Verteilte Systeme werden verwendet, wenn eine horizontale Skalierung erforderlich ist, um Leistungsindikatoren bereitzustellen, die darauf hinweisen, dass ein vertikal skaliertes System nicht in der Lage ist, angemessenes Geld bereitzustellen.
Wie der Übergang von einem Single-Thread-Paradigma zu einem Multi-Thread-Paradigma erfordert die Migration zu einem verteilten System eine Art Eintauchen und Verständnis dafür, wie es im Inneren funktioniert und worauf Sie achten müssen.
Eines der Probleme, mit denen eine Person konfrontiert ist, die ein Projekt auf ein verteiltes System migrieren oder ein Projekt darauf starten möchte, ist das zu wählende Produkt.
Als Unternehmen, das bei der Entwicklung solcher Systeme „einen Hund gefressen“ hat, helfen wir unseren Kunden, fundierte Entscheidungen in Bezug auf verteilte Speichersysteme zu treffen. Wir veröffentlichen auch eine
Reihe von Webinaren für ein breiteres Publikum, die sich auf Grundprinzipien in einer einfachen Sprache konzentrieren. Unabhängig von den spezifischen Essenspräferenzen können wichtige Funktionen festgelegt werden, um die Auswahl zu vereinfachen.
Dieser Artikel basiert auf unseren Materialien zur Konsistenz und zu ACID-Garantien in verteilten Systemen.
Was ist das und warum wird es benötigt?
"
Datenkonsistenz (manchmal
Datenkonsistenz ) ist
Datenkonsistenz untereinander, Datenintegrität und interne Konsistenz." (
Wikipedia )
Konsistenz bedeutet, dass Anwendungen jederzeit sicher sein können, dass sie mit der richtigen, technisch relevanten Version der Daten arbeiten, und sich bei Entscheidungen darauf verlassen können.
In verteilten Systemen wird die Gewährleistung der Konsistenz immer schwieriger und teurer, da eine ganze Reihe neuer Herausforderungen im Zusammenhang mit dem Netzwerkaustausch zwischen verschiedenen Knoten, der Möglichkeit des Ausfalls einzelner Knoten und - häufig - dem Fehlen eines einzelnen Speichers, der zur Überprüfung dienen kann, auftreten.
Wenn ich beispielsweise ein System mit 4 Knoten habe: A, B, C und D, das Bankgeschäfte abwickelt, und die Knoten C und D von A und B getrennt sind (z. B. aufgrund von Netzwerkproblemen), ist dies jetzt möglicherweise nicht der Fall Ich habe Zugriff auf einen Teil der Transaktion. Wie verhalte ich mich in dieser Situation? Unterschiedliche Systeme verfolgen unterschiedliche Ansätze.
Auf der obersten Ebene gibt es zwei Schlüsselrichtungen, die im CAP-Theorem ausgedrückt werden.
„
Das CAP-Theorem (auch als
Brewer-Theorem bekannt ) ist eine heuristische Aussage, dass es bei jeder Implementierung von verteiltem Computing möglich ist, nicht mehr als zwei der folgenden drei Eigenschaften bereitzustellen:
- Datenkonsistenz (Eng. Konsistenz) - In allen Rechenknoten zu einem bestimmten Zeitpunkt widersprechen sich die Daten nicht.
- Verfügbarkeit (engl. Verfügbarkeit) - Jede Anfrage an ein verteiltes System endet mit einer korrekten Antwort, jedoch ohne Garantie, dass die Antworten aller Knoten des Systems übereinstimmen.
- Partitionstoleranz - Die Aufteilung eines verteilten Systems in mehrere isolierte Abschnitte führt nicht zu einer falschen Antwort von jedem Abschnitt. “
(
Wikipedia )
Wenn der CAP-Satz von Konsistenz spricht, impliziert er eine ziemlich strenge Definition, einschließlich der Linearisierung von Aufzeichnungen und Messwerten, und legt nur Konsistenz beim Schreiben einzelner Werte fest. (
Martin Kleppman )
Das CAP-Theorem besagt, dass wir, wenn wir gegen Netzwerkprobleme resistent sein wollen, im Allgemeinen entscheiden müssen, ob wir Opfer bringen wollen: Konsistenz oder Zugänglichkeit. Es gibt auch eine erweiterte Version dieses Theorems - PACELC (
Wikipedia ), die zusätzlich darüber spricht, dass wir auch ohne Netzwerkprobleme zwischen Antwortgeschwindigkeit und Konsistenz wählen müssen.
