In einem der vorherigen Artikel habe ich darüber gesprochen, wie Sie einen Programm-Executor für eine virtuelle Stack-Maschine mithilfe funktionaler und sprachorientierter Programmieransätze erstellen können. Die mathematische Struktur der Sprache schlug die Grundstruktur für die Implementierung ihres Übersetzers vor, die auf dem Konzept von Halbgruppen und Monoiden basiert. Dieser Ansatz ermöglichte es mir, eine schöne und erweiterbare Implementierung zu erstellen und den Applaus zu brechen, aber die erste Frage des Publikums ließ mich vom Podium steigen und wieder in Emacs einsteigen.

Ich habe einen einfachen Test durchgeführt und sichergestellt, dass bei einfachen Aufgaben, bei denen nur der Stapel verwendet wird, die virtuelle Maschine intelligent funktioniert und bei Verwendung des "Speichers" - eines Arrays mit wahlfreiem Zugriff - große Probleme auftreten. Wie wir es geschafft haben, sie zu lösen, ohne die Grundprinzipien der Programmarchitektur zu ändern und eine tausendfache Beschleunigung des Programms zu erreichen, wird in diesem Artikel erörtert.
Haskell ist eine eigenartige Sprache mit einer besonderen Nische. Das Hauptziel seiner Schaffung und Entwicklung war die Notwendigkeit der Verkehrssprache, Ideen der funktionalen Programmierung auszudrücken und zu testen. Dies rechtfertigt seine auffälligsten Merkmale: Faulheit, extreme Reinheit, Betonung von Typen und Manipulationen mit ihnen. Es war nicht für die alltägliche Entwicklung gedacht, nicht für die industrielle Programmierung, nicht für den weit verbreiteten Gebrauch. Die Tatsache, dass es wirklich zur Erstellung von Großprojekten in der Netzwerkbranche und in der Datenverarbeitung verwendet wird, ist der gute Wille der Entwickler, ein Proof of Concept, wenn Sie möchten. Aber das wichtigste, weit verbreitete und erstaunlich leistungsfähige Produkt, das in Haskell geschrieben wurde, ist ... der ghc-Compiler. Und dies ist unter dem Gesichtspunkt seines Zwecks völlig gerechtfertigt - ein Werkzeug für die Forschung auf dem Gebiet der Informatik zu sein. Das von Simon Payton-Johnson proklamierte Prinzip: „Vermeiden Sie Erfolg um jeden Preis“ ist notwendig, damit die Sprache ein solches Instrument bleibt. Haskell ist wie eine sterile Kammer im Labor eines Forschungszentrums, das Halbleitertechnologien oder Nanomaterialien entwickelt. Es ist furchtbar unpraktisch, darin zu arbeiten, und für die tägliche Praxis schränkt es auch die Handlungsfreiheit ein, aber ohne diese Unannehmlichkeiten und ohne kompromisslose Einhaltung von Beschränkungen wird es nicht möglich sein, die subtilen Auswirkungen zu beobachten und zu untersuchen, die später die Grundlage industrieller Entwicklungen werden. Gleichzeitig wird in der Industrie Sterilität nur in dem notwendigsten Volumen benötigt, und die Ergebnisse dieser Experimente werden in Form von Geräten in unseren Taschen erscheinen. Wir untersuchen Sterne und Galaxien nicht, weil wir erwarten, dass sie direkten Nutzen daraus ziehen, sondern weil auf der Skala dieser unpraktischen Objekte quanten- und relativistische Effekte beobachtet und untersucht werden, so dass wir dieses Wissen später nutzen können, um etwas sehr Nützliches zu entwickeln. Haskell mit seinen "falschen" Linien, der unpraktischen Faulheit der Berechnungen, der Starrheit einiger Inferenzalgorithmen mit einer extrem steilen Eingabekurve ermöglicht es Ihnen schließlich nicht, einfach eine intelligente Anwendung auf dem Knie oder einem Betriebssystem zu erstellen. Linsen, Monaden, kombinatorisches Parsen, die