



Dieser Artikel beschreibt die interessantesten Konvertierungen, die eine Kette von zwei
Transpilern ausführt (der erste übersetzt Python-Code in Code in der
neuen Programmiersprache 11l und der zweite übersetzt Code in 11l in C ++) und vergleicht auch die Leistung mit anderen Beschleunigungswerkzeugen / Python-Code-Ausführung (PyPy, Cython, Nuitka).
Slices \ Slices durch Bereiche ersetzen
Die explizite Angabe für die Indizierung vom