In diesem Artikel möchte ich über meine langjährige Leidenschaft sprechen - das Studieren und Arbeiten mit Fernfeldmikrofonen (Mikrofonarrays) - Mikrofonarrays.
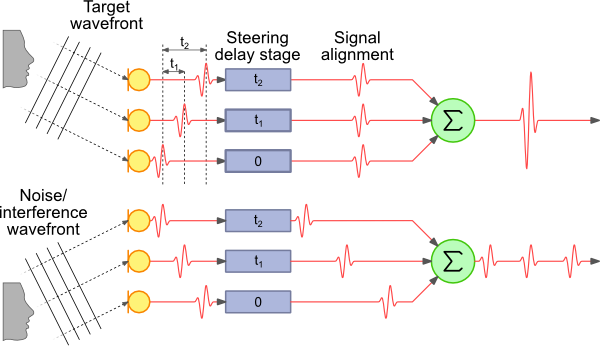
Der Artikel wird für diejenigen interessant sein, die gerne ihre Sprachassistenten aufbauen. Er wird einige Fragen an Menschen beantworten, die Ingenieurwesen als Kunst wahrnehmen und sich auch in der Rolle des Q versuchen möchten ( Dies ist von Bond ). Meine bescheidene Geschichte, ich hoffe, sie kann Ihnen helfen zu verstehen, warum eine intelligente Assistentenspalte, die streng nach dem Tutorial erstellt wurde, nur dann gut funktioniert, wenn überhaupt kein Lärm zu hören ist. Und so schlimm, wo sie sind, zum Beispiel in der Küche.
Vor vielen Jahren begann ich mich für das Programmieren zu interessieren. Ich fing an, Code zu schreiben, nur weil weise Lehrer mir erlaubten, nur von mir selbst geschriebene Spiele zu spielen. Es war ein Jahr, also 87 und es war ein Yamaha MSX. Zu diesem Thema gab es auch einen ersten Start. Alles ist streng nach Weisheit: „Wählen Sie einen Job nach Ihren Wünschen, und Sie müssen keinen einzigen Tag in Ihrem Leben arbeiten“ (Konfuzius).
Und so sind die Jahre vergangen und ich schreibe immer noch Code. Sogar ein Hobby mit einem Code - nun, außer beim Rollschuhlaufen, zum Aufwärmen des Gehirns und "Ich werde Matan nicht vergessen" funktioniert dies mit dem Far Fields-Mikrofon (Mic-Array). Vergebens verbrachten die Lehrer Zeit mit mir.
Was ist es und wo wird es angewendet
Der Sprachassistent, der Ihnen zuhört, verfügt normalerweise über eine Reihe von Mikrofonen. Wir finden sie in Videokonferenzsystemen. In der kollektiven Kommunikation wird der Löwenanteil der Aufmerksamkeit auf die Sprache gerichtet. Natürlich schauen wir bei der Kommunikation nicht ständig auf den Sprecher, aber das direkte Sprechen in das Mikrofon oder Headset ist einschränkend und unpraktisch.
Fast jeder, ein angesehener Kunde, ein Mobiltelefonhersteller, verwendet zwei oder mehr Mikrofone in seinen Kreationen (ja, Mikrofone sitzen hinter diesen Löchern oben, unten, hinten). Zum Beispiel war er im iPhone 3G / 3GS der einzige, in der vierten Generation von iPhones gab es zwei und in der fünften gab es bereits drei Mikrofone. Im Allgemeinen ist dies auch eine Anordnung von Mikrofonen. Und das alles für eine bessere Hörbarkeit des Klangs.
Aber zurück zu unseren Sprachassistenten
Wie kann die Hörreichweite erhöht werden?
"brauche große Ohren"
Eine einfache Idee: Wenn nur ein Mikrofon ausreicht, um das in der Nähe zu hören, müssen Sie ein teureres Mikrofon mit Reflektor verwenden, ähnlich den Ohren von Fenech-Füchsen: Um aus der Ferne zu hören:

(Wikipedia)


 Tatsächlich ist dies kein Teil der pelzigen Suite, sondern ein ernstes Gerät für Jäger und Pfadfinder.
Tatsächlich ist dies kein Teil der pelzigen Suite, sondern ein ernstes Gerät für Jäger und Pfadfinder.

