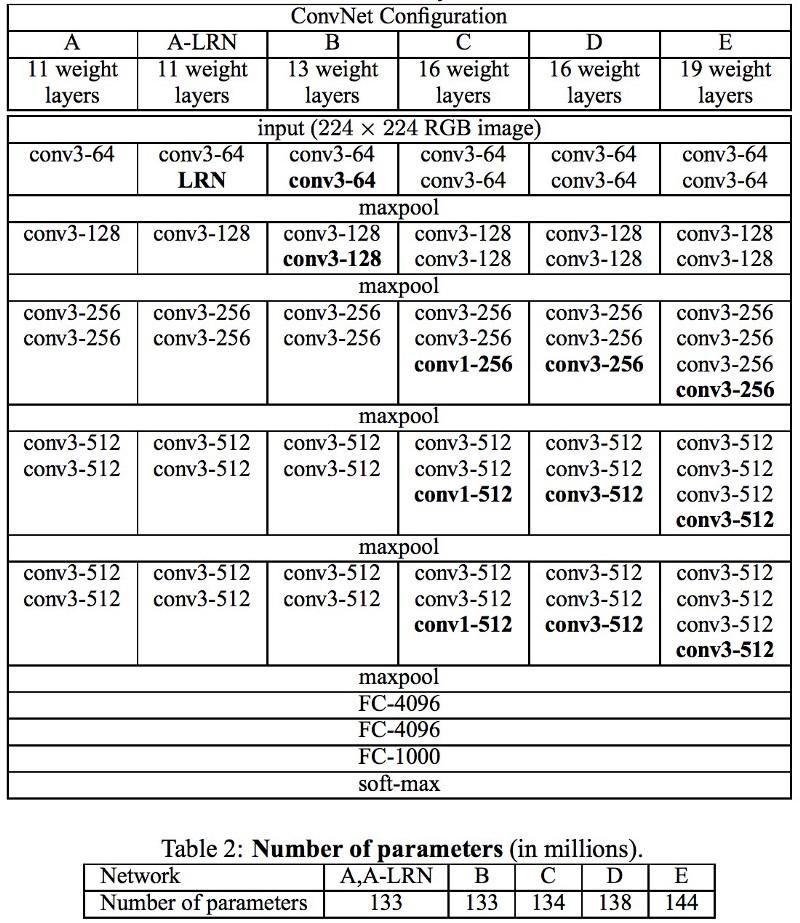
VGG-Netzwerke verwenden mehrere 3x3-Faltungsschichten, um komplexe Eigenschaften darzustellen. Beachten Sie die Blöcke 3, 4 und 5 in VGG-E: Um komplexere Eigenschaften zu extrahieren und zu kombinieren, werden 256 × 256 und 512 × 512 3 × 3 Filtersequenzen verwendet. Dies entspricht einem großen Faltungsklassifikator 512x512 mit drei Schichten! Dies gibt uns eine Vielzahl von Parametern und hervorragende Lernfähigkeiten. Aber es war schwierig, solche Netzwerke zu lernen, ich musste sie in kleinere aufteilen und Schichten nacheinander hinzufügen. Der Grund war das Fehlen effektiver Methoden zur Regularisierung von Modellen oder einiger Methoden zur Begrenzung eines großen Suchraums, was durch viele Parameter gefördert wird.
VGG verwendet in vielen Schichten eine große Anzahl von Eigenschaften, so dass das Training
rechenintensiv war . Die Last kann reduziert werden, indem die Anzahl der Eigenschaften verringert wird, wie dies in den Engpassschichten der Inception-Architektur der Fall ist.
Netzwerk im Netzwerk
Die
Network-in-Network- Architektur (NiN) basiert auf einer einfachen Idee: Verwendung von 1x1-Faltungen zur Erhöhung der Kombinatorialität von Eigenschaften in Faltungsschichten.
