
Hallo Habr! Vor zwei Jahren haben wir darüber geschrieben, wie wir auf PHP 7.0 umgestiegen sind und eine Million Dollar gespart haben. In unserem Lastprofil erwies sich die neue Version als doppelt so effizient bei der CPU-Auslastung: Die Last, mit der wir ~ 600 Server bedienten, nachdem der Übergang begonnen hatte, ~ 300 zu bedienen. Infolgedessen verfügten wir zwei Jahre lang über Kapazitätsreserven.
Aber Badoo wächst. Die Anzahl der aktiven Benutzer nimmt ständig zu. Wir verbessern und entwickeln unsere Funktionen, dank derer Benutzer immer mehr Zeit in der Anwendung verbringen. Dies spiegelt sich wiederum in der Anzahl der Anfragen wider, die sich in den letzten zwei Jahren um das 2- bis 2,5-fache erhöht haben.
Wir befanden uns in einer Situation, in der ein zweifacher Leistungszuwachs durch mehr als eine zweifache Steigerung der Anforderungen ausgeglichen wurde, und wir näherten uns erneut den Grenzen unseres Clusters. Im Kern von PHP werden wieder nützliche
Optimierungen (JIT, Preloading) erwartet, die jedoch nur für PHP 7.4 geplant sind. Diese Version wird frühestens in einem Jahr veröffentlicht. Daher kann der Übergangstrick jetzt nicht wiederholt werden - Sie müssen den Anwendungscode selbst optimieren.
Im Folgenden werde ich Ihnen erläutern, wie wir solche Aufgaben angehen, welche Tools wir verwenden, und Beispiele für Optimierungen, Ideen und Ansätze nennen, die wir anwenden und die uns in unserer Zeit geholfen haben.
Warum optimieren?
Der einfachste und naheliegendste Weg, um das Leistungsproblem zu lösen, ist das Hinzufügen von Eisen. Wenn Ihr Code auf demselben Server ausgeführt wird, verdoppelt das Hinzufügen eines weiteren die Leistung Ihres Clusters. Wenn wir diese Kosten auf die Arbeitszeit des Entwicklers übertragen, fragen wir uns: Wird er in dieser Zeit aufgrund von Optimierungen eine zweifache Produktivitätssteigerung erzielen können? Vielleicht ja, aber vielleicht auch nicht: Es kommt darauf an, wie optimal das System bereits funktioniert und wie gut der Entwickler ist. Auf der anderen Seite bleibt der gekaufte Server Eigentum des Unternehmens und die aufgewendete Zeit wird nicht zurückgegeben.
Es stellt sich heraus, dass bei kleinen Mengen die richtige Lösung häufig die Zugabe von Eisen ist.
Aber nehmen Sie unsere Situation. Nachdem der Gewinn durch die Umstellung auf PHP 7.0 durch die Zunahme der Aktivität und der Anzahl der Benutzer ausgeglichen wurde, haben wir wieder 600 Server, die Anforderungen an die PHP-Anwendung bedienen. Um die Kapazität um das Eineinhalbfache zu erhöhen, müssen 300 Server hinzugefügt werden.
Berechnen Sie die durchschnittlichen Kosten eines Servers mit 4.000 US-Dollar. 300 * 4000 = 1.200.000 USD - die Kosten für die anderthalbfache Erhöhung der Kapazität.
Das heißt, unter unseren Bedingungen können wir viel Arbeitszeit in die Optimierung des Systems investieren, und es wird immer noch rentabler sein als der Kauf von Eisen.
Kapazitätsplanung
Bevor Sie etwas unternehmen, ist es wichtig zu verstehen, ob ein Problem vorliegt. Wenn sie nicht da ist, lohnt es sich vorherzusagen, wann sie erscheinen wird. Dieser Prozess wird als Kapazitätsplanung bezeichnet.
Ein konkreter Indikator für das Vorhandensein von Leistungsproblemen ist die Reaktionszeit. Schließlich spielt es keine Rolle, ob die CPU (oder andere Ressourcen) zu 6% oder 146% ausgelastet ist: Wenn ein Client in zufriedenstellender Zeit einen Dienst der erforderlichen Qualität erhält, funktioniert alles einwandfrei.
Der Nachteil der Konzentration auf die Reaktionszeit besteht darin, dass sie normalerweise erst dann zunimmt, wenn das Problem bereits aufgetreten ist. Wenn es noch nicht ist, ist es schwierig, sein Aussehen vorherzusagen. Darüber hinaus spiegelt die Reaktionszeit die Ergebnisse des Einflusses aller Faktoren (Bremsdienste, Netzwerk, Antriebe usw.) wider und bietet kein Verständnis für die Ursachen von Problemen.
