[Teil 2 von 2]
[Teil 1 von 2]

Wie haben wir das gemacht?
Wir haben uns entschlossen, auf GCP umzusteigen , um die Anwendungsleistung zu verbessern - und gleichzeitig den Umfang zu erhöhen, jedoch ohne erhebliche Kosten. Der gesamte Prozess dauerte mehr als 2 Monate. Um dieses Problem zu lösen, haben wir eine spezielle Gruppe von Ingenieuren gebildet.
In dieser Veröffentlichung werden wir über den gewählten Ansatz und seine Implementierung sowie darüber sprechen, wie wir das Hauptziel erreicht haben - diesen Prozess so reibungslos wie möglich durchzuführen und die gesamte Infrastruktur auf die Google Cloud Platform zu übertragen, ohne die Qualität des Nutzerdienstes zu beeinträchtigen.
Planung
- Es wurde eine detaillierte Checkliste erstellt, in der jeder mögliche Schritt aufgeführt ist. Zur Beschreibung der Sequenz wurde ein Flussdiagramm erstellt.
- Es wurde ein Rücksetzplan entwickelt, den wir, wenn überhaupt, verwenden könnten.
Einige Brainstorming-Sitzungen - und wir haben den verständlichsten und einfachsten Ansatz für die Implementierung des Aktiv-Aktiv-Schemas ermittelt. Es besteht in der Tatsache, dass eine kleine Gruppe von Benutzern in einer Cloud und der Rest in einer anderen gehostet wird. Dieser Ansatz verursachte jedoch Probleme, insbesondere auf der Clientseite (im Zusammenhang mit der DNS-Verwaltung), und führte zu Verzögerungen bei der Datenbankreplikation. Aus diesem Grund war es fast unmöglich, es sicher umzusetzen. Die offensichtliche Methode lieferte nicht die notwendige Lösung, und wir mussten eine spezielle Strategie entwickeln.
Basierend auf dem Abhängigkeitsdiagramm und den Anforderungen an die Betriebssicherheit haben wir die Infrastrukturdienste in 9 Module unterteilt.
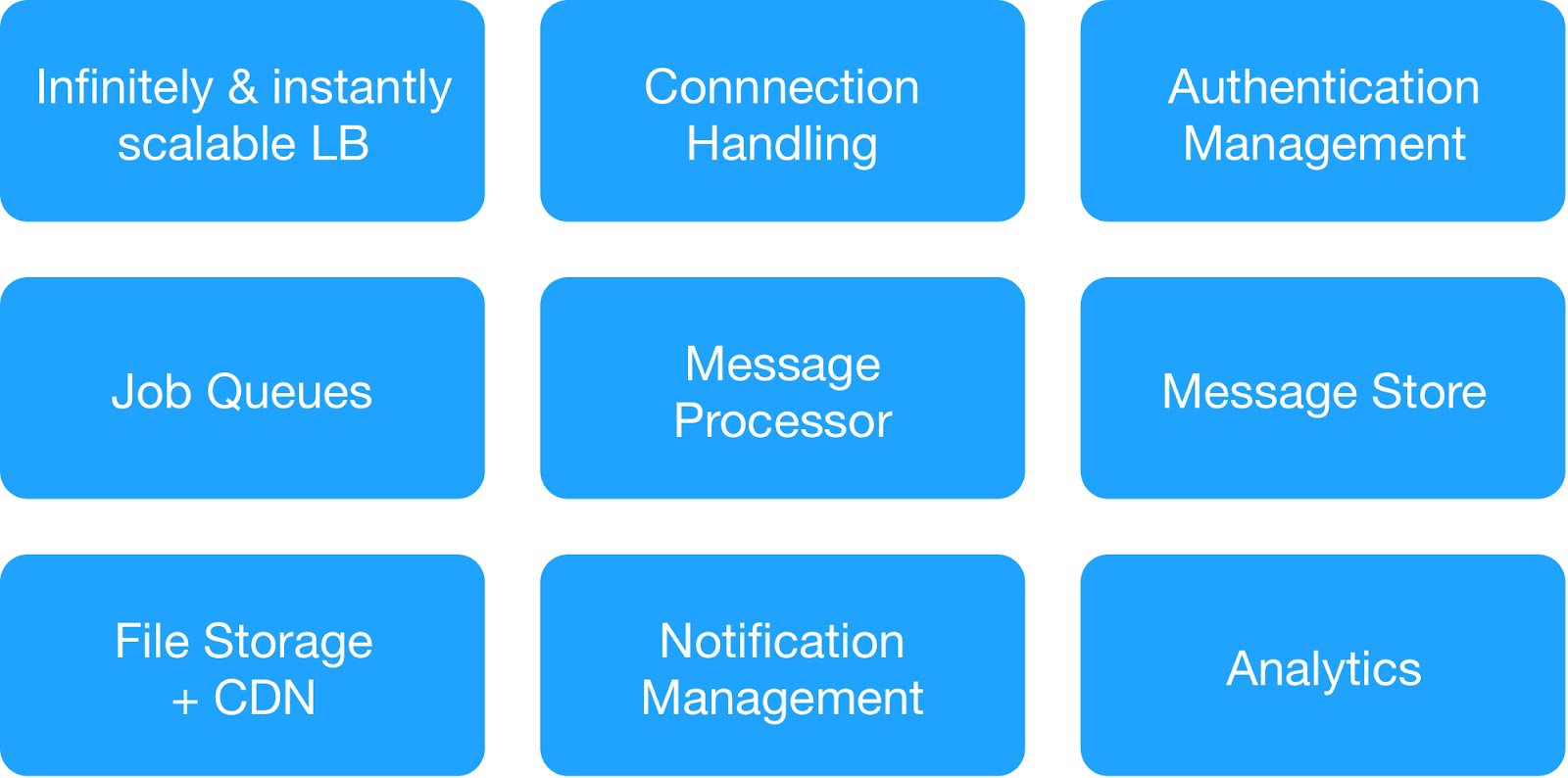
(Grundmodule für die Bereitstellung der Hosting-Infrastruktur)
Jede Infrastrukturgruppe verwaltete gemeinsame interne und externe Dienste.