weit verbreitete Verwendung von Monoiden, Methoden zur automatischen Theoremprüfung, deklarative Funktionspaketmanager, lineare und abhängige Typen nähern sich jedoch der praktischen Welt. Dies findet Anwendung unter weniger sterilen Bedingungen in den Sprachen Python, Scala, Kotlin, F #, Rust und vielen anderen. Aber ich würde keine dieser wunderbaren Sprachen verwenden, um die Prinzipien der funktionalen Programmierung zu lehren: Ich würde den Schüler ins Labor bringen, in hellen und sauberen Beispielen zeigen, wie es funktioniert, und dann können Sie diese Prinzipien in der Fabrik in Aktion sehen eine große und unverständliche, aber sehr schnelle Maschine. Erfolg um jeden Preis zu vermeiden, ist ein Schutz vor Versuchen, eine Kaffeemaschine in ein Elektronenmikroskop zu stecken, um sie bekannt zu machen. Und bei Wettbewerben, deren Sprache cooler ist, wird Haskell immer außerhalb der üblichen Nominierungen liegen.
Die Person ist jedoch schwach und ein Dämon lebt auch in mir, was mich dazu bringt, „meine Lieblingssprache“ vor anderen zu vergleichen, zu bewerten und zu verteidigen. Nachdem ich eine elegante Implementierung einer gestapelten Maschine geschrieben hatte, die auf einer monoidalen Komposition basiert, um zu sehen, ob diese Idee für mich funktioniert, war ich sofort verärgert, dass mir klar wurde, dass die Implementierung brillant, aber schrecklich ineffizient funktionierte! Es ist, als würde ich es wirklich für ernsthafte Aufgaben verwenden oder meine gestapelte Maschine auf demselben Markt verkaufen, auf dem virtuelle Python- oder Java-Maschinen angeboten werden. Aber verdammt noch mal, der Artikel über das Ferkel, mit dem dieses ganze Gespräch begann, gibt so leckere Zahlen: Hunderte von Millisekunden für das Ferkel, Sekunden für Python ... und mein wunderschöner Monoid kann dieselbe Aufgabe nicht in einer Stunde bewältigen! Ich muss es schaffen! Mein Mikroskop brüht Espresso nicht schlechter als eine Kaffeemaschine im Flur des Instituts! Der Kristallpalast kann zerstreut und ins All gebracht werden!
Aber was willst du aufgeben, fragt mich der Mathematiker-Engel? Die Reinheit und Transparenz der Palastarchitektur? Welche Flexibilität und Erweiterbarkeit bieten Homomorphismen von Programmen zu anderen Lösungen? Der Dämon und der Engel sind beide hartnäckig, und der weise Taoist, den auch ich leben lasse, schlug vor, dass wir den Weg gehen, der zu beiden passt, und ihm so lange wie möglich folgen. Nicht mit dem Ziel, den Gewinner zu identifizieren, sondern um den Weg selbst zu kennen, herauszufinden, wie weit er führt, und um neue Erfahrungen zu sammeln. Und so kannte ich die vergebliche Traurigkeit und Freude an der Optimierung.
Bevor wir beginnen, fügen wir hinzu, dass Vergleiche von Sprachen hinsichtlich ihrer Effektivität sinnlos sind. Sie müssen Übersetzer (Dolmetscher oder Compiler) oder die Leistung eines Programmierers vergleichen, der die Sprache verwendet. Am Ende lässt sich die Behauptung, dass C-Programme am schnellsten sind, leicht widerlegen, indem beispielsweise ein vollständiger C-Interpreter in BASIC geschrieben wird. Wir vergleichen also nicht Haskell und Javascript, sondern die Leistung von Programmen, die von einem von ghc kompilierten Übersetzer ausgeführt werden, und von Programmen, die beispielsweise in einem bestimmten Browser ausgeführt werden. Die gesamte Schweine-Terminologie stammt aus einem inspirierenden Artikel über gestapelte Maschinen. Der gesamte Haskell-Code, der dem Artikel beiliegt, kann im Repository untersucht werden .