In unserem Fall ist die CPU normalerweise der Engpass. Bei der Planung der Größe und Leistung von Clustern achten wir daher in erster Linie auf die mit ihrer Verwendung verbundenen Metriken. Wir erfassen die CPU-Auslastung aller unserer Maschinen und erstellen Diagramme mit dem Durchschnittswert, dem Median, dem 75. und 95. Perzentil:
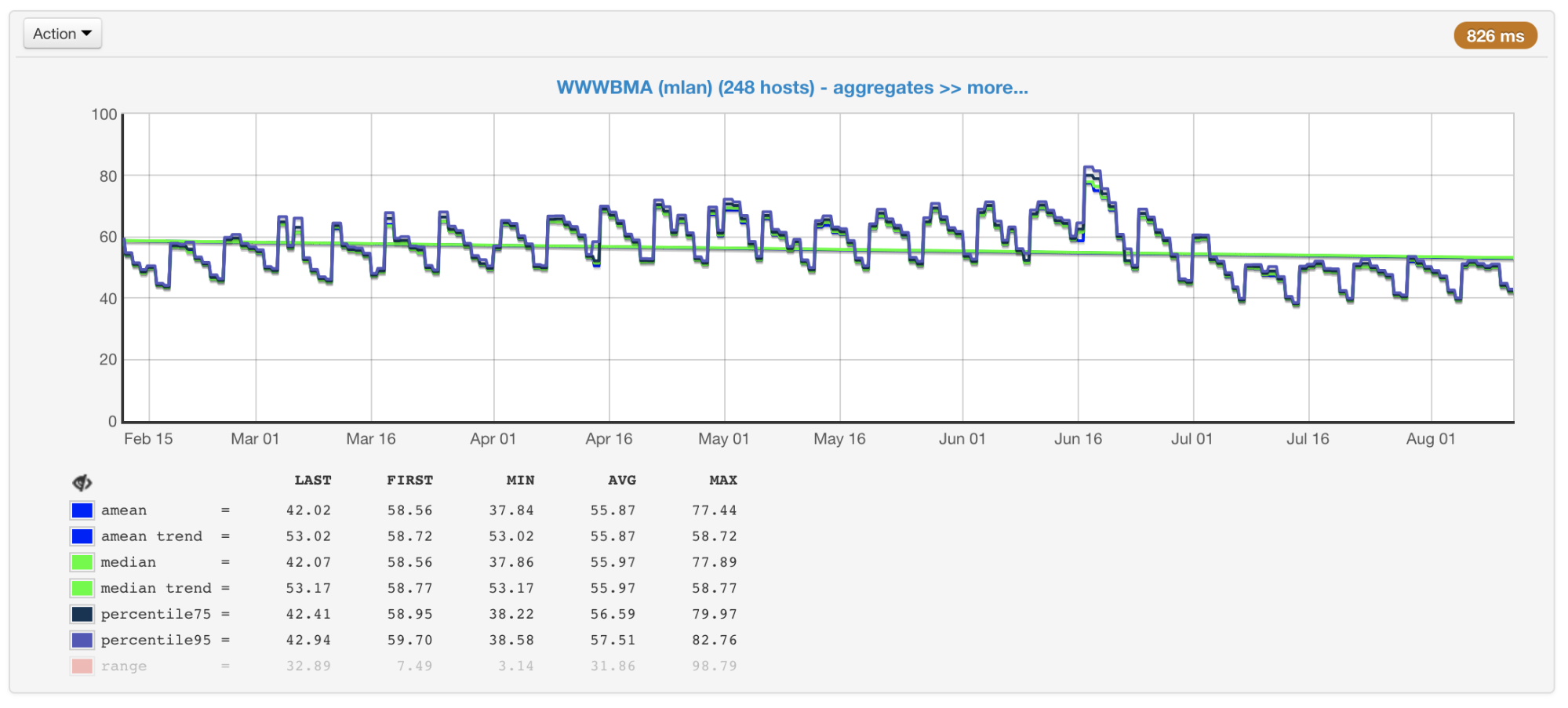 CPU-Auslastung von Cluster-Maschinen in Prozent: Durchschnitt, Median, Perzentile
CPU-Auslastung von Cluster-Maschinen in Prozent: Durchschnitt, Median, PerzentileEs gibt Hunderte von Maschinen in unseren Clustern, die dort seit vielen Jahren hinzugefügt wurden. Sie unterscheiden sich in Konfiguration und Leistung (der Cluster ist nicht homogen). Unser Balancer berücksichtigt dies (
Artikel und
Video ) und lädt die Maschinen entsprechend ihrer Fähigkeiten. Um diesen Prozess zu steuern, haben wir auch einen Zeitplan für maximal und minimal geladene Maschinen.
 Die am meisten und am wenigsten belasteten Cluster-Computer
Die am meisten und am wenigsten belasteten Cluster-ComputerWenn Sie sich diese Diagramme (oder nur die Ausgabe des Befehls top) ansehen und die CPU-Auslastung von 50% sehen, denken Sie, dass wir noch einen Spielraum für eine zweifache Erhöhung der Auslastung haben. Tatsächlich ist dies jedoch normalerweise nicht der Fall. Und hier ist warum.
Hyper-Threading
Stellen Sie sich einen einzelnen Kern ohne Hypertreading vor. Wir laden es mit einem CPU-gebundenen Thread. Oben wird 100% geladen.
Aktivieren Sie nun das Hyperlesen auf diesem Kernel und laden Sie es genauso. Oben sehen wir bereits zwei logische Kerne, und die Gesamtlast beträgt 50% (normalerweise auf einem 0% und auf dem anderen 100%).