In NiN werden nach jeder Faltung räumliche MLP-Schichten verwendet, um die Eigenschaften besser zu kombinieren, bevor sie der nächsten Schicht zugeführt werden. Es mag den Anschein haben, dass die Verwendung von 1x1-Faltungen den ursprünglichen LeNet-Prinzipien widerspricht, aber in Wirklichkeit können Eigenschaften besser kombiniert werden, als nur mehr Faltungsschichten zu füllen. Dieser Ansatz unterscheidet sich von der Verwendung von bloßen Pixeln als Eingabe für die nächste Ebene. In diesem Fall werden 1x1-Faltungen für die räumliche Kombination von Eigenschaften nach der Faltung im Rahmen von Eigenschaftskarten verwendet, sodass Sie viel weniger Parameter verwenden können, die allen Pixeln dieser Eigenschaften gemeinsam sind!
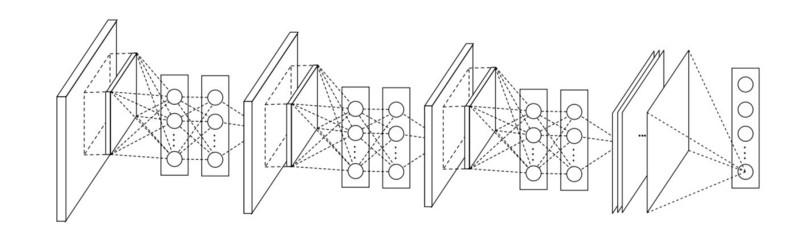
MLP kann die Wirksamkeit einzelner Faltungsschichten erheblich steigern, indem sie zu komplexeren Gruppen zusammengefasst werden. Diese Idee wurde später in anderen Architekturen wie ResNet, Inception und deren Varianten verwendet.
GoogLeNet und Inception
Google Christian Szegedy ist besorgt darüber, die Berechnungen in tiefen neuronalen Netzen zu
verringern, und hat daher
GoogLeNet erstellt, die erste Inception-Architektur .
Bis zum Herbst 2014 waren Deep-Learning-Modelle sehr nützlich, um Bildinhalte und Frames aus Videos zu kategorisieren. Viele Skeptiker haben die Vorteile von Deep Learning und neuronalen Netzwerken erkannt, und Internetgiganten, einschließlich Google, sind sehr daran interessiert, effiziente und große Netzwerke auf ihren Serverkapazitäten bereitzustellen.
Christian suchte nach Möglichkeiten, die Rechenlast in neuronalen Netzen zu reduzieren und die höchste Leistung zu erzielen (z. B. in ImageNet). Oder den Rechenaufwand beibehalten, aber dennoch die Produktivität steigern.
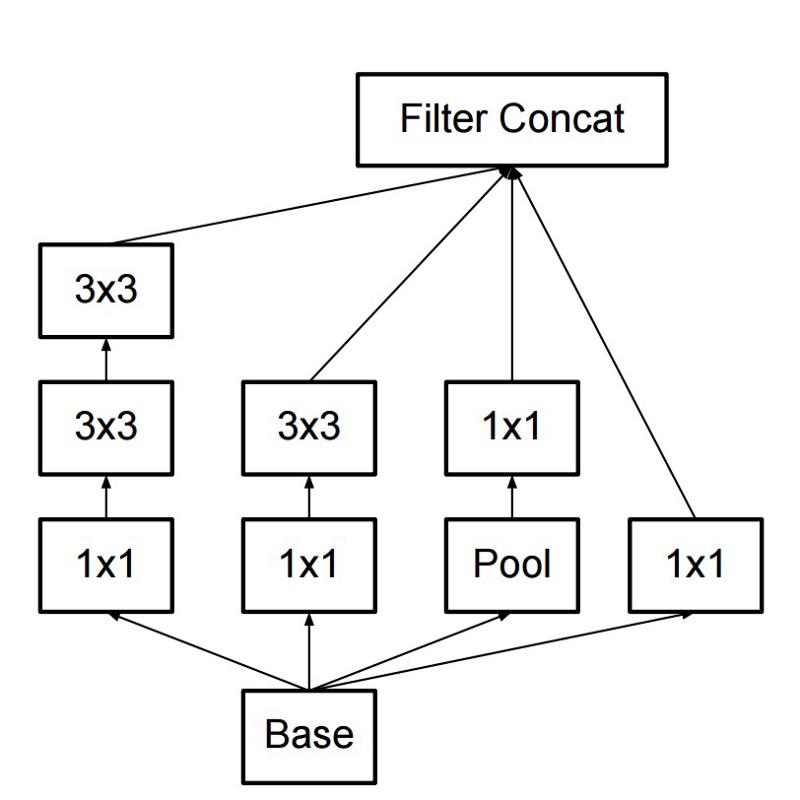
Infolgedessen hat der Befehl ein Inception-Modul erstellt:

Auf den ersten Blick ist dies eine parallele Kombination der Faltungsfilter 1x1, 3x3 und 5x5. Das Highlight war jedoch die Verwendung von Faltungsblöcken 1x1 (NiN), um die Anzahl der Eigenschaften vor dem Servieren in den "teuren" parallelen Blöcken zu verringern. Normalerweise wird dieser Teil als Engpass bezeichnet. Er wird im nächsten Kapitel ausführlicher beschrieben.