Wir verlassen die Komfortzone
Die Ausgangsposition wird die Implementierung einer monoidalen Stapelmaschine in Form von EDSL sein - einer kleinen einfachen Sprache, die es ermöglicht, zwei Dutzend Grundelemente zu kombinieren, um Programme für eine virtuelle Stapelmaschine zu rendern. Sobald er in den zweiten Artikel gekommen ist, geben wir ihm den Namen monopig . Es basiert auf der Tatsache, dass Sprachen für gestapelte Maschinen ein Monoid mit einer Verkettungsoperation und einer leeren Operation als Einheit bilden. Dementsprechend wurde er selbst in Form einer monoiden Transformation des Maschinenzustands aufgebaut. Der Zustand umfasst einen Stapel, einen Speicher in Form eines Vektors (eine Struktur, die einen zufälligen Zugriff auf Elemente ermöglicht), ein Not-Aus-Flag und eine monoidale Batterie zum Sammeln von Debugging-Informationen. Diese gesamte Struktur wird entlang einer Kette von Endomorphismen von Operation zu Operation übertragen, wobei ein Rechenprozess ausgeführt wird. Eine isomorphe Struktur von Programmcodes wurde aus der Struktur, die die Programme bilden, und daraus Homomorphismen in andere nützliche Strukturen aufgebaut, die die Anforderungen an das Programm in Bezug auf die Anzahl der Argumente und den Speicher darstellen. Die letzte Phase der Konstruktion war die Erstellung von Transformationsmonoiden in der Kategorie Claysley, mit denen Sie Berechnungen in eine beliebige Monade eintauchen können. So erhielt die Maschine die Fähigkeit zur Eingabe / Ausgabe und zu mehrdeutigen Berechnungen. Wir beginnen mit dieser Implementierung. Ihren Code finden Sie hier .
Wir werden die Wirksamkeit des Programms auf die naive Implementierung des Eratosthenes-Siebs testen, das den Speicher (Array) mit Nullen und Einsen füllt und Primzahlen mit Null bezeichnet. Wir geben den Verfahrenscode des Algorithmus in javascript :
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
Der Algorithmus wird sofort leicht optimiert. Es beseitigt schlechtes Gehen durch bereits gefüllte Speicherzellen. Mein mathematischer Engel stimmte einer wirklich naiven Version aus einem Beispiel im PorosenokVM Projekt nicht zu, da diese Optimierung nur fünf Anweisungen der Stapelsprache kostet. So übersetzt sich der Algorithmus in monopig :
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
Und so können Sie eine äquivalente Implementierung dieses Algorithmus auf dem idiomatischen Haskell schreiben, wobei Sie dieselben Typen wie in monopig :
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
Es verwendet den Data.Vector Typ und die Tools für die Arbeit damit, die für die tägliche Arbeit in Haskell nicht allzu häufig sind. Ausdruck m ! k m ! k gibt das k te Element des Vektors m und m // [(n,1)] - setzt das Element mit der Zahl n auf 1. Ich schreibe dies hier, weil ich zu ihnen gehen musste, um Hilfe zu erhalten, obwohl ich in Haskell arbeite fast jeden Tag. Tatsache ist, dass Strukturen mit wahlfreiem Zugriff in einer funktionalen Implementierung ineffizient und aus diesem Grund ungeliebt sind.
Gemäß den im Artikel über das Ferkel angegebenen Wettbewerbsbedingungen wird der Algorithmus 100 Mal ausgeführt. Um einen bestimmten Computer loszuwerden, vergleichen wir die Ausführungsgeschwindigkeiten dieser drei Programme und verweisen sie auf die Leistung des in Chrome ausgeführten javascript Programms.