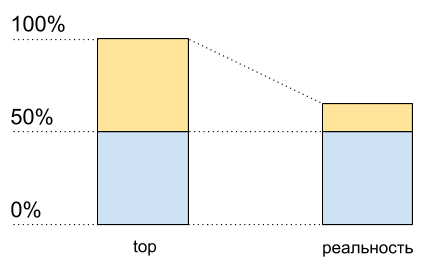 CPU-Auslastung: Top-Daten und was wirklich passiert
CPU-Auslastung: Top-Daten und was wirklich passiertAls ob der Prozessor nur zu 50% ausgelastet wäre. Aber physikalisch erschien kein zusätzlicher freier Kern. Hypertreading ermöglicht
in einigen Fällen die gleichzeitige Ausführung von mehr als einem Prozess auf einem physischen Kern. Dies ist jedoch weit davon entfernt, die Leistung in typischen Situationen zu verdoppeln, obwohl es im Diagramm zur CPU-Auslastung wie die Hälfte der Ressourcen aussieht: von 50% auf 100%.
Dies bedeutet, dass nach 50% der CPU-Auslastung, wenn Hypertreading aktiviert ist, es nicht mehr so wächst wie zuvor.
Ich habe diesen Code geschrieben, um zu demonstrieren (dies ist eine Art synthetischer Fall, in Wirklichkeit werden die Ergebnisse unterschiedlich sein):
Skriptcode<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
Ich habe zwei physische Kerne auf meinem Laptop. Führen Sie diesen Code mit unterschiedlichen Eingabedaten aus, um seine Leistung mit einer unterschiedlichen Anzahl paralleler C-Prozesse zu messen.
Wir zeichnen die Ergebnisse der Starts auf:
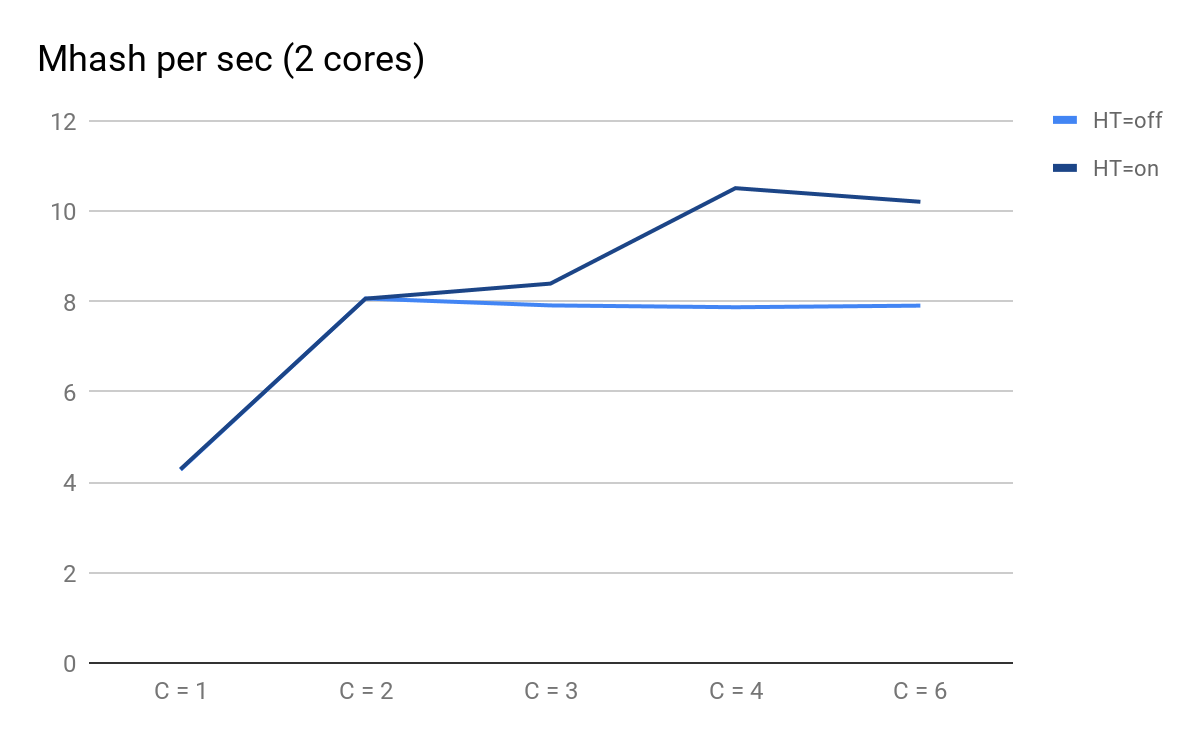 Skriptleistung abhängig von der Anzahl der parallelen Prozesse
Skriptleistung abhängig von der Anzahl der parallelen ProzesseWorauf Sie achten können:
- C = 1 und C = 2 sind vorhersehbar gleich für HT = Ein und HT = Aus. Die Leistung verdoppelt sich, wenn ein physischer Kern hinzugefügt wird.
- Bei C = 3 machen sich die Vorteile von HT bemerkbar: Bei HT = Ein konnten wir zusätzliche Leistung erzielen, während bei HT = Aus ab C = 3 die Vorhersage vorhersehbar langsam abnimmt.
- bei C = 4 sehen wir alle Vorteile von HT; Wir konnten weitere 30% der Produktivität herausholen, aber im Vergleich zu C = 2 zu diesem Zeitpunkt stieg die CPU-Auslastung von 50% auf 100%.