⊹ Infrastruktur-Messaging-Dienst : MQTT, HTTPs, Thrift, Gunicorn-Server, Warteschlangenmodul, Async-Client, Jetty-Server, Kafka-Cluster.
⊹ Data Warehouse-Dienste : Verteilte Cluster-MongoDB, Redis, Cassandra, Hbase, MySQL und MongoDB.
⊹ Infrastrukturanalysedienst : Kafka-Cluster, Data Warehouse-Cluster (HDFS, HIVE).
Vorbereitung auf einen wichtigen Tag:
✓ Ein detaillierter Plan für den Wechsel zu GCP für jeden Dienst: Sequenz, Data Warehouse, Plan für das Zurücksetzen.
✓ Projektübergreifende Netzwerkinteraktionen (Shared Virtual Private Cloud VPC [XPN]) in GCP, um verschiedene Teile der Infrastruktur zu isolieren, das Management zu optimieren, die Sicherheit und Konnektivität zu verbessern.
✓ Mehrere VPN-Tunnel zwischen dem GCP und der laufenden Virtual Private Cloud (VPC), um die Übertragung großer Datenmengen über das Netzwerk während der Replikation sowie die mögliche spätere Bereitstellung eines parallelen Systems zu vereinfachen.
✓ Automatisieren Sie die Installation und Konfiguration des gesamten Stacks mithilfe des Chef-Systems.
✓ Skripte und Automatisierungstools für Bereitstellung, Überwachung, Protokollierung usw.
✓ Konfigurieren Sie alle erforderlichen Subnetze und verwalteten Firewall-Regeln für den Systemstrom.
✓ Replikation in mehreren Rechenzentren (Multi-DC) für alle Speichersysteme.
✓ Konfigurieren Sie Load Balancer (GLB / ILB) und verwaltete Instanzgruppen (MIG).
✓ Skripte und Code zum Übertragen des Objektspeichercontainers in den GCP Cloud Storage mit Prüfpunkten.
Bald erfüllten wir alle notwendigen Voraussetzungen und erstellten eine Checkliste mit Elementen für die Verlagerung der Infrastruktur auf die GCP-Plattform. Nach zahlreichen Diskussionen und unter Berücksichtigung der Anzahl der Dienste und ihrer Abhängigkeitsdiagramme haben wir beschlossen, die Cloud-Infrastruktur in drei Nächten auf GCP zu übertragen, um alle serverseitigen und Datenspeicherungsdienste abzudecken.