GoogLeNet verwendet einen Stamm ohne Inception-Module als erste Schicht und verwendet außerdem ein durchschnittliches Pooling und einen Softmax-Klassifikator ähnlich wie NiN. Dieser Klassifikator führt im Vergleich zu AlexNet und VGG äußerst wenige Operationen aus. Es hat auch dazu beigetragen, eine
sehr effiziente neuronale Netzwerkarchitektur zu erstellen.
Engpassschicht
Diese Schicht reduziert die Anzahl der Eigenschaften (und damit der Operationen) in jeder Schicht, so dass die Geschwindigkeit, mit der das Ergebnis erhalten wird, auf einem hohen Niveau gehalten werden kann. Vor der Übertragung von Daten an „teure“ Faltungsmodule wird die Anzahl der Eigenschaften beispielsweise um das Vierfache reduziert. Dies reduziert den Rechenaufwand erheblich, was die Architektur populär gemacht hat.
Lass es uns herausfinden. Angenommen, wir haben 256 Eigenschaften am Eingang und 256 am Ausgang und lassen die Inception-Ebene nur 3x3-Faltungen ausführen. Wir erhalten 256 x 256 x 3 x 3 Faltungen (589.000 Operationen der Akkumulationsmultiplikation, dh MAC-Operationen). Dies kann über unsere Anforderungen an die Rechengeschwindigkeit hinausgehen. Nehmen wir an, eine Ebene wird in 0,5 Millisekunden auf Google Server verarbeitet. Reduzieren Sie dann die Anzahl der Eigenschaften für das Falten auf 64 (256/4). In diesem Fall führen wir zuerst eine 1x1-Faltung von 256 -> 64, dann eine weitere 64-Faltung in allen Inception-Zweigen durch und wenden dann erneut eine 1x1-Faltung von 64 -> 256 Eigenschaften an. Anzahl der Operationen:
- 256 × 64 × 1 × 1 = 16.000
- 64 × 64 × 3 × 3 = 36.000
- 64 × 256 × 1 × 1 = 16.000
Nur etwa 70.000, reduzierte die Anzahl der Operationen um fast das Zehnfache! Gleichzeitig haben wir die Verallgemeinerung in dieser Ebene nicht verloren. Engpass-Layer haben im ImageNet-Dataset eine hervorragende Leistung gezeigt und wurden in späteren Architekturen wie ResNet verwendet. Der Grund für ihren Erfolg ist, dass die Eingabeeigenschaften korreliert sind. Dies bedeutet, dass Sie Redundanz beseitigen können, indem Sie Eigenschaften korrekt mit 1x1-Faltungen kombinieren. Und nachdem Sie mit weniger Eigenschaften gefaltet haben, können Sie sie auf der nächsten Ebene wieder in einer signifikanten Kombination bereitstellen.