Und obwohl auf den ersten Blick ein Eingeborener aus der Welt der klassischen DBMS zu sein scheint, dass die Wahl offensichtlich ist und Konsistenz das Wichtigste ist, was wir haben, ist dies bei weitem nicht immer der Fall, was das explosive Wachstum einer Reihe von NoSQL-DBMS deutlich macht, die eine andere Wahl getroffen haben und Trotzdem haben sie eine riesige Nutzerbasis. Apache Cassandra mit seiner berühmten Konsistenz ist ein gutes Beispiel.
Dies alles ist auf die Tatsache zurückzuführen, dass dies eine
Entscheidung ist , die impliziert, dass wir etwas opfern und nicht immer bereit sind, es zu opfern.
Oft wird das Problem der Konsistenz in verteilten Systemen einfach dadurch gelöst, dass diese Konsistenz aufgegeben wird.
Es ist jedoch notwendig und wichtig zu verstehen, wann die Ablehnung dieser Konsistenz akzeptabel ist und wann sie eine kritische Geschäftsanforderung darstellt.
Wenn ich beispielsweise eine Komponente entwerfe, die für das Speichern von Benutzersitzungen verantwortlich ist, ist mir die Konsistenz hier höchstwahrscheinlich nicht so wichtig, und Datenverlust ist nicht kritisch, wenn er nur in problematischen Fällen auftritt - sehr selten. Das Schlimmste, was passieren wird, ist, dass sich der Benutzer anmelden muss, und für viele Unternehmen hat dies nur geringe Auswirkungen auf ihre finanzielle Leistung.
Wenn ich den Datenstrom von Sensoren analysiere, ist es in vielen Fällen völlig unkritisch, einen Teil der Daten zu verlieren und für kurze Zeit ein Downsampling durchzuführen, insbesondere wenn ich die Daten endlich sehe.
Wenn ich jedoch ein Bankensystem aufbaue, ist die Konsistenz der Bargeldtransaktionen für mein Unternehmen von entscheidender Bedeutung. Wenn ich eine Strafe für das Darlehen eines Kunden erhalten habe, weil ich die Zahlung einfach nicht rechtzeitig gesehen habe, obwohl er im System war, ist dies sehr, sehr schlecht. Außerdem kann der Kunde das gesamte Geld mehrmals von meiner Kreditkarte abheben, da ich zum Zeitpunkt der Transaktion Netzwerkprobleme hatte und die Abhebungsinformationen keinen Teil meines Clusters erreichten.
Wenn Sie einen teuren Einkauf in einem Online-Shop tätigen, möchten Sie nicht, dass Ihre Bestellung trotz des Erfolgsberichts auf der Webseite vergessen wird.
Wenn Sie sich jedoch für Konsistenz entscheiden, opfern Sie die Zugänglichkeit. Und oft wird dies erwartet, höchstwahrscheinlich sind Sie mehr als einmal persönlich darauf gestoßen.
Es ist besser, wenn im Warenkorb des Online-Shops die Meldung "Später versuchen, ein verteiltes DBMS ist nicht verfügbar" angezeigt wird, als wenn der Erfolg gemeldet und die Bestellung vergessen wird. Es ist besser, eine Ablehnung einer Transaktion aufgrund der Nichtverfügbarkeit der Dienstleistungen der Bank zu erhalten, als den Erfolg und dann das Verfahren mit der Bank zu beeinträchtigen, da er vergessen hat, dass Sie den Kredit bezahlt haben.
Wenn wir uns schließlich das erweiterte PACELC-Theorem ansehen, dann verstehen wir, dass wir selbst bei normalem Betrieb des Systems bei Auswahl der Konsistenz niedrige Latenzen opfern und möglicherweise eine geringere maximale Leistung erzielen können.
