Hallo allerseits! Ich arbeite bei Veeam am Veeam Agent für Linux-Projekt. Mit diesem Produkt können Sie einen Linux-Computer sichern. "Agent" im Namen bedeutet, dass Sie mit dem Programm physische Maschinen sichern können. Virtualalkans sichern ebenfalls, befinden sich jedoch auf dem Gastbetriebssystem.
Die Inspiration für diesen Artikel war mein Bericht auf der
Linux Piter- Konferenz, den ich als Artikel für alle interessierten Habragiteli herausgeben wollte.
In diesem Artikel werde ich das Thema des Erstellens eines Snapshots erläutern, mit dem Sie die Probleme, die beim Erstellen unseres eigenen Mechanismus zum Erstellen von Snapshots von Blockgeräten aufgetreten sind, sichern und erläutern können.
Alle Interessierten bitten um einen Schnitt!

Ein bisschen Theorie am Anfang
In der Vergangenheit gibt es zwei Ansätze zum Erstellen von Sicherungen: Dateisicherung und Volumensicherung. Im ersten Fall kopieren wir jede Datei als separates Objekt, im zweiten kopieren wir den gesamten Inhalt des Volumes als eine Art Bild.
Beide Methoden haben viele Vor- und Nachteile, aber wir werden sie durch das Prisma der Wiederherstellung nach einem Fehler betrachten:
- Bei der Dateisicherung müssen wir für eine vollständige Wiederherstellung des gesamten Servers zuerst das Betriebssystem und dann die erforderlichen Dienste installieren und erst dann die Dateien aus der Sicherung wiederherstellen.
- Bei der Volumensicherung reicht es für eine vollständige Wiederherstellung aus, einfach alle Volumes des Computers ohne unnötigen Aufwand seitens der Person wiederherzustellen.
Im Fall einer Volumensicherung können Sie das System natürlich schneller wiederherstellen, und dies ist ein wichtiges
Merkmal des Systems . Aus diesem Grund empfehlen wir für uns die Volumensicherung als bevorzugte Option.
Wie nehmen und speichern wir das gesamte Volumen? Natürlich werden wir durch einfaches Kopieren nichts Gutes erreichen. Während des Kopierens treten einige Aktivitäten mit Daten auf dem Volume auf. Infolgedessen werden die inkonsistenten Daten in der Sicherung angezeigt. Die Dateisystemstruktur wird verletzt, Datenbankdateien werden beschädigt sowie andere Dateien, mit denen während des Kopierens Vorgänge ausgeführt werden.
Um all diese Probleme zu vermeiden, hat die fortschrittliche Menschheit eine Snapshot-Technologie entwickelt - Snapshot. Theoretisch ist alles einfach: Wir erstellen eine unveränderte Kopie - einen Schnappschuss - und sichern Daten daraus. Wenn das Backup beendet ist, zerstören wir den Snapshot. Es klingt einfach, aber wie immer gibt es Nuancen.
Aufgrund dessen wurden viele Implementierungen dieser Technologie geboren. Beispielsweise bieten auf
Device Mapper basierende Lösungen wie LVM und Thin Provisioning Snapshots mit vollem Volumen, erfordern jedoch ein spezielles Festplattenlayout in der Phase der Systeminstallation, was bedeutet, dass sie im Allgemeinen nicht geeignet sind.
BTRFS und ZFS ermöglichen das Erstellen von Snapshots von Dateisystem-Substrukturen, was sehr cool ist, aber im Moment ist ihr Anteil auf den Servern gering, und wir versuchen, eine universelle Lösung zu finden.
Angenommen, auf unserem Blockgerät befindet sich eine banale EXT. In diesem Fall können wir
dm-snap verwenden (
dm-bow wird übrigens gerade entwickelt), aber hier ist seine eigene Nuance. Sie müssen ein kostenloses Blockgerät bereithalten, damit Sie Snapshot-Daten dort ablegen können.
Bei der Betrachtung alternativer Backup-Lösungen haben wir festgestellt, dass sie in der Regel ihr Kernelmodul verwenden, um Snapshots von Blockgeräten zu erstellen. Wir haben uns für diesen Weg entschieden und unser Modul geschrieben. Es wurde beschlossen, es unter der GPL-Lizenz zu vertreiben, damit es auf
github öffentlich verfügbar
ist .
