Die Entstehung von Ideen
Kürzlich war ich bei Freunden und wir haben uns für einen Film entschieden, und ich als Fan eines verbrannten Films (in der Tat nicht so direkt verbrannt) habe alles abgelehnt, was ich mir angesehen habe. Und sie haben mir eine logische Frage gestellt, aber warum hast du überhaupt nicht nachgesehen? Zu dem ich sagte, dass ich eine Filmsuche durchführe und mir jeden Film ansehe, den ich gesehen habe, entweder nach Bewertung oder nur nach einem Häkchen, dass die Wiedergabe stattgefunden hat. Und dann tauchte eine Frage in meinem Kopf auf, aber wie viel Zeit habe ich für Filme aufgewendet? Steam hat praktische Statistiken für das Spiel, aber nichts für Filme. Also habe ich beschlossen, diese Idee in Angriff zu nehmen.
Was ist mit der Implementierung los?
Ich habe mehrere Jahre auf ASP.NET entwickelt und bin an C # gewöhnt. Zuerst wollte ich dieses Dienstprogramm darauf schreiben, aber es gab ein Problem mit einer schweren Umgebung, und da ich mit Python ein wenig vertraut bin, habe ich darauf zurückgegriffen.
Und woher bekommen die Daten?
Und hier stehe ich vor dem ersten Problem. Ich ging naiv davon aus, dass die Filmsuche eine offizielle öffentliche API und eine Art kostenlose Version hat. Aber so etwas habe ich nicht gefunden. Es besteht die Möglichkeit, technische Unterstützung anzufordern, aber selbst dort geben sie nur den n-ten Betrag aus, und ich habe dies für mich selbst geschrieben und wollte es in keiner Weise bezahlen.
Natürlich musste ich die Möglichkeit in Betracht ziehen, Seiten zu analysieren, und darauf hörte ich auf.
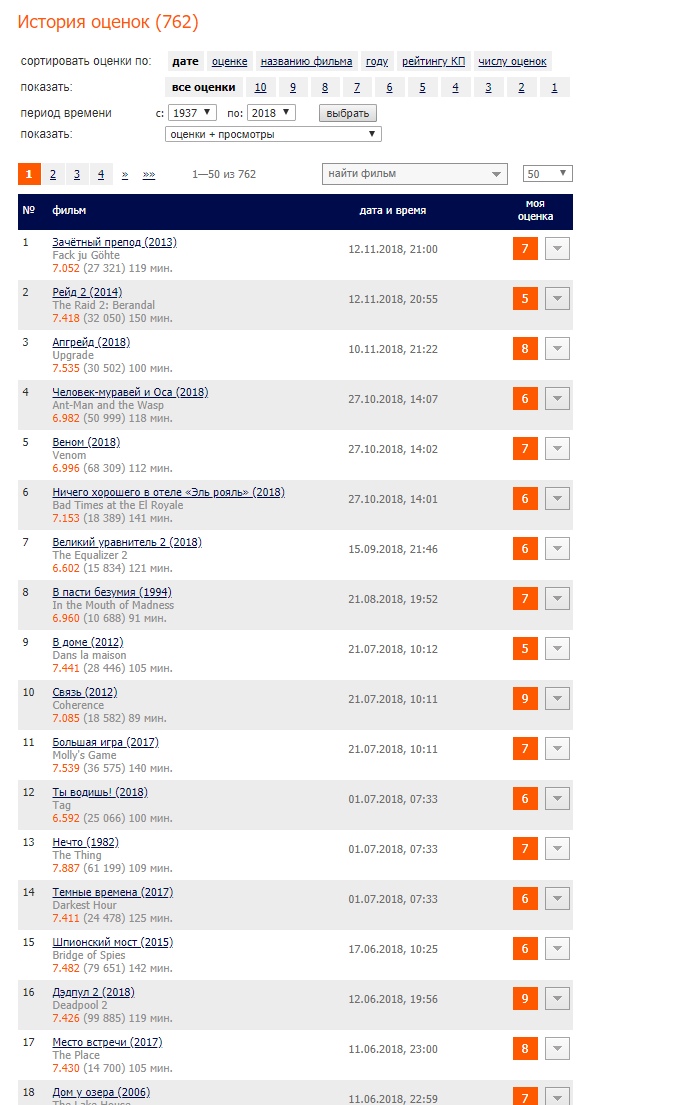
Jeder im Profil hat eine Liste der gesehenen Filme mit einer kleinen Beschreibung, die die Dauer des Bildes enthält. Auf diese Weise kann ich nur wenige Seiten erhalten (ich habe 762 Filme und es war notwendig, nur 17 Seiten zu erhalten) und die aufgewendete Zeit berechnen.
