
Habr, dies ist ein Bericht des Software-Ingenieurs Alexei Starkov auf der Moscow Python Conf ++ 2018-Konferenz in Moskau. Video am Ende des Beitrags.
Hallo allerseits! Mein Name ist Alexei Starkov - das bin ich, in meinen besten Jahren arbeite ich in einer Fabrik.
Jetzt arbeite ich bei Qrator Labs. Grundsätzlich habe ich mein ganzes Leben lang C und C ++ studiert - ich liebe Alexandrescu, The Gang of Four, die Prinzipien von SOLID - das ist alles. Was mich zu einem architektonischen Astronauten macht. Ich habe Python in den letzten Jahren geschrieben, weil es mir gefällt.
Wer sind eigentlich "architektonische Kosmonauten"? Als ich diesen Begriff zum ersten Mal mit Joel Spolsky traf, haben Sie ihn wahrscheinlich gelesen. Er beschreibt die "Astronauten" als Menschen, die eine ideale Architektur aufbauen wollen, die Abstraktion über Abstraktion, über Abstraktion hängen, die immer allgemeiner wird. Am Ende sind diese Ebenen so hoch, dass sie alle möglichen Programme beschreiben, aber keine praktischen Probleme lösen. In diesem Moment geht dem "Astronauten" (dies ist das letzte Mal, dass dieser Begriff von Anführungszeichen umgeben ist) die Luft aus und er stirbt.
Ich habe auch Tendenzen zur Erforschung des architektonischen Weltraums, aber in diesem Bericht werde ich ein wenig darüber sprechen, wie es mich gebissen hat und mir nicht erlaubt hat, ein System mit der erforderlichen Leistung zu bauen. Die Hauptsache ist, wie ich es überwunden habe.
Zusammenfassung meines Berichts: war / war.

Eine tausende und millionenfache Zunahme. Als ich diese Folie machte, war der einzige Gedanke, den ich hatte, "Wie?"

Wo könnte ich so viel vermasseln? Wenn Sie es nicht wie ich vermasseln wollen - lesen Sie weiter.

Ich werde über das Konfigurationssystem sprechen. Das Konfigurationssystem ist ein internes Tool in Qrator Labs, das Konfigurationen für das Software Defined Network (SDN) - unser Filternetzwerk - speichert. Es ist verpflichtet, die Konfiguration zwischen Komponenten zu synchronisieren und ihren Status zu überwachen.

Woraus besteht es kurz gesagt? Wir haben eine Datenbank, in der eine Momentaufnahme unserer Konfiguration für das gesamte Netzwerk gespeichert ist, und wir haben einen Server, der die eingehenden Befehle verarbeitet und die Konfiguration irgendwie ändert.
Unsere technischen Administratoren und Clients kommen zu diesem Server und geben über die Konsole, über die Endpunkt-APIs, REST-APIs, JSON-RPCs und andere Dinge Befehle an den Server aus, wodurch unsere Konfiguration geändert wird.
Teams können entweder sehr einfach oder komplizierter sein. Dann haben wir einen bestimmten Satz von Empfängern, aus denen unser SDN besteht, und der Server überträgt die Konfiguration an diese Empfänger. Das klingt ziemlich einfach. Grundsätzlich werde ich über diesen Teil sprechen.
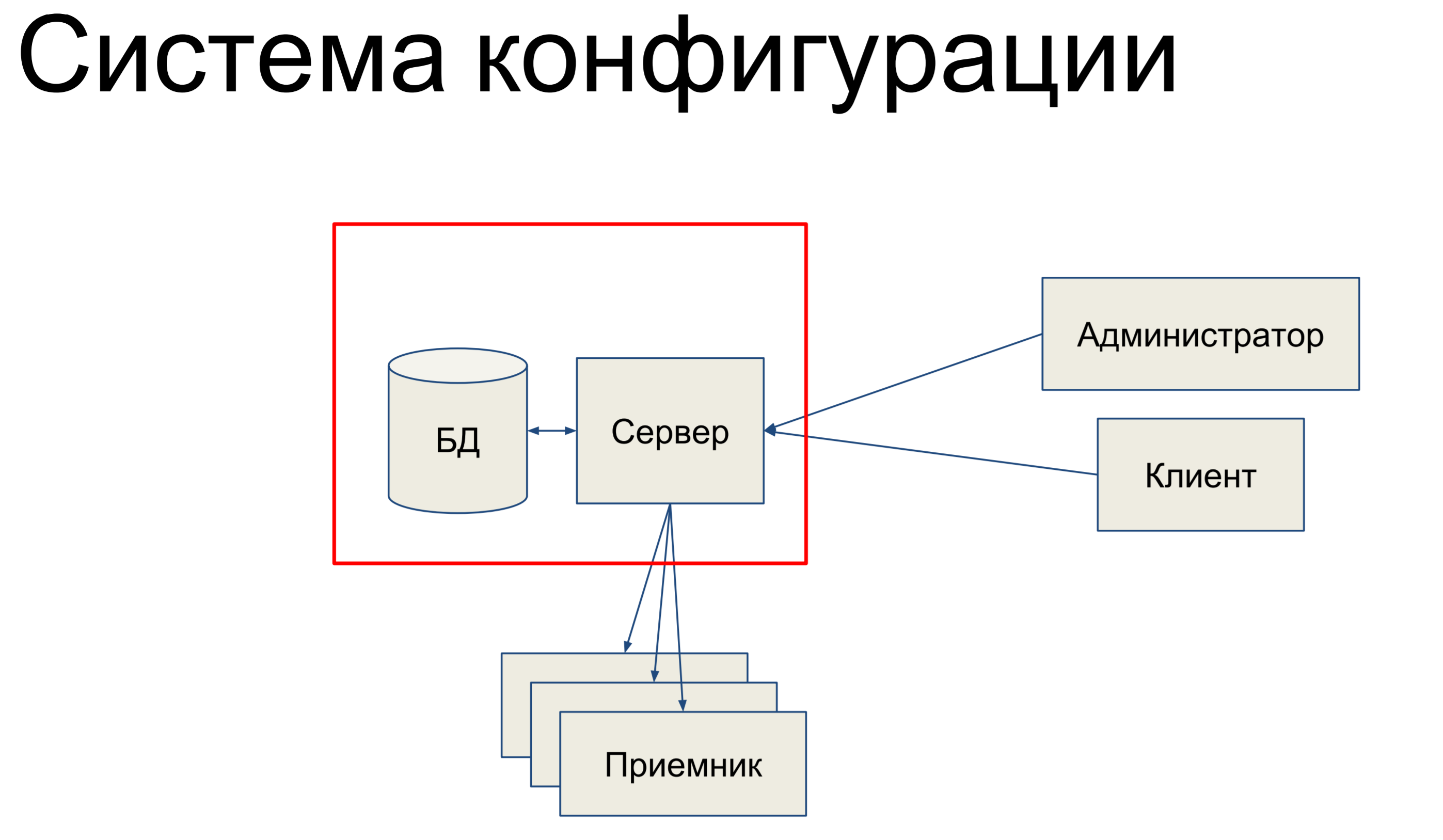
Da ist sie es, die mit der Datenbank und der Alchemie verwandt ist.

Was ist die Besonderheit dieses Systems? Es ist ziemlich klein - mittelmäßig. Hunderttausende, bis zu Millionen von Entitäten werden in dieser Datenbank gespeichert. Die Besonderheit ist, dass der Graph der Beziehungen zwischen Entitäten ziemlich komplex ist. Es gibt mehrere Vererbungshierarchien zwischen Entitäten, es gibt Einschlüsse, es gibt einfach Abhängigkeiten zwischen ihnen. Alle diese Einschränkungen werden von der Geschäftslogik bestimmt und wir müssen sie einhalten.
Das Verhältnis von Schreibanforderungen zu Leseanforderungen beträgt ungefähr 15: 1. Hier ist klar: Es gibt viele Befehle zum Ändern der Konfiguration, und einmal in einem bestimmten Zeitraum haben wir die Konfiguration an die Endpunkte verschoben.
MySQL wird intern verwendet - es ist auch in anderen Produkten unseres Unternehmens verfügbar, wir haben ziemlich ernsthaftes Fachwissen in dieser Datenbank, es gibt Leute, die damit arbeiten können: Erstellen eines Datenschemas, Entwurfsabfragen und alles andere. Daher haben wir MySQL als universelle relationale Datenbank verwendet.

Was war das Problem, nachdem wir dieses System entworfen haben? Die Ausführung eines Befehls dauerte je nach Komplexität des Teams zwischen einer und dreißig Sekunden. Dementsprechend erreichte die Verzögerung der Ausführung fünf Minuten. Ein Team traf ein - 30 Sekunden, das zweite und so weiter, ein Stapel angesammelter - eine Verzögerung von 5 Minuten.
Die Verzögerung beim Anwenden der Konfiguration beträgt bis zu zehn Minuten. Es wurde entschieden, dass dies für uns nicht ausreicht und dass eine Optimierung erforderlich ist.

Bevor eine Optimierung durchgeführt wird, muss zunächst eine Untersuchung durchgeführt werden, um herauszufinden, worum es tatsächlich geht.

Wie sich herausstellte, fehlte uns die wichtigste Komponente für die Untersuchung - wir hatten keine Telemetrie. Wenn Sie also eine Art System entwerfen, setzen Sie zunächst in der Entwurfsphase Telemetrie ein. Selbst wenn das System anfangs klein ist, dann ein bisschen mehr, dann noch mehr - am Ende kommt jeder in eine Situation, in der man Tracks sehen muss, aber es gibt keine Telemetrie.
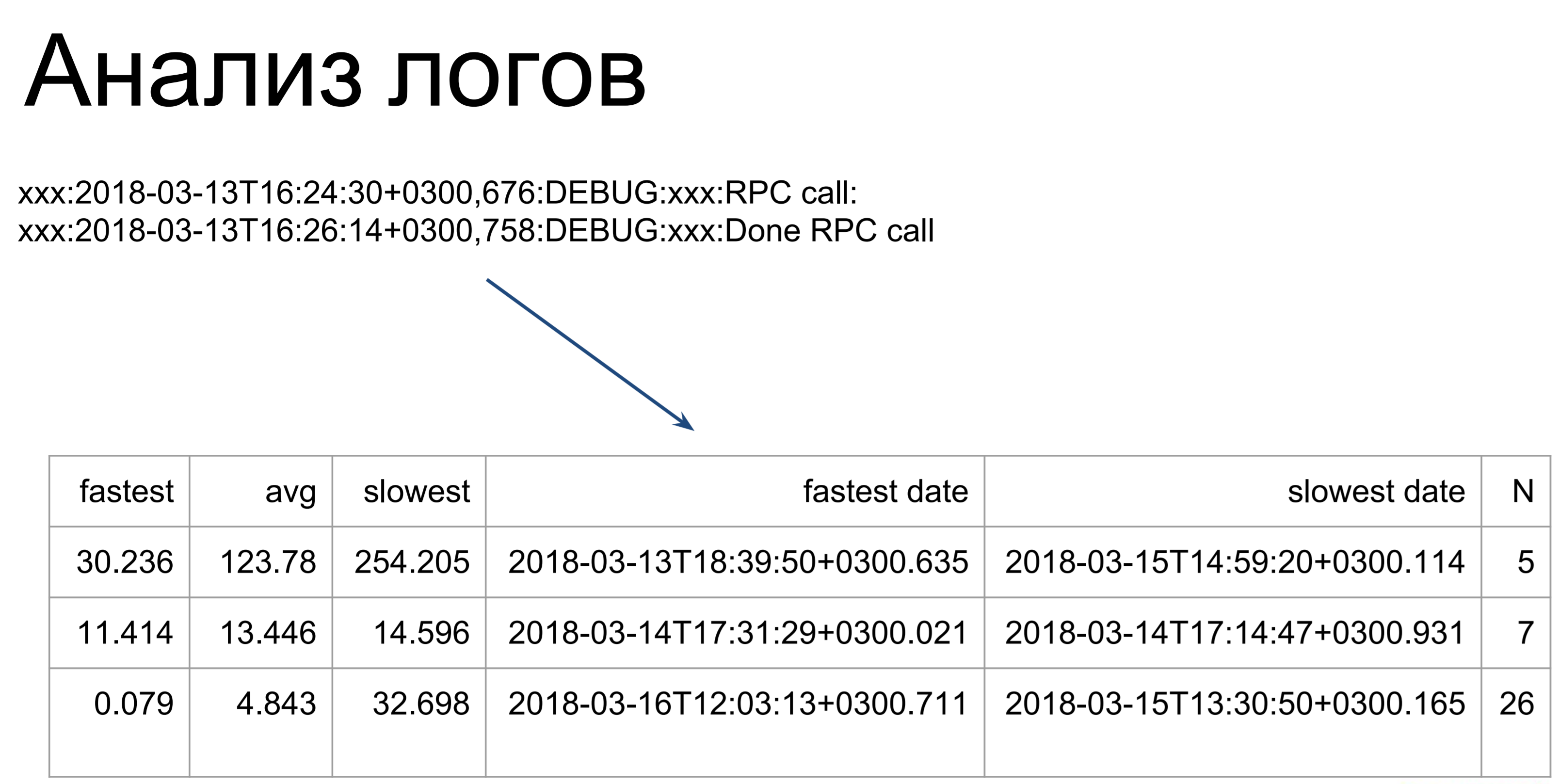
Was kann als nächstes getan werden, wenn Sie keine Telemetrie haben? Sie können die Protokolle analysieren. Hier gehen ziemlich einfache Skripte unsere Protokolle durch und wandeln sie in eine solche Tabelle um, die die schnellsten, langsamsten und durchschnittlichen Befehlsausführungszeiten darstellt. Ab hier können wir bereits sehen, an welchen Stellen wir Gags haben: Welche Teams brauchen länger, welche schneller.

