Für diejenigen, denen mein
vorheriger Artikel gefallen hat, teile ich weiterhin meine Eindrücke vom Locust-Stresstest-Tool.
Ich werde versuchen, die Vorteile des Schreibens einer Lasttest-Python mit Code klar zu demonstrieren, in dem Sie bequem alle Daten für den Test vorbereiten und die Ergebnisse verarbeiten können.
Serverantwortverarbeitung
Manchmal reicht es beim Auslastungstest nicht aus, einfach 200 OK vom HTTP-Server zu erhalten. Es kommt vor, dass Sie den Inhalt der Antwort überprüfen müssen, um sicherzustellen, dass der Server unter Last die richtigen Daten ausgibt oder genaue Berechnungen durchführt. Nur für solche Fälle hat Locust die Möglichkeit hinzugefügt, die Erfolgsparameter der Serverantwort zu überschreiben. Betrachten Sie das folgende Beispiel:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Es gibt nur eine Anforderung, die im folgenden Szenario eine Last erzeugt:
Vom Server fordern wir Fotoobjekte mit einer zufälligen ID im Bereich von 1 bis 5000 an und überprüfen die Album-ID in diesem Objekt, vorausgesetzt, es kann kein Vielfaches von 10 sein
Hier können Sie sofort einige Erklärungen geben:
- Die großartige Konstruktion mit request () als Antwort: Sie können sie erfolgreich durch response = request () ersetzen und leise mit dem Antwortobjekt arbeiten
- Die URL wird mithilfe der in Python 3.6 hinzugefügten Syntax des Zeichenfolgenformats gebildet, wenn ich mich nicht irre - f '/ photos / {photo_id}' . In früheren Versionen funktioniert dieses Design nicht!
- Ein neues Argument, das wir zuvor nicht verwendet hatten, catch_response = True , teilt Locust mit, dass wir selbst den Erfolg der Serverantwort bestimmen werden. Wenn Sie es nicht angeben, erhalten wir das Antwortobjekt auf die gleiche Weise und können seine Daten verarbeiten, aber das Ergebnis nicht neu definieren. Unten finden Sie ein detailliertes Beispiel.
- Ein anderes Argument name = '/ photos / [id]' . Es wird benötigt, um Anforderungen in Statistiken zu gruppieren. Der Name kann ein beliebiger Text sein, eine Wiederholung der URL ist nicht erforderlich. Ohne diese Option wird jede Anforderung mit einer eindeutigen Adresse oder Parametern separat aufgezeichnet. So funktioniert es:
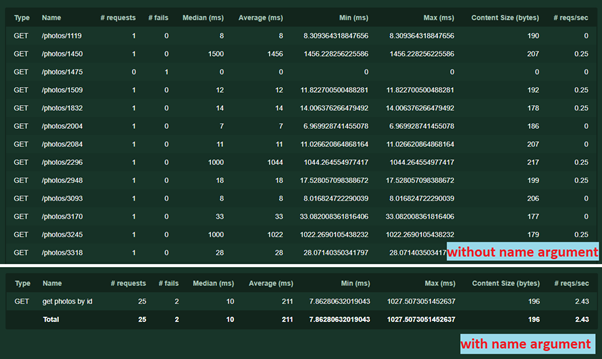
Mit demselben Argument können Sie einen anderen Trick ausführen. Manchmal führt ein Dienst mit unterschiedlichen Parametern (z. B. unterschiedlichen Inhalten von POST-Anforderungen) eine andere Logik aus. Damit die Testergebnisse nicht verwechselt werden, können Sie mehrere separate Aufgaben schreiben und für jede ihren eigenen Argumentnamen
angeben .
Als nächstes machen wir die Kontrollen. Ich habe zwei davon. Zuerst überprüfen wir, ob der Server eine Antwort zurückgegeben hat, wenn
response.status_code == 200 :
Wenn ja, überprüfen Sie, ob die ID des Albums ein Vielfaches von 10 ist. Wenn nicht ein Vielfaches, markieren Sie diese Antwort als erfolgreiche
Antwort. Success ()In anderen Fällen geben wir an, warum die Antwort fehlgeschlagen ist.
Response.failure ('Fehlertext') . Dieser Text wird während des Tests auf der Seite Fehler angezeigt.
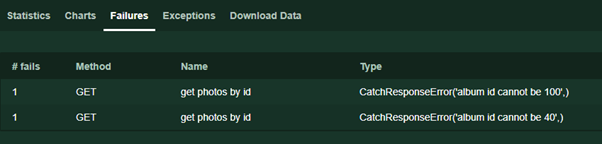
Aufmerksame Leser könnten auch das Fehlen von Ausnahmen bemerken, die für Code charakteristisch sind, der mit Netzwerkschnittstellen funktioniert. Im Fall von Zeitüberschreitung, Verbindungsfehlern und anderen unvorhergesehenen Vorfällen behandelt Locust die Fehler und gibt dennoch eine Antwort zurück, wobei jedoch angezeigt wird, dass der Status des Antwortcodes 0 ist.
Wenn der Code immer noch eine Ausnahme auslöst, wird diese zur Laufzeit auf die Registerkarte Ausnahmen geschrieben, damit wir damit umgehen können. Die typischste Situation ist, dass der json'e der Antwort nicht den gesuchten Wert zurückgegeben hat, aber wir führen bereits die folgenden Operationen daran durch.
Vor dem Schließen des Themas - im Beispiel verwende ich aus Gründen der Übersichtlichkeit den JSON-Server, da es einfacher ist, die Antworten zu verarbeiten. Mit HTML, XML, FormData, Dateianhängen und anderen Daten, die von HTTP-basierten Protokollen verwendet werden, können Sie jedoch mit demselben Erfolg arbeiten.