Wie es funktioniert - theoretisch
Mikroskop-Schnappschuss
Nun werden wir das allgemeine Prinzip der Funktionsweise des Moduls betrachten und uns eingehender mit den wichtigsten Fragen befassen.
Tatsächlich ist veeamsnap (wie wir unser Kernelmodul genannt haben) ein Blockgerätetreiberfilter.

Seine Aufgabe ist es, Anfragen nach einem Blockgerätetreiber abzufangen.
Nachdem das Modul eine Schreibanforderung abgefangen hat, kopiert es Daten vom ursprünglichen Blockgerät in den Snapshot-Datenbereich. Wir nennen diesen Bereich Snapstore.
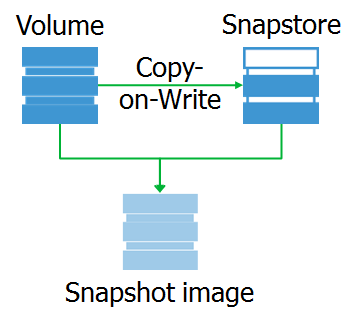
Und was ist der Schnappschuss selbst? Dies ist ein virtuelles Blockgerät, eine Kopie des Originalgeräts zu einem bestimmten Zeitpunkt. Wenn Sie auf Datenblöcke auf diesem Gerät zugreifen, können Sie diese entweder vom Snap-In oder vom Originalgerät lesen.
Ich möchte darauf hinweisen, dass der Snapshot genau das Blockgerät ist, das zum Zeitpunkt des Entfernens des Snapshots vollständig mit dem Original identisch war. Dank dessen können wir das Dateisystem auf einem Snapshot mounten und die erforderliche Vorverarbeitung durchführen.
Zum Beispiel können wir eine Karte der belegten Blöcke aus dem Dateisystem erhalten. Der einfachste Weg, dies zu tun, ist die Verwendung von ioctl
GETFSMAP .
Mit Daten auf belegten Blöcken können Sie nur die neuesten Daten aus einem Snapshot lesen.
Sie können auch einige Dateien ausschließen. Nun, eine völlig optionale Aktion: Indizieren Sie die Dateien, die in das Backup fallen, für die Möglichkeit eines granularen Restaurants in der Zukunft.
CoW vs RoW
Lassen Sie uns ein wenig auf die Auswahl des Snapshot-Algorithmus eingehen. Die Auswahl hier ist nicht sehr umfangreich:
Copy-on-Write oder Redirect-on-Write .
Redirect-on-Write beim Abfangen einer Schreibanforderung leitet sie an den Snap weiter. Danach werden auch alle Anforderungen zum Lesen dieses Blocks dorthin geleitet. Ein großartiger Algorithmus für Speichersysteme, die auf B + -Bäumen wie BTRFS, ZFS und Thin Provisioning basieren. Die Technologie ist so alt wie die Welt, manifestiert sich jedoch besonders gut in Hypervisoren, in denen Sie eine neue Datei erstellen und dort für die Dauer des Snapshots neue Blöcke schreiben können. Die Leistung ist im Vergleich zu CoW ausgezeichnet. Es gibt jedoch ein dickes Minus: Die Struktur des Originalgeräts ändert sich. Wenn Sie den Snapshot entfernen, müssen Sie alle Blöcke aus dem Snap an den ursprünglichen Speicherort kopieren.
Copy-on-Write kopiert beim Abfangen einer Anforderung Daten in den Snapstore, die geändert werden müssen, und kann anschließend an der ursprünglichen Stelle überschrieben werden. Wird zum Erstellen von Snapshots für LVM-Volumes und Schattenkopien von VSS verwendet. Offensichtlich ist es besser geeignet, um Schnappschüsse von Blockgeräten zu erstellen, weil ändert nicht die Struktur des Originalgeräts, und wenn Sie den Snapshot löschen (oder abstürzen), können Sie ihn einfach verwerfen, ohne Daten zu riskieren. Der Nachteil dieses Ansatzes ist eine Leistungsverschlechterung, da jeder Schreiboperation einige Lese- / Schreiboperationen hinzugefügt werden.