Das gleiche nur bei Resonatorröhren

Im Lebensraum.
(Entnommen aus https://forum.guns.ru )
Durchmesser des Spiegels von 200 mm bis 1,5 m
(mehr davon siehe http://elektronicspy.narod.ru/next.html )
"Benötigen Sie mehr Mikrofone"
Oder wenn Sie viele billige Mikrofone einsetzen, wird die Quantität in Qualität gehen und alles wird funktionieren? Zerghrash nur mit Mikrofonen.
Seltsam, aber es funktioniert im wirklichen Leben. Stimmt mit viel Matan, aber es funktioniert. Und darüber werden wir im nächsten Abschnitt sprechen.
Und wie kann man lernen, ohne schöne Hörner weiter zu hören?

Eines der Probleme bei Hornsystemen besteht darin, dass Sie deutlich hören können, worauf es ankommt. Wenn Sie jedoch etwas aus einer anderen Richtung hören möchten, müssen Sie eine "Finte mit Ihren Ohren" ausführen und das System physisch in eine andere Richtung umleiten.
Und was das Signal-Rausch-Verhältnis in Systemen mit Mikrofonmatrizen betrifft, ist es im Vergleich zu einem herkömmlichen Mikrofon irgendwie besser.
In den Arrays von Mikrofonen sowie in ihren nächsten Verwandten - PAR (Phased Array-Antennen) - müssen Sie nichts drehen. Lesen Sie mehr im Abschnitt Beamforming. Leicht zu sehen:

Ein nicht fokussiertes Mikrofon (linkes Bild) zeichnet alle Töne aus allen Richtungen auf, nicht nur die, die Sie benötigen.
Woher kommt das große Sortiment? Im rechten Bild hört das Mikrofon nur einer Quelle aufmerksam zu. Als ob es fokussiert, empfängt es ein Signal nur von einer ausgewählten Quelle und kein Durcheinander von möglichen Rauschquellen, und ein reines Signal wird einfach verstärkt (lauter gemacht), ohne dass ausgefeilte Rauschunterdrückungstechniken verwendet werden. Ein bisschen wie ein Mundstück, aber auf einer matten Traktion.
Was ist falsch an der Geräuschreduzierung?
Bei der Anwendung einer komplexen Rauschunterdrückung führen viele Fehler dazu, dass ein Teil des Signals zusammen mit einem Teil des Signals verschwindet und sich der Ton ändert. Nach Gehör sieht es aus wie eine charakteristische Färbung des Klangs durch Rauschunterdrückung und als Folge von Unleserlichkeit. Diese Unleserlichkeit ist für russischsprachige Personen sichtbar, die dieses Zischen vom Gesprächspartner hören möchten. Nun, und zusätzlich - aufgrund der Geräuschreduzierung hört der Hörer keine Identifikationssignale, die ihn mit dem Gesprächspartner verbinden (Atmung, Schnüffeln und andere Geräusche, die mit Live-Sprache einhergehen). Dies schafft einige Probleme, da in der Umgangssprache all dies zu hören ist und es nur hilft, den Zustand und die Haltung des Gesprächspartners Ihnen gegenüber zu beurteilen. Das Fehlen von ihnen (Lärm), während wir die Stimme hören, verursacht unangenehme Empfindungen und verringert das Maß an Wahrnehmung, Verständnis und Identifikation. Wenn ein Sprachassistent auf Sie hört, macht es die Rauschunterdrückung schwierig, sowohl die Schlüsselphrase als auch die Sprache danach zu erkennen. Es stimmt, es gibt einen Life-Hack - Sie müssen den Erkenner an einer aufgenommenen Probe trainieren, wobei die Verzerrungen durch die verwendete Rauschunterdrückung berücksichtigt werden.
Diejenigen, die mit den Worten Cocktailparty-Problem vertraut sind, können immer noch Kaffee oder einen Cocktail trinken und ein Feldexperiment durchführen. Diejenigen, die Lust zum Lesen haben, fahren fort.