Das einzige, was zu beachten ist, ist, dass bei der Analyse der Protokolle nur die Ausführungszeit dieser Befehle auf dem Server berücksichtigt wird. Dies ist die erste Stufe - die als t2 gekennzeichnete. t1 - So sieht der Client die Ausführungszeit unseres Teams: In die Warteschlange treten, warten, Ausführung auf dem Server. Diese Zeit wird länger sein, daher optimieren wir die Zeit t2 und verwenden dann die Zeit t1, um festzustellen, ob wir das Ziel erreicht haben.
t1 ist die Qualitätsmetrik unserer Leistung.

Dementsprechend haben wir auf diese Weise alle Teams profiliert - das heißt, wir haben das Protokoll vom Server genommen, es durch unsere Skripte geführt, die Komponenten gesucht und identifiziert, die am langsamsten arbeiteten. Der Server ist recht modular aufgebaut, für jeden Befehl ist eine eigene Komponente verantwortlich, und wir können die Komponenten einzeln profilieren - und Benchmarks für sie erstellen. Hier hatten wir also eine Klasse - für jede problematische Komponente, die wir geschrieben haben, in der wir in code_under_test () eine Aktivität ausgeführt haben, die den Kampfeinsatz der Komponente darstellt. Und es gab zwei Methoden: profile () und bank (). Der erste Aufruf von cProfile zeigt an, wie oft was aufgerufen wurde und wo die Engpässe liegen.
Bench () wurde mehrmals ausgeführt und hat für uns unterschiedliche Metriken berücksichtigt - so haben wir die Leistung bewertet.
Es stellte sich jedoch heraus, dass dies nicht das Problem ist!

Das Hauptproblem war die Anzahl der Datenbankabfragen. Es gab viele Anfragen, und um zu verstehen, warum es so viele gab, schauen wir uns an, wie alles organisiert war.
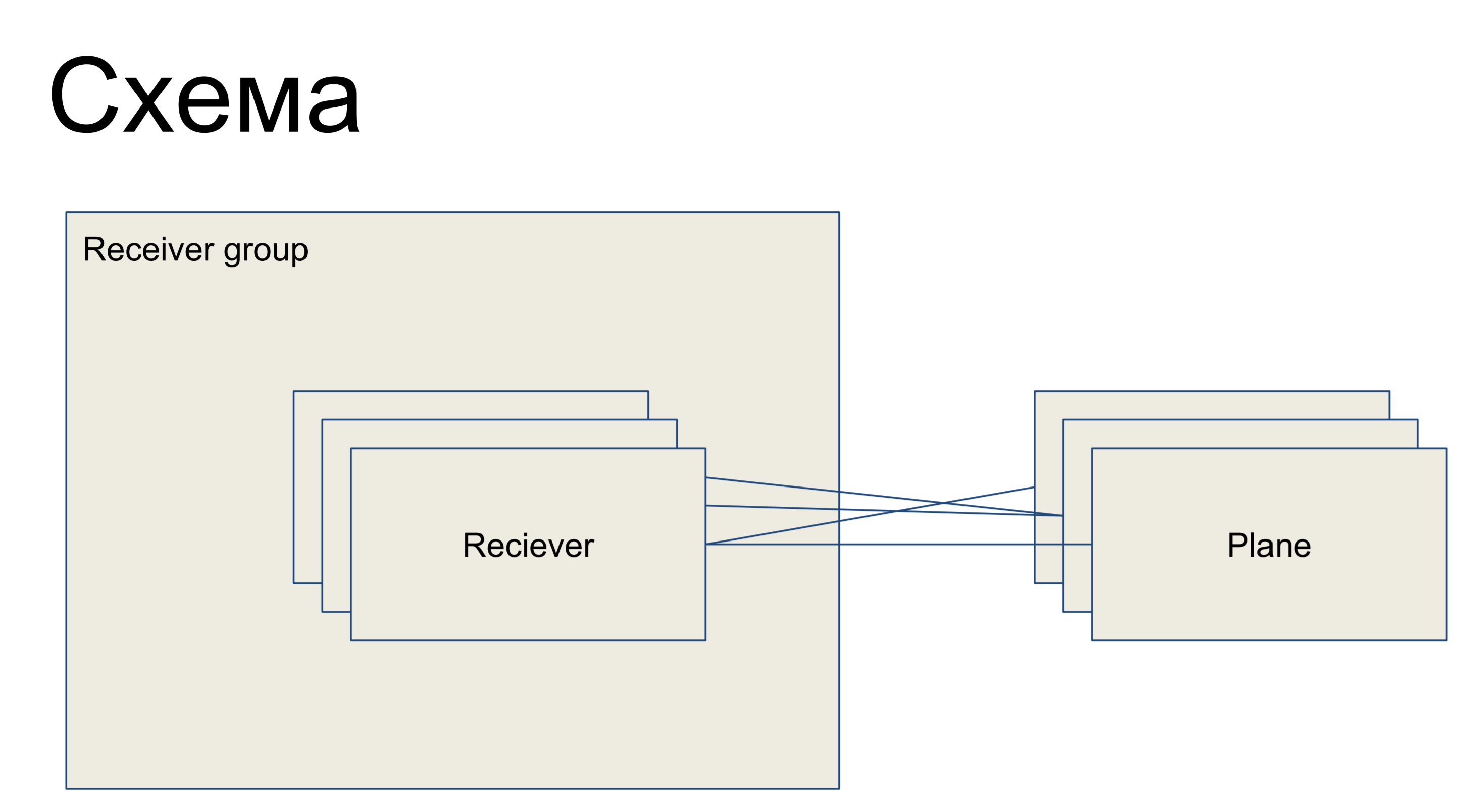
Vor uns liegt ein Teil einer einfachen Schaltung, die unsere Empfänger darstellt und in Form der Reciever-Klasse dargestellt wird. Sie sind in einer Gruppe - Empfängergruppe - vereint. Dementsprechend gibt es einige Konfigurationsebenen - Slices der Konfiguration, die eine Teilmenge der Konfigurationen sind, die für eine „Rolle“ dieses Empfängers verantwortlich sind. Zum Beispiel für Routing - Routing-Ebene. Ebenen mit Empfängern können in beliebiger Reihenfolge verbunden werden - das heißt, dies ist eine Viele-zu-Viele-Beziehung.
Dies ist ein Teil des großen Umrisses, den ich hier präsentiere, damit Beispiele besser verstanden werden können.
Was möchte jeder Architektur-Kosmonaut tun, wenn er die API eines anderen sieht? Er möchte es ausblenden, abstrahieren und seine Schnittstelle schreiben, um diese API entfernen oder vielmehr ausblenden zu können.
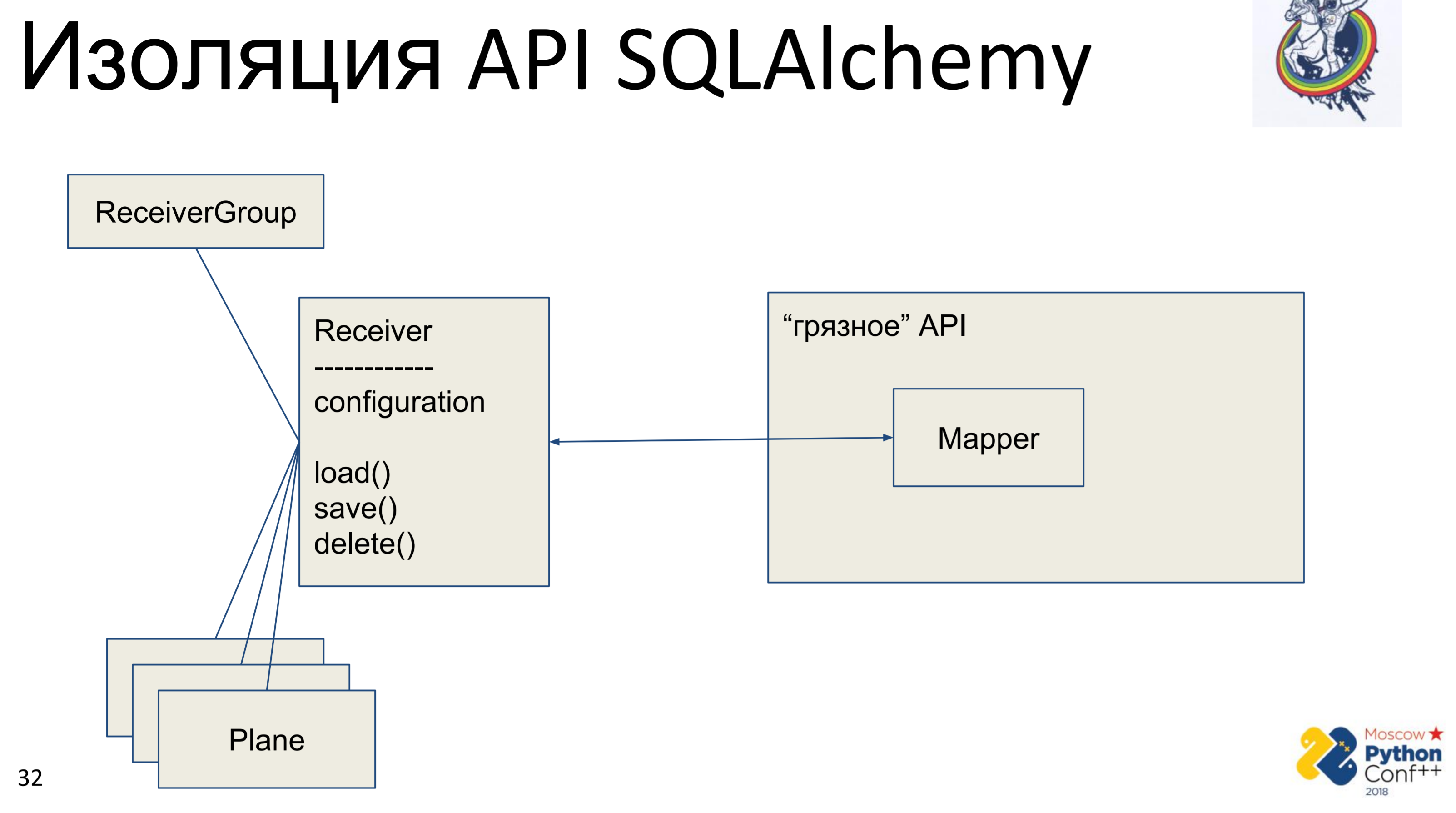
Dementsprechend gibt es eine "schmutzige" API der Alchemie, in der es tatsächlich Mapper und unsere "reine" Klasse - Receiver gibt, in der einige Konfigurationen gespeichert sind und es Methoden gibt: load (), save (), delete (). Und alle anderen damit verbundenen Klassen. Wir erhalten ein Diagramm von Python-Objekten, die irgendwie miteinander verbunden sind - jedes von ihnen verfügt über eine Methode load (), save (), delete (), die sich auf den Alchemy Mapper bezieht, der wiederum die API aufruft.

