 datacenterknowledge.com
datacenterknowledge.comIm vergangenen Jahr wurde die derzeit größte RAIDIX-basierte Speicherinstallation implementiert. Am RIKEN Institute of Computing Sciences (Japan) wurde ein System von 11 Failover-Clustern eingesetzt. Der Hauptzweck des Systems ist die Speicherung der HPC-Infrastruktur (HPCI), die im Rahmen des groß angelegten akademischen Austauschs akademischer Informationen in der Academic Cloud (basierend auf dem SINET-Netzwerk) implementiert wird.
Ein wesentliches Merkmal dieses Projekts ist sein Gesamtvolumen von 65 PB, von denen das nutzbare Volumen des Systems 51,4 PB beträgt. Um diesen Wert besser zu verstehen, fügen wir hinzu, dass es sich um 6512 Festplatten mit jeweils 10 TB handelt (die modernsten zum Zeitpunkt der Installation). Das ist viel.
Die Arbeiten an dem Projekt wurden das ganze Jahr über fortgesetzt. Danach wurde die Überwachung der Stabilität des Systems etwa ein Jahr lang fortgesetzt. Die erhaltenen Indikatoren erfüllten die angegebenen Anforderungen, und jetzt können wir über den Erfolg dieser Aufzeichnung und des für uns bedeutenden Projekts sprechen.
Supercomputer im Rechenzentrum des RIKEN-Instituts
Für die IKT-Branche ist das RIKEN-Institut vor allem für seinen legendären „K-Computer“ (vom japanischen „Kei“, was 10 Billiarden bedeutet) bekannt, der zum Zeitpunkt des Starts (Juni 2011) als der leistungsstärkste Supercomputer der Welt galt.
Lesen Sie mehr über den K-Computer Der Supercomputer unterstützt das Zentrum für Computerwissenschaften bei der Durchführung komplexer groß angelegter Studien: Er ermöglicht die Modellierung von Klima, Wetterbedingungen und molekularem Verhalten, die Berechnung und Analyse von Reaktionen in der Kernphysik, die Vorhersage von Erdbeben und vieles mehr. Supercomputerkapazitäten werden auch für mehr „alltägliche“ und angewandte Forschung verwendet - um nach Ölfeldern zu suchen und Trends an den Aktienmärkten vorherzusagen.
Solche Berechnungen und Experimente erzeugen eine große Datenmenge, deren Wert und Bedeutung nicht überschätzt werden kann. Um das Beste daraus zu machen, entwickelten japanische Wissenschaftler das Konzept eines einzigen Informationsraums, in dem HPC-Experten aus verschiedenen Forschungszentren Zugriff auf die erhaltenen HPC-Ressourcen haben.
Hochleistungsrechnerinfrastruktur (HPCI)
HPCI arbeitet auf der Basis von SINET (The Science Information Network), einem Backbone-Netzwerk für den Austausch wissenschaftlicher Daten zwischen japanischen Universitäten und Forschungszentren. Derzeit bringt SINET rund 850 Institute und Universitäten zusammen und bietet enorme Möglichkeiten für den Informationsaustausch in der Forschung, die sich auf Kernphysik, Astronomie, Geodäsie, Seismologie und Informatik auswirken.
HPCI ist ein einzigartiges Infrastrukturprojekt, das ein einheitliches Informationsaustauschsystem im Bereich Hochleistungsrechnen zwischen Universitäten und Forschungszentren in Japan bildet.
Durch die Kombination der Funktionen des Supercomputers „K“ und anderer Forschungszentren in zugänglicher Form erhält die wissenschaftliche Gemeinschaft offensichtliche Vorteile für die Arbeit mit wertvollen Daten, die durch Supercomputer-Computing erstellt wurden.