Arbeiten Sie mit komplexen Szenarien
Fast jedes Mal, wenn die Aufgabe darin besteht, Lasttests für eine Webanwendung durchzuführen, wird schnell klar, dass es unmöglich ist, eine angemessene Abdeckung mit GET-Diensten allein bereitzustellen, die einfach Daten zurückgeben.
Klassisches Beispiel: Um einen Online-Shop zu testen, ist es wünschenswert, dass der Benutzer
- Öffnete den Hauptladen
- Ich habe nach Waren gesucht
- Details zum geöffneten Artikel
- Artikel in den Warenkorb gelegt
- Bezahlt
Aus dem Beispiel können wir annehmen, dass das Aufrufen von Diensten in zufälliger Reihenfolge nicht funktioniert, sondern nur nacheinander. Darüber hinaus können Waren, Körbe und Zahlungsarten für jeden Benutzer eindeutige Kennungen aufweisen.
Mit dem vorherigen Beispiel können Sie mit geringfügigen Änderungen das Testen eines solchen Szenarios problemlos implementieren. Wir passen das Beispiel für unseren Testserver an:
- Benutzer schreibt einen neuen Beitrag
- Der Benutzer schreibt einen Kommentar zu dem neuen Beitrag
- Benutzer liest Kommentar
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
In diesem Beispiel habe ich eine neue
FlowException- Klasse hinzugefügt. Wenn es nach jedem Schritt nicht wie erwartet gelaufen ist, habe ich diese Ausnahmeklasse ausgelöst, um das Skript abzubrechen. Wenn der Beitrag nicht funktioniert hat, gibt es nichts zu kommentieren usw. Falls gewünscht, kann die Konstruktion durch die übliche
Rückgabe ersetzt werden. In diesem Fall ist jedoch zur Laufzeit und bei der Analyse der Ergebnisse nicht klar, wo das ausgeführte Skript auf die Registerkarte Ausnahmen fällt. Aus dem gleichen Grund verwende ich den
Versuch nicht ... außer Konstrukt.
Die Last realistisch machen
Jetzt kann ich mir Vorwürfe machen - im Fall des Geschäfts ist alles wirklich linear, aber das Beispiel mit Posts und Kommentaren ist zu weit hergeholt - sie lesen Posts zehnmal häufiger als sie erstellen. Lassen Sie uns das Beispiel vernünftigerweise praktikabler machen. Und es gibt mindestens zwei Ansätze:
- Sie können die Liste der von Benutzern gelesenen Beiträge „fest codieren“ und den Testcode vereinfachen, wenn eine solche Möglichkeit besteht und die Funktionalität des Backends nicht von bestimmten Beiträgen abhängt
- Speichern Sie erstellte Beiträge und lesen Sie sie, wenn die Liste der Beiträge nicht voreingestellt werden kann oder die realistische Belastung davon abhängt, welche Beiträge gelesen werden (ich habe die Erstellung von Kommentaren aus dem Beispiel entfernt, um den Code kleiner und visueller zu gestalten).
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
In der
UserBehavior- Klasse habe ich eine Liste mit erstellten
Posts erstellt . Achten Sie besonders darauf - dies ist ein Objekt, das nicht im Konstruktor der Klasse
__init __ () erstellt wurde. Daher ist diese Liste im Gegensatz zur
Clientsitzung für alle Benutzer gleich. Die erste Aufgabe erstellt einen Beitrag und schreibt seine ID in die Liste. Der zweite - zehnmal häufiger - liest einen zufällig ausgewählten Beitrag aus der Liste. Eine zusätzliche Bedingung für die zweite Aufgabe ist die Überprüfung, ob Beiträge erstellt wurden.
Wenn jeder Benutzer nur mit seinen eigenen Daten arbeiten soll, können wir diese im Konstruktor wie folgt deklarieren:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
Einige weitere Funktionen
Für das sequentielle Starten von Aufgaben wird in der offiziellen Dokumentation vorgeschlagen, dass wir auch die Aufgabenanmerkung @seq_task (1) verwenden und die Seriennummer der Aufgabe im Argument angeben
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
In diesem Beispiel führt jeder Benutzer zuerst die erste
Aufgabe , dann die
zweite Aufgabe und dann die
zehnfache dritte Aufgabe aus .
Ehrlich gesagt ist die Verfügbarkeit einer solchen Gelegenheit erfreulich, aber im Gegensatz zu den vorherigen Beispielen ist nicht klar, wie die Ergebnisse der ersten Aufgabe bei Bedarf auf die zweite übertragen werden sollen.
In besonders komplexen Szenarien ist es auch möglich, verschachtelte Task-Sets zu erstellen, indem mehrere TaskSet-Klassen erstellt und eine Verbindung hergestellt werden.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Im obigen Beispiel wird das
Todo- Skript mit einer Wahrscheinlichkeit von 1 bis 6 gestartet und ausgeführt, bis es mit einer Wahrscheinlichkeit von 1 bis 4 zum
UserBehavior- Skript zurückkehrt. Es ist sehr wichtig, dass Sie einen Aufruf von
self.interrupt () haben. Ohne diesen Aufruf
konzentrieren sich die Tests auf die Unteraufgabe.
Danke fürs Lesen. Im letzten Artikel werde ich über verteilte Tests und Tests ohne Benutzeroberfläche sowie über die Schwierigkeiten, die ich beim Testen mit Locust hatte, und darüber, wie ich sie umgehen kann, schreiben.