Die Implementierung hier ist sehr einfach. Wir haben eine Lademethode, die eine Abfrage an die Datenbank durchführt und für jedes empfangene Objekt ein eigenes Python-Objekt erstellt. Es gibt eine Speichermethode, die den umgekehrten Vorgang ausführt. Wenn nicht, wird ein Objekt mit dem Primärschlüssel in der Datenbank vorhanden. Andernfalls wird der Status dieses Objekts erstellt, hinzugefügt und anschließend gespeichert. Löschen auf dem Primärschlüssel empfängt und löscht das Objekt aus der Datenbank.

Das Hauptproblem ist sofort sichtbar - dies ist die Zuordnung. Zuerst machen wir es einmal vom Python-Objekt zum Mapper, dann vom Mapper zur Basis. Zusätzliche Zuordnung sind ein oder zwei Aufrufe, die möglicherweise noch nicht so beängstigend sind. Das Hauptproblem war die manuelle Synchronisation. Wir haben zwei Objekte unserer "sauberen" Oberfläche und eines davon ändert das Attribut - wie sehen wir, dass sich das Attribut im anderen geändert hat? Auf keinen Fall. Es ist erforderlich, die Änderungen in der Datenbank zusammenzuführen und das Attribut in einem anderen Objekt abzurufen. Wenn wir wissen, dass Objekte im selben Kontext vorhanden sind, können wir dies natürlich irgendwie verfolgen. Aber wenn wir zwei Sitzungen an verschiedenen Orten haben - nur über die Basis oder blockieren Sie die Basis im Speicher, was wir nicht getan haben.
Dieses Laden / Speichern / Löschen ist ein weiterer Mapper, der die Innenseiten der Alchemie vollständig dupliziert, was gut geschrieben und getestet ist. Dieses Tool ist viele Jahre alt, es gibt eine Menge Hilfe im Internet und das Duplizieren ist auch nicht sehr gut.
Sehen Sie das Symbol in der oberen rechten Ecke? Also werde ich die Folien markieren, auf denen etwas für "Reinheit" getan wird, um den Abstraktionsgrad für die architektonische Astronautik zu erhöhen. Das heißt, Folien ohne dieses Symbol sind pragmatisch und langweilig, uninteressant und können nicht gelesen werden.
Was tun, wenn viele Abfragen langsam sind? Wie viele? Eigentlich viel. Stellen Sie sich eine Vererbungskette vor: Ein Objekt hat ein Elternteil, dieses hat ein anderes Elternteil. Wir synchronisieren das untergeordnete Objekt. Dazu müssen Sie zuerst die übergeordneten Objekte synchronisieren. Um ein übergeordnetes Element zu synchronisieren, müssen Sie das übergeordnete Element synchronisieren. Nun, alle waren synchronisiert. Abhängig davon, wie wir das Diagramm erstellt haben, können wir alle diese Objekte hundertmal durchlaufen und synchronisieren - daher eine große Anzahl von Anforderungen.
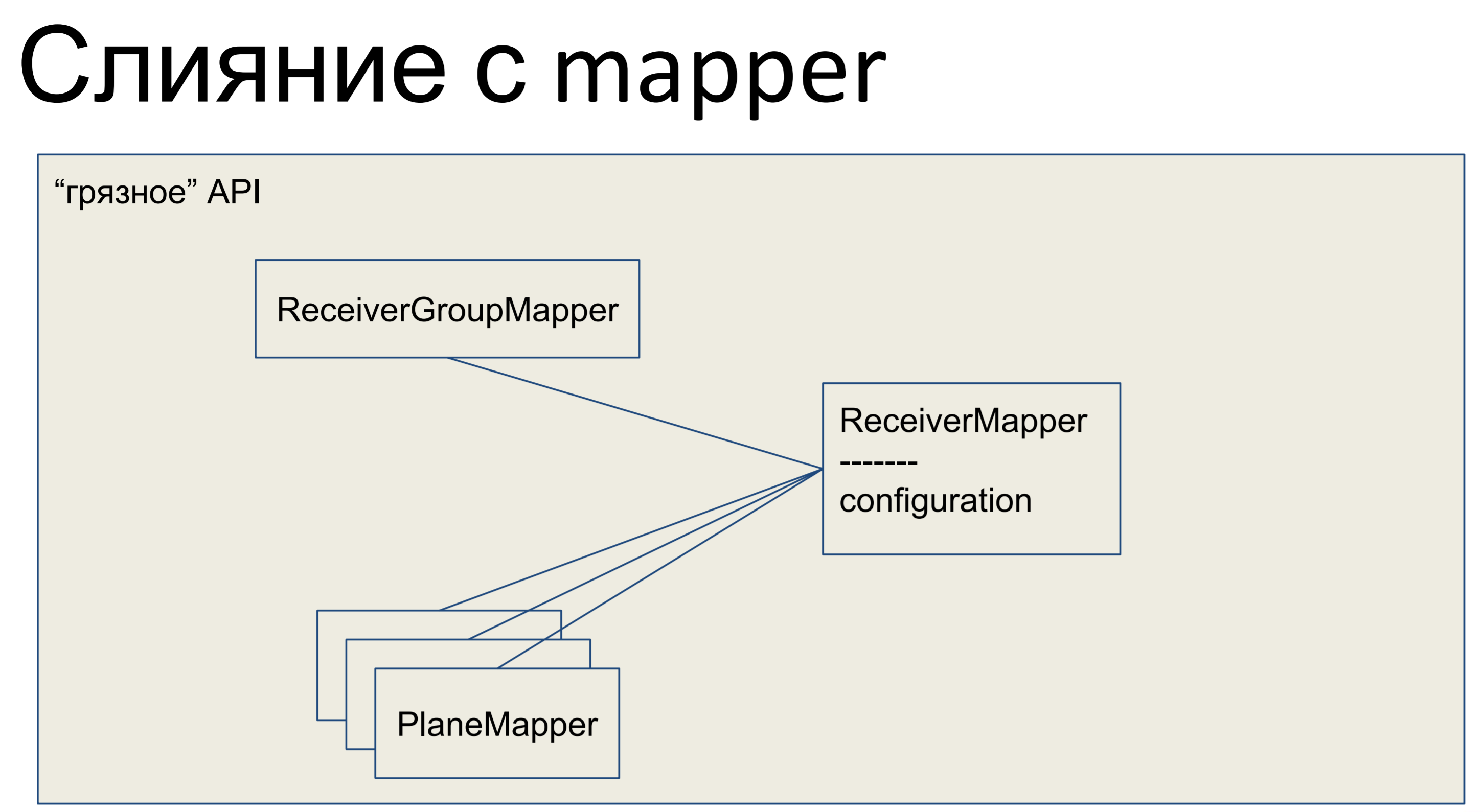
Was haben wir getan Wir haben unsere gesamte Geschäftslogik übernommen und in den Mapper gesteckt. Alle anderen Objekte hier wurden ebenfalls mit den Mappern zusammengeführt, und unsere gesamte API, die gesamte Datenabstraktionsschicht, erwies sich als fehlerhaft.

So sieht es in Python aus - unser Mapper hat eine Art Geschäftslogik, genau dort gibt es eine deklarative Beschreibung dieser Platte. Spalten werden aufgelistet, Beziehungen. Hier haben wir eine solche Klasse.

Aus Sicht eines jeden Astronauten ist eine schmutzige API natürlich ein Nachteil. Geschäftslogik in einer deklarativen Beschreibung der Basis. Schemata werden mit Geschäftslogik gemischt. Puh. Hässlich.
Die Beschreibung der Schaltung ist unübersichtlich. Dies ist tatsächlich ein Problem - wenn die Geschäftslogik nicht aus zwei Zeilen, sondern aus einem größeren Volumen besteht, müssen wir in dieser Klasse sehr lange scrollen oder suchen, um zu bestimmten Beschreibungen zu gelangen. Davor war alles schön: an einem Ort die Beschreibung der Basis, deklarativ, Beschreibung der Schemata, an einem anderen Ort Geschäftslogik. Und dann ist die Schaltung überfüllt.
Andererseits erhalten wir sofort die Mechanismen der Alchemie: Arbeitseinheit, mit der Sie verfolgen können, welche Objekte verschmutzt sind und welche Relais aktualisiert werden müssen; Wir erhalten eine Beziehung, die es uns ermöglicht, zusätzliche Fragen in der Datenbank zu entfernen, ohne sicherzustellen, dass die relevanten Sammlungen gefüllt sind. und die Identitätskarte, die uns am meisten geholfen hat. Die Identitätszuordnung stellt sicher, dass zwei Python-Objekte dasselbe Python-Objekt sind, wenn sie denselben Primärschlüssel haben.
Dementsprechend haben wir die Komplexität sofort auf linear reduziert.