Inception V3 (und V2)
Christian und sein Team haben sich als sehr effektive Forscher erwiesen. Im Februar 2015 wurde die
Batch-normalisierte Inception- Architektur als zweite Version von
Inception eingeführt . Die Chargennormalisierung berechnet den Mittelwert und die Standardabweichung aller Eigenschaftsverteilungskarten in der Ausgabeebene und normalisiert ihre Antworten mit diesen Werten. Dies entspricht dem "Aufhellen" der Daten, dh die Antworten aller neuronalen Karten liegen im gleichen Bereich und mit einem Mittelwert von Null. Dieser Ansatz erleichtert das Lernen, da die nächste Ebene keine Offsets von Eingabedaten speichern muss und nur nach den besten Kombinationen von Eigenschaften suchen kann.
Im Dezember 2015 wurde eine
neue Version der Inception-Module und der entsprechenden Architektur veröffentlicht . Der Artikel des Autors erklärt die ursprüngliche GoogLeNet-Architektur besser, die viel mehr über die getroffenen Entscheidungen erzählt. Schlüsselideen:
- Maximierung des Informationsflusses im Netzwerk aufgrund des sorgfältigen Gleichgewichts zwischen Tiefe und Breite. Vor jedem Pooling werden die Eigenschaftskarten erhöht.
- Mit zunehmender Tiefe nimmt auch die Anzahl der Eigenschaften oder die Schichtbreite systematisch zu.
- Die Breite jeder Schicht nimmt zu, um die Kombination der Eigenschaften vor der nächsten Schicht zu erhöhen.
- Soweit möglich werden nur 3x3 Windungen verwendet. Vorausgesetzt, dass 5x5- und 7x7-Filter mit mehreren 3x3-Filtern zerlegt werden können
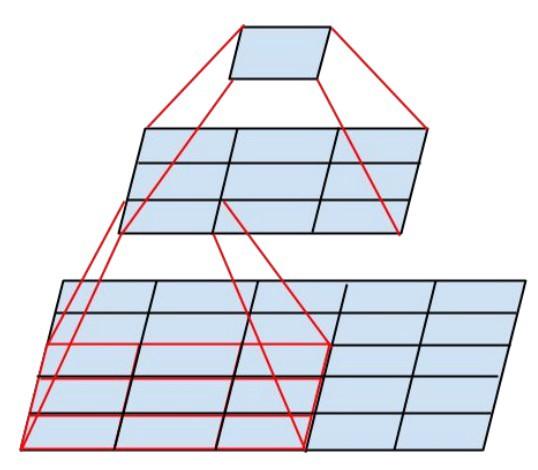
Das neue Inception-Modul sieht folgendermaßen aus:
- Filter können auch durch geglättete Windungen in komplexere Module zerlegt werden:

- Inception-Module können die Datengröße mithilfe von Pooling während Inception-Berechnungen reduzieren. Dies ähnelt der Durchführung einer Faltung mit Schritten parallel zu einer einfachen Pooling-Schicht:

Inception verwendet die Pooling-Ebene mit Softmax als endgültigen Klassifikator.
Resnet
Im Dezember 2015, ungefähr zur gleichen Zeit, als die Inception v3-Architektur eingeführt wurde, kam es zu einer Revolution - sie veröffentlichten
ResNet . Es enthält einfache Ideen: Senden Sie die Ausgabe von zwei erfolgreichen Faltungsebenen und umgehen Sie die Eingabe für die nächste Ebene!

Solche Ideen wurden beispielsweise
hier bereits vorgeschlagen. In diesem Fall umgehen die Autoren jedoch ZWEI Ebenen und wenden den Ansatz in großem Maßstab an. Das Umgehen einer Schicht bringt nicht viel, und das Umgehen von zwei ist eine wichtige Erkenntnis. Dies kann als kleiner Klassifikator angesehen werden, als Netzwerk-in-Netzwerk!
Es war auch das erste Beispiel für das Training eines Netzwerks aus mehreren hundert oder sogar Tausenden von Schichten.