Um einen effektiven gemeinsamen Benutzerzugriff auf die HPCI-Umgebung zu ermöglichen, wurden hohe Anforderungen an den Speicher hinsichtlich der Zugriffsgeschwindigkeit gestellt. Und dank der "Hyperproduktivität" des K-Computers konnte der Speichercluster im Zentrum für Computerwissenschaften des RIKEN-Instituts mit einem Arbeitsvolumen von mindestens 50 PB erstellt werden.
Die HPCI-Projektinfrastruktur wurde auf dem Gfarm-Dateisystem aufgebaut, das ein hohes Leistungsniveau ermöglichte und unterschiedliche Speichercluster in einem einzigen gemeinsam genutzten Bereich kombinierte.
Gfarm-Dateisystem
Gfarm ist ein verteiltes Open Source-Dateisystem, das von japanischen Ingenieuren entwickelt wurde. Gfarm ist das Ergebnis der Entwicklung des Instituts für fortgeschrittene industrielle Wissenschaft und Technologie (AIST), und der Name des Systems bezieht sich auf die von Grid Data Farm verwendete Architektur.
Dieses Dateisystem kombiniert eine Reihe von scheinbar inkompatiblen Eigenschaften:
- Hohe Skalierbarkeit in Volumen und Leistung
- Fernnetzverteilung mit Unterstützung eines einzelnen Namespace für mehrere verschiedene Forschungszentren
- POSIX API-Unterstützung
- Hohe Leistung für paralleles Rechnen erforderlich
- Datenspeichersicherheit
Gfarm erstellt ein virtuelles Dateisystem unter Verwendung von Speicherressourcen von mehreren Servern. Daten werden vom Metadatenserver verteilt, und das Verteilungsschema selbst ist für Benutzer nicht sichtbar. Ich muss sagen, dass Gfarm nicht nur aus einem Speichercluster besteht, sondern auch aus einem Rechenraster, das die Ressourcen derselben Server verwendet. Das Funktionsprinzip des Systems ähnelt Hadoop: Die eingereichte Arbeit wird auf den Knoten „abgesenkt“, auf dem sich die Daten befinden.
Die Dateisystemarchitektur ist asymmetrisch. Die Rollen sind klar zugeordnet: Speicherserver, Metadatenserver, Client. Gleichzeitig können jedoch alle drei Rollen von derselben Maschine ausgeführt werden. Speicherserver speichern viele Kopien von Dateien, und Metadatenserver arbeiten im Master-Slave-Modus.
Projektarbeit
Core Micro Systems, ein strategischer Partner und exklusiver Lieferant von RAIDIX in Japan, implementierte die Implementierung im RIKEN Institute of Computing Sciences Center. Die Umsetzung des Projekts dauerte etwa 12 Monate, an denen nicht nur die Mitarbeiter von Core Micro Systems, sondern auch die technischen Spezialisten des Reydix-Teams aktiv teilnahmen.
Gleichzeitig schien der Übergang zu einem anderen Speichersystem unwahrscheinlich: Das bestehende System hatte viele technische Bindungen, die den Übergang zu einer neuen Marke erschwerten.
Bei langwierigen Tests, Überprüfungen und Verbesserungen hat RAIDIX bei der Arbeit mit einer derart beeindruckenden Datenmenge eine konstant hohe Leistung und Effizienz gezeigt.
Über die Verbesserungen lohnt es sich, etwas mehr zu erzählen. Es war nicht nur notwendig, die Integration von Speichersystemen in das Gfarm-Dateisystem zu erstellen, sondern auch einige funktionale Merkmale der Software zu erweitern. Um beispielsweise die festgelegten Anforderungen der technischen Spezifikationen zu erfüllen, musste die Technologie des automatischen Durchschreibens so schnell wie möglich entwickelt und implementiert werden.
Die Bereitstellung des Systems selbst erfolgte systematisch. Ingenieure von Core Micro Systems führten jede Testphase sorgfältig und genau durch und vergrößerten schrittweise den Maßstab des Systems.
