
Kürzlich hat uns ein Kunde gebeten, ein Abrechnungssystem für die Festplattenkapazität zu implementieren. Die Aufgabe bestand darin, Informationen von mehr als siebzig Festplatten-Arrays verschiedener Hersteller zu kombinieren, von SAN-Switches und VMware ESX-Hosts. Anschließend mussten die Daten systematisiert, analysiert und in einem Dashboard sowie in verschiedenen Berichten angezeigt werden, z. B. über das freie und belegte Speicherplatzvolumen in allen oder separat aufgenommenen Arrays.
Wir haben uns entschlossen, das Projekt mit dem Betriebsanalysesystem Splunk umzusetzen.
Warum splunk?
Splunk ist leistungsstark bei der Visualisierung der gesammelten Daten. Sie können interaktive Berichte - Dashboards - erstellen, die in Echtzeit aktualisiert werden. Wir haben Informationen zum gesamten Speicherplatz auf ihnen angezeigt und sofort alle Arrays mit der Möglichkeit angezeigt, nach verschiedenen Filtern zu sortieren, z. B. nach Kapazität. Durch Klicken auf das Array erhalten wir sofort Informationen zu allen Verbindungen. In einem separaten Bereich können Sie den Namen der virtuellen Maschine eingeben und sehen, auf welchem ESX-Host sie lebt, von welchen Arrays sie Daten und andere Parameter empfängt.
Meiner Meinung nach hat Splunk bisher keine Analoga, die mit jedem Speichersystem sofort funktionieren würden. Vor einigen Jahren erschien das kostenpflichtige CommandCentral, aber es verfügt nicht über die erforderliche Flexibilität, es weiß nicht, wie beliebige Berichte erstellt werden sollen (in den ersten Versionen der Berichte gab es überhaupt keine) und mit lahmer Visualisierung. Im Allgemeinen ist dies kein Werkzeug zur Bestandsaufnahme, sondern zur Überwachung und Steuerung des Systemstatus. Um die vom Kunden gestellte Aufgabe zu erfüllen, müsste sie lange und teuer verfeinert werden.
Gleichzeitig verfügt Splunk über beeindruckende Funktionen zur Informationsanzeige: Grafiken können frei untereinander angeordnet werden, überwachen den Status aller Systeme in einem einzigen Fenstermodus und vereinfachen so deren Wartung. Zu allem anderen - für unsere Aufgabe haben wir die kostenlose Version verwendet.

Was hast du gemacht
Bis zu diesem Zeitpunkt hatte unser Team keine Erfahrung mit Splunk. Glücklicherweise erwies sich das System als freundlich und intuitiv, und Lösungen für neu auftretende Probleme konnten mithilfe einer regelmäßigen Hilfe oder in einer Suchmaschine leicht gefunden werden.
Splunk hat eine Reihe von Tools entwickelt, die wir benötigen. Das System ermöglicht es Ihnen beispielsweise, Daten aus verschiedenen Quellen für jedes Feld über die sogenannten Lookups (Verzeichnisse) zu kombinieren. In einer Tabelle wurden ESX-Hosts als IP angezeigt, in einer anderen als DNS-Namen. Zuerst wollten wir eine hausgemachte Suche erstellen und das Dienstprogramm nslookup verwenden, um DNS-Einträge auszuwählen und Tabellen zu sammeln. Es stellte sich jedoch heraus, dass Splunk über ein Verzeichnis verfügt, das DNS über IP vergleicht und umgekehrt. Diese integrierte Suche muss nicht konfiguriert werden, sie extrahiert selbst Daten zu DNS-Servern aus den Systemeinstellungen und spielt keine Rolle, ob es sich um Windows oder Linux handelt. Die Daten in DNS-Einträgen sind immer aktuell.

Eines der interessanten Szenarien, die mit Splunk implementiert werden, ist die Änderungskontrolle (RFC) im System. Beispielsweise erhält ein RFC-Manager eine Anforderung von einem Techniker, einen der SAN-Switches zu warten. Er gibt den Switch-Namen in Splunk ein und sieht, welche Speicher damit verbunden sind und welche Server Daten von diesen Speichern empfangen. Gleichzeitig sieht der Manager den vom Techniker erstellten Arbeitsplan und kann bewerten, wie sich das Deaktivieren dieses Switches während der Wartung auf die Leistung von Arrays und Servern auswirkt.
Wir haben das tägliche Laden von Informationen zum Verbinden aller Switches und Arrays mit Splunk eingerichtet. Der Kunde ist mit dieser Aktualisierungsrate zufrieden. Er hatte bereits ein Überwachungstool Stor2RRD, weiß aber nicht, wie man Daten aus verschiedenen Quellen kombiniert und visualisiert. Daher haben wir das Datenerfassungssystem in Splunk wie folgt konfiguriert:
- Wir erhalten Informationen zu Speichern von Stor2RRD;
- Von Switches erhalten wir Informationen über SAN;
- Über vCenter mit PowerCLI-Skripten erfassen wir Daten von ESX-Hosts.
Die empfangenen Daten werden automatisch in ein einziges Formular gebracht, verarbeitet und in Form aller erforderlichen Berichte angezeigt.
Womit musstest du kämpfen?
Splunk ist ein leistungsstarkes System, aber es gibt Aufgaben, die nicht sofort gelöst werden können. Um einige Probleme zu lösen, benötigen wir fundierte Kenntnisse über VMware.