Dies sind Zwischenergebnisse. Die Leistung stieg sofort um das Zehnfache, die Anzahl der Abfragen an die Datenbank sank um das 40-80-fache und der RPS stieg auf 1-5. Gut. Aber die API ist schmutzig. Was zu tun ist?
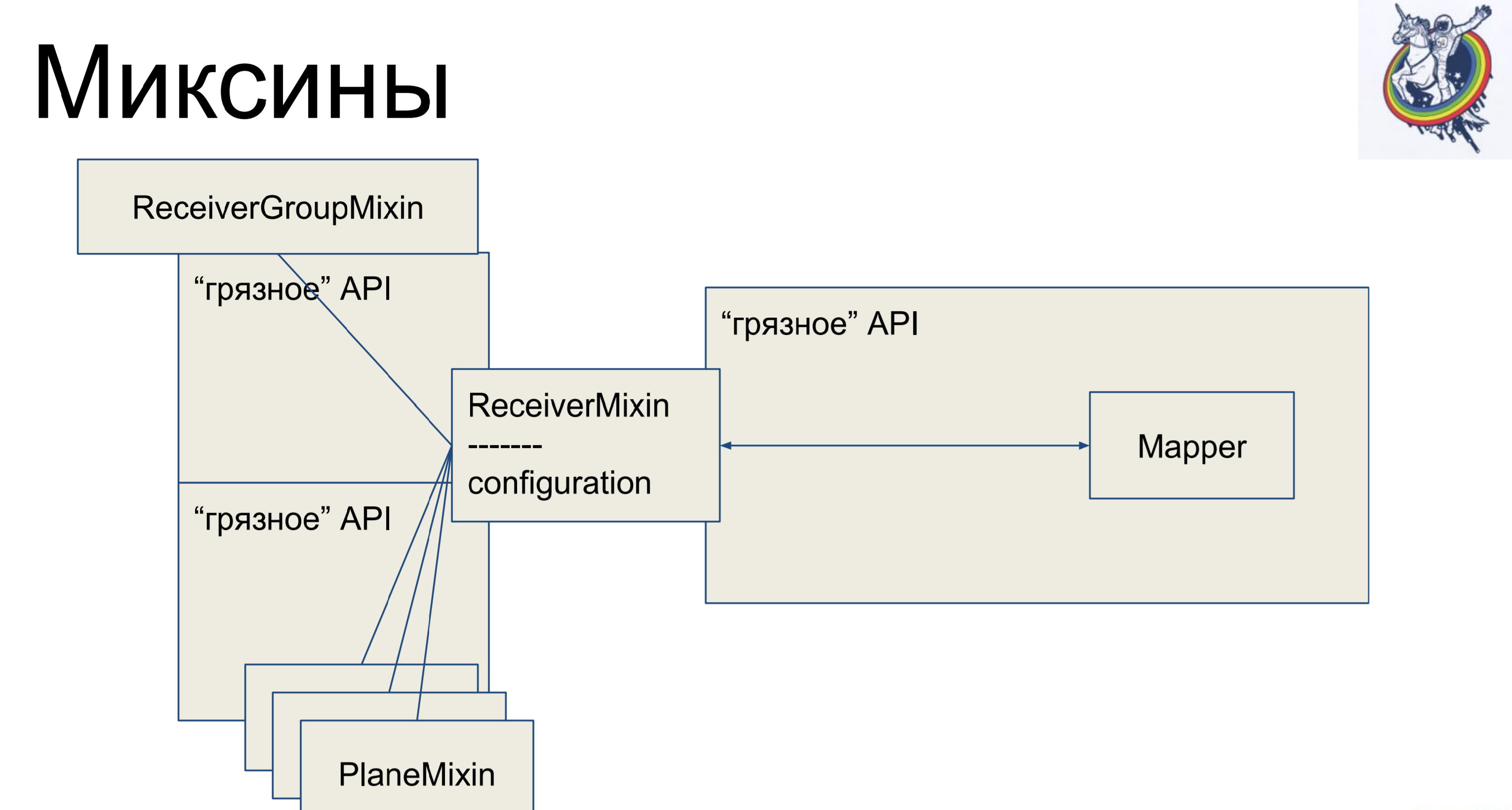
Mixins. Wir nehmen die Geschäftslogik, entfernen sie wieder aus unserem Mapper, aber damit es kein Mapping mehr gibt, erben wir unseren Mapper innerhalb der Alchemie von unserem Mixin. Warum nicht umgekehrt? Dies wird in der Alchemie nicht funktionieren, sie wird schwören und sagen: "Sie haben zwei verschiedene Klassen, die sich auf eine Tablette beziehen, es gibt keinen Polyformismus - gehen Sie von hier aus." Und so - es ist möglich.
Wir haben also eine deklarative Beschreibung im Mapper, die vom Mixin geerbt wird und die gesamte Geschäftslogik empfängt. Sehr bequem. Und der Rest der Klassen ist genau das gleiche. Es scheint - cool, alles ist sauber. Es gibt jedoch eine Einschränkung: Verbindungen und Relais verbleiben in der Alchemie, und wenn wir uns beispielsweise durch eine sekundäre Zwischenplatten-Tabelle verbinden, ist der Mapper dieser Platte irgendwie im Client-Code vorhanden, was nicht sehr schön ist.
Die Alchemie wäre kein so guter, berühmter Rahmen gewesen, wenn sie mir nicht die Gelegenheit gegeben hätte, dagegen anzukämpfen.

Wie sieht ein Mixin aus? Er hat Geschäftslogik, Mapper separat, eine deklarative Beschreibung der Platte. Verbindungen bleiben innerhalb der Alchemie, aber die Geschäftslogik ist getrennt.
Wie sieht der allgemeine Umriss aus?
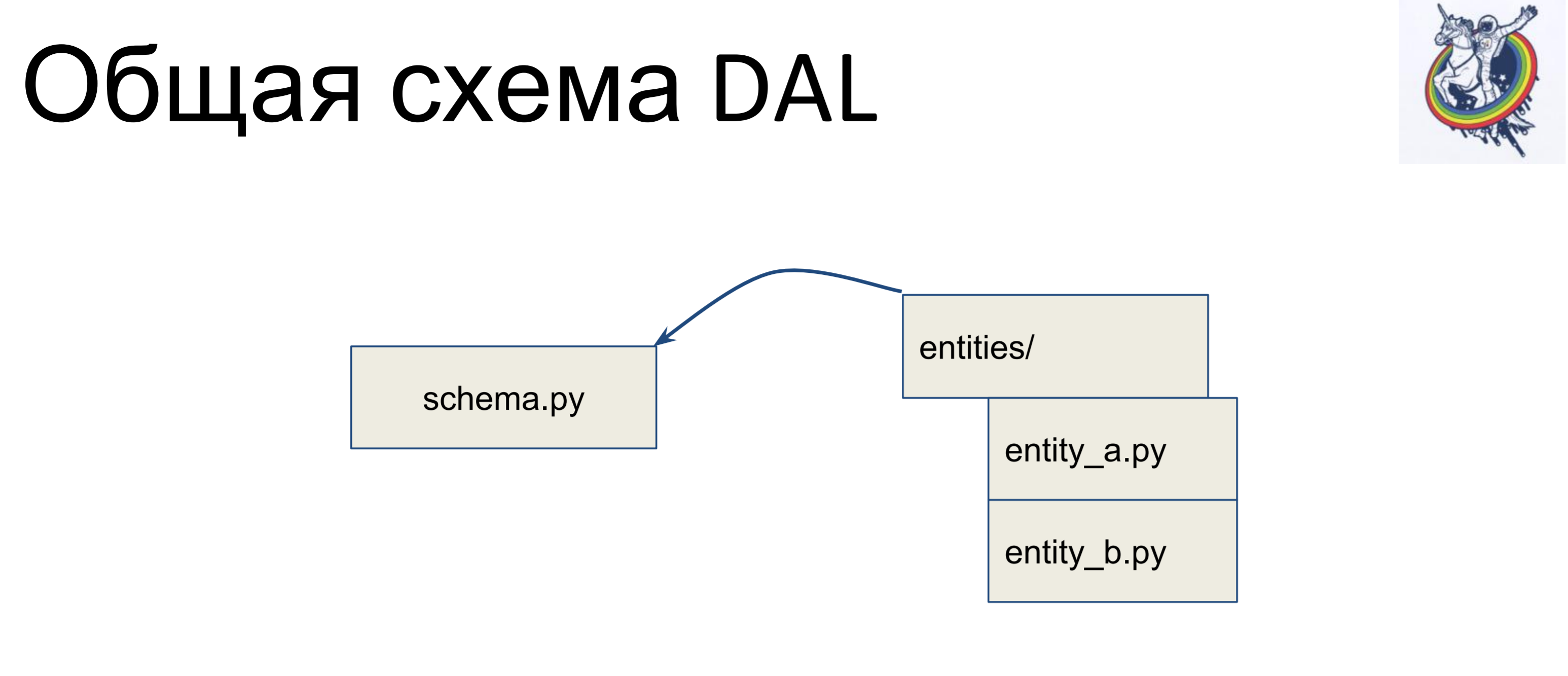
Wir haben eine Datei mit einem Schema, in dem alle unsere deklarativen Klassen gesammelt werden - nennen wir es schema.py. Und wir haben Entitäten in der Geschäftslogik separat. Diese Entitäten werden in der Schemadatei vererbt. Wir schreiben für jede Entität eine separate Klasse und erben sie im Schema. Somit liegt die Geschäftslogik in einem Haufen, das Schema in einem anderen und sie können unabhängig voneinander geändert werden.
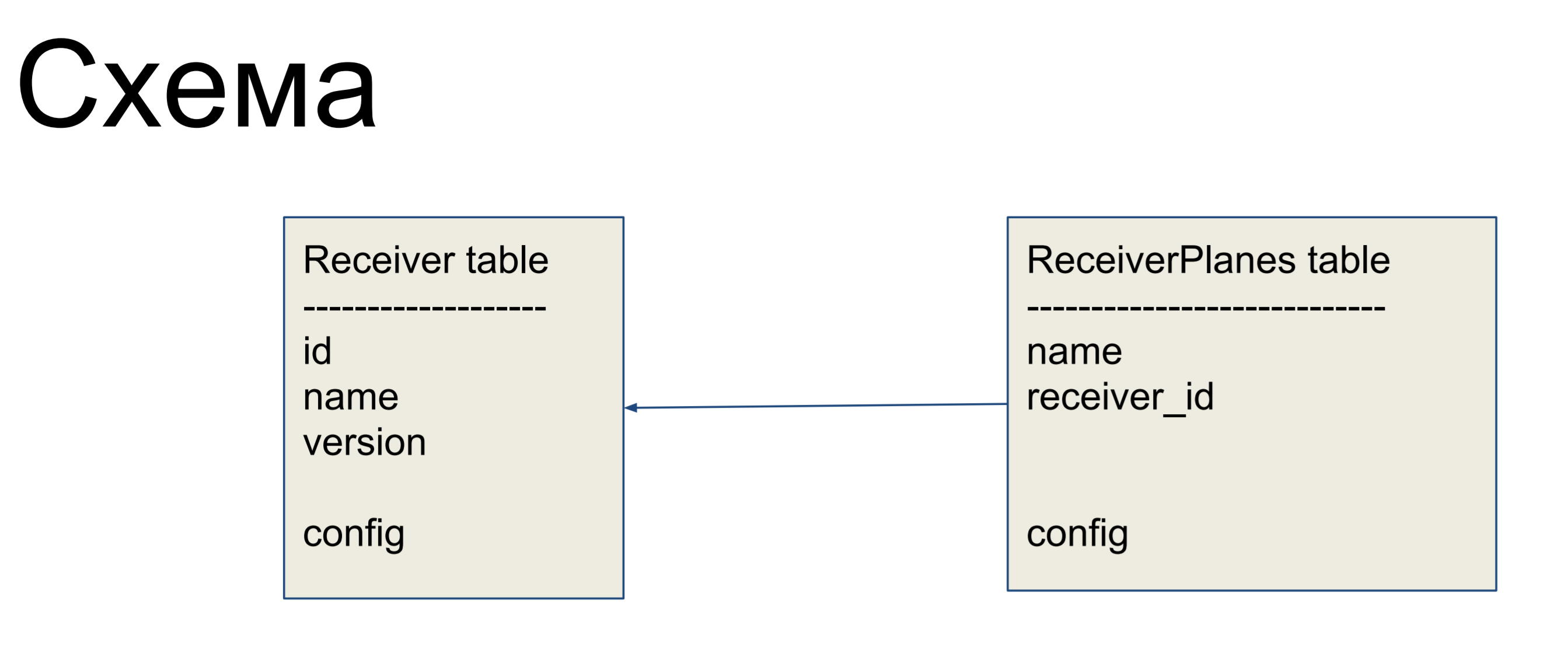
Als Beispiel für eine Verbesserung betrachten wir ein einfaches Schema aus zwei Bezeichnungen: Empfänger (Empfängertabelle) und Slices der Konfiguration (ReceiverPlanes-Tabelle). Dem Empfängeretikett sind mehrere Konfigurationsscheiben zugeordnet. Es gibt nichts besonders kompliziertes.
Um Beziehungen innerhalb der „schmutzigen“ Schnittstelle der Alchemie zu verbergen, verwenden wir Beziehungen und Sammlungen.