Insgesamt erhalten wir bei der Ausführung dieses Skripts in den oberen 50% der CPU-Auslastung 8.065 Mhash / Sek. Und bei 100% - 10.511 Mhash / Sek. Dies bedeutet, dass wir bei etwa 50% der Spitze 8,065 / 10,511 ~ 77% der maximalen Systemleistung erhalten und tatsächlich noch etwa 100% in der Reserve verbleiben - 77% = 23% und nicht 50%, wie es scheint.
Diese Tatsache muss bei der Planung berücksichtigt werden.
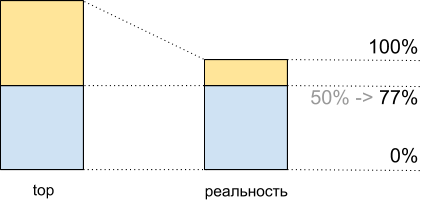 CPU-Auslastung für Demoscript: Top-Daten und was wirklich passiert
CPU-Auslastung für Demoscript: Top-Daten und was wirklich passiertVerkehrsinkonsistenz
Neben dem Hypertreading erschwert die Planung auch die Unebenheiten des Verkehrs in Abhängigkeit von Tageszeit, Wochentag, Jahreszeit und anderer Häufigkeit. Für uns ist der Höhepunkt zum Beispiel Sonntagabend.
 Anzahl der Anfragen pro Sekunde, Spitzen-Sonntagabend
Anzahl der Anfragen pro Sekunde, Spitzen-SonntagabendNicht immer ändert sich die Anzahl der Anfragen auf offensichtliche Weise. Zum Beispiel können Benutzer irgendwie mit anderen Benutzern interagieren: Die Aktivität einiger kann Push / E-Mail an andere generieren und sie somit in den Prozess einbeziehen. Hinzu kommen Werbekampagnen, die den Traffic erhöhen und auf die Sie ebenfalls vorbereitet sein müssen.
All dies ist auch bei der Planung zu berücksichtigen: Zum Beispiel, um einen Trend nach Spitzentagen aufzubauen und die mögliche Nichtlinearität des Spitzenwachstums zu berücksichtigen.
Profilierungs- und Messwerkzeuge
Angenommen, wir stellen fest, dass es Leistungsprobleme gibt, verstehen, dass dies nicht die Datenbank / die Dienste / das Zeug ist, und haben uns dennoch entschlossen, den Code zu optimieren. Dazu benötigen wir zunächst einen Profiler oder einige Tools, um Engpässe zu finden und anschließend die Ergebnisse unserer Optimierungen anzuzeigen.
Leider gibt es für PHP heute kein gutes universelles Tool.
perf
perf ist ein Profiling-Tool, das in den Linux-Kernel integriert ist. Es handelt sich um einen
Stichprobenprofiler , der von einem separaten Prozess gestartet wird. Daher wird dem zu profilierenden Programm kein direkter Overhead hinzugefügt. Indirekt hinzugefügter Overhead wird gleichmäßig „verschmiert“, sodass die Messungen nicht verzerrt werden.
Trotz all seiner Vorteile kann perf nur mit kompiliertem Code und mit JIT arbeiten und nicht mit Code, der "unter einer virtuellen Maschine" ausgeführt wird. Daher kann der PHP-Code selbst nicht profiliert werden, aber Sie können deutlich sehen, wie PHP im Inneren funktioniert, einschließlich verschiedener PHP-Erweiterungen, und wie viel Ressourcen dafür aufgewendet werden.
Zum Beispiel haben wir bei perf mehrere Engpässe festgestellt, einschließlich einer Komprimierungsstelle, auf die ich weiter unten eingehen werde.
Ein Beispiel:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(Wenn der Prozess und perf unter verschiedenen Benutzern ausgeführt werden, muss perf unter sudo ausgeführt werden.)
 Beispiel für die Ausgabe eines Perf-Berichts für PHP-FPM
Beispiel für die Ausgabe eines Perf-Berichts für PHP-FPMXHProf und XHProf Aggregator
XHProf ist eine Erweiterung für PHP, die Timer um alle Aufrufe von Funktionen / Methoden platziert und Tools zur Visualisierung der so erhaltenen Ergebnisse enthält. Im Gegensatz zu perf können Sie damit mit PHP-Code arbeiten (gleichzeitig ist nicht sichtbar, was in den Erweiterungen passiert).
Die Nachteile umfassen zwei Dinge:
- Alle Messungen werden im Rahmen einer einzigen Anfrage gesammelt, daher liefern sie keine Informationen über das Gesamtbild.
- Der Overhead ist zwar nicht so groß wie beispielsweise bei Verwendung von Xdebug, aber er ist und in einigen Fällen sind die Ergebnisse stark verzerrt (je öfter eine Funktion aufgerufen wird und je einfacher sie ist, desto größer ist die Verzerrung).