Da Datensicherheit unsere oberste Priorität ist, haben wir uns auf CoW konzentriert.
Bisher sieht alles einfach aus, also gehen wir die Probleme des wirklichen Lebens durch.
Wie es funktioniert - in der Praxis
Konsistenter Zustand
Für ihn wurde alles konzipiert.
Wenn zum Beispiel zum Zeitpunkt der Erstellung eines Schnappschusses (in erster Näherung können wir davon ausgehen, dass er sofort erstellt wird) ein Datensatz in einer Datei aufgezeichnet wird, ist die Datei in einem Schnappschuss unvollständig, was bedeutet, dass sie beschädigt und bedeutungslos ist. Ähnlich verhält es sich mit Datenbankdateien und dem Dateisystem selbst.
Aber wir leben im 21. Jahrhundert! Es gibt Protokollierungsmechanismen, die vor solchen Problemen schützen! Die Wahrheit ist, dass es ein wichtiges „Aber“ gibt: Dieser Schutz ist nicht vor Versagen, sondern vor seinen Folgen. Bei der Wiederherstellung eines konsistenten Zustands gemäß dem Protokoll werden unvollständige Vorgänge verworfen, was bedeutet, dass sie verloren gehen. Daher ist es wichtig, die Priorität auf den Schutz vor der Ursache zu verlagern, anstatt die Folgen zu behandeln.
Das System kann gewarnt werden, dass jetzt ein Snapshot erstellt wird. Dafür hat der Kernel die Funktionen
freeze_bdev und
thaw_bdev . Sie ziehen die Dateisystemfunktionen freeze_fs und unfreeze_fs. Wenn Sie den ersten aufrufen, muss das System den Cache zurücksetzen, die Erstellung neuer Anforderungen an das Blockgerät unterbrechen und auf den Abschluss aller zuvor generierten Anforderungen warten. Und wenn unfreeze_fs aufgerufen wird, stellt das Dateisystem seine normale Funktion wieder her.
Es stellt sich heraus, dass wir das Dateisystem warnen können. Was ist mit Anwendungen? Hier ist leider alles schlecht. Unter Windows gibt es einen
VSS- Mechanismus, der mithilfe von Writers die Interaktion mit anderen Produkten ermöglicht. Unter Linux geht jeder seinen eigenen Weg. Im Moment hat dies dazu geführt, dass der Systemadministrator die Aufgabe hat, Skripte vor dem Einfrieren und nach dem Auftauen selbst zu schreiben (zu kopieren, zu
stehlen , zu kaufen usw.), um seine Anwendung für den Snapshot vorzubereiten. In der nächsten Version werden wir unsererseits die Unterstützung für Oracle Application Processing einführen, die von unseren Kunden am häufigsten angeforderte Funktion. Dann werden möglicherweise andere Anwendungen unterstützt, aber insgesamt ist die Situation eher traurig.
Wo soll der Druckknopf platziert werden?
Dies ist das zweite Problem, das uns im Weg steht. Auf den ersten Blick ist das Problem nicht offensichtlich, aber nach ein wenig Verständnis sehen wir, dass dies immer noch ein Splitter ist.
Die einfachste Lösung besteht natürlich darin, den Snap im RAM zu platzieren. Für den Entwickler ist die Option einfach großartig! Alles ist schnell, sehr bequem zum Debuggen, aber es gibt einen Stau: RAM ist eine wertvolle Ressource, und niemand wird uns dort einen großen Schnappschuss geben.
OK, machen wir die Snap-Datei zu einer regulären Datei. Es tritt jedoch ein anderes Problem auf: Sie können das Volume, auf dem sich der Snapstop befindet, nicht sichern. Der Grund ist einfach: Wir fangen Aufzeichnungsanforderungen ab, was bedeutet, dass wir unsere eigenen Aufzeichnungsanforderungen im Snap-In abfangen. Pferde liefen auf wissenschaftliche Weise herum - Deadlock. Dann besteht der akute Wunsch, dafür eine separate Festplatte zu verwenden, aber niemand wird für uns Festplatten zu unserem Server hinzufügen. Sie müssen in der Lage sein, an dem zu arbeiten, was ist.