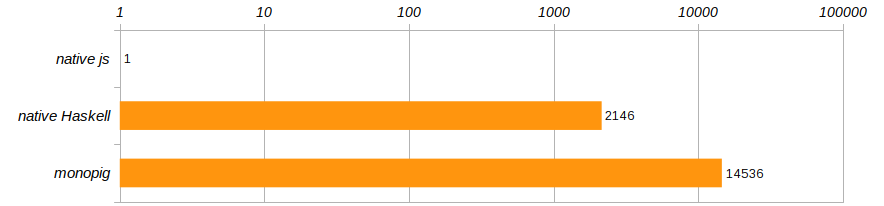
Horror Horror !!! monopig verlangsamt sich nicht nur gottlos, die native Version ist auch nicht viel besser! Haskell ist natürlich cool, aber einem Programm, das in einem Browser ausgeführt wird, nicht unterlegen ?! Wie Trainer uns lehren, können Sie nicht so leben, es ist Zeit, die Komfortzone zu verlassen, die Haskell uns bietet!
Faulheit überwinden
Lass es uns richtig machen. Kompilieren Sie dazu ein Programm auf monopig mit dem Flag -rtsopts , um die -rtsopts zu -rtsopts und zu sehen, was wir brauchen, um das Eratosthenes-Sieb einmal auszuführen:
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
Die letzte Zeile sagt uns, dass das Programm nur ein Drittel der Zeit mit produktivem Computing beschäftigt war. Für den Rest der Zeit lief der Garbage Collector aus dem Speicher und räumte für träge Berechnungen auf. Wie oft wurde uns in der Kindheit gesagt, dass Faulheit nicht gut ist! Hier hat uns das Hauptmerkmal von Haskell einen schlechten Dienst erwiesen und versucht, mehrere Milliarden verzögerte Vektor- und Stapeltransformationen zu erstellen.
Ein mathematischer Engel hebt an dieser Stelle den Finger und spricht glücklich darüber, dass es seit der Zeit der Alonzo-Kirche einen Satz gibt, der besagt, dass die Berechnungsstrategie das Ergebnis nicht beeinflusst, was bedeutet, dass wir sie aus Effizienzgründen frei wählen können. Die Berechnungen auf streng zu ändern ist überhaupt nicht schwierig - setzen Sie ein Zeichen ! in der Deklaration der Art des Stapels und des Speichers, und machen Sie dadurch diese Felder streng.
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
Wir werden nichts anderes ändern und sofort das Ergebnis überprüfen:
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
Die Produktivität ist deutlich gestiegen. Die Gesamtspeicherkosten blieben aufgrund der Unveränderlichkeit der Daten immer noch beeindruckend, aber vor allem, da wir die Faulheit der Daten begrenzt haben, hat der Garbage Collector die Möglichkeit, faul zu sein, nur 5% der Arbeit verbleiben darauf. Geben Sie einen neuen Eintrag in die Bewertung ein.

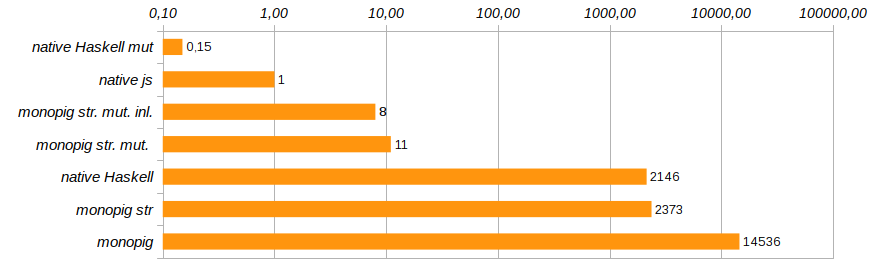
Nun, strenge Berechnungen haben uns der Geschwindigkeit des nativen Haskell-Codes näher gebracht, der ohne virtuelle Maschine schändlich langsamer wird. Dies bedeutet, dass der Aufwand für die Verwendung eines unveränderlichen Vektors die Kosten für die Wartung einer gestapelten Maschine erheblich übersteigt. Und das bedeutet, dass es Zeit ist, sich von der Unveränderlichkeit des Gedächtnisses zu verabschieden.