Übergang
Load Balancer Transfer Strategie:
Wir haben den zuvor verwendeten HAProxy-verwalteten Cluster durch einen globalen Load Balancer ersetzt, um täglich mehrere zehn Millionen aktive Benutzerverbindungen zu verarbeiten.
⊹ Stufe 1:
- MIGs werden mit Paketweiterleitungsregeln erstellt, um den gesamten Datenverkehr an MQTT-IP-Adressen in der vorhandenen Cloud weiterzuleiten.
- Ein SSL- und TCP-Proxy-Balancer wurde mit MIG als Serverteil erstellt.
- Für MIG wird HAProxy mit MQTT-Servern als Serverteil gestartet.
- In DNS hat eine gewichtsbasierte Routing-Richtlinie eine externe GLB-IP-Adresse hinzugefügt.
Benutzerverbindungen werden schrittweise bereitgestellt, während ihre Leistung verfolgt wird.
⊹ Schritt 2: Meilensteinübergang: Starten Sie die Bereitstellung von Diensten in GCP.
⊹ Phase 3: In der letzten Phase des Übergangs werden alle Dienste an das GCP übertragen.
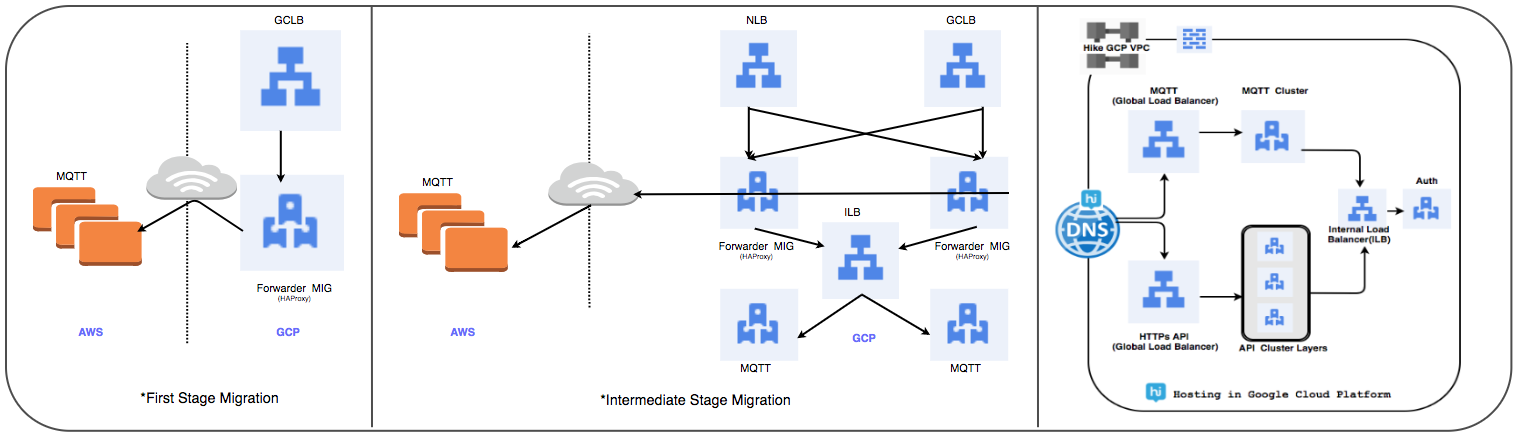
(Übertragungsstufen des Load Balancers)
Zu diesem Zeitpunkt funktionierte alles wie erwartet. Bald war es an der Zeit, mehrere interne HTTP-Dienste in GCP mit Routing bereitzustellen - angesichts des Gewichts der Koeffizienten. Wir haben alle Indikatoren genau überwacht. Als wir am Tag vor dem geplanten Übergang begannen, den Datenverkehr schrittweise zu erhöhen, nahmen die Verzögerungen bei der VPC-Interaktion über VPN (Verzögerungen von 40 ms - 100 ms wurden aufgezeichnet, obwohl sie früher weniger als 10 ms betrugen) zu.