Das Remote-Positionieren des Snap-Ins ist eine hervorragende Idee, kann jedoch in sehr engen Kreisen von Netzwerken mit hoher Bandbreite und mikroskopischen Latenzen implementiert werden. Andernfalls gibt es eine rundenbasierte Strategie, während Sie den Schnappschuss auf der Maschine halten.
Sie müssen den Snap also irgendwie schwierig auf der lokalen Festplatte platzieren. In der Regel ist jedoch der gesamte Speicherplatz auf lokalen Datenträgern bereits auf Dateisysteme verteilt, und gleichzeitig müssen Sie sich überlegen, wie Sie das Deadlock-Problem umgehen können.
Die Richtung für die Reflexion ist im Prinzip eine: Sie müssen irgendwie Speicherplatz im Dateisystem zuweisen, aber direkt mit dem Blockgerät arbeiten. Die Lösung für dieses Problem wurde im Benutzerbereichscode im Dienst implementiert.
Es gibt einen
Fallocate -Systemaufruf, mit dem Sie eine leere Datei mit der gewünschten Größe erstellen können. Tatsächlich werden jedoch nur Metadaten im Dateisystem erstellt, die den Speicherort der Datei auf dem Volume beschreiben. Mit ioctl
FIEMAP können wir eine Karte des Speicherorts der Dateiblöcke
abrufen .
Und voila: Wir erstellen eine Datei unter Snap mit Fallocate. FIEMAP gibt uns eine Karte des Speicherorts der Blöcke dieser Datei, die wir zur Arbeit in unserem veeamsnap-Modul übertragen können. Wenn das Modul auf den Snapstor zugreift, sendet es Anforderungen direkt an das Blockgerät in uns bekannten Blöcken und ohne Deadlocks.
Aber es gibt eine Nuance. Der Fallocate-Systemaufruf wird nur von XFS, EXT4 und BTRFS unterstützt. Bei anderen Dateisystemen wie EXT3 müssen Sie es vollständig schreiben, um die Datei zuzuweisen. Die Funktionalität wird durch eine längere Zeit für die Zubereitung von Schnappschüssen beeinträchtigt, es gibt jedoch keine andere Wahl. Auch hier müssen Sie in der Lage sein, an dem zu arbeiten, was ist.
Was ist, wenn ioctl FIEMAP ebenfalls nicht unterstützt wird? Dies ist die Realität von NTFS und FAT32, wo die alte FIBMAP nicht einmal unterstützt wird. Ich musste einen bestimmten generischen Algorithmus implementieren, dessen Funktionsweise nicht von den Funktionen des Dateisystems abhängt. Kurz gesagt lautet der Algorithmus:
- Der Dienst erstellt eine Datei und beginnt mit dem Schreiben eines bestimmten Musters.
- Das Modul fängt Schreibanforderungen ab und überprüft die zu schreibenden Daten.
- Wenn die Blockdaten mit dem angegebenen Muster übereinstimmen, wird der Block als zum Snapstop gehörend markiert.
Ja, schwierig, ja, langsam, aber besser als nichts. Es wird in seltenen Fällen für Dateisysteme ohne FIEMAP- und FIBMAP-Unterstützung verwendet.
Schnappschuss-Überlauf
Vielmehr endet der Platz, den wir unter Snapstore zugewiesen haben. Das Wesentliche des Problems ist, dass neue Daten nirgends verworfen werden können, was bedeutet, dass der Snapshot unbrauchbar wird.
Was zu tun ist?
Natürlich müssen Sie die Größe der Schnappschüsse erhöhen. Wie viel? Der einfachste Weg, die Größe von Snappants festzulegen, besteht darin, den Prozentsatz des freien Speicherplatzes auf dem Volume zu bestimmen (wie bei VSS). Bei einem Volumen von 20 TB sind 10% 2 TB - was für einen entladenen Server sehr viel ist. Bei einem Volumen von 200 GB sind 10% 20 GB, was für einen Server, der seine Daten intensiv aktualisiert, möglicherweise zu wenig ist. Und es gibt immer noch dünne Bände ...
Im Allgemeinen kann nur der Systemadministrator des Servers die optimale Größe des erforderlichen Snap-In im Voraus ermitteln. Das heißt, Sie müssen die Person zum Nachdenken anregen und ihre Expertenmeinung abgeben. Dies entspricht nicht dem Prinzip „Es funktioniert einfach“.