Veränderungen ins Leben lassen
Der Data.Vector Typ Data.Vector gut, aber wenn wir ihn verwenden, verbringen wir viel Zeit mit dem Kopieren, um die Reinheit des Rechenprozesses zu erhalten. Data.Vector.Unpacked wir es durch den Typ Data.Vector.Unpacked ersetzen Data.Vector.Unpacked sparen wir zumindest die Verpackung der Struktur, aber dies ändert das Bild nicht grundlegend. Die richtige Lösung wäre, den Speicher aus dem Zustand der Maschine zu entfernen und mithilfe der Kategorie Kleisley Zugriff auf den externen Vektor zu gewähren. Gleichzeitig können Sie zusammen mit reinen Vektoren die sogenannten veränderlichen (veränderlichen) Vektoren Data.Vector.Mutable .
Wir werden die entsprechenden Module verbinden und darüber nachdenken, wie mit veränderlichen Daten in einem sauberen Funktionsprogramm umgegangen werden soll.
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
Diese schmutzigen Typen sollen von der reinen Öffentlichkeit isoliert sein. Sie sind in den Monaden der PrimMonad Klasse enthalten (einschließlich ST oder IO ), in denen saubere Programme sorgfältig Anweisungen für Aktionen einfügen, die in einer Kristallfunktionssprache auf wertvollem Pergament geschrieben sind. Daher wird das Verhalten dieser unreinen Tiere durch streng orthodoxe Szenarien bestimmt und ist nicht gefährlich. Nicht alle Programme für unsere Maschine verwenden Speicher, daher muss die gesamte Architektur nicht zum Eintauchen in die IO Monade verurteilt werden. Zusammen mit einer sauberen Teilmenge der monopig Sprache monopig wir vier Anweisungen erstellen, die den Zugriff auf den Speicher ermöglichen, und nur sie haben Zugriff auf das gefährliche Gebiet.
Die Art der sauberen Maschine wird immer kürzer:
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
Programmdesigner und die Programme selbst werden diese Änderung kaum bemerken, aber ihre Typen werden sich ändern. Darüber hinaus ist es sinnvoll, verschiedene Arten von Synonymen zu definieren, um die Signaturen zu vereinfachen.
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
Konstruktoren haben ein weiteres Argument, das den Speicherzugriff darstellt. Ausführende werden sich erheblich ändern, insbesondere diejenigen, die ein Berechnungsprotokoll führen, da sie jetzt den Status des Variablenvektors danach fragen müssen. Der vollständige Code kann im Repository angezeigt und studiert werden, aber hier werde ich das Interessanteste geben: die Implementierung der grundlegenden Komponenten für die Arbeit mit dem Speicher, um zu zeigen, wie dies gemacht wird.
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
Der Optimizer-Daemon bot sofort an, beim Überprüfen der zulässigen Indexwerte im Speicher etwas mehr zu sparen, da bei puti und geti Indizes in der Phase der Programmerstellung bekannt sind und falsche Werte im Voraus beseitigt werden können. Dynamisch definierte Indizes für put und get Befehle garantieren keine Sicherheit, und der Mathematiker-Engel erlaubte keine gefährlichen Aufrufe an sie.
All diese Aufregung, das Gedächtnis in ein separates Argument zu setzen, scheint kompliziert. Aber es zeigt sehr deutlich, welche Daten von ihrem Ort geändert werden müssen - sie sollten draußen sein . Ich erinnere Sie daran, dass wir versuchen, einen Pizzaboten in ein steriles Labor zu bringen. Reine Funktionen wissen, was sie damit anfangen sollen, aber diese Objekte werden niemals zu erstklassigen Bürgern, und es lohnt sich nicht, Pizza direkt im Labor zuzubereiten.