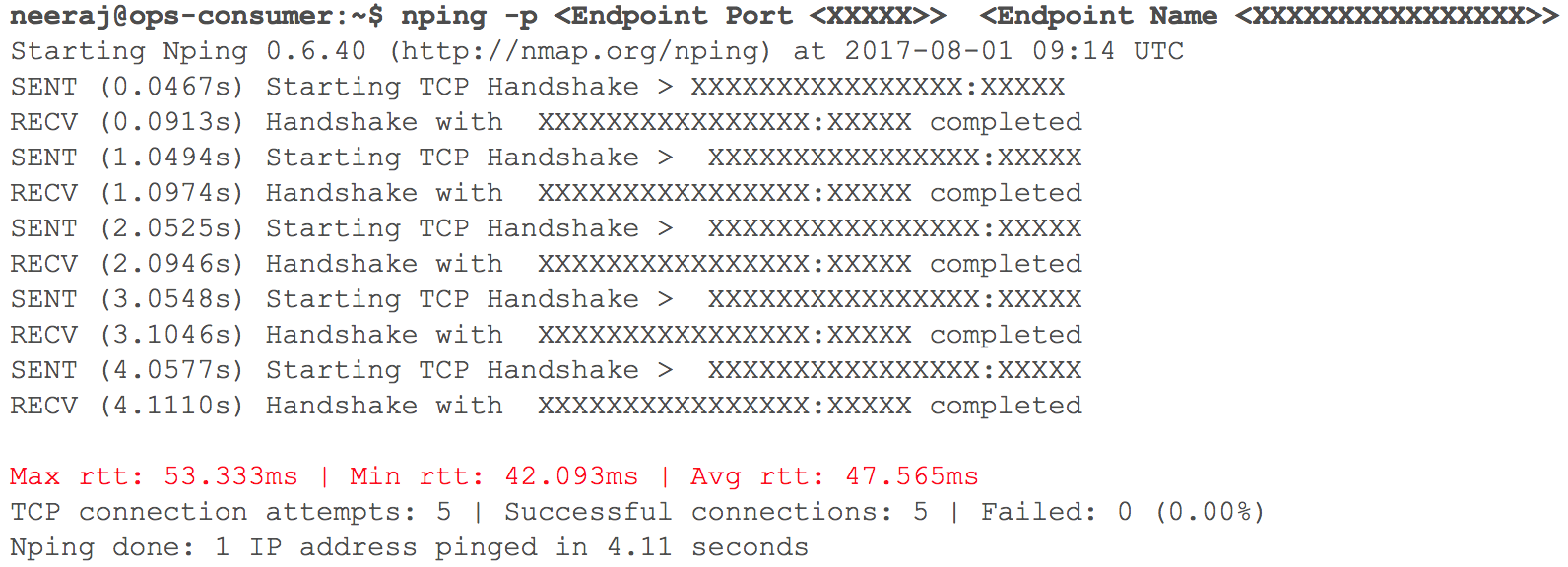
(Momentaufnahme der Überprüfung der Netzwerkverzögerung, wenn zwei VPCs interagieren)
Die Überwachung zeigte deutlich: Bei beiden Cloud-Netzwerkkanälen mit VPN-Tunneln stimmte etwas nicht. Selbst der Durchsatz des VPN-Tunnels erreichte nicht die optimale Marke. Diese Situation hat begonnen, einige unserer Benutzerdienste negativ zu beeinflussen. Wir haben alle zuvor migrierten HTTP-Dienste sofort in ihren ursprünglichen Zustand zurückversetzt. Wir kontaktierten die Supportteams von TAM und Cloud Services, stellten die erforderlichen Anfangsdaten bereit und begannen zu verstehen, warum die Verzögerungen zunahmen. Support-Spezialisten kamen zu dem Schluss, dass die maximale Netzwerkbandbreite im Cloud-Kanal zwischen zwei Cloud-Service-Providern erreicht wurde. Daher die Zunahme von Netzwerkverzögerungen während der Übertragung interner Systeme.
Dieser Vorfall zwang dazu, den Übergang zur Cloud auszusetzen. Cloud-Dienstanbieter konnten die Bandbreite nicht schnell genug verdoppeln. Daher sind wir zur Planungsphase zurückgekehrt und haben die Strategie überarbeitet. Wir haben uns entschlossen, die Cloud-Infrastruktur in einer statt in drei Nächten auf GCP zu übertragen, und alle Dienste des Serverteils und des Datenspeichers in den Plan aufgenommen. Als die Stunde „X“ eintraf, verlief alles reibungslos: Die Workloads wurden von unseren Nutzern unbemerkt erfolgreich in die Google Cloud übertragen!