Kaum gesagt als getan.
class KinopoiskParser: def __init__(self, user_id, current_page=1): self._user_id = user_id self._current_page = current_page self._wasted_time_in_minutes = 0 def calculate_wasted_time(self): while True: film_list_url = f'https://www.kinopoisk.ru/user/{self._user_id}' \ f'/votes/list/ord/date/genre/films/page/{self._current_page}/#list' try: film_response = requests.get(film_list_url).text except BaseException: proxy_manager.update_proxy() continue user_page = BeautifulSoup(film_response, "html.parser") is_end = kinopoisk_parser._check_that_is_end_of_film_list(user_page) if is_end: break wasted_time = self._get_film_duration_on_page(user_page) self._wasted_time_in_minutes += wasted_time print(f'Page {self._current_page}, wasted time {self._wasted_time_in_minutes}') self._move_next_page() def get_wasted_time(self): return self._wasted_time_in_minutes def _move_next_page(self): self._current_page += 1 @staticmethod def _get_film_duration_on_page(user_page): try: wasted_time = 0 film_list = user_page.findAll("div", {"class": "profileFilmsList"})[0].findAll("div", {"class": "item"}) for film in film_list: film_description = film.findAll("span") if len(film_description) <= 1: continue film_duration_in_minutes = int(film_description[1].string.split(" ")[0]) wasted_time = wasted_time + film_duration_in_minutes return wasted_time except BaseException: print("Something went wrong.") return 0 @staticmethod def _check_that_is_captcha(html): captcha_element = html.find_all("a", {"href": "//yandex.ru/support/captcha/"}) return len(captcha_element) > 0 @staticmethod def _check_that_is_end_of_film_list(html): error_element = html.find_all("div", {"class": "error-page__container-left"}) return len(error_element) > 0
Aber bereits in der Debugging-Phase stieß ich auf ein Problem, bei dem die Kinosuche Anfragen blockiert (ca. 4 Iterationen) und sie als verdächtig ansieht. Und er hat recht! Ich schlug diese Option aber auch vor und fuhr mit Plan B fort.
Plan B - Proxies wie Handschuhe wechseln
Nehmen Sie den ersten Server, der eine API zum Abrufen des IP-Proxys bereitstellt (ich mache keine Werbung für die Dienste, nehme die ersten beiden Links von Google), schraubte ihn schief und schrieb den Hauptcode weiter. Und eine Stunde später, als ich kurz vor dem Abschluss stand, wurde ich von dem Server blockiert, den die API bereitstellt! Ich musste es in eine andere ändern, die jede halbe Stunde eine feste Liste erstellt, für meine Aufgabe ist dies genug. Wenn die Liste jedoch plötzlich endet, können Sie zur vorherigen Option zurückkehren (alle 24 Stunden werden 10 bis 24 Proxys ausgegeben).
class ProxyManager: def __init__(self): self._current_proxy = "" self._current_proxy_index = -1 self._proxy_list = [] self._get_proxy_list() def get_proxies(self): proxies = { "http": self._current_proxy, "https": self._current_proxy } return proxies def update_proxy(self): self._current_proxy_index += 1 if self._current_proxy_index == len(self._proxy_list): print("Proxies are ended") print("Try get alternative proxy") proxy_ip_with_port = self._get_another_proxy() print("Proxy updated to " + proxy_ip_with_port) self._current_proxy = f'http://{proxy_ip_with_port}' return self._current_proxy proxy_ip_with_port = self._proxy_list[self._current_proxy_index] print("Proxy updated to " + proxy_ip_with_port) self._current_proxy = f'http://{proxy_ip_with_port}' return self._current_proxy @staticmethod def _get_another_proxy(): proxy_response = requests.get("https://api.getproxylist.com/proxy?protocol[]=http", headers={ 'Content-Type': 'application/json' }).json() ip = proxy_response['ip'] port = proxy_response['port'] proxy = f'{ip}:{port}' return proxy def _get_proxy_list(self): proxy_response = requests.get("http://www.freeproxy-list.ru/api/proxy?anonymity=false&token=demo") self._proxy_list = proxy_response.text.split("\n")
Wenn ich das alles zusammen kombiniere (am Ende werde ich einen Link zum Github mit der endgültigen Version geben), habe ich eine hervorragende Möglichkeit, die für Filme aufgewendete Zeit zu zählen. Und er erhielt die geschätzte Nummer, tadam: "Sie haben 84542 Minuten oder 1409,03 Stunden oder 58,71 Tage verschwendet."
Vergebens verbrachte Zeit, um vergebens verbrachte Zeit zu zählen
In der Tat nicht umsonst. Die Aufgabe war zumindest für jemanden interessant, wenn auch kaum notwendig.
Und jetzt kann ich jedem sagen, dass ich fast zwei Monate meines Lebens einen Film gesehen habe!
Wenn jemand auch daran interessiert sein möchte, solche "wichtigen" Statistiken für sich selbst zu erhalten, kopieren Sie einfach die ID Ihres Profils und starten Sie das Projekt mit diesem Parameter. Wenn Sie das Ergebnis im Kommentar leicht verwerfen können, bin ich an einem "Filmfan" oder einem Anfänger interessiert.
Quellcode-LinkPS Ich werde mich auch über Tipps zur Verbesserung des Codes freuen, da ich sehr wenig über Python geschrieben habe und die Syntax sogar nicht vollständig verstehe.