Im August 2017 wurde die erste Bereitstellungsphase abgeschlossen, als das Systemvolumen 18 PB erreichte. Im Oktober desselben Jahres wurde die zweite Phase durchgeführt, in der das Volumen auf einen Rekordwert von 51 PB stieg.
Lösungsarchitektur
Die Lösung wurde durch die Integration von RAIDIX-Speichersystemen und dem verteilten Gfarm-Dateisystem erstellt. In Verbindung mit Gfarm die Möglichkeit, skalierbaren Speicher mit 11 RAIDIX-Systemen mit zwei Controllern zu erstellen.
Die Verbindung zu Gfarm-Servern erfolgt über 8 x SAS 12G.
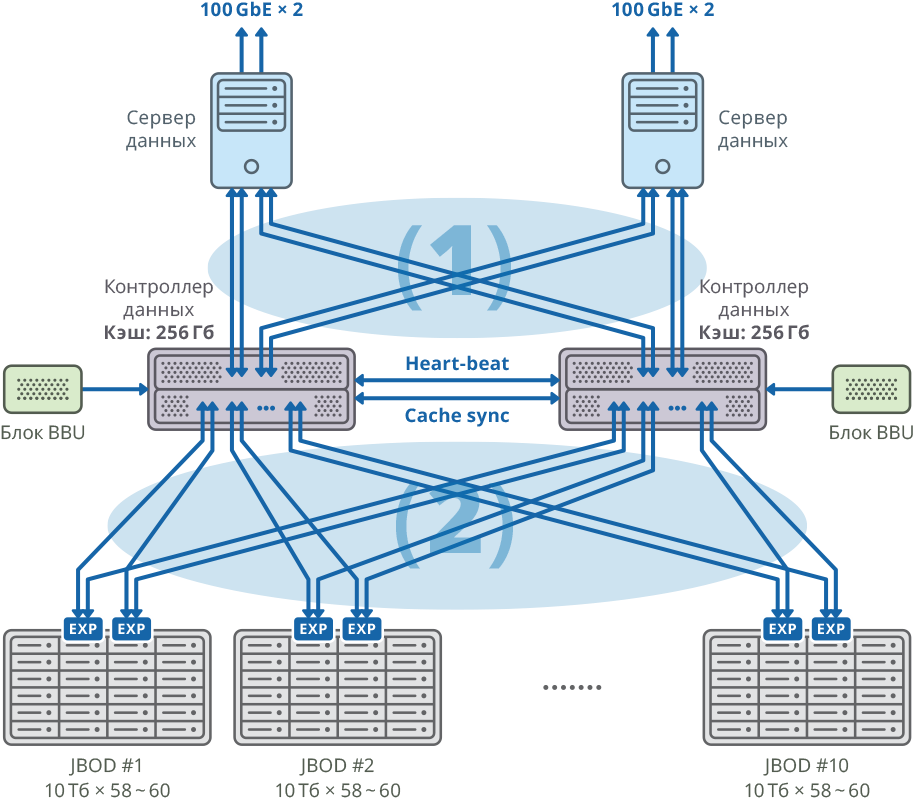 Abb. 1. Image eines Clusters mit einem separaten Datenserver für jeden Knoten
Abb. 1. Image eines Clusters mit einem separaten Datenserver für jeden Knoten(1) 48 Gbit / s × 8 SAN-Netzverbindungen; Bandbreite: 384 Gbit / s
(2) 48 Gbit / s × 40 Mesh FABRIC-Verbindungen; Bandbreite: 1920 Gbit / s
Konfiguration der Dual-Controller-Plattform
| CPU | Intel Xeon E5-2637 - 4 Stück |
| Hauptplatine | Kompatibel mit dem Prozessormodell, das PCI Express 3.0 x8 / x16 unterstützt |
| Interner Cache | 256 GB für jeden Knoten |
| Chassis | 2U |
| SAS-Controller zum Verbinden von Festplattenregalen, Servern und zur Synchronisierung des Schreibcaches | Broadcom 9305 16e, 9300 8e |
| Festplatte | HGST Helium 10 TB SAS-Festplatte |
| Herzschlag synchronisieren | Ethernet 1 GbE |
| CacheSync Sync | 6 x SAS 12G |
Beide Knoten des Failoverclusters sind über 20 SAS 12G-Ports für jeden Knoten mit 10 JBODs (60 Festplatten mit jeweils 10 TB) verbunden. Auf diesen Festplattenregalen wurden 58 10-TB-RAID6-Arrays erstellt (8 Datenfestplatten (D) + 2 Paritätsfestplatten (P)) und 12 Festplatten für den „Hot-Swap“ zugewiesen.