Lassen Sie uns überprüfen, was wir mit diesen Änderungen gekauft haben:
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
Das ist schon ein Fortschritt! Die Speichernutzung wurde um das Achtfache reduziert, die Programmausführungsgeschwindigkeit um das 180-fache erhöht und der Garbage Collector blieb fast vollständig ohne Arbeit.

Die Lösung erschien monopig st. mut. js ist zehnmal langsamer als die native Lösung auf js , aber abgesehen davon die native Lösung auf Haskell unter Verwendung veränderlicher Vektoren. Hier ist sein Code:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
Es beginnt wie folgt
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
Und jetzt zeigt Haskell endlich, dass er keine Spielzeugsprache ist. Sie müssen es nur mit Bedacht einsetzen. Übrigens verwendet der obige Code die Tatsache, dass der Typ IO () eine Halbgruppe mit der Operation der sequentiellen Ausführung von Programmen (>>) , und mit Hilfe von stimes wir die Berechnung des Testproblems 100-mal wiederholt.
Jetzt ist klar, warum es eine solche Abneigung gegen funktionale Arrays gibt und warum sich niemand daran erinnert, wie man mit ihnen arbeitet: Sobald ein Haskell-Programmierer wirklich Direktzugriffsstrukturen benötigt, konzentriert er sich wieder auf veränderbare Daten und arbeitet in ST- oder IO-Monaden.
Das Herausbringen eines Teils von Befehlen in eine spezielle Zone stellt die Rechtmäßigkeit des Isomorphismus in Frage das Programm . Schließlich können wir den Code nicht gleichzeitig in reine und monadische Programme umwandeln, dies erlaubt dem Typsystem dies nicht. Typklassen sind jedoch flexibel genug, damit dieser Isomorphismus existiert. Homomorphismus- Code Das Programm ist nun in mehrere Homomorphismen für verschiedene Teilmengen der Sprache unterteilt. Wie genau dies gemacht wird, sehen Sie im vollständigen [Code] () des Programms.
Hör hier nicht auf
Durch das Eliminieren unnötiger Funktionsaufrufe und das direkte Einbetten des Codes mithilfe des {-# INLINE #-} die Produktivität des Programms geringfügig geändert werden. Diese Methode ist für rekursive Funktionen ungeeignet, eignet sich jedoch hervorragend für grundlegende Komponenten und Setterfunktionen. Es reduziert die Ausführungszeit des Testprogramms um weitere 25% (siehe Monopig51.hs ).
Der nächste vernünftige Schritt besteht darin, die Protokollierungswerkzeuge zu entfernen, wenn sie nicht benötigt werden. In der Phase der Bildung des Endomorphismus, der das Programm darstellt, verwenden wir ein externes Argument, das wir beim Start bestimmen. Smart-Konstruktoren program und programM können gewarnt werden, dass möglicherweise kein Argument-Logger vorhanden ist. In diesem Fall enthält der Konvertercode nichts Überflüssiges: nur die Funktionalität und die Überprüfung des Maschinenstatus.
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
Jetzt muss das Ausführen von Funktionen explizit das Vorhandensein oder Fehlen einer Protokollierung anzeigen, die nicht den Stub none , sondern den Typ Maybe (Logger ma) . Warum sollte dies funktionieren, denn wenn es eine Protokollierung gibt oder nicht, werden die Programmkomponenten "im letzten Moment" vor der Ausführung herausfinden? Würde der unnötige Code nicht beim Erstellen der Programmkomposition genäht? Haskell ist eine faule Sprache und hier spielt sie uns in die Hände. Vor der Ausführung wird der endgültige Code für eine bestimmte Aufgabe optimiert. Diese Optimierung reduzierte die Programmausführungszeit um weitere 40% (siehe Monopig52.hs ).