Sie ermöglichen es uns, unsere Mapper vor dem Client-Code zu verbergen.

Insbesondere sind zwei sehr nützliche Sammlungen Associated_proxy und attribute_mapped_collection. Wir benutzen sie zusammen. Wie die klassische Beziehung in der Alchemie funktioniert: Wir haben eine Beziehung - dies ist eine bestimmte Sammlung, Liste, Mapper. Mapper sind weit entfernte Beziehungsobjekte. Mit Attribute_mapped_collection können Sie diese Liste durch ein Diktat ersetzen, dessen Schlüssel einige der Attribute der Mapper sind und deren Werte die Mapper selbst sind.
Dies ist der erste Schritt.
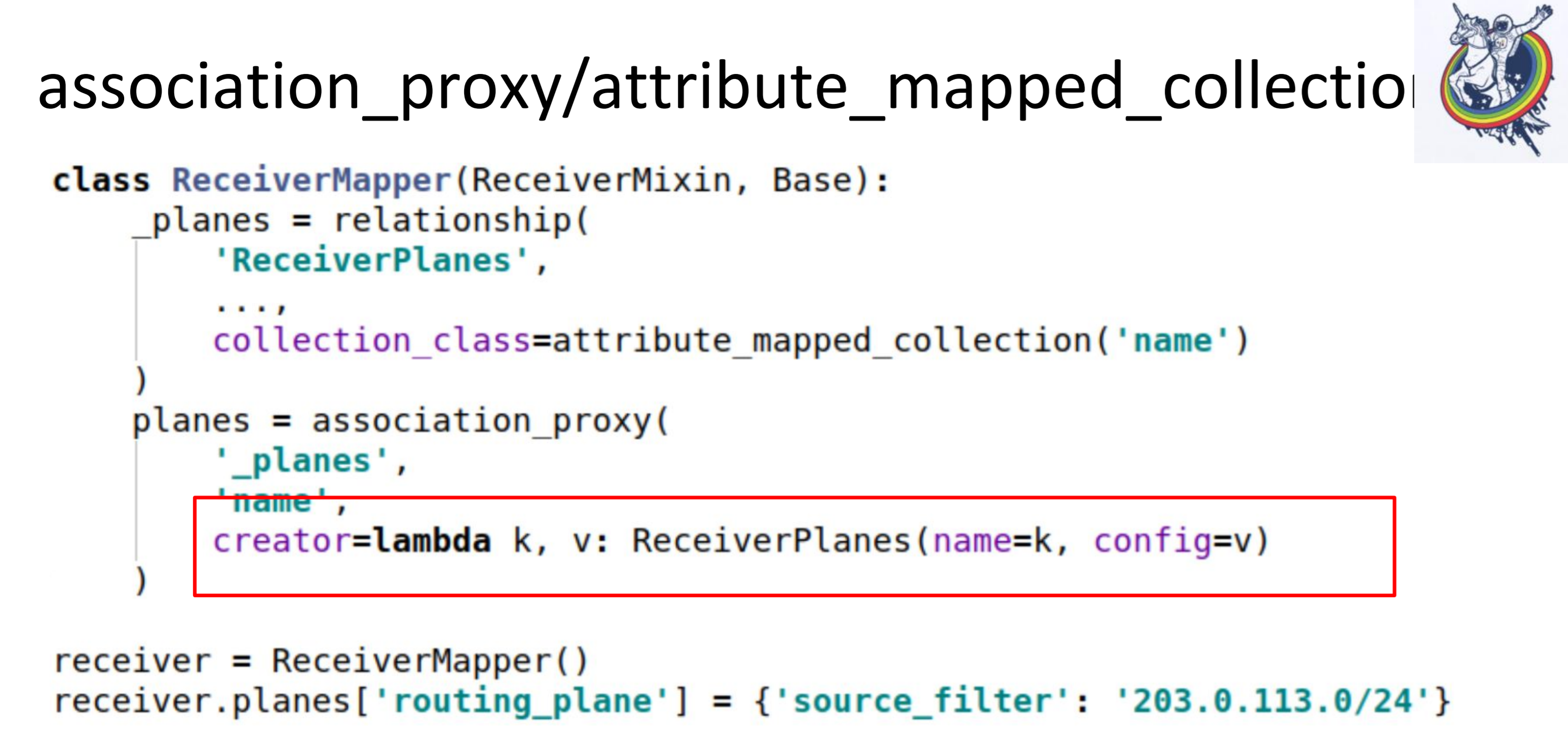
Im zweiten Schritt führen wir Association_Proxy über diese Beziehung aus. Es erlaubt uns, den Mapper nicht an die Sammlung zu übergeben, sondern einen Wert zu übergeben, der später zum Initialisieren unseres Mappers ReceiverPlanes verwendet wird.
Hier haben wir Lambda, in dem wir den Schlüssel und den Wert übergeben. Der Schlüssel wird zum Namen des Konfigurations-Slice und der Wert zum Wert des Konfigurations-Slice. Infolgedessen sieht im Client-Code alles so aus.

Wir haben nur eine Art Diktat in eine Art Wörterbuch eingefügt. Alles funktioniert: keine Mapper, keine Alchemie, keine Datenbanken.
Es stimmt, es gibt Fallstricke.