Beantworten Sie daher die Frage „Warum ist dies erforderlich?“: Wenn es für Ihre Aufgabe wichtig ist, über aktuelle, konsistente Daten zu verfügen, führt die Alternative zu erheblichen Verlusten, die größer sind als die vorübergehende Nichtverfügbarkeit des Dienstes für den Zeitraum des Vorfalls oder dessen geringere Leistung.
Wie kann man das bereitstellen?
Dementsprechend ist die erste Entscheidung, die Sie treffen müssen, wo Sie sich im CAP-Theorem befinden. Sie möchten im Falle eines Vorfalls Konsistenz oder Verfügbarkeit.
Als nächstes müssen Sie verstehen, auf welcher Ebene Sie Änderungen vornehmen möchten. Vielleicht haben Sie gerade genug atomare Datensätze, die sich auf ein einzelnes Objekt auswirken, da MongoDB in der Lage und in der Lage war (jetzt erweitert es dies um zusätzliche Unterstützung für vollwertige Transaktionen). Ich möchte Sie daran erinnern, dass der CAP-Satz nichts über die Konsistenz von Schreibvorgängen mit mehreren Objekten aussagt: Das System kann durchaus CP sein (d. H. Zugänglichkeitskonsistenz bevorzugen) und gleichzeitig nur atomare Einzeldatensätze bereitstellen.
Wenn Ihnen dies nicht ausreicht, nähern wir uns dem Konzept vollwertiger verteilter ACID-Transaktionen.
Ich stelle fest, dass wir selbst in der schönen neuen Welt der verteilten ACID-Transaktionen oft etwas opfern müssen. Beispielsweise haben einige verteilte Speichersysteme verteilte Transaktionen, jedoch nur innerhalb einer einzelnen Partition. Beispielsweise unterstützt das System den I-Teil möglicherweise nicht auf der von Ihnen benötigten Ebene, ohne Isolation oder mit einer unzureichenden Anzahl von Isolationsstufen.
Diese Einschränkungen wurden häufig aus irgendeinem Grund vorgenommen: entweder um die Implementierung zu vereinfachen oder um beispielsweise die Leistung zu verbessern oder um etwas anderes zu tun. Sie sind für eine große Anzahl von Fällen ausreichend, daher sollten Sie sie nicht als Nachteile für sich betrachten.
Sie müssen verstehen, ob diese Einschränkungen für Ihr spezifisches Szenario ein Problem darstellen. Wenn nicht, haben Sie mehr Auswahlmöglichkeiten und können beispielsweise Leistungsindikatoren oder der Fähigkeit des Systems, Katastrophenverträglichkeit usw. bereitzustellen, mehr Gewicht beimessen. Schließlich dürfen wir nicht vergessen, dass in einer Reihe von Systemen diese Parameter so angepasst werden können, dass das System je nach Konfiguration CP oder AP sein kann.
Wenn unser Produkt CP sein soll, hat es normalerweise entweder einen Quorum-Ansatz für die Datenauswahl oder dedizierte Knoten, die die Haupteigentümer der Datensätze sind. Alle Datenänderungen werden durch sie geleitet, und bei Netzwerkproblemen, wenn diese Hauptknoten nicht geben können Als Antwort wird angenommen, dass die Daten im Prinzip nicht abgerufen oder nicht vermittelt werden können, wenn eine externe, leicht zugängliche Komponente (z. B. der ZooKeeper-Cluster) sagen kann, welches der Clustersegmente das Hauptsegment ist, die aktuelle Version der Daten enthält und die Anforderung effektiv bedienen kann s.
Wenn wir nicht nur an CP interessiert sind, sondern an der Unterstützung vollwertiger verteilter ACID-Transaktionen, wird häufig eine einzige Wahrheitsquelle verwendet, beispielsweise ein zentraler Festplattenspeicher, bei dem unsere Knoten tatsächlich nur als Caches dienen, die deaktiviert werden können Festschreibungszeit oder das mehrphasige Festschreibungsprotokoll wird angewendet.
Der erste Single-Disk-Ansatz vereinfacht auch die Implementierung, bietet geringe Latenzen bei verteilten Transaktionen, wird jedoch gegen eine sehr eingeschränkte Skalierbarkeit bei Lasten mit großem Aufzeichnungsvolumen eingetauscht.