Um dieses Problem zu lösen, haben wir den Stretch-Snapshot-Algorithmus entwickelt. Die Idee ist, den Druckknopf in Teile zu zerlegen. Gleichzeitig werden nach der Erstellung eines Snapshots nach Bedarf neue Teile erstellt.

Nochmals kurz der Algorithmus:
- Vor dem Erstellen eines Snapshots wird der erste Teil des Snapshots erstellt und dem Modul übergeben.
- Wenn der Schnappschuss erstellt wird, füllt sich der Teil.
- Sobald die Hälfte des Teils voll ist, wird eine Anfrage an den Dienst gesendet, um einen neuen zu erstellen.
- Der Dienst erstellt es und gibt die Daten an das Modul weiter.
- Das Modul beginnt, die nächste Charge zu füllen.
- Der Algorithmus wird wiederholt, bis die Sicherung abgeschlossen ist oder bis die Verwendung von freiem Speicherplatz begrenzt ist.
Es ist wichtig zu beachten, dass das Modul Zeit haben muss, um bei Bedarf neue Teile von Snapposts zu erstellen. Andernfalls - Überlauf, Zurücksetzen von Snapshots und keine Sicherung. Daher ist die Bedienung eines solchen Algorithmus nur auf Dateisystemen mit Fallocate-Unterstützung möglich, in denen Sie schnell eine leere Datei erstellen können.
Was ist in anderen Fällen zu tun? Wir versuchen, die erforderliche Größe zu erraten und den gesamten Snappast vollständig zu erstellen. Laut unseren Statistiken verwendet die überwiegende Mehrheit der Linux-Server jetzt EXT4 und XFS. EXT3 ist auf älteren Maschinen zu finden. In SLES / openSUSE können Sie jedoch auf BTRFS stoßen.
Blockverfolgung ändern (CBT)
Inkrementelle oder differenzielle Sicherung (Radieschen-Meerrettich ist übrigens süßer oder nicht, ich schlage vor,
hier zu lesen) - ohne diese können Sie sich kein Sicherungsprodukt für Erwachsene vorstellen. Und damit dies funktioniert, benötigen Sie CBT. Wenn jemand etwas verpasst hat: Mit CBT können Sie Änderungen verfolgen und nur die Daten in die Sicherung schreiben, die seit der letzten Sicherung geändert wurden.

Viele haben ihre eigenen Erfahrungen in diesem Bereich. In VMware vSphere ist diese Funktion beispielsweise seit Version 4 im Jahr 2009 verfügbar. In Hyper-V wurde die Unterstützung mit Windows Server 2016 eingeführt. Um frühere Versionen zu unterstützen, wurde bereits 2012 ein eigener VeeamFCT-Treiber entwickelt. Daher wurden wir für unser Modul nicht original und verwendeten bereits funktionierende Algorithmen.
Wie es funktioniert.
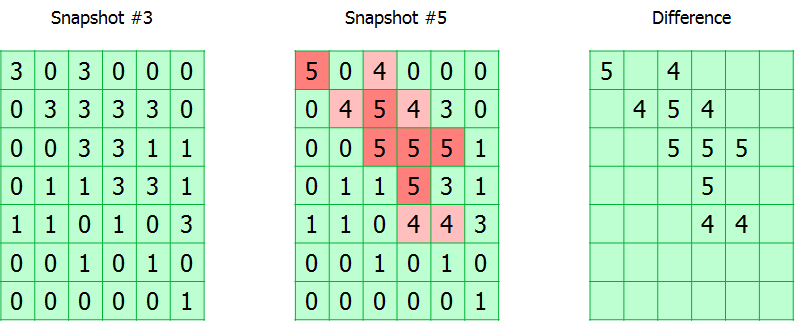
Das gesamte verfolgte Volumen ist in Blöcke unterteilt. Das Modul verfolgt einfach alle Schreibanforderungen und markiert die geänderten Blöcke in der Tabelle. Tatsächlich ist die CBT-Tabelle ein Array von Bytes, wobei jedes Byte einem Block entspricht und die Nummer des Snapshots enthält, in dem es geändert wurde.