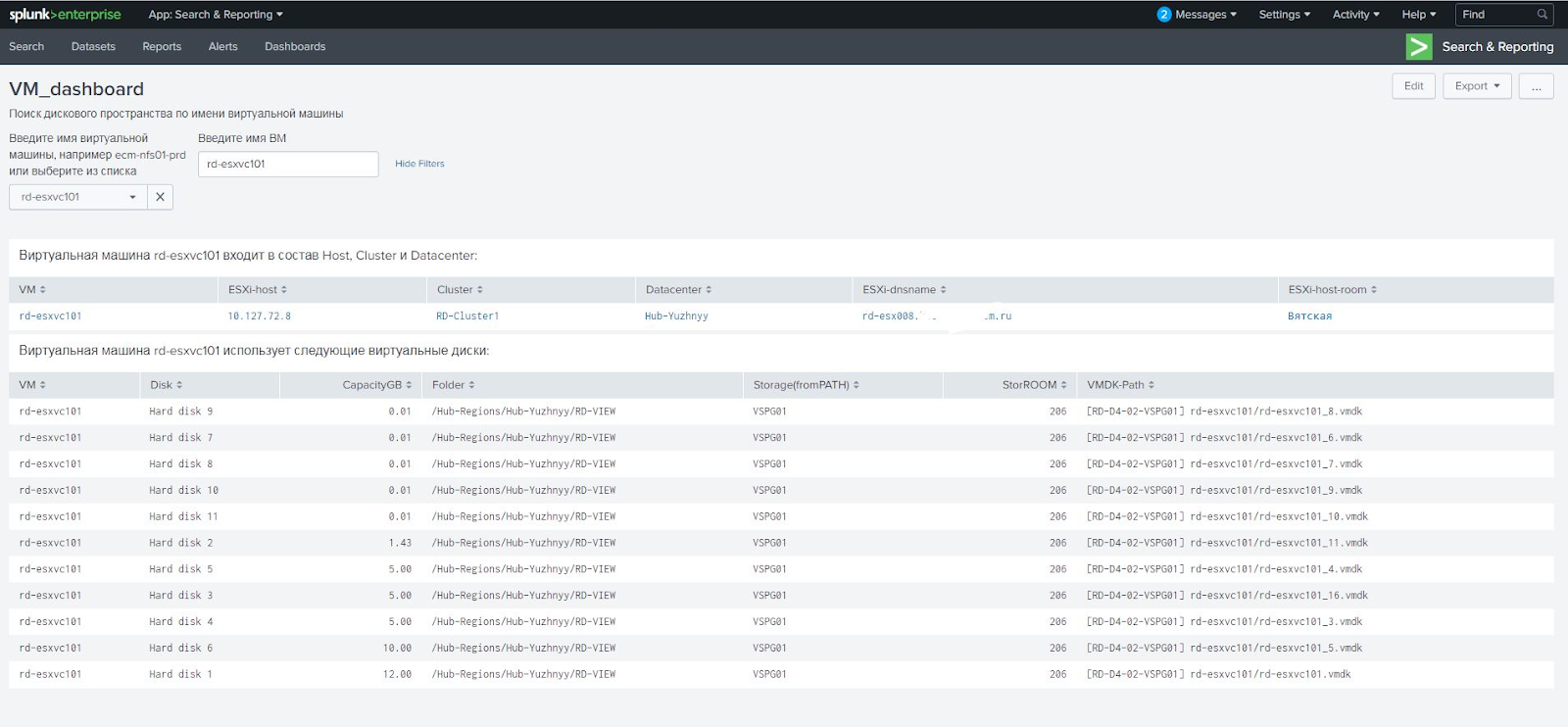
Beispielsweise verwendet ein Kunde sowohl direkt zugewiesene RDM-Festplatten als auch virtuelle virtuelle Datenspeicher für virtuelle Maschinen. Diese beiden Laufwerkstypen müssen unterschiedlich behandelt werden. Zuerst haben wir das Problem selbst gelöst, waren dann aber mit einer Situation konfrontiert, in der die virtuelle Maschine sowohl RAW-Festplatten als auch virtuelle Festplatten erhielt. Es stellte sich heraus, dass wir im Bericht das falsche Pfadfeld von vCenter und den falschen Link zum RAW-Festplattenarray erhalten haben. Das Schema funktioniert mit normalen Datenspeichern, jedoch nicht mit RAW-Festplatten. Für sie müssen Sie die RAW Disk ID-Festplatteneigenschaft verwenden, die das Festplattenattribut enthält. Ich musste mich an VMware-Experten wenden, die das Skript überarbeitet haben, damit es das richtige Array über die RAW-Festplatten-ID berechnet.
Außerdem haben wir nicht sofort gelernt, wie man optimal mit PowerCLI-Skripten arbeitet, später mussten die Algorithmen weiterentwickelt werden. Zunächst verarbeiteten die Skripte drei Stunden lang Daten von mehreren tausend virtuellen Maschinen! Nach der Verfeinerung wurde die Dauer der Skripte auf vierzig Minuten reduziert.
Was ist das Ergebnis?
Da wir keine Erfahrung mit Splunk haben, haben wir schnell ein System zur Abrechnung von Festplattenkapazitäten implementiert, das Informationen aus zahlreichen Quellen empfängt, konsolidiert und eine breite Palette an praktischen und intuitiven Grafiken bereitstellt. Wenn Sie zuvor noch kein solches System ausgewählt oder erstellt haben, ist Splunk ein guter Kandidat für diese Rolle. Es funktioniert schnell, ist einfach und flexibel zu konfigurieren und erfordert keine speziellen Kenntnisse, um die meisten Aufgaben zu lösen.
Vladislav Semenov, Leiter der System Architecture Group, Zentrum für das Entwerfen von Computerkomplexen, Jet Infosystems