Der zweite Ansatz bietet viel mehr Freiheit bei der Skalierung und ist wiederum in zwei- (
Wikipedia ) und dreiphasige (
Wikipedia ) Festschreibungsprotokolle unterteilt.
Stellen Sie sich ein zweiphasiges Commit vor, das beispielsweise Apache Ignite verwendet.
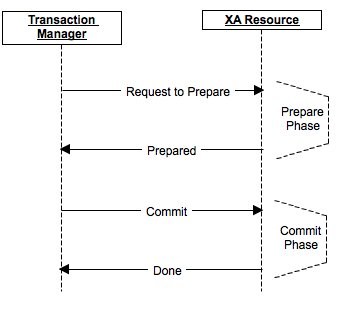

Das Festschreibungsverfahren ist in zwei Phasen unterteilt: Vorbereiten und Festschreiben.
In der Vorbereitungsphase wird eine Nachricht über die Vorbereitung des Commits vorbereitet, und jeder Teilnehmer führt bei Bedarf eine Sperre durch, führt alle Vorgänge bis einschließlich des tatsächlichen Commits aus und sendet die Vorbereitung an seine Replikate, sofern dies vom Produkt angenommen wird. Wenn mindestens einer der Teilnehmer aus irgendeinem Grund mit einer Ablehnung antwortete oder sich als nicht verfügbar herausstellte - die Daten änderten sich nicht tatsächlich, gab es kein Commit. Die Teilnehmer setzen Änderungen zurück, lösen Sperren und kehren in ihren ursprünglichen Zustand zurück.
In der Festschreibungsphase wird die tatsächliche Ausführung der Festschreibung an die Clusterknoten gesendet. Wenn aus irgendeinem Grund einige der Knoten nicht verfügbar waren oder mit einem Fehler geantwortet haben, wurden die Daten zu diesem Zeitpunkt in ihr Redo-Log eingegeben (da die Vorbereitung erfolgreich war), und das Festschreiben kann in jedem Fall zumindest in einem ausstehenden Zustand abgeschlossen werden.
Wenn der Koordinator ausfällt, wird das Festschreiben in der Vorbereitungsphase abgebrochen. In der Festschreibungsphase kann ein neuer Koordinator ausgewählt werden. Wenn alle Knoten die Vorbereitung abgeschlossen haben, kann er überprüfen und sicherstellen, dass die Festschreibungsphase abgeschlossen ist.
Verschiedene Produkte haben ihre eigenen Implementierungs- und Optimierungsfunktionen. So können beispielsweise einige Produkte in einigen Fällen ein 2-Phasen-Commit auf ein 1-Phasen-Commit reduzieren und so erheblich an Leistung gewinnen.
Schlussfolgerungen
Wichtigste Schlussfolgerung: Verteilte Speichersysteme sind ein ziemlich entwickelter Markt, und Produkte darauf können eine hohe Datenkonsistenz bieten.
Darüber hinaus befinden sich Produkte dieser Kategorie an verschiedenen Punkten der Konsistenzskala, von vollständig AP-Produkten ohne Transaktionsfähigkeit bis zu CP-Produkten, die zusätzlich vollwertige ACID-Transaktionen bereitstellen. Einige Produkte können auf die eine oder andere Weise konfiguriert werden.
Wenn Sie wählen, was Sie brauchen, müssen Sie die Bedürfnisse Ihres Falles berücksichtigen und gut verstehen, welche Opfer und Kompromisse Sie bereit sind, weil nichts umsonst passiert, und wenn Sie einen auswählen, werden Sie höchstwahrscheinlich etwas anderes ablehnen.
Bei der Bewertung von Produkten von dieser Seite ist Folgendes zu beachten:
- wo sie im CAP-Theorem stehen;
- Unterstützen sie verteilte ACID-Transaktionen?
- Welche Einschränkungen erlegen sie verteilten Transaktionen auf (z. B. nur innerhalb einer einzelnen Partition usw.)?
- Bequemlichkeit und Effizienz bei der Verwendung verteilter Transaktionen sowie deren Integration in andere Produktkomponenten.