Multilayer ResNet verwendete eine Engpassschicht ähnlich der in Inception:

Diese Schicht reduziert die Anzahl der Eigenschaften in jeder Schicht, indem zuerst eine 1x1-Faltung mit einer kleineren Ausgabe (normalerweise ein Viertel der Eingabe), dann eine 3x3-Schicht und dann erneut eine 1x1-Faltung auf eine größere Anzahl von Eigenschaften verwendet wird. Wie bei Inception-Modulen werden hierdurch Rechenressourcen eingespart und gleichzeitig eine Vielzahl von Eigenschaftskombinationen beibehalten. Vergleichen Sie mit den komplexeren und weniger offensichtlichen Stämmen in Inception V3 und V4.
ResNet verwendet eine Pooling-Schicht mit Softmax als endgültigem Klassifikator.
Jeden Tag werden zusätzliche Informationen zur ResNet-Architektur angezeigt:
- Es kann als ein System von gleichzeitig parallelen und seriellen Modulen betrachtet werden: In vielen Modulen kommt das Inout-Signal parallel und die Ausgangssignale jedes Moduls sind in Reihe geschaltet.
- ResNet kann als mehrere Ensembles paralleler oder serieller Module betrachtet werden .
- Es stellte sich heraus, dass ResNet normalerweise mit relativ kleinen Tiefenblöcken von 20 bis 30 Schichten arbeitet, die parallel arbeiten, anstatt nacheinander über die gesamte Länge des Netzwerks zu laufen.
- Da das Ausgangssignal zurückkommt und wie in RNN als Eingang eingespeist wird, kann ResNet als verbessertes plausibles Modell der Großhirnrinde angesehen werden .
Inception V4
Christian und sein Team haben sich mit einer
neuen Version von Inception erneut hervorgetan .
Das folgende Stammmodul des Inception-Moduls ist das gleiche wie in Inception V3:

In diesem Fall wird das Inception-Modul mit dem ResNet-Modul kombiniert:

Diese Architektur erwies sich nach meinem Geschmack als komplizierter, weniger elegant und auch voller undurchsichtiger heuristischer Lösungen. Es ist schwer zu verstehen, warum die Autoren diese oder jene Entscheidungen getroffen haben, und es ist ebenso schwierig, ihnen irgendeine Art von Bewertung zu geben.
Daher geht der Preis für ein sauberes und einfaches neuronales Netzwerk, das leicht zu verstehen und zu ändern ist, an ResNet.
Squeezenet
SqueezeNet wurde kürzlich veröffentlicht. Dies ist ein neues Remake vieler Konzepte von ResNet und Inception. Die Autoren haben gezeigt, dass die Verbesserung der Architektur die Netzwerkgröße und die Anzahl der Parameter ohne komplexe Komprimierungsalgorithmen reduziert.
ENet
Alle Funktionen der neuesten Architekturen werden zu einem sehr effizienten und kompakten Netzwerk kombiniert, das nur sehr wenige Parameter und Rechenleistung verwendet und gleichzeitig hervorragende Ergebnisse liefert. Die Architektur hieß
ENet und wurde von Adam Paszke (
Adam Paszke ) entwickelt. Zum Beispiel haben wir es verwendet, um Objekte auf dem Bildschirm sehr genau zu markieren und Szenen zu analysieren.
Einige Beispiele von Enet . Diese Videos beziehen sich nicht auf den
Trainingsdatensatz .
Technische Details zu ENet finden Sie hier. Es ist ein Netzwerk, das auf Encoder und Decoder basiert. Der Codierer basiert auf dem üblichen CNN-Kategorisierungsschema, und der Decodierer ist ein Upsampling-Netzwerk, das zur Segmentierung durch Zurückstreuen der Kategorien auf das Bild in Originalgröße entwickelt wurde. Für die Bildsegmentierung wurden nur neuronale Netze verwendet, keine anderen Algorithmen.