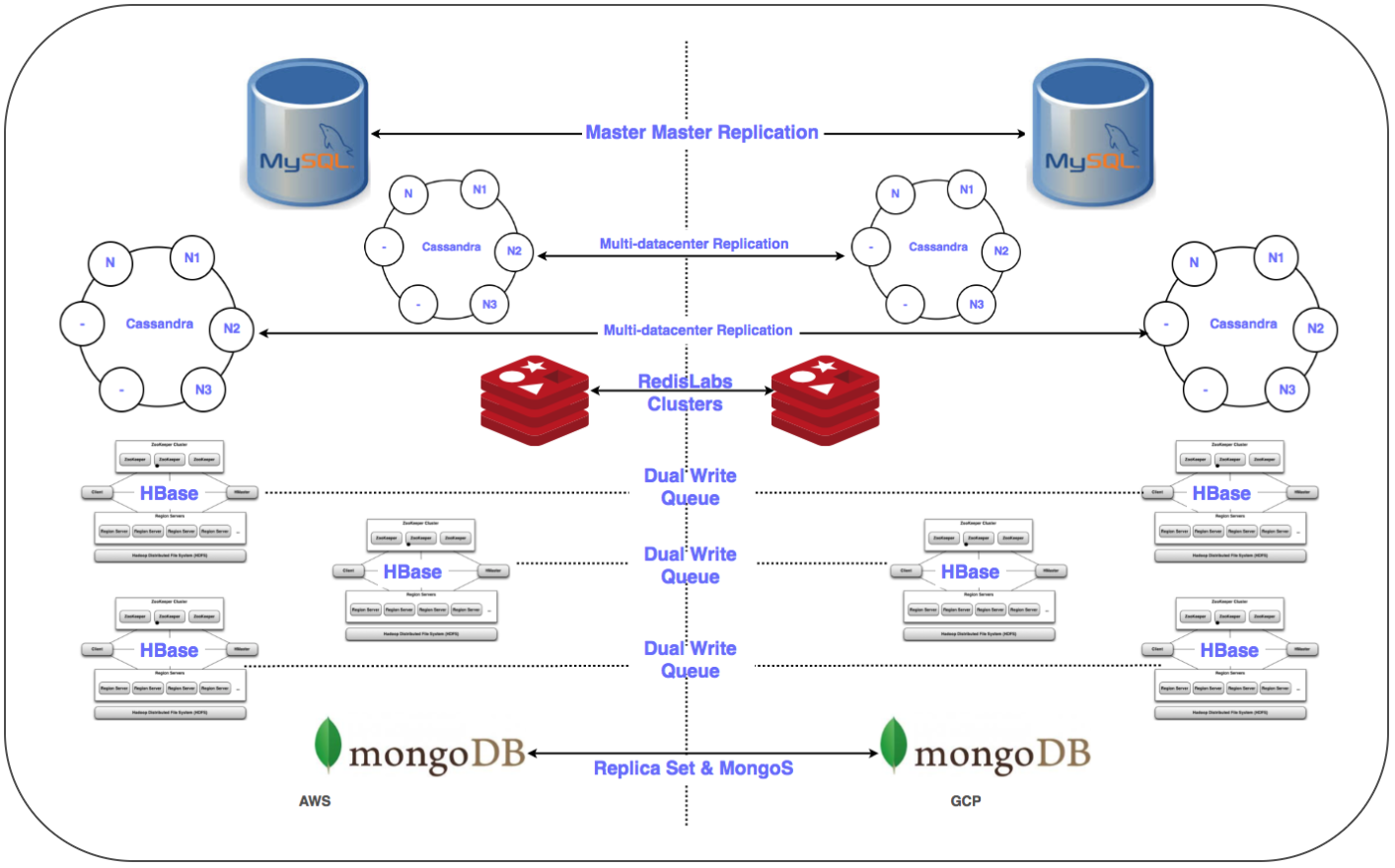
Datenbankmigrationsstrategie:
Es war erforderlich, mehr als 50 Datenbankendpunkte für ein relationales DBMS, In-Memory-Speicher sowie NoSQL und verteilte und skalierbare Cluster mit geringer Latenz zu übertragen. Wir haben Replikate aller Datenbanken in GCP platziert. Dies wurde für alle Bereitstellungen außer HBase durchgeführt.