Während der Sicherung wird die Snapshot-Nummer in den Sicherungsmetadaten aufgezeichnet. Wenn Sie also die Nummern des aktuellen Snapshots und die Nummer kennen, aus der die vorherige erfolgreiche Sicherung erstellt wurde, können Sie die Karte des Speicherorts der geänderten Blöcke berechnen.
Es gibt zwei Nuancen.
Wie bereits erwähnt, wird der Snapshot-Nummer in der CBT-Tabelle ein Byte zugewiesen. Dies bedeutet, dass die maximale Länge der inkrementellen Kette nicht mehr als 255 betragen darf. Wenn dieser Schwellenwert erreicht ist, wird die Tabelle zurückgesetzt und eine vollständige Sicherung durchgeführt. Es mag unpraktisch erscheinen, aber tatsächlich ist eine Kette von 255 Schritten bei weitem nicht die beste Lösung, wenn Sie einen Sicherungsplan erstellen.
Das zweite Merkmal ist die Speicherung der CBT-Tabelle nur im RAM. Wenn Sie den Zielcomputer neu starten oder das Modul entladen, wird es zurückgesetzt, und Sie müssen erneut eine vollständige Sicherung erstellen. Eine solche Lösung ermöglicht es, das Problem des Modulstarts beim Systemstart nicht zu lösen. Außerdem müssen beim Ausschalten des Systems keine CBT-Tabellen gespeichert werden.
Leistungsproblem
Backup ist immer eine gute Belastung für die E / A Ihrer Geräte. Wenn bereits genügend aktive Aufgaben vorhanden sind, kann der Sicherungsprozess Ihr System in eine Art
Faultier verwandeln.
Mal sehen warum.
Stellen Sie sich vor, der Server schreibt einige Daten einfach linear. Die Aufnahmegeschwindigkeit ist in diesem Fall maximal, alle Verzögerungen werden minimiert, die Leistung tendiert zum Maximum. Jetzt fügen wir hier den Sicherungsprozess hinzu, der bei jedem Schreibvorgang noch den Copy-on-Write-Algorithmus ausführen muss. Dies ist eine zusätzliche Leseoperation mit anschließendem Schreibvorgang. Und vergessen Sie nicht, dass Sie für die Sicherung immer noch Daten von demselben Volume lesen müssen. Mit einem Wort, Ihr schöner linearer Zugriff wird zu einem gnadenlosen Direktzugriff mit allen Konsequenzen.
Wir müssen offensichtlich etwas damit anfangen, und wir haben eine Pipeline implementiert, um Anforderungen nicht einzeln, sondern in ganzen Paketen zu verarbeiten. Es funktioniert so.
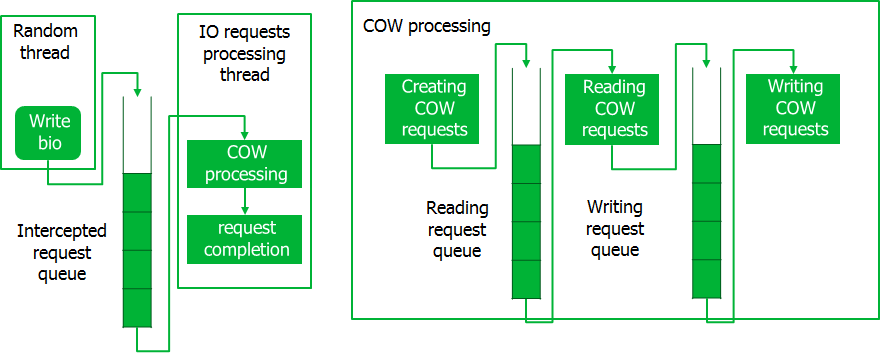
Beim Abfangen von Anforderungen werden sie in eine Warteschlange gestellt, wo sie von einem speziellen Stream in Portionen aufgenommen werden. Zu diesem Zeitpunkt werden CoW-Anforderungen erstellt, die auch stapelweise verarbeitet werden. Bei der Verarbeitung von CoW-Anforderungen werden zunächst alle Leseoperationen für den gesamten Teil ausgeführt, wonach Schreiboperationen ausgeführt werden. Erst nachdem die Verarbeitung des gesamten Teils der CoW-Anforderungen abgeschlossen ist, werden abgefangene Anforderungen ausgeführt. Ein solcher Förderer ermöglicht den Zugriff auf die Platte in großen Datenblöcken, wodurch Zeitverluste minimiert werden.