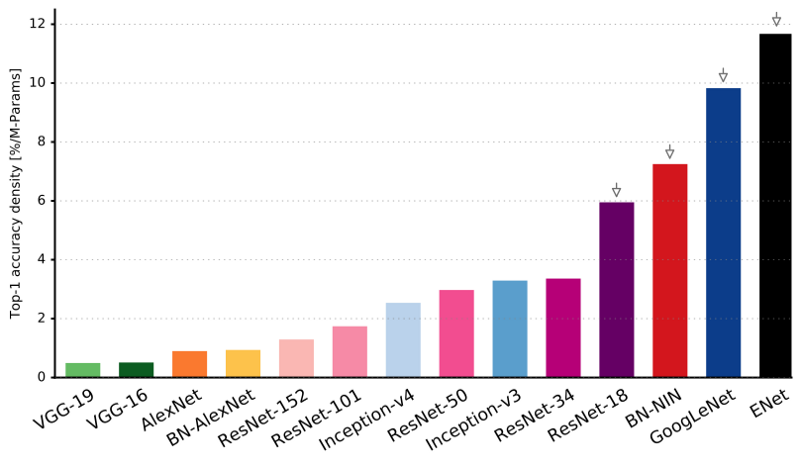
Wie Sie sehen können, weist ENet im Vergleich zu allen anderen neuronalen Netzen die höchste spezifische Genauigkeit auf.
ENet wurde von Anfang an so konzipiert, dass möglichst wenig Ressourcen verwendet werden. Infolgedessen belegen der Codierer und der Decodierer zusammen nur 0,7 MB mit einer Genauigkeit von fp16. Und mit solch einer winzigen Größe ist ENet der Segmentierungsgenauigkeit nicht unterlegen oder anderen rein neuronalen Netzwerklösungen überlegen.
Modulanalyse
Veröffentlichung einer systematischen Bewertung von CNN-Modulen. Es stellte sich als vorteilhaft heraus:
- Verwenden Sie die ELU-Nichtlinearität ohne Batch-Normalisierung (Batchnorm) oder ReLU mit Normalisierung.
- Wenden Sie die gelernte Transformation des RGB-Farbraums an.
- Verwenden Sie eine Richtlinie für den linearen Lernratenabfall.
- Verwenden Sie die Summe der mittleren und maximalen Pooling-Ebene.
- Verwenden Sie ein 128- oder 256-Minipaket. Wenn dies für Ihre Grafikkarte zu viel ist, reduzieren Sie die Lerngeschwindigkeit proportional zur Paketgröße.
- Verwenden Sie vollständig verbundene Schichten als Faltungsschichten und Durchschnittsvorhersagen, um die endgültige Lösung zu erhalten.
- Wenn Sie den Trainingsdatensatz vergrößern, stellen Sie sicher, dass Sie im Training kein Plateau erreicht haben. Datenbereinigung ist wichtiger als Größe.
- Wenn Sie das Eingabebild nicht vergrößern und den Schritt in nachfolgenden Ebenen verringern können, ist der Effekt ungefähr gleich.
- Wenn Ihr Netzwerk wie in GoogLeNet über eine komplexe und hochoptimierte Architektur verfügt, ändern Sie diese mit Vorsicht.
Xception
Xception hat eine einfachere und elegantere Architektur in das Inception-Modul eingeführt, die nicht weniger effizient ist als ResNet und Inception V4.
So sieht das Xception-Modul aus:
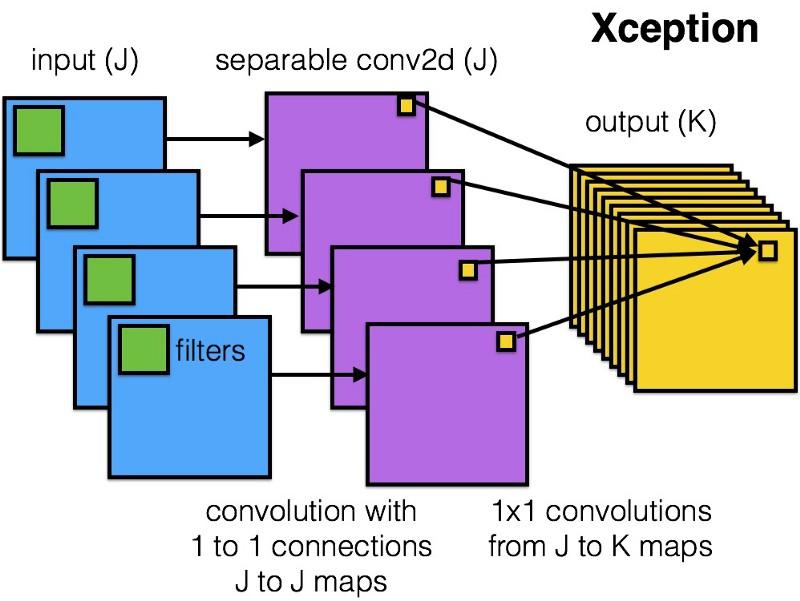
Jeder wird dieses Netzwerk aufgrund der Einfachheit und Eleganz seiner Architektur mögen:

Es enthält 36 Faltungsschritte und ähnelt ResNet-34. Gleichzeitig sind Modell und Code wie in ResNet einfach und viel angenehmer als in Inception V4.