⊹ Master-Slave-Replikation: Implementiert für MySQL-, Redis-, MongoDB- und MongoS-Cluster.
Multi Multi-DC-Replikation: Implementiert für Cassandra-Cluster.
⊹ Duale Cluster: Für Gbase in GCP wurde ein paralleler Cluster konfiguriert. Bestehende Daten wurden migriert, die doppelte Eingabe wurde gemäß der Strategie zur Aufrechterhaltung der Datenkonsistenz in beiden Clustern konfiguriert.
Im Fall von HBase bestand das Problem darin, Ambari einzurichten. Beim Platzieren von Clustern in mehreren Rechenzentren sind einige Schwierigkeiten aufgetreten. Beispielsweise gab es Probleme mit DNS, einem Rack-Erkennungsskript usw.
Die letzten Schritte (nach dem Verschieben der Server) umfassten das Verschieben der Replikate auf die Hauptserver und das Herunterfahren der alten Datenbanken. Um die Priorität der Datenbankübertragung zu bestimmen, haben wir wie geplant Zookeeper für die erforderliche Konfiguration von Anwendungsclustern verwendet.
Migrationsstrategie für Anwendungsdienste
Um die Arbeitslast der Anwendungsdienste vom aktuellen Hosting in die GCP-Cloud zu übertragen, haben wir den Lift-and-Shift-Ansatz verwendet. Für jeden Anwendungsdienst haben wir eine Gruppe verwalteter Instanzen (MIG) mit automatischer Skalierung erstellt.
In Übereinstimmung mit einem detaillierten Plan haben wir begonnen, Dienste nach GCP zu migrieren, wobei die Reihenfolge und Abhängigkeiten von Data Warehouses berücksichtigt wurden. Alle Messaging-Stack-Dienste wurden ohne Ausfallzeiten auf GCP migriert. Ja, es gab einige kleinere Störungen, aber wir haben uns sofort darum gekümmert.
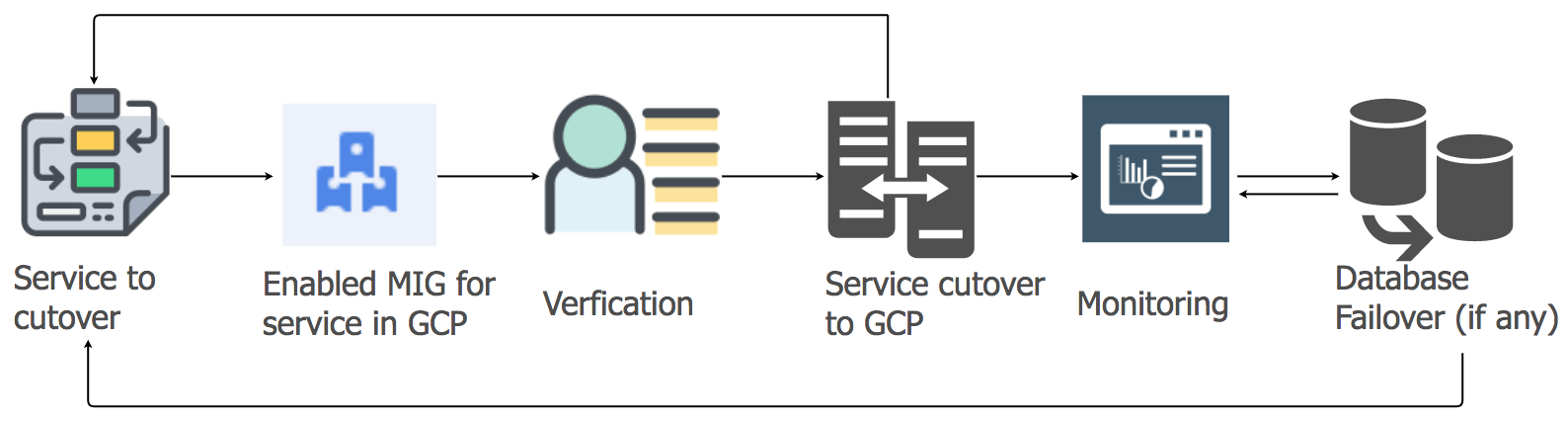
Am Morgen, als die Benutzeraktivität zunahm, folgten wir sorgfältig allen Dashboards und Indikatoren, um Probleme schnell zu identifizieren. Einige Schwierigkeiten traten wirklich auf, aber wir konnten sie schnell beseitigen. Eines der Probleme war auf die Einschränkungen des internen Load Balancers (ILB) zurückzuführen, der nicht mehr als 20.000 gleichzeitige Verbindungen verarbeiten kann. Und wir brauchten 8 mal mehr! Aus diesem Grund haben wir unserer Verbindungsverwaltungsschicht zusätzliche ILBs hinzugefügt.