Hier ist ein Beispiel, das den letzten Punkt veranschaulicht:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
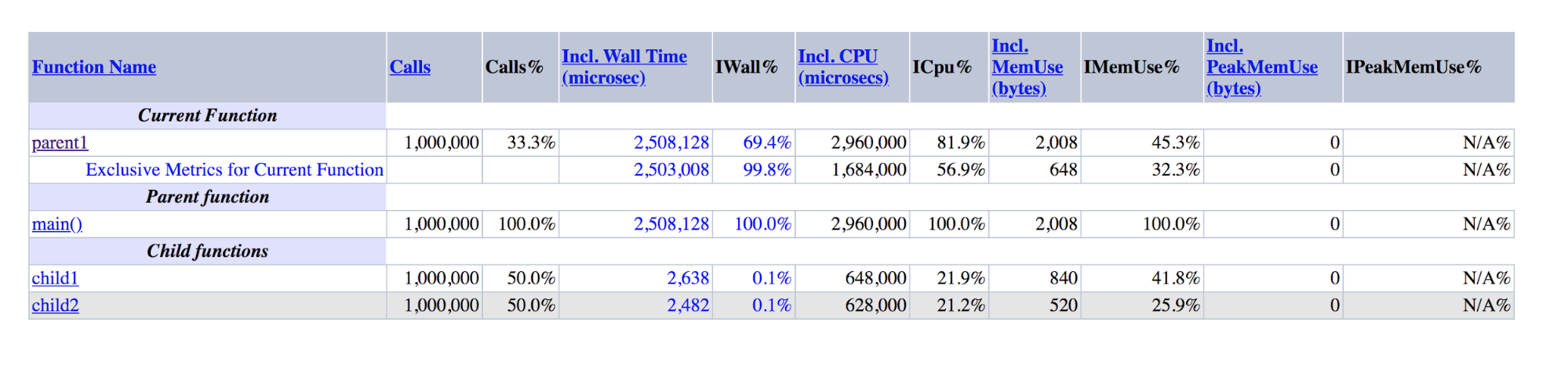 XHProf-Ausgabe für Demos: parent1 ist um Größenordnungen größer als die Summe von child1 und child2
XHProf-Ausgabe für Demos: parent1 ist um Größenordnungen größer als die Summe von child1 und child2Es ist ersichtlich, dass parent1 () ~ 500-mal länger ausgeführt wurde als child1 () + child2 (), obwohl diese Zahlen in Wirklichkeit ungefähr gleich sein sollten, ebenso wie main () und parent1 ().
Wenn der letzte Nachteil schwer zu bekämpfen ist, haben wir zur Bekämpfung des ersten einen Zusatz für XHProf erstellt, der die Profile verschiedener Anforderungen aggregiert und aggregierte Daten visualisiert.
Neben XHProf gibt es viele andere weniger bekannte Profiler, die nach einem ähnlichen Prinzip arbeiten. Sie haben ähnliche Vor- und Nachteile.
Pinba
Mit Pinba können Sie
die Leistung anhand von Skripten (Aktionen) und voreingestellten Timern
überwachen . Alle Messungen im Rahmen von Skripten werden sofort durchgeführt, hierfür sind keine zusätzlichen Schritte erforderlich. Für jedes Skript und jeden Timer wird
getrusage ausgeführt , sodass wir genau wissen, wie viel Prozessorzeit für einen bestimmten Code aufgewendet wurde (im Gegensatz zu Stichprobenprofilern, bei denen sich diese Zeit möglicherweise als Netzwerk, Festplatte usw. herausstellt). Pinba eignet sich hervorragend zum Speichern historischer Daten und zum Abrufen eines Bildes im Allgemeinen und innerhalb bestimmter Arten von Abfragen.
 Die allgemeine Auswahl aller von Pinba erhaltenen Skripte
Die allgemeine Auswahl aller von Pinba erhaltenen SkripteZu den Nachteilen gehören die Tatsache, dass Timer, die bestimmte Abschnitte des Codes und nicht die gesamten Skripte profilieren, im Voraus im Code angeordnet werden müssen, sowie das Vorhandensein eines Overheads, der (wie in XHProf) Daten verzerren kann.
phpspy
phpspy ist ein relativ neues Projekt (das erste Commit auf GitHub war vor einem halben Jahr), das vielversprechend aussieht, daher beobachten wir es genau.
Aus Sicht des Benutzers ähnelt phpspy perf: Es wird ein paralleler Prozess gestartet, der die Speicherteile des PHP-Prozesses regelmäßig kopiert, analysiert und von dort Stapelspuren und andere Daten empfängt. Dies geschieht auf eine ziemlich spezifische Art und Weise. Um den Overhead zu minimieren, stoppt phpspy den PHP-Prozess nicht und kopiert den Speicher direkt, während er ausgeführt wird. Dies führt dazu, dass der Profiler einen inkonsistenten Status erhalten kann und Stapelspuren beschädigt werden können. Aber phpspy kann dies erkennen und solche Daten verwerfen.
Mit diesem Tool können künftig sowohl Daten zum Gesamtbild als auch Profile bestimmter Abfragetypen erfasst werden.
Vergleichstabelle
Um die Unterschiede zwischen den Werkzeugen zu strukturieren, erstellen wir eine Pivot-Tabelle:
 Vergleich der Hauptmerkmale von ProfilernFlammengraphen
Vergleich der Hauptmerkmale von ProfilernFlammengraphenOptimierung und Ansätze
Mit diesen Tools überwachen wir ständig die Leistung und Nutzung unserer Ressourcen. Wenn sie ungerechtfertigt verwendet werden oder wir uns dem Schwellenwert nähern (für die CPU haben wir empirisch einen Wert von 55% gewählt, um im Falle eines Wachstums eine Zeitspanne zu haben), wie ich oben geschrieben habe, ist eine der Lösungen für das Problem die Optimierung.