Wenn wir demselben Schlüssel zweimal unterschiedliche oder sogar einen Wert zuweisen - Lambda wird für jedes dieser festgelegten Elemente aufgerufen, wird ein Objekt erstellt - ein Mapper. Und je nach Struktur des Schemas kann dies zu verschiedenen Konsequenzen führen, von „nur Verstößen gegen die Konstanten“ bis zu unvorhersehbaren Konsequenzen. Sie haben beispielsweise ein Objekt aus der Sammlung gelöscht, es ist jedoch weiterhin dort geblieben: Sie haben nur eines gelöscht. Als ich anfing, habe ich viel Zeit mit solchen Dingen verbracht.
Und eine kleine implizite Synchronisation. Association_proxy und attribute_mapped_collection können etwas verzögert sein: Wenn wir ein Mapper-Objekt erstellen, wird es der Datenbank hinzugefügt, ist jedoch noch nicht im Auflistungsattribut vorhanden. Es wird dort nur angezeigt, wenn das Attribut in dieser Sitzung abläuft. Wenn es abläuft, wird eine neue Synchronisation mit der Datenbank durchgeführt und es wird dort ankommen.
Um dies zu überwinden, haben wir unsere eigenen, selbst geschriebenen Sammlungen verwendet. Dies ist nicht einmal Alchemie - Sie können einfach Ihre eigene Sammlung erstellen, um all dies zu überwinden.
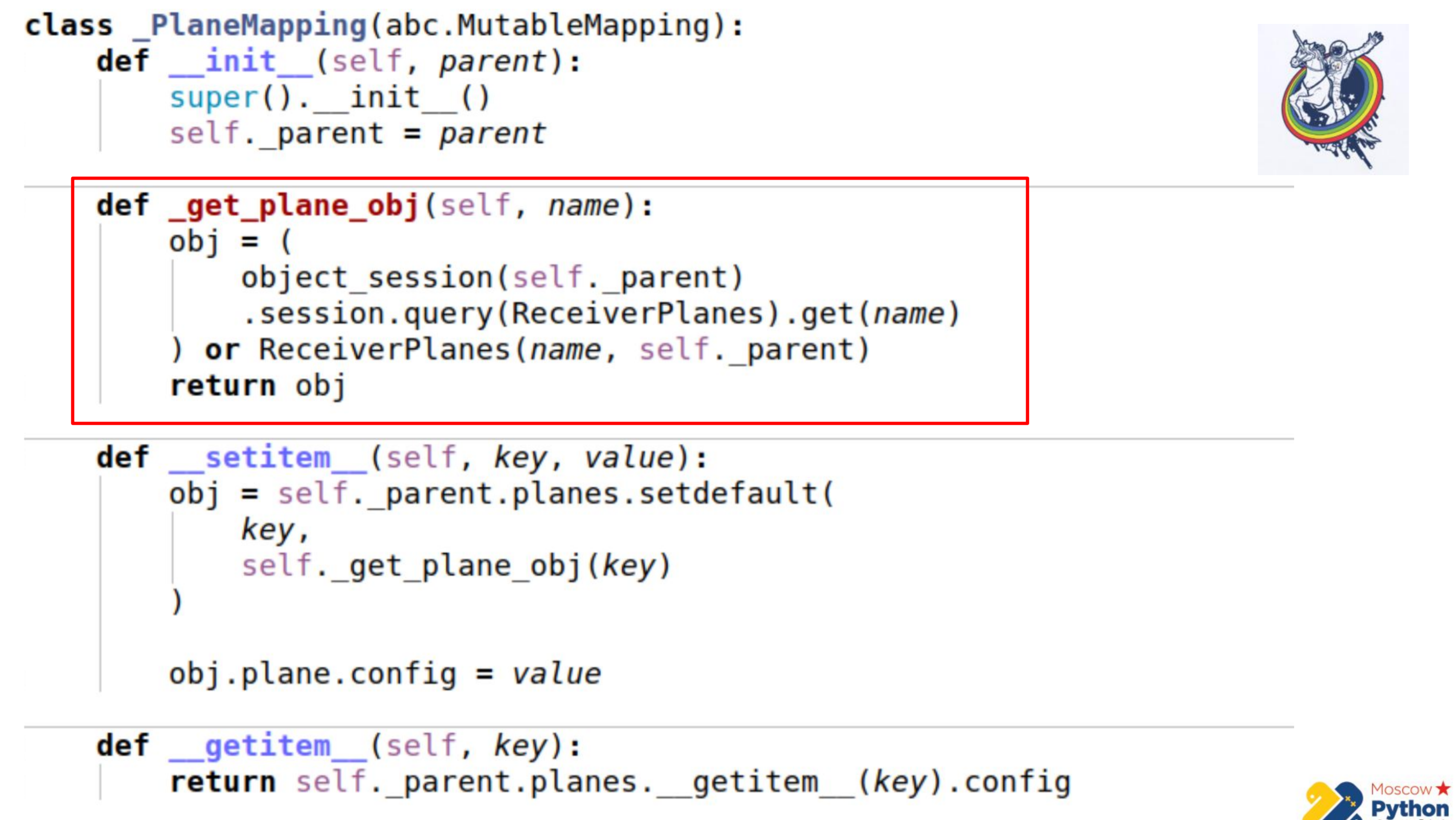
Es gibt mehr Code und der wichtigste Teil wird hervorgehoben. Wir haben eine bestimmte Sammlung, die von veränderlichen Zuordnungen erbt - dies ist ein Diktat, in dessen Schlüsseln Sie die Werte ändern können. Und es gibt eine _get_plane_obj-Methode, um das Konfigurations-Slice-Objekt abzurufen.
Hier machen wir einfache Dinge - wir versuchen, es durch Namen, durch einen Primärschlüssel zu erhalten, und wenn dies nicht der Fall ist, erstellen wir dieses Objekt und geben es zurück.
Als nächstes definieren wir nur zwei Methoden neu: __setitem__ und __getitem__
In __setitem__ fügen wir diese Objekte in einer Sammlung in unsere Sammlung ein. Das einzige ist, dass wir ganz am Ende Wert zuweisen. Daher implementieren wir den gleichen Mechanismus wie assoziations_proxy - übergeben Sie den Wert, diktieren Sie dort und er wird dem entsprechenden Attribut zugewiesen.
__getitem__ führt die umgekehrte Manipulation durch. Es empfängt per Schlüssel ein Objekt vom Relais und gibt sein Attribut zurück. Hier gibt es auch eine kleine Gefahr: Wenn Sie die Sammlung in unserem Mapping zwischenspeichern, kann es sein, dass die Synchronisation etwas ausfällt. Denn wenn das Attribut der Sammlung in der Alchemie abgelaufen ist, wird die Sammlung nach Ablauf durch eine andere ersetzt. Daher können wir den Verweis auf die alte Sammlung beibehalten und wissen nicht, dass die alte abgelaufen ist und eine neue bereits erschienen ist. Daher gehen wir im letzten Teil direkt zur Instanz der Alchemie, erhalten die Sammlung erneut über __getattr__ und machen __getitem__ damit. Das heißt, wir können die Planes-Sammlung hier nicht zwischenspeichern.
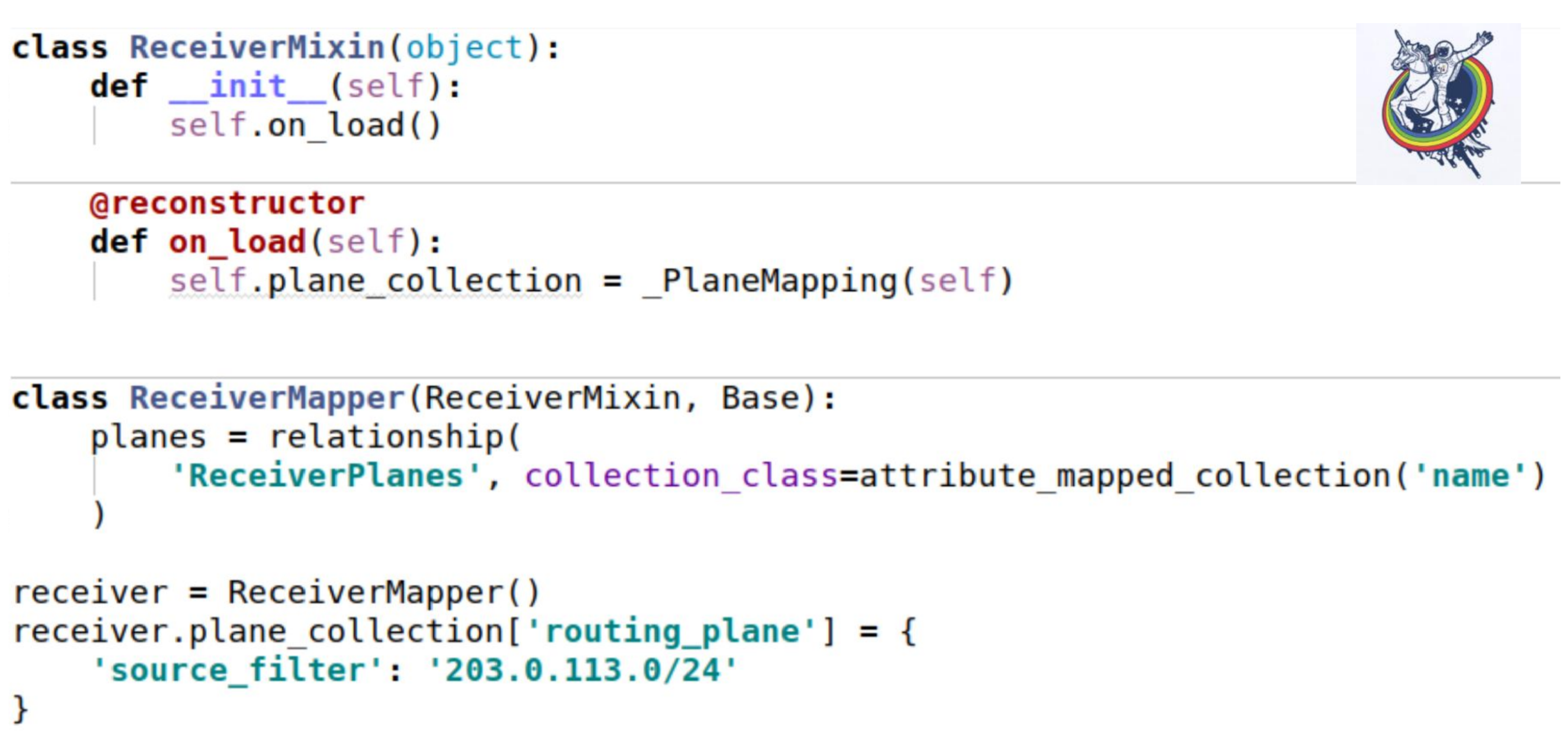
Wie schlägt diese Sammlung auf unsere Mixins? Richten Sie wie gewohnt ein Sammlungsattribut ein.
Der einzig interessante Ort ist, dass beim Laden einer Instanz aus der Datenbank die Methode __init__ nicht aufgerufen wird. Alle Attribute werden nachträglich ersetzt.Alchemy bietet einen Standard-Rekonstruktor-Dekorator, mit dem Sie eine Methode als aufgerufen markieren können, nachdem Sie ein Objekt aus der Datenbank geladen haben. Und gerade beim Booten müssen wir unsere Sammlung initialisieren. Selbst ist genau diese Instanz. Die Verwendung ist genau die gleiche wie im vorherigen Beispiel.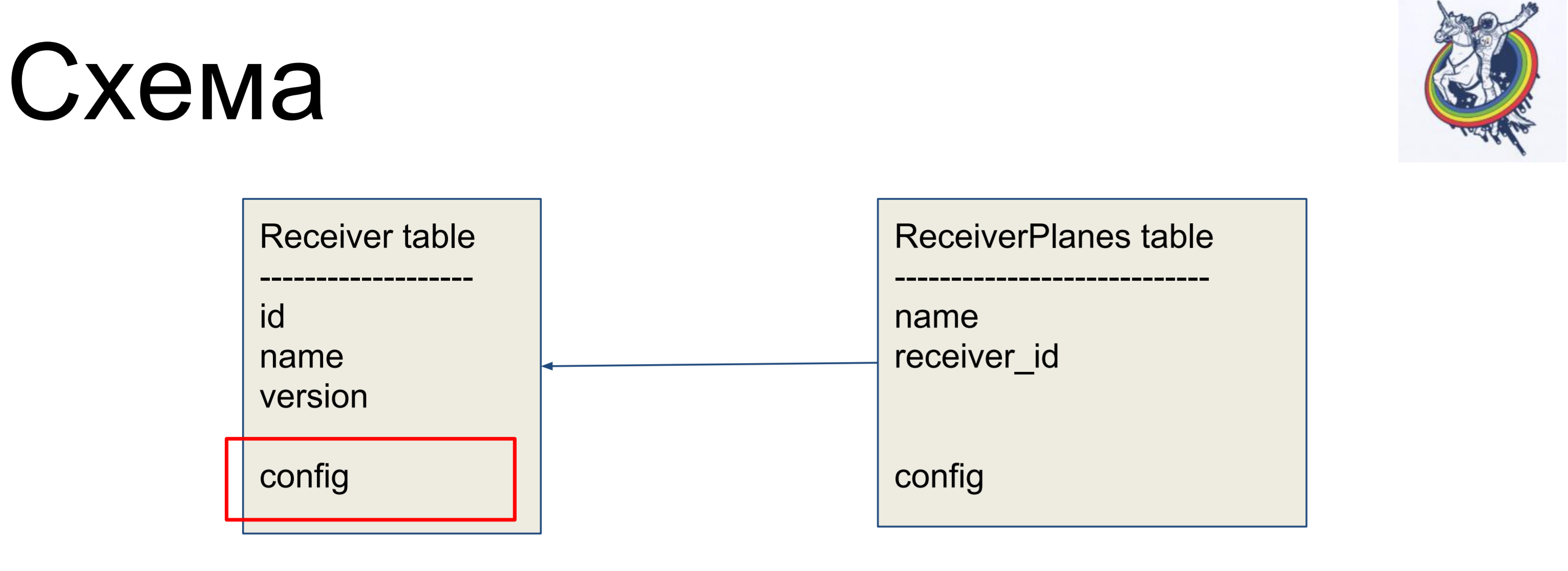 In unserem Schema sind die Ohren der Datenbank jedoch weiterhin sichtbar - dies ist die Konfiguration. Welche Art von Konfiguration? Ist es varchar oder ist es blob? In der Tat ist der Kunde nicht interessiert. Er muss mit abstrakten Entitäten seiner Ebene arbeiten. Dafür bietet die Alchemie eine Art Dekoration.
In unserem Schema sind die Ohren der Datenbank jedoch weiterhin sichtbar - dies ist die Konfiguration. Welche Art von Konfiguration? Ist es varchar oder ist es blob? In der Tat ist der Kunde nicht interessiert. Er muss mit abstrakten Entitäten seiner Ebene arbeiten. Dafür bietet die Alchemie eine Art Dekoration. Ein einfaches Beispiel. Unsere Datenbank speichert IPAddress als varchar. Wir verwenden die TypeDecorator-Klasse, die Teil der Alchemie ist und die es ermöglicht, zum einen anzugeben, welcher zugrunde liegende Datenbanktyp für diesen Typ verwendet wird, und zum anderen zwei Parameter zu definieren: process_bind_param, die den Wert in den Datenbanktyp konvertieren, und process_result_value, wenn wir bewerten Konvertieren Sie vom Datenbanktyp in ein Python-Objekt.Das Attribut from address nimmt den Python-Typ IPAddress an. Und wir können beide Methoden dieses Typs aufrufen und Objekte dieses Typs zuweisen, und alles funktioniert für uns. Und es ist in der Datenbank gespeichert ... Ich weiß nicht, was gespeichert ist, varchar (45), aber wir können diese Zeile ersetzen und der Blob wird gespeichert. Wenn ein nativer Typ IP-Adressen unterstützt, können Sie ihn verwenden.Der Client-Code hängt nicht davon ab, er muss nicht neu geschrieben werden.
Ein einfaches Beispiel. Unsere Datenbank speichert IPAddress als varchar. Wir verwenden die TypeDecorator-Klasse, die Teil der Alchemie ist und die es ermöglicht, zum einen anzugeben, welcher zugrunde liegende Datenbanktyp für diesen Typ verwendet wird, und zum anderen zwei Parameter zu definieren: process_bind_param, die den Wert in den Datenbanktyp konvertieren, und process_result_value, wenn wir bewerten Konvertieren Sie vom Datenbanktyp in ein Python-Objekt.Das Attribut from address nimmt den Python-Typ IPAddress an. Und wir können beide Methoden dieses Typs aufrufen und Objekte dieses Typs zuweisen, und alles funktioniert für uns. Und es ist in der Datenbank gespeichert ... Ich weiß nicht, was gespeichert ist, varchar (45), aber wir können diese Zeile ersetzen und der Blob wird gespeichert. Wenn ein nativer Typ IP-Adressen unterstützt, können Sie ihn verwenden.Der Client-Code hängt nicht davon ab, er muss nicht neu geschrieben werden.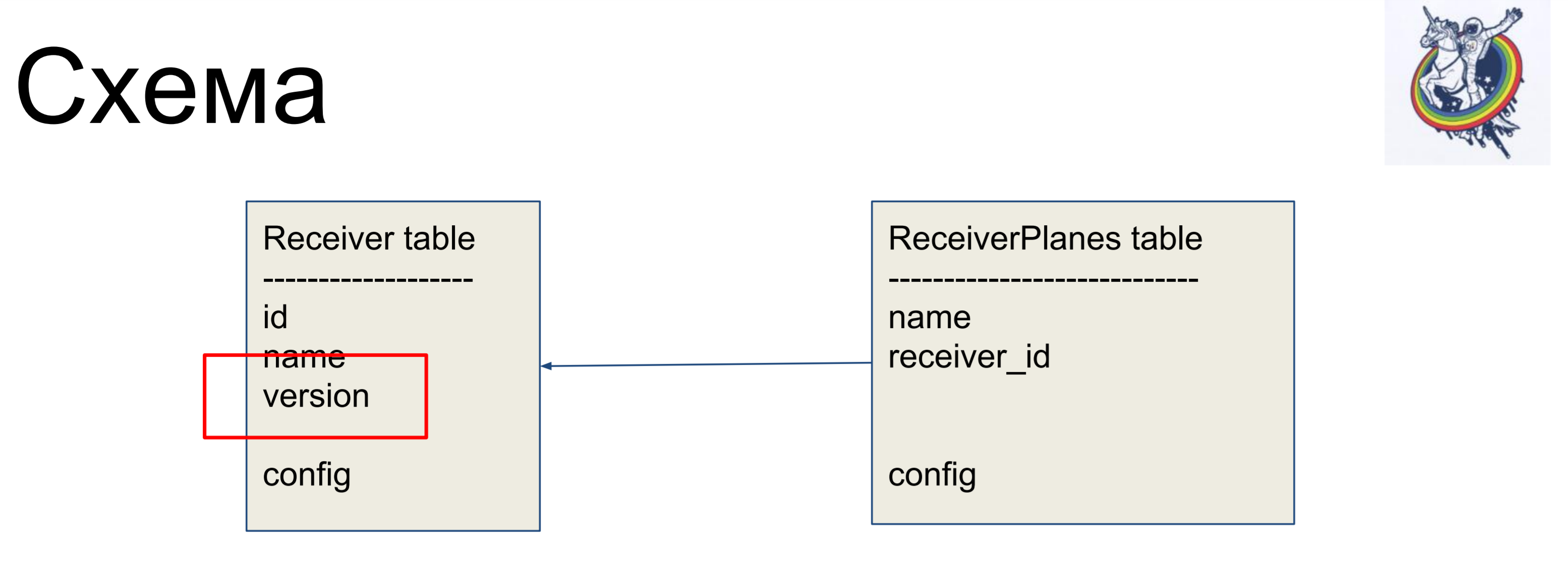 Eine andere interessante Sache ist, dass wir eine Version haben. Wir möchten, dass die Version sofort erhöht wird, sobald wir unser Objekt ändern. Wir haben einen Versionszähler, wir haben das Objekt geändert - es hat sich geändert, die Version hat sich erhöht. Wir machen das automatisch, um nicht zu vergessen.