Kurz über die Matan, auf der es funktioniert:
DOA (Richtungsbestimmung und, wenn möglich, Lokalisierung an der Quelle):
Ich werde mich kurz fassen, da das Thema sehr umfangreich ist. Dies geschieht mit Hilfe von weißer, grauer oder dunkler Magie (abhängig vom bevorzugten Thema in der IDE) und Matan. die Haupt Eine häufige Methode zum Spielen von DOA ist die Analyse von Korrelationen und anderen Dingen zwischen Mikrofonpaaren (normalerweise mit entgegengesetztem Durchmesser).
Life Hack: Für die Forschung ist es besser, ein Array mit einer kreisförmigen Anordnung von Mikrofonen zu wählen. Der Vorteil ist, dass es einfach ist, Statistiken von Paaren mit unterschiedlichen Abständen zwischen Mikrofonen zu sammeln - maximal im Durchmesser und minimal zwischen Mikrofonen -, wenn Sie Paare in Akkorden und mit unterschiedlichen Azimuten (Richtungen) zur Quelle nehmen.
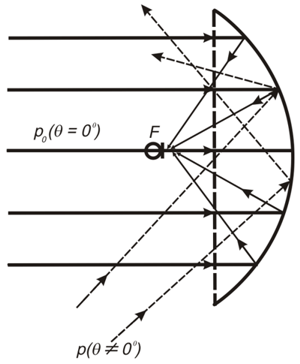
Strahlbildung - Der einfachste und einfachste Weg, dies zu verstehen, ist -delay & sum (DAS und FDAS) - Strahlformung basierend auf Verzögerung und Summe.
Für Visuals:
(Entnommen aus http://www.labbookpages.co.uk/audio/beamforming/delaySum.html )
Life Hack: Vergessen Sie nicht verschiedene Wellenlängen und berechnen Sie für jede Frequenz unsere Phasendifferenz tn
Ein ungefähres Strahlungsmuster sieht ungefähr so aus
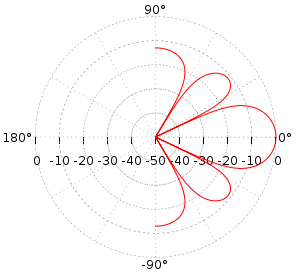
Details und mit Formeln
Diejenigen, die nicht vergessen haben, wie man eine Matan raucht, können an JIO-RLS (Joint Iterative Subspace Adaptive, kleinste Quadrate mit reduziertem Rang) teilnehmen. Sehr ähnlich dem Geschmack des Gefälles, wissen Sie.

Wir fassen also zusammen: Mit herkömmlichen Methoden ist es schwierig, eine mit einem Matrixmikrofon vergleichbare Qualität zu erzielen. Nachdem wir die Definition der Richtung auf die Quelle angewendet haben und infolgedessen nur die Quelle hören, die benötigt wird, werden wir das Rauschen und den Nachhall des Mediums beseitigen, selbst eines, das schlecht hörbar ist (Haas-Effekt).
Sprachassistent - Wie es innen aussieht
Wie sieht das Klangverarbeitungsschema eines erfahrenen Sprachassistenten aus:

Das Signal von der Anordnung der Mikrofone wird einem Gerät zugeführt, in dem wir einen Strahl zu einer Schallquelle bilden (Beamforming), wodurch Interferenzen beseitigt werden. Dann beginnen wir, den Klang dieses Strahls zu erkennen. Normalerweise reicht dies nicht aus, um die Ressourcen des Geräts in hoher Qualität zu erkennen, und meistens wird das Signal zur Erkennung in die Cloud geleitet (Microsoft, Google, Amazon wählen es aus).
Der aufmerksame Leser wird bemerken: Und auf dem Bild mit der Beschreibung gibt es eine Art Quadrat des Wortes Nicht, und warum nicht sofort erkennen, wie versprochen?
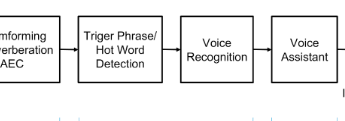
Warum ist dieses zusätzliche Quadrat wahrscheinlich im Diagramm eingezeichnet?
Und weil Sie ständig ein Signal von allen Geräuschquellen ins Internet senden für zuhören Das Erkennen von Ressourcen reicht nicht aus. Daher beginnen wir erst zu erkennen, als sie merkten, dass sie es definitiv von uns wollen - und dafür sagten sie einen besonderen Zauber - ok Google, Siri oder Alex, oder sie nannten mich einen Cortan. Und der Notifier-Wortklassifikator ist meistens ein Neuron und funktioniert direkt auf dem Gerät. In der Konstruktion des Klassifikators gibt es auch viele interessante Dinge, aber heute geht es nicht darum.
Tatsächlich sieht das Diagramm folgendermaßen aus:
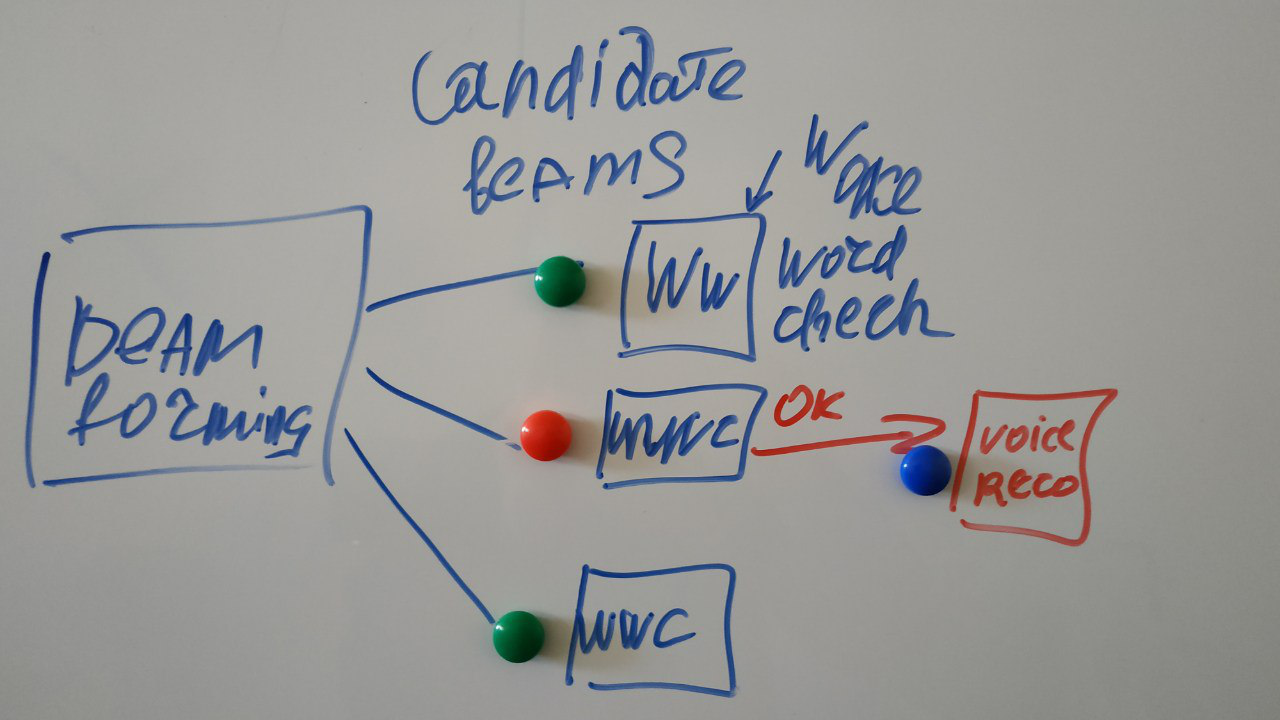
(meine Kritzeleien)
Auf verschiedenen Signalquellen können mehrere Strahlen gebildet werden, und wir suchen in jeder von ihnen nach einem speziellen Wort. Aber weiter werden wir denjenigen verarbeiten, der das richtige Wort gesagt hat.
Der nächste Schritt ist die Erkennung in der Cloud, die wiederholt im Internet behandelt wird. Es gibt viele Tutorials.
Wie können Sie sich dieser Feiertagsmatana anschließen?
Der einfachste Weg, ein Dev Board zu kaufen. Übersicht über vorhandene Devboards: eine der vollständigsten - als Referenz .
Das freundlichste für Anfänger:
https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi-p-2941.html
https://www.seeedstudio.com/ReSpeaker-Mic-Array-v2-0-p-3053.html