10 JBOD => 58 × RAID6 (8 Datenfestplatten (D) + 2 Paritätsfestplatten (P)), LUN von 580 HDD + 12 HDD für „Hot Swap“ (2,06% des Gesamtvolumens)
592 Festplatte (10 TB SAS / 7,2 KB Festplatte) pro Cluster * Festplatte: HGST (MTBF: 2 500 000 Stunden)
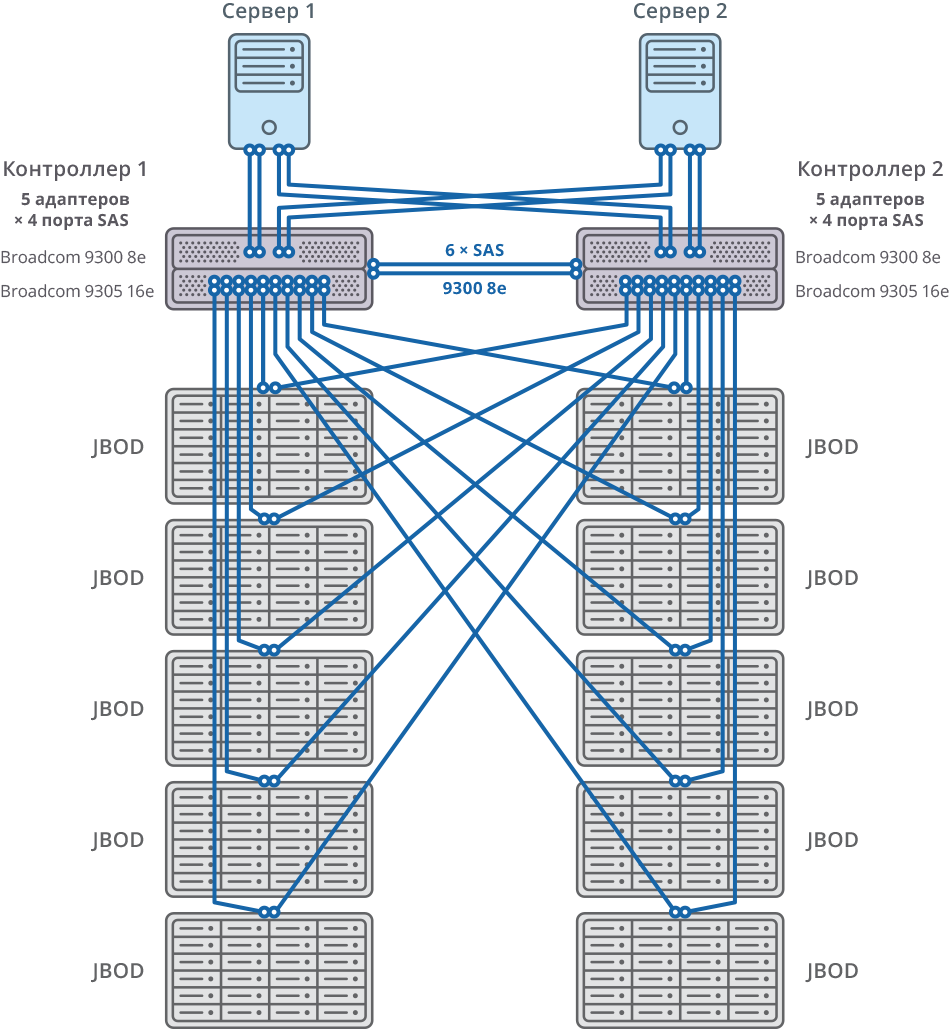 Abb. 2. Failover-Cluster mit 10 JBOD-Verbindungsdiagramm
Abb. 2. Failover-Cluster mit 10 JBOD-VerbindungsdiagrammAllgemeines System und Anschlussplan
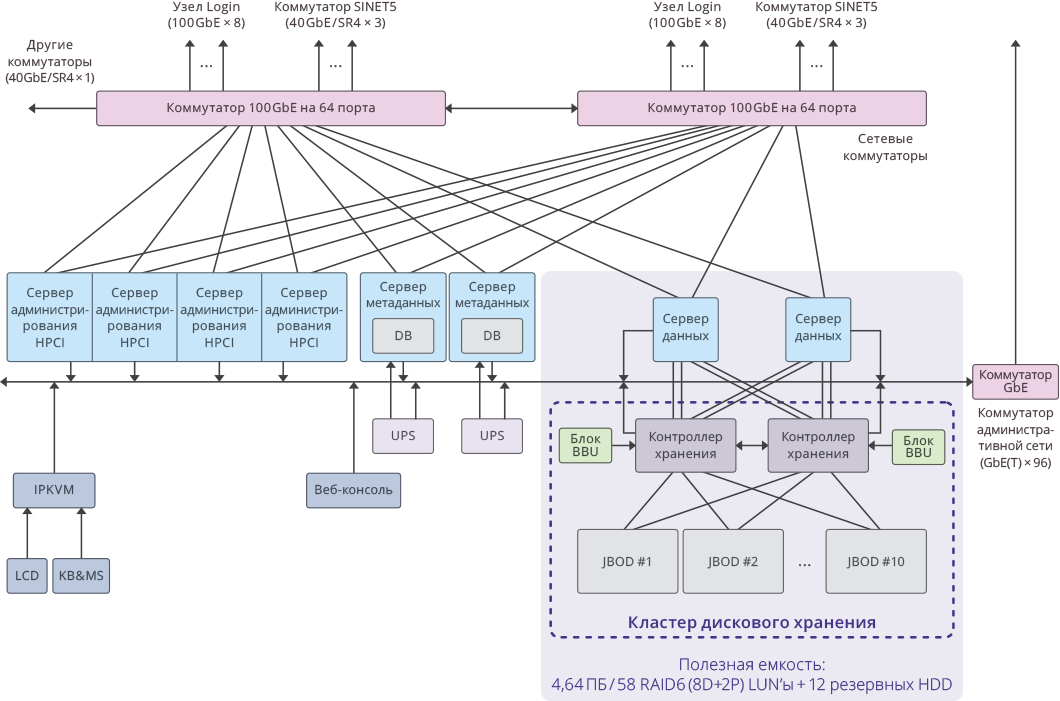 Abb. 3. Image eines einzelnen Clusters innerhalb des HPCI-Systems
Abb. 3. Image eines einzelnen Clusters innerhalb des HPCI-SystemsWichtige Projektindikatoren
Nutzbare Kapazität pro Cluster: 4,64 PB ((RAID6 / 8D + 2P) LUN × 58)
Die insgesamt nutzbare Kapazität des gesamten Systems: 51,04 PB (4,64 PB × 11 Cluster).
Gesamtsystemkapazität: 65 PB .
Die Systemleistung betrug: 17 GB / s zum Schreiben, 22 GB / s zum Lesen.
Die Gesamtleistung des Festplattensubsystems des Clusters auf 11 RAIDIX-Speichersystemen: 250 GB / s .