Eine andere interessante Sache ist, dass wir eine Version haben. Wir möchten, dass die Version sofort erhöht wird, sobald wir unser Objekt ändern. Wir haben einen Versionszähler, wir haben das Objekt geändert - es hat sich geändert, die Version hat sich erhöht. Wir machen das automatisch, um nicht zu vergessen. Dafür haben wir Ereignisse verwendet. Ereignisse sind Ereignisse, die in verschiedenen Lebensphasen eines Mappers auftreten. Sie können ausgelöst werden, wenn sich Attribute ändern, wenn eine Entität von einem Status in einen anderen wechselt, z. B. "erstellt", "in der Datenbank gespeichert", "aus der Datenbank geladen", "gelöscht". und auch - bei Ereignissen auf Sitzungsebene, bevor der SQL-Code an die Datenbank ausgegeben wird, vor dem Festschreiben, nach dem Festschreiben und auch nach dem Rollback.Mit Alchemy können wir Handler für alle diese Ereignisse zuweisen, aber die Reihenfolge, in der Handler für dasselbe Ereignis ausgeführt werden, ist nicht garantiert. Das heißt, es ist spezifisch, aber es ist nicht bekannt, welches. Wenn Ihnen die Ausführungsreihenfolge wichtig ist, müssen Sie daher einen Registrierungsmechanismus durchführen.
Dafür haben wir Ereignisse verwendet. Ereignisse sind Ereignisse, die in verschiedenen Lebensphasen eines Mappers auftreten. Sie können ausgelöst werden, wenn sich Attribute ändern, wenn eine Entität von einem Status in einen anderen wechselt, z. B. "erstellt", "in der Datenbank gespeichert", "aus der Datenbank geladen", "gelöscht". und auch - bei Ereignissen auf Sitzungsebene, bevor der SQL-Code an die Datenbank ausgegeben wird, vor dem Festschreiben, nach dem Festschreiben und auch nach dem Rollback.Mit Alchemy können wir Handler für alle diese Ereignisse zuweisen, aber die Reihenfolge, in der Handler für dasselbe Ereignis ausgeführt werden, ist nicht garantiert. Das heißt, es ist spezifisch, aber es ist nicht bekannt, welches. Wenn Ihnen die Ausführungsreihenfolge wichtig ist, müssen Sie daher einen Registrierungsmechanismus durchführen.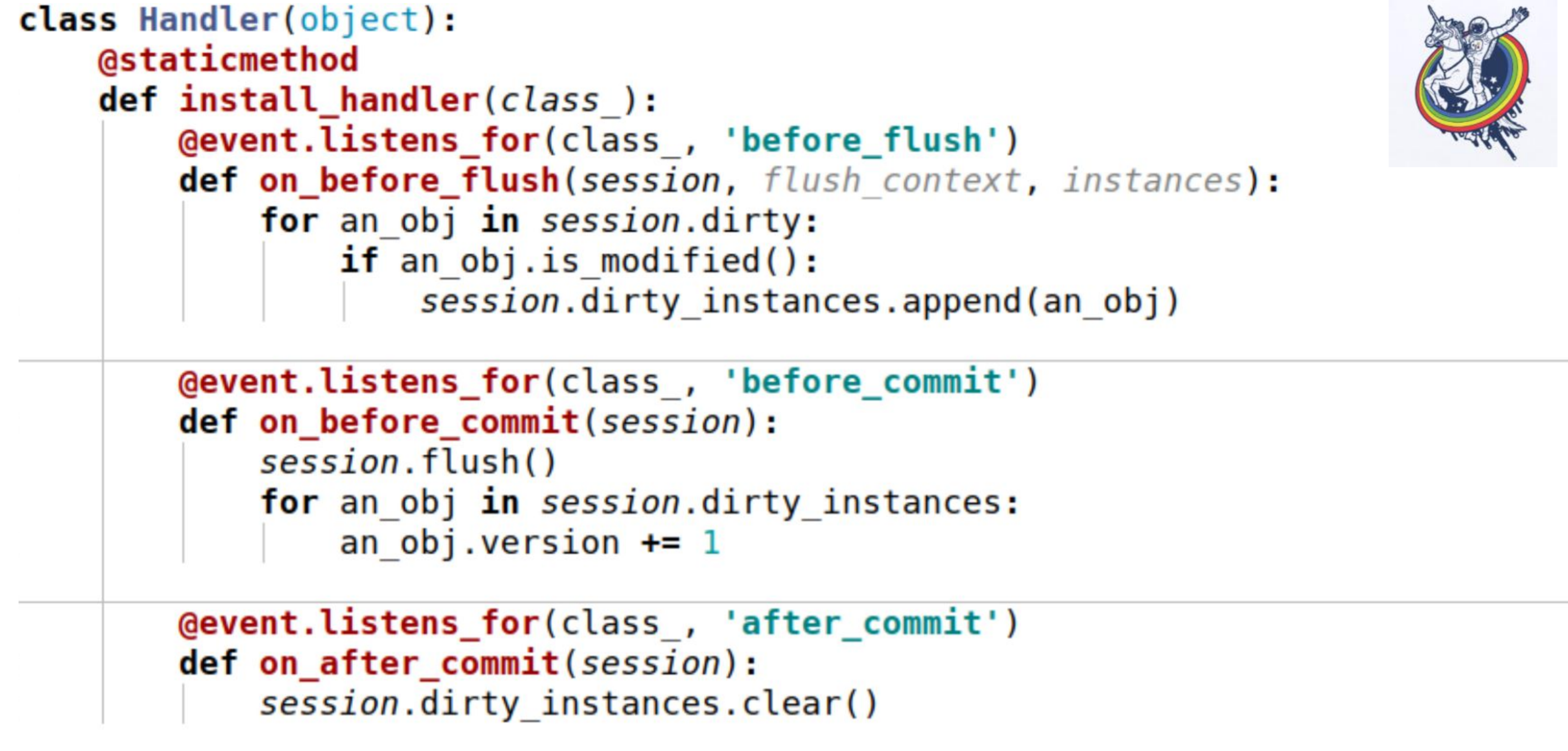 Hier ist ein Beispiel. Hier werden drei Ereignisse verwendet:on_before_flush - Bevor der SQL-Code an die Datenbank ausgegeben wird, gehen wir alle Objekte durch, die in dieser Sitzung als fehlerhaft markiert wurden, und prüfen, ob dieses Objekt geändert wurde oder nicht. Warum ist das notwendig, wenn die Alchemie bereits alles markiert hat? Alchemie markiert ein Objekt als verschmutzt, sobald sich ein Attribut geändert hat. Wenn wir diesem Attribut denselben Wert zuweisen, den es hatte, wird es als verschmutzt markiert. Hierfür gibt es eine is_modified-Sitzungsmethode - sie wird intern verwendet, ich habe sie nicht gezeichnet. Aus Sicht unserer Semantik und aus Sicht unserer Geschäftslogik kann das Objekt auch dann unverändert bleiben, wenn sich das Attribut geändert hat. Zum Beispiel gibt es eine bestimmte Liste, in der zwei Elemente ausgetauscht werden - aus Sicht der Alchemie hat sich das Attribut geändert, aber es spielt für die Geschäftslogik keine Rolle, wenn beispielsweiseeine Art.Und am Ende rufen wir eine andere objektspezifische Methode auf, um zu verstehen, ob das Objekt geändert wird oder nicht. Und wir fügen sie einer bestimmten Variablen hinzu, die mit der Sitzung verknüpft ist, die wir selbst aufgerufen haben - dies ist unsere Variable dirty_instances, in die wir dieses Objekt einfügen.Das folgende Ereignis tritt vor dem Commit auf - before_commit. Es gibt auch eine kleine Gefahr: Wenn wir für die gesamte Transaktion keinen einzigen Flush hatten, wird der Flush vor dem Commit aufgerufen. In meinem Fall wurde der Handler vor dem Commit vor dem Flush aufgerufen.Wie Sie sehen können, hilft uns das, was wir im vorherigen Absatz getan haben, möglicherweise nicht und session.dirty_instances ist leer. Daher machen wir im Handler erneut Flush, sodass alle Handler vor dem Flush aufgerufen werden, und erhöhen die Version einfach um eins.after_commit, after_soft_rollback - nach dem Commit bereinigen wir es einfach, damit es beim nächsten Mal keine Überschüsse gibt.Sie sehen also, diese install_handler-Methode installiert Handler für drei Ereignisse gleichzeitig. Als Klasse bestehen wir die Sitzung hier, da dies ein Ereignis seines Niveaus ist.
Hier ist ein Beispiel. Hier werden drei Ereignisse verwendet:on_before_flush - Bevor der SQL-Code an die Datenbank ausgegeben wird, gehen wir alle Objekte durch, die in dieser Sitzung als fehlerhaft markiert wurden, und prüfen, ob dieses Objekt geändert wurde oder nicht. Warum ist das notwendig, wenn die Alchemie bereits alles markiert hat? Alchemie markiert ein Objekt als verschmutzt, sobald sich ein Attribut geändert hat. Wenn wir diesem Attribut denselben Wert zuweisen, den es hatte, wird es als verschmutzt markiert. Hierfür gibt es eine is_modified-Sitzungsmethode - sie wird intern verwendet, ich habe sie nicht gezeichnet. Aus Sicht unserer Semantik und aus Sicht unserer Geschäftslogik kann das Objekt auch dann unverändert bleiben, wenn sich das Attribut geändert hat. Zum Beispiel gibt es eine bestimmte Liste, in der zwei Elemente ausgetauscht werden - aus Sicht der Alchemie hat sich das Attribut geändert, aber es spielt für die Geschäftslogik keine Rolle, wenn beispielsweiseeine Art.Und am Ende rufen wir eine andere objektspezifische Methode auf, um zu verstehen, ob das Objekt geändert wird oder nicht. Und wir fügen sie einer bestimmten Variablen hinzu, die mit der Sitzung verknüpft ist, die wir selbst aufgerufen haben - dies ist unsere Variable dirty_instances, in die wir dieses Objekt einfügen.Das folgende Ereignis tritt vor dem Commit auf - before_commit. Es gibt auch eine kleine Gefahr: Wenn wir für die gesamte Transaktion keinen einzigen Flush hatten, wird der Flush vor dem Commit aufgerufen. In meinem Fall wurde der Handler vor dem Commit vor dem Flush aufgerufen.Wie Sie sehen können, hilft uns das, was wir im vorherigen Absatz getan haben, möglicherweise nicht und session.dirty_instances ist leer. Daher machen wir im Handler erneut Flush, sodass alle Handler vor dem Flush aufgerufen werden, und erhöhen die Version einfach um eins.after_commit, after_soft_rollback - nach dem Commit bereinigen wir es einfach, damit es beim nächsten Mal keine Überschüsse gibt.Sie sehen also, diese install_handler-Methode installiert Handler für drei Ereignisse gleichzeitig. Als Klasse bestehen wir die Sitzung hier, da dies ein Ereignis seines Niveaus ist. Bitte schön. Ich werde Sie daran erinnern, was wir erreicht haben - Geschwindigkeit von 30-40 Sekunden für komplexe und große Teams. Überhaupt nicht, einige wurden in einer Sekunde abgeschlossen, andere in 200 Millisekunden, wie Sie auf RPS sehen können. Datenbankabfragen wurden zu Hunderten gezählt.
Bitte schön. Ich werde Sie daran erinnern, was wir erreicht haben - Geschwindigkeit von 30-40 Sekunden für komplexe und große Teams. Überhaupt nicht, einige wurden in einer Sekunde abgeschlossen, andere in 200 Millisekunden, wie Sie auf RPS sehen können. Datenbankabfragen wurden zu Hunderten gezählt. Das Ergebnis ist ein ziemlich ausgewogenes System. Es gab jedoch eine Einschränkung. Einige Anfragen kommen von uns in Chargen, Emissionen. Das heißt, ungefähr 30 Anfragen kommen an und jede von ihnen ist so! (Sprecher zeigt Daumen)Wenn wir sie jeweils eine Sekunde lang verarbeiten, funktioniert die letzte Anforderung in der Warteschlange 30 Sekunden lang. Der erste, die zweiten beiden und so weiter.
Das Ergebnis ist ein ziemlich ausgewogenes System. Es gab jedoch eine Einschränkung. Einige Anfragen kommen von uns in Chargen, Emissionen. Das heißt, ungefähr 30 Anfragen kommen an und jede von ihnen ist so! (Sprecher zeigt Daumen)Wenn wir sie jeweils eine Sekunde lang verarbeiten, funktioniert die letzte Anforderung in der Warteschlange 30 Sekunden lang. Der erste, die zweiten beiden und so weiter. Deshalb müssen wir noch beschleunigen. Was machen wir?Tatsächlich besteht die Alchemie aus zwei Teilen. Die erste ist eine Abstraktion über eine SQL-Datenbank namens SQLAlchemy Core. Das zweite ist ORM, die tatsächliche Zuordnung zwischen der relationalen Datenbank und der Objektdarstellung. Dementsprechend fällt der Alchemiekern ungefähr eins zu eins mit SQL zusammen - wenn Sie letzteres kennen, werden Sie keine Probleme mit dem Kern haben. Wenn Sie SQL nicht kennen - lernen Sie SQL.Darüber hinaus stellt der Kern den geringsten Overhead dar. Es gibt praktisch kein Pumpen - Abfragen werden mit dem Abfragegenerator generiert und dann ausgeführt. Der Overhead über Dbapi ist minimal.Wir können Anforderungen beliebiger Komplexität und Art erstellen und sie für die Aufgabe optimieren. Das heißt, wenn es ORM im allgemeinen Fall egal ist, wie das Datenbankschema erstellt wird - es gibt eine Beschreibung der Tabellen, werden einige Abfragen generiert, ohne zu wissen, dass es in diesem Fall beispielsweise optimal ist, von hier, in einem anderen - von dort aus auszuwählen Wenden Sie den Filter an, und dort - noch einen, dann können wir hier Anfragen für die Aufgabe stellen.Der Nachteil ist, dass wir wieder zur manuellen Synchronisation gekommen sind. Alle Ereignisse, Relais - all dies im Kern funktioniert nicht. Wir haben eine Auswahl getroffen, Objekte sind zu uns gekommen, wir haben etwas mit ihnen gemacht, dann aktualisiert, eingefügt ... Sie müssen die Version mit Ihren Händen erhöhen, die Konstanten selbst überprüfen. Core erlaubt es nicht, all dies bequem auf hohem Niveau zu erledigen.Nun, wir leben nicht am ersten Tag.
Deshalb müssen wir noch beschleunigen. Was machen wir?Tatsächlich besteht die Alchemie aus zwei Teilen. Die erste ist eine Abstraktion über eine SQL-Datenbank namens SQLAlchemy Core. Das zweite ist ORM, die tatsächliche Zuordnung zwischen der relationalen Datenbank und der Objektdarstellung. Dementsprechend fällt der Alchemiekern ungefähr eins zu eins mit SQL zusammen - wenn Sie letzteres kennen, werden Sie keine Probleme mit dem Kern haben. Wenn Sie SQL nicht kennen - lernen Sie SQL.Darüber hinaus stellt der Kern den geringsten Overhead dar. Es gibt praktisch kein Pumpen - Abfragen werden mit dem Abfragegenerator generiert und dann ausgeführt. Der Overhead über Dbapi ist minimal.Wir können Anforderungen beliebiger Komplexität und Art erstellen und sie für die Aufgabe optimieren. Das heißt, wenn es ORM im allgemeinen Fall egal ist, wie das Datenbankschema erstellt wird - es gibt eine Beschreibung der Tabellen, werden einige Abfragen generiert, ohne zu wissen, dass es in diesem Fall beispielsweise optimal ist, von hier, in einem anderen - von dort aus auszuwählen Wenden Sie den Filter an, und dort - noch einen, dann können wir hier Anfragen für die Aufgabe stellen.Der Nachteil ist, dass wir wieder zur manuellen Synchronisation gekommen sind. Alle Ereignisse, Relais - all dies im Kern funktioniert nicht. Wir haben eine Auswahl getroffen, Objekte sind zu uns gekommen, wir haben etwas mit ihnen gemacht, dann aktualisiert, eingefügt ... Sie müssen die Version mit Ihren Händen erhöhen, die Konstanten selbst überprüfen. Core erlaubt es nicht, all dies bequem auf hohem Niveau zu erledigen.Nun, wir leben nicht am ersten Tag. Ein einfacher Anwendungsfall. Jeder Mapper enthält intern ein __table__ -Objekt, das im Core verwendet wird. Als nächstes sehen Sie - wir nehmen die übliche Auswahl, listen die Spalten auf, verbinden zwei Platten, geben links und rechts an, geben an, unter welchen Bedingungen wir sie verbinden. Außerdem geben wir diese generierte Anforderung in die Sitzung ein und sie gibt sie iterabel an uns zurück, wobei die tippartigen Objekte sowohl nach dem Namen der Spalte als auch nach der Nummer indiziert werden. Die Nummer entspricht der Reihenfolge, in der sie in der Auswahl aufgeführt sind.
Ein einfacher Anwendungsfall. Jeder Mapper enthält intern ein __table__ -Objekt, das im Core verwendet wird. Als nächstes sehen Sie - wir nehmen die übliche Auswahl, listen die Spalten auf, verbinden zwei Platten, geben links und rechts an, geben an, unter welchen Bedingungen wir sie verbinden. Außerdem geben wir diese generierte Anforderung in die Sitzung ein und sie gibt sie iterabel an uns zurück, wobei die tippartigen Objekte sowohl nach dem Namen der Spalte als auch nach der Nummer indiziert werden. Die Nummer entspricht der Reihenfolge, in der sie in der Auswahl aufgeführt sind. Es ist viel besser geworden. Die Leistung fiel im schlimmsten Fall auf 2-4 Sekunden, die komplexeste und längste Anforderung enthielt 14 Befehle und RPS 10-15. Es ist fest.
Es ist viel besser geworden. Die Leistung fiel im schlimmsten Fall auf 2-4 Sekunden, die komplexeste und längste Anforderung enthielt 14 Befehle und RPS 10-15. Es ist fest. Was ich abschließend sagen möchte.Produzieren Sie keine Entitäten, wo sie nicht benötigt werden - schrauben Sie Ihre nicht dort, wo sie fertig sind.Verwenden Sie SQLA ORM - dies ist ein sehr praktisches Tool, mit dem Sie Ereignisse auf hoher Ebene verfolgen, auf verschiedene Ereignisse im Zusammenhang mit der Datenbank reagieren und alle Ohren der Alchemie verbergen können.Wenn alles andere fehlschlägt, reicht die Leistung nicht aus - verwenden Sie SQLA Core. Dies ist immer noch besser als die Verwendung von reinem SQL, da es eine relationale Abstraktion über die Datenbank bietet. Entgeht automatisch Parametern, führt Ordner korrekt aus, es spielt keine Rolle, welche Datenbank sich darunter befindet - sie kann geändert werden und Core unterstützt verschiedene Dialekte.
Was ich abschließend sagen möchte.Produzieren Sie keine Entitäten, wo sie nicht benötigt werden - schrauben Sie Ihre nicht dort, wo sie fertig sind.Verwenden Sie SQLA ORM - dies ist ein sehr praktisches Tool, mit dem Sie Ereignisse auf hoher Ebene verfolgen, auf verschiedene Ereignisse im Zusammenhang mit der Datenbank reagieren und alle Ohren der Alchemie verbergen können.Wenn alles andere fehlschlägt, reicht die Leistung nicht aus - verwenden Sie SQLA Core. Dies ist immer noch besser als die Verwendung von reinem SQL, da es eine relationale Abstraktion über die Datenbank bietet. Entgeht automatisch Parametern, führt Ordner korrekt aus, es spielt keine Rolle, welche Datenbank sich darunter befindet - sie kann geändert werden und Core unterstützt verschiedene Dialekte. Es ist sehr bequem.
Das ist alles, was ich dir heute sagen wollte.