basierend auf XMOS XVF-3000.
Ich wende es selbst an
Gemacht nach Belieben - FPGA mit offener Schnittstelle steuert die Mikrofone der Matrix und kommuniziert mit ihr über SDA.
Meine Talente für die Kreuzung von Android Things und Mic Array:
Es gibt sicherlich viele Beispiele für dieses Board (Voice), aber es ist einfach bequem für mich, es unter Dinge zu verwenden.
Argumente für Dinge:
Sie können ein flexibles und leistungsstarkes Tool erstellen:
- Praktisch, dass Sie den Bildschirm als separates Gerät verwenden können
- kann als kopfloses Gerät verwendet werden, d. h. eine Übertragung über das Netzwerk durchführen (eine API für die Übertragung auf ein anderes Gerät erstellen)
- bequemes Debuggen
- viele Bibliotheken, auch für die Übertragung über das Netzwerk;
- Analysewerkzeuge - viel.
- und wenn es ein wenig schien, dann ist es möglich, Sishnoy-Bibliotheken zu verbinden
Zum Beispiel benutze ich:
- Sounddatei-Analyse
- HRTF,
- Training \ Gebäudeklassifikatoren.
Und wenn Sie dann den Code in eine Art Einbettung portieren / umschreiben müssen, ist es irgendwie einfacher, dies mit Java-Code zu tun.
Leider war das Beispiel der Autoren des Boards for Things etwas unwirksam, so dass ich mein Demo-Projekt gemacht habe (natürlich - ich kann).
Kurz gesagt, was ist da - all die schwarze Magie, Mikrofone schnell abzufragen, wir machen FFT in C ++ und Visualisierung, Analyse, Netzwerkinteraktion - in Java.
Zukünftige Entwicklungspläne
Quelle von Plänen und Inspiration zugleich: ODAS .
Also möchte ich das Gleiche tun, nur bei Dingen und ohne Störungen.
- Weil die Verwendung von ODAS etwas unpraktisch ist.
- Ich brauche ein normales Werkzeug, um zu arbeiten
- Weil ich dieses Thema kann und ich mag
- Verwendete Hardwaretools erfüllen die Komplexität der Aufgabe.
Meine Pläne basieren auf diesem (eigenen) Repository .
Und daran erinnern
"Wenn Sie etwas zu ergänzen oder zu kritisieren haben, zögern Sie nicht, in den Kommentaren darüber zu schreiben, denn ein Kopf ist schlechter als zwei, zwei sind schlechter als drei und n-1 ist schlechter als n" nikitasius