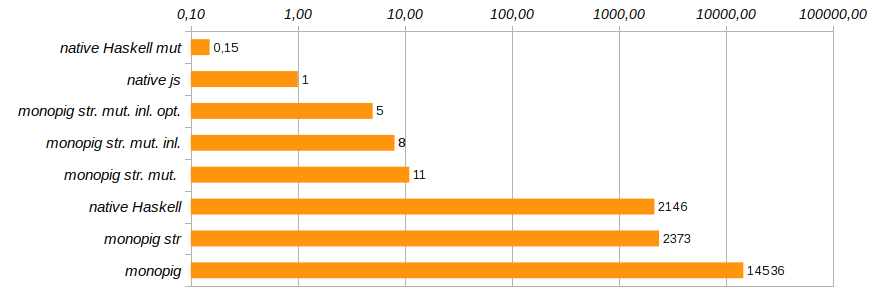
Damit werden wir die Arbeiten zur Beschleunigung des monoidalen Ferkels abschließen. Er rennt bereits schnell genug, damit sich sowohl der Engel als auch der Dämon beruhigen können. Dies ist natürlich nicht C, wir verwenden immer noch eine saubere Liste als Stapel, aber das Ersetzen durch ein Array führt zu einer gründlichen Ausgrabung des Codes und der Weigerung, elegante Vorlagen in den Definitionen grundlegender Befehle zu verwenden. Ich wollte mit minimalen Änderungen auskommen, hauptsächlich auf der Ebene der Typen.
Einige Probleme bleiben bei der Protokollierung bestehen. Eine einfache Zählung der Anzahl der Schritte oder die Verwendung des Stapels funktioniert gut (wir haben das Protokollfeld streng gemacht), aber wenn Sie sie seq , wird bereits Speicherplatz verbraucht. Sie müssen sich mit Kicks mit seq , was bereits ziemlich ärgerlich ist. Aber sagen Sie mir, wer wird die 14 Milliarden Schritte protokollieren, wenn Sie die Aufgabe in den ersten Hunderten debuggen können? Ich werde also nicht meine Zeit damit verbringen, für die Beschleunigung zu beschleunigen.
Es muss nur hinzugefügt werden, dass in dem Artikel über das Ferkel als eine der Methoden zur Optimierung von Berechnungen die Ablaufverfolgung angegeben wird: die Zuordnung von linearen Codeabschnitten, Ablaufverfolgungen, innerhalb derer Berechnungen unter Umgehung des Hauptbefehlsversandzyklus ( switch ) durchgeführt werden können. In unserem Fall erzeugt die monoidale Zusammensetzung der Programmkomponenten solche Spuren entweder während der Bildung des Programms aus den EDSL-Komponenten oder während des Betriebs des fromCode Homomorphismus. Diese Optimierungsmethode steht uns sozusagen kostenlos zur Verfügung.
Es gibt viele Conduits und schnelle Lösungen im Haskell-Ökosystem, wie z. B. Conduits oder Pipes Streams, ausgezeichnete String Ersetzungen und flinke XML-Ersteller wie attoparsec -html, und der attoparsec Parser ist ein Standard für die kombinatorische Analyse von LL (∞) -Grammatiken. All dies ist für den normalen Betrieb notwendig. Noch notwendiger ist jedoch die Forschung, die zu diesen Entscheidungen führt. Haskell war und ist ein Forschungsinstrument, das bestimmte Anforderungen erfüllt, die von der Öffentlichkeit nicht benötigt werden. Ich sah in Kamtschatka, wie Asse in einem Mi-4-Hubschrauber bei einem Streit Streichholzschachteln schlossen und das Fahrwerk mit einem Rad drückten, während sie in der Luft hingen. Dies ist möglich und cool, aber nicht erforderlich.
Aber trotzdem ist das cool !!