In den ersten Stunden der Spitzenlast nach dem Übergang haben wir alle Parameter besonders sorgfältig gesteuert, da die gesamte Last des Messaging-Stacks auf GCP übertragen wurde. Es gab ein paar kleine Pannen, mit denen wir uns sehr schnell befasst haben. Bei der Migration anderer Dienste haben wir den gleichen Ansatz gewählt.
Objektspeichermigration:
Wir verwenden den Objektspeicherdienst hauptsächlich auf drei Arten.
⊹ Speicherung von Mediendateien, die an einen persönlichen oder Gruppenchat gesendet wurden. Die Aufbewahrungsdauer wird durch die Lebenszyklusmanagementrichtlinie festgelegt.
⊹ Speicherung von Bildern und Miniaturansichten des Benutzerprofils.
⊹ Speicherung von Mediendateien aus den Abschnitten "Verlauf" und "Zeitleiste" sowie den entsprechenden Miniaturansichten.
Wir haben das Speicherübertragungstool von Google verwendet, um alte Objekte von S3 nach GCS zu kopieren. Wir haben auch eine benutzerdefinierte Kafka-basierte MIG verwendet, um Objekte von S3 nach GCS zu übertragen, wenn eine spezielle Logik erforderlich war.
Der Übergang von S3 zu GCS umfasste die folgenden Schritte:
● Für den ersten Anwendungsfall des Objektspeichers haben wir begonnen, neue Daten sowohl in S3 als auch in GCS zu schreiben, und nach Ablauf haben wir begonnen, Daten aus GCS mithilfe der Logik auf der Anwendungsseite zu lesen. Das Übertragen alter Daten ist nicht sinnvoll und dieser Ansatz ist kostengünstig.
● Für den zweiten und dritten Anwendungsfall haben wir begonnen, neue Objekte in GCS zu schreiben, und den Pfad zum Lesen von Daten so geändert, dass die Suche zuerst in GCS und erst dann in S3 durchgeführt wird, wenn das Objekt nicht gefunden wird.
Es dauerte Monate , um zu planen, die Richtigkeit des Konzepts zu überprüfen, vorzubereiten und Prototypen zu erstellen, aber dann haben wir uns für den Übergang entschieden und ihn sehr schnell umgesetzt. Wir haben die Risiken bewertet und festgestellt, dass eine schnelle Migration vorzuziehen und kaum wahrnehmbar ist.
Dieses Großprojekt hat uns geholfen, eine starke Position zu erlangen und die Teamproduktivität in vielen Bereichen zu steigern, da die meisten manuellen Vorgänge zur Verwaltung der Cloud-Infrastruktur in der Vergangenheit liegen.
● Was die Benutzer betrifft, haben wir jetzt alles Notwendige erhalten, um die höchste Qualität ihres Dienstes sicherzustellen. Die Ausfallzeiten sind fast verschwunden und neue Funktionen werden schneller implementiert.
● Unser Team verbringt weniger Zeit mit Wartungsaufgaben und kann sich auf Automatisierungsprojekte und die Erstellung neuer Tools konzentrieren.
● Wir haben Zugriff auf eine beispiellose Reihe von Tools für die Arbeit mit Big Data sowie auf vorgefertigte Funktionen für maschinelles Lernen und Analyse. Details finden Sie hier.
● Das Engagement von Google Cloud für die Zusammenarbeit mit dem Open Source-Projekt von Kubernetes entspricht auch unserem Entwicklungsplan für dieses Jahr.