Nun, wenn die Optimierung bereits von jemand anderem durchgeführt wurde, wie dies bei PHP 7.0 der Fall war, stellte sich heraus, dass diese Version viel produktiver war als die vorherigen. Wir versuchen im Allgemeinen, moderne Technologien und Tools zu verwenden, einschließlich zeitnaher Updates auf die neuesten Versionen von PHP. Laut
öffentlichen Benchmarks ist PHP 7.2 5-12% schneller als PHP 7.1. Aber dieser Übergang gab uns leider viel weniger.
Für die ganze Zeit haben wir eine Vielzahl von Optimierungen implementiert. Leider hängen die meisten von ihnen stark mit unserer Geschäftslogik zusammen. Ich werde über diejenigen sprechen, die nicht nur für uns relevant sein können, oder über Ideen und Ansätze, die außerhalb unseres Codes verwendet werden können.
Zlib-Komprimierung => zstd
Wir verwenden die Komprimierung für große Memkey-Schlüssel. Dies ermöglicht es uns, drei- bis viermal weniger Speicher für Speicher zu verwenden, da zusätzliche CPU-Kosten für die Komprimierung / Dekomprimierung anfallen. Wir haben dafür zlib verwendet (unsere Erweiterung für die Arbeit mit Memekes unterscheidet sich von der mit PHP, aber offizielle verwenden
auch zlib).
In der Perfektion war die Produktion ungefähr so:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7-8% der Zeit wurden für die Komprimierung / Dekomprimierung aufgewendet.
Wir haben uns entschlossen, verschiedene Ebenen und Komprimierungsalgorithmen zu testen. Es stellte sich heraus, dass zstd auf unseren Daten fast zehnmal schneller läuft und ~ 1,1-mal an Ort und Stelle verliert. Eine ziemlich einfache Änderung des Algorithmus hat uns ~ 7,5% CPU gespart (dies entspricht, wie ich mich erinnere, auf unseren Volumes ~ 45 Servern).
Es ist wichtig zu verstehen, dass das Verhältnis der Leistung verschiedener Komprimierungsalgorithmen in Abhängigkeit von den Eingabedaten stark variieren kann. Es gibt verschiedene
Vergleiche , aber am genauesten kann dies nur anhand von Beispielen aus der Praxis geschätzt werden.
IS_ARRAY_IMMUTABLE als Repository selten geänderter Daten
Wenn Sie mit realen Aufgaben arbeiten, müssen Sie mit solchen Daten umgehen, die Sie häufig benötigen und gleichzeitig selten ändern und eine begrenzte Größe haben. Wir haben viele ähnliche Daten, ein gutes Beispiel ist die Konfiguration von
Split-Tests . Wir prüfen, ob der Benutzer unter die Bedingungen eines bestimmten Tests fällt, und zeigen ihm abhängig davon experimentelle oder normale Funktionen (dies geschieht fast bei jeder Anforderung). In anderen Projekten können Konfigurationen und verschiedene Verzeichnisse ein Beispiel sein: Länder, Städte, Sprachen, Kategorien, Marken usw.
Da solche Daten häufig angefordert werden, kann ihr Empfang sowohl für die Anwendung selbst als auch für den Dienst, in dem diese Daten gespeichert sind, eine spürbare zusätzliche Belastung darstellen. Das letztere Problem kann beispielsweise mit APCu gelöst werden, das den Speicher desselben Computers verwendet, auf dem PHP-FPM als Speicher ausgeführt wird. Aber auch dann:
- Es fallen Serialisierungs- / Deserialisierungskosten an.
- Sie müssen die Daten beim Ändern irgendwie ungültig machen.
- Es gibt einen gewissen Overhead im Vergleich zum Zugriff auf nur eine Variable in PHP.
PHP 7.0 führt die
IS_ARRAY_IMMUTABLE- Optimierung ein. Wenn Sie ein Array deklarieren, dessen Elemente zum Zeitpunkt der Kompilierung bekannt sind, wird es einmal verarbeitet und in den OPCache-Speicher gestellt. PHP-FPM-Mitarbeiter verweisen auf diesen gemeinsam genutzten Speicher, ohne ihre Zeit zu verbringen, bevor sie versuchen, Änderungen vorzunehmen. Daraus folgt auch, dass das Einschließen eines solchen Arrays unabhängig von der Größe eine konstante Zeit benötigt (normalerweise ~ 1 Mikrosekunde).
Zum Vergleich: Ein Beispiel für die Zeit, um ein Array mit 10.000 Elementen über include und apcu_fetch abzurufen:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
Die Überprüfung, ob diese Optimierung angewendet wurde, kann sehr einfach sein, wenn Sie sich die generierten Opcodes ansehen:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
Im ersten Fall ist klar, dass die Datei nur einen Opcode enthält - die Rückgabe des fertigen Arrays. Im zweiten Fall erfolgt die Element-für-Element-Bildung jedes Mal, wenn diese Datei ausgeführt wird.
Somit ist es möglich, Strukturen in einer Form zu generieren, die keine weitere Transformation zur Laufzeit erfordert. Anstatt beispielsweise die Klassennamen jedes Mal für das automatische Laden durch die Zeichen "_" und "\" zu zerlegen, können Sie die Korrespondenzzuordnung "Klasse => Pfad" vorab generieren. In diesem Fall wird die Konvertierungsfunktion auf einen einzelnen Hash-Tabellenaufruf reduziert. Composer führt diese Art der Optimierung durch, wenn Sie die
Option "Autoloader optimieren" aktivieren.
Für die Ungültigmachung solcher Daten müssen Sie nichts Spezielles tun. PHP selbst kompiliert die Datei beim Ändern neu, genau wie bei einer normalen Codebereitstellung. Der einzige Nachteil, den Sie nicht vergessen dürfen: Wenn die Datei sehr groß ist, führt die erste Anforderung nach dem Ändern zu einer Neukompilierung, die eine spürbare Zeit in Anspruch nehmen kann.
Leistung umfassen / erfordern
Im Gegensatz zum statischen Array-Beispiel ist das Anhängen von Dateien mit Klassen- und Funktionsdeklarationen nicht so schnell. Trotz des Vorhandenseins von OPCache muss die PHP-Engine sie in den Prozessspeicher kopieren und Abhängigkeiten rekursiv verbinden, was am Ende Hunderte von Mikrosekunden oder sogar Millisekunden pro Datei dauern kann.
Wenn Sie in
Symfony 4.1 ein neues leeres Projekt erstellen und
get_included_files () als erste Zeile in die Aktion
einfügen , sehen Sie, dass bereits 310 Dateien verbunden sind. In einem realen Projekt kann diese Anzahl Tausende pro Anfrage erreichen. Es lohnt sich, auf folgende Dinge zu achten.
Fehlende automatische LadefunktionenEs gibt
Function Autoloading RFC , aber seit einigen Jahren ist keine Entwicklung mehr zu beobachten. Wenn eine Abhängigkeit in Composer Funktionen außerhalb der Klasse definiert und diese Funktionen für den Benutzer zugänglich sein sollten, erfolgt dies durch
obligatorisches Verbinden einer Datei mit diesen Funktionen mit jeder Initialisierung des Autoloaders.
Wenn Sie beispielsweise eine der Abhängigkeiten aus composer.json entfernen, die viele Funktionen deklariert und leicht durch hundert Codezeilen ersetzt werden kann, haben wir ein paar Prozent der CPU gewonnen.
Der Auto-Loader wird häufiger aufgerufen, als es den Anschein hat.Erstellen Sie eine solche Datei mit einer Klasse, um die Idee zu demonstrieren:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
Auto-Loader registrieren: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
Und wir werden mehrere Anwendungsfälle für diese Klasse machen: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
Möglicherweise stellen Sie fest, dass, wenn wir die Klasse nur irgendwie verbinden, aber ihre Instanz nicht erstellen, die übergeordneten Elemente, Schnittstellen und Merkmale miteinander verbunden werden. Dies erfolgt rekursiv für alle Dateien, die als Auflösungen verbunden sind.
Beim Erstellen einer Instanz wird die Auflösung aller Konstanten und Felder hinzugefügt, was zur Verbindung aller dafür erforderlichen Dateien führt, was wiederum auch die rekursive Verbindung von Merkmalen, Eltern und Schnittstellen der neu verbundenen Klassen bewirkt.
 Verbinden verwandter Klassen für den Instanzerstellungsprozess und andere Fälle
Verbinden verwandter Klassen für den Instanzerstellungsprozess und andere FälleEs gibt keine universelle Lösung für dieses Problem. Sie müssen nur daran denken und die Verbindungen zwischen Klassen überwachen: Eine Zeile kann die Verbindung von Hunderten von Dateien herstellen.
OPCache-EinstellungenWenn Sie die
atomare Bereitstellungsmethode verwenden,
indem Sie den von Rasmus Lerdorf, dem Ersteller von PHP, vorgeschlagenen Symlink ändern, müssen Sie opcache.revalidate_path einschließen,
um das Problem des "Festhaltens" des Symlinks an der alten Version zu lösen, wie beispielsweise in diesem von Mail übersetzten
Artikel über OPCache empfohlen .Ru Group.
Das Problem ist, dass diese Option die Zeit für das Einschließen jeder Datei erheblich verlängert (durchschnittlich eineinhalb bis zwei Mal). Insgesamt kann dies eine erhebliche Menge an Ressourcen verbrauchen (in unserem Fall ergab das Deaktivieren dieser Option einen Gewinn von 7–9%).
Um es zu deaktivieren, müssen Sie zwei Dinge tun:
- Lassen Sie den Webserver Symlinks auflösen.
- Beenden Sie die Verbindung von Dateien innerhalb des PHP-Skripts entlang der Pfade, die Symlinks enthalten, oder erzwingen Sie sie über readlink () oder realpath ().
Wenn alle Dateien mit dem Composer-Autoloader verbunden sind, wird das zweite Element automatisch ausgeführt, nachdem das erste abgeschlossen ist: composer verwendet die Konstante __DIR__, die korrekt aufgelöst wird.
OPCache bietet einige weitere Optionen, die im Austausch für Flexibilität zu einer Leistungssteigerung führen können. Sie können mehr darüber in dem
Artikel lesen, den ich oben erwähnt habe.
Trotz all dieser Optimierungen ist include immer noch nicht kostenlos. Um dem entgegenzuwirken, plant PHP 7.4 das Hinzufügen von
Preload .
APCu-Sperre
Obwohl es sich hier nicht um Datenbanken und Dienste handelt, können im Code auch verschiedene Arten von Sperren auftreten, die die Ausführungszeit des Skripts verlängern.
Als die Anfragen wuchsen, stellten wir zu Spitzenzeiten eine starke Verlangsamung der Reaktion fest. Nachdem die Gründe herausgefunden wurden, stellte sich heraus, dass APCu zwar der schnellste Weg ist, um Daten zu erhalten (im Vergleich zu Memcache, Redis und anderen externen Speichern), aber auch langsam arbeiten kann, wenn dieselben Schlüssel häufig überschrieben werden.
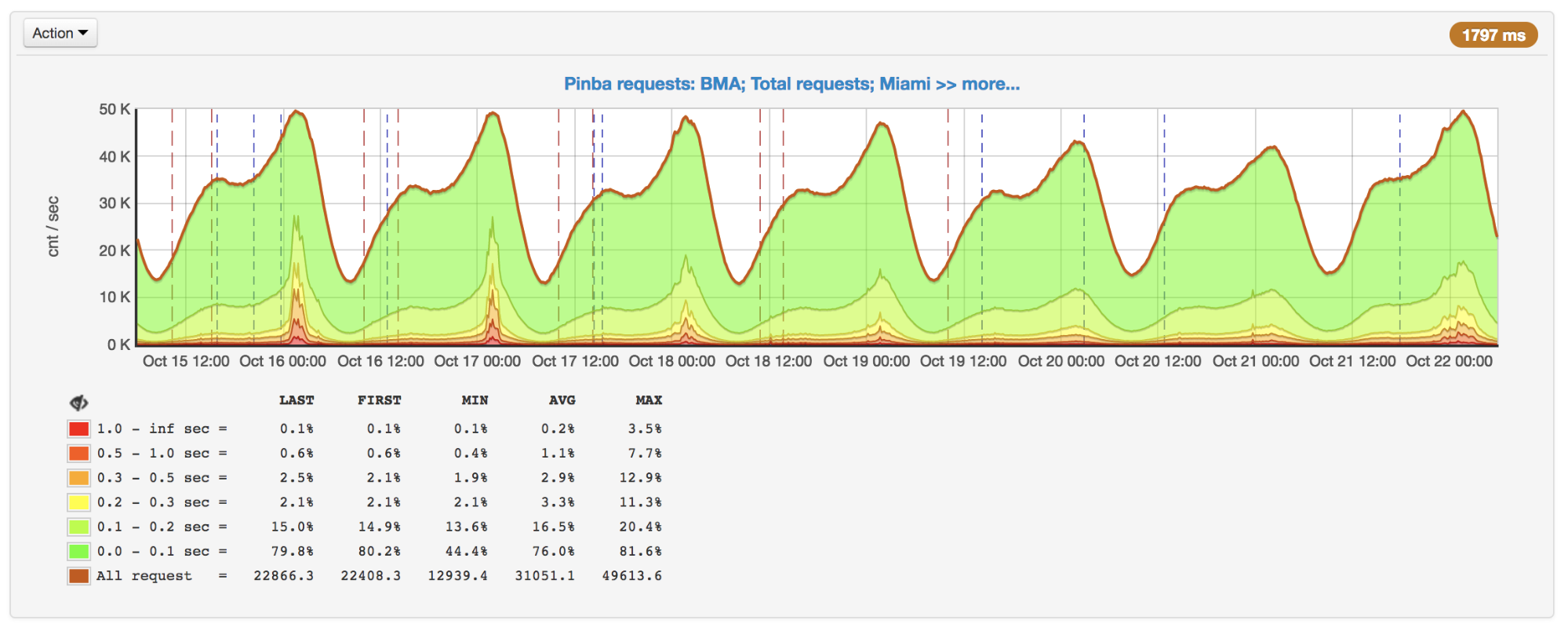 Anzahl der Anfragen pro Sekunde und Laufzeit: Spitzenwerte am 16. und 17. Oktober
Anzahl der Anfragen pro Sekunde und Laufzeit: Spitzenwerte am 16. und 17. OktoberBei Verwendung von APCu als Cache ist dieses Problem nicht so relevant, da das Caching normalerweise seltenes Schreiben und häufiges Lesen umfasst. Einige Aufgaben und Algorithmen (z. B. Leistungsschalter (
Implementierung in PHP )) beinhalten jedoch auch häufige Aufzeichnungen, die zu Sperren führen.
Es gibt keine universelle Lösung für dieses Problem, aber im Fall von Leistungsschaltern kann es beispielsweise gelöst werden, indem es in einen
separaten Dienst gestellt wird , der auf Computern mit PHP installiert ist.
Stapelverarbeitung
Selbst wenn Sie include nicht berücksichtigen, wird in der Regel trotzdem ein erheblicher Teil der Ausführungszeit für die Initialisierung für die Initialisierung aufgewendet: ein Framework (z. B. Erstellen eines DI-Containers und Initialisieren aller Abhängigkeiten, Routing, Ausführen aller Listener), Auslösen der Sitzung, des Benutzers usw. weiter.
Wenn Ihr Backend eine interne API für etwas ist, können einige Anforderungen auf Clients gebündelt und als einzelne Anforderung gesendet werden. In diesem Fall wird die Initialisierung für mehrere Anforderungen einmal durchgeführt.
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
Fazit
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
Vielen Dank für Ihre Aufmerksamkeit!