Eine torch7-Implementierung dieses Netzwerks ist
hier verfügbar, während eine Keras / TF-Implementierung hier verfügbar ist.
Seltsamerweise waren die Autoren der jüngsten Xception-Architektur auch von
unserer Arbeit an trennbaren Faltungsfiltern inspiriert.
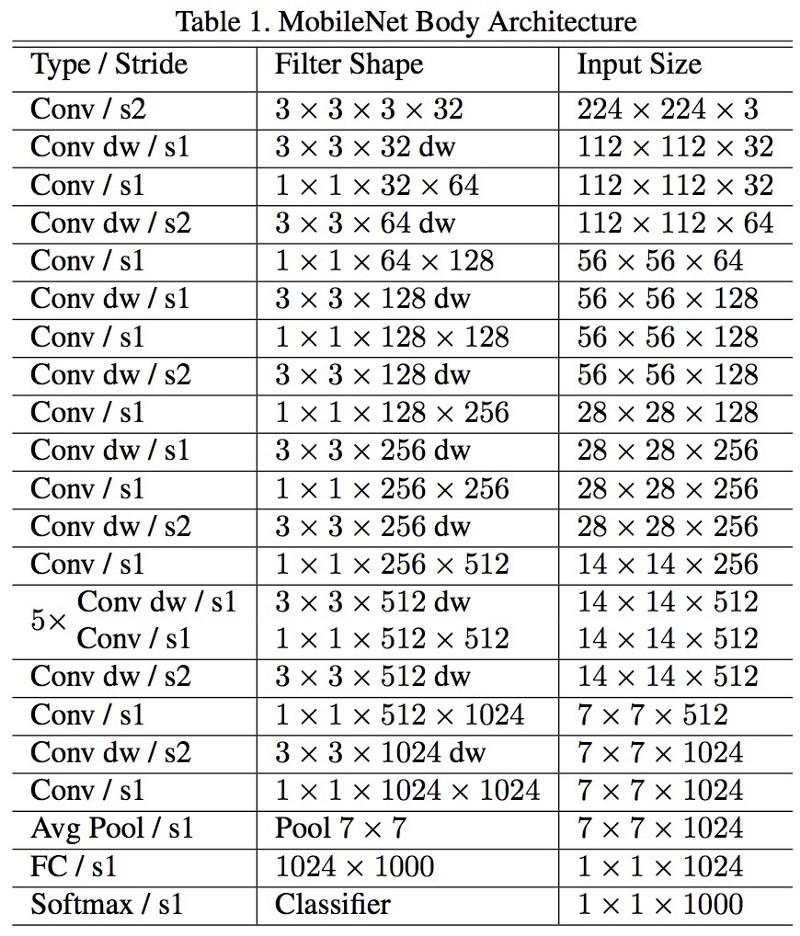
MobileNets
Die neue Architektur von M
obileNets wurde im April 2017 veröffentlicht. Um die Anzahl der Parameter zu verringern, werden abnehmbare Windungen verwendet, wie in Xception. In der Arbeit wird auch festgestellt, dass die Autoren die Anzahl der Parameter stark reduzieren konnten: etwa die Hälfte im Fall von FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.