Drosselung
Bereits beim Debuggen tauchte eine weitere Nuance auf. Während der Sicherung reagierte das System nicht mehr, d.h. System-E / A-Anforderungen wurden mit langen Verzögerungen ausgeführt. Anforderungen zum Lesen von Daten aus einem Schnappschuss wurden jedoch mit einer Geschwindigkeit nahe dem Maximum ausgeführt.
Ich musste den Sicherungsprozess ein wenig erwürgen, indem ich den Drosselungsmechanismus implementierte. Zu diesem Zweck wird der Prozess, der aus dem Snapshot-Image gelesen wird, in einen Wartezustand versetzt, wenn die Warteschlange abgefangener Anforderungen nicht leer ist. Erwartungsgemäß wurde das System zum Leben erweckt.
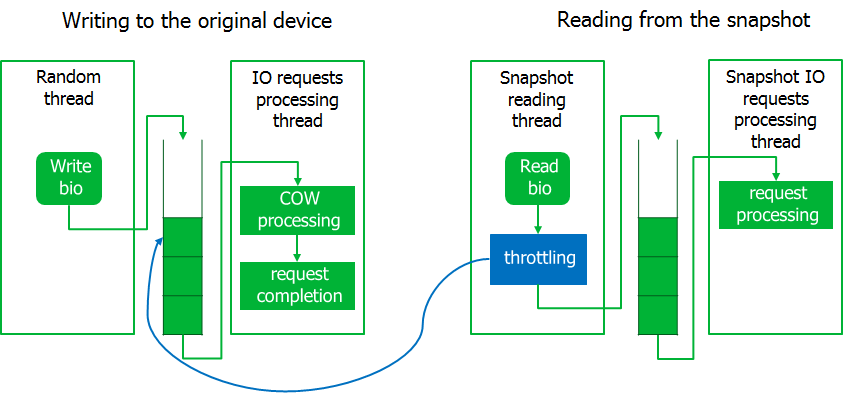
Wenn die Belastung des E / A-Systems stark zunimmt, wartet der Lesevorgang aus dem Snapshot. Hier haben wir uns von dem Prinzip leiten lassen, dass es besser ist, die Sicherung mit einem Fehler zu beenden, als den Server zu stören.
Deadlock
Ich denke, wir müssen genauer erklären, was es ist.
Bereits in der Testphase stießen wir mit der Diagnose von sieben Problemen - einem Zurücksetzen - auf Situationen, in denen das System vollständig hängen blieb.
Sie begannen zu verstehen. Es stellte sich heraus, dass eine solche Situation beobachtet werden kann, wenn Sie beispielsweise einen Snapshot des Blockgeräts erstellen, auf dem sich das LVM-Volume befindet, und den Snapshot auf demselben LVM-Volume platzieren. Ich möchte Sie daran erinnern, dass LVM das Device Mapper-Kernelmodul verwendet.

In dieser Situation sendet das Modul beim Abfangen einer Schreibanforderung beim Schreiben der Daten in das Snap-In die Schreibanforderung an das LVM-Volume. Der Geräte-Mapper leitet diese Anforderung an das Blockierungsgerät weiter. Eine Anfrage vom Device Mapper wird erneut vom Modul abgefangen. Eine neue Anfrage kann jedoch erst bearbeitet werden, wenn die vorherige bearbeitet wurde. Infolgedessen wird die Anforderungsverarbeitung blockiert, und Sie werden von einem Deadlock begrüßt.
Um dies zu verhindern, bietet das Kernelmodul selbst eine Zeitüberschreitung für das Kopieren von Daten in das Snap-In. Auf diese Weise können Sie Deadlocks und Absturzsicherungen erkennen. Die Logik hier ist dieselbe: Es ist besser, nicht zu sichern, als den Server anzuhalten.
Round-Robin-Datenbank
Dies ist bereits ein Problem, das Benutzer nach der Veröffentlichung der ersten Version haben.
Es stellte sich heraus, dass es solche Dienste gibt, die nur ständig dieselben Blöcke überschreiben.
Ein markantes Beispiel sind Überwachungsdienste, die ständig Daten zum Systemzustand generieren und diese in einem Kreis überschreiben. Verwenden Sie für solche Aufgaben spezielle zyklische Datenbanken ( RRD ).Es stellte sich heraus, dass bei einer Sicherung solcher Basen der Snapshot garantiert überläuft. In einer detaillierten Untersuchung des Problems haben wir einen Fehler in der Implementierung des CoW-Algorithmus festgestellt. Wenn derselbe Block überschrieben wurde, wurden die Daten jedes Mal in das Snap-In kopiert. Ergebnis: Duplizieren von Daten im Snap.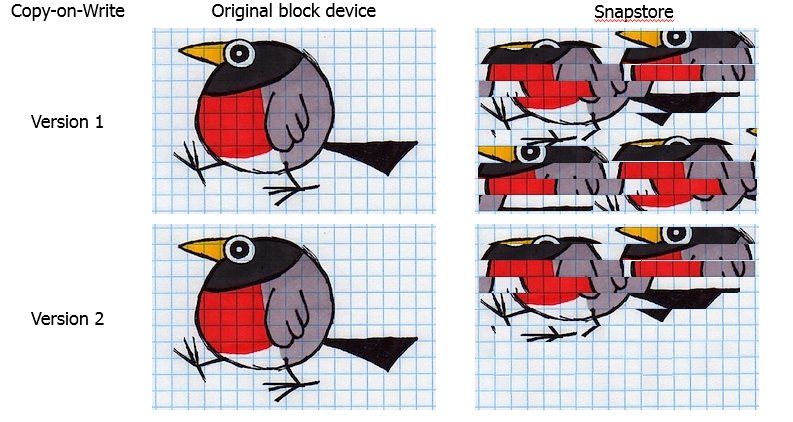 Natürlich haben wir den Algorithmus geändert. Jetzt wird das Volume in Blöcke unterteilt und die Daten in den Snap-Block kopiert. Wenn der Block bereits einmal kopiert wurde, wird dieser Vorgang nicht wiederholt.
Natürlich haben wir den Algorithmus geändert. Jetzt wird das Volume in Blöcke unterteilt und die Daten in den Snap-Block kopiert. Wenn der Block bereits einmal kopiert wurde, wird dieser Vorgang nicht wiederholt.Auswahl der Blockgröße
Wenn nun der Snapstrap in Blöcke zerlegt wird, stellt sich die Frage: Wie groß sind die Blöcke tatsächlich, um Snappastes aufzuteilen?Das Problem ist zweifach. Wenn der Block groß gemacht wird, ist die Bedienung für sie einfacher. Wenn sich jedoch mindestens ein Sektor ändert, müssen Sie den gesamten Block an das Rig senden, wodurch die Wahrscheinlichkeit einer Überfüllung des Rigs erhöht wird. Je kleiner die Blockgröße ist, desto mehr nützliche Daten werden natürlich an den Snapstore gesendet. Wie wirkt sich dies natürlich auf die Leistung aus?Sie suchten empirisch nach der Wahrheit und kamen auf 16 KB. Beachten Sie auch, dass Windows VSS auch 16 KiB-Blöcke verwendet.
Je kleiner die Blockgröße ist, desto mehr nützliche Daten werden natürlich an den Snapstore gesendet. Wie wirkt sich dies natürlich auf die Leistung aus?Sie suchten empirisch nach der Wahrheit und kamen auf 16 KB. Beachten Sie auch, dass Windows VSS auch 16 KiB-Blöcke verwendet.Anstelle einer Schlussfolgerung
Das ist alles für jetzt. Ich werde viele andere, nicht weniger interessante Probleme hinterlassen, wie die Abhängigkeit von Kernelversionen, die Auswahl der Modulverteilungsoptionen, die kABI-Kompatibilität, die Arbeit unter Backport-Bedingungen usw. Der Artikel erwies sich als umfangreich, daher beschloss ich, mich mit den interessantesten Problemen zu befassen.Jetzt bereiten wir uns auf Release 3.0 vor, der Modulcode ist auf Github und jeder kann ihn unter der GPL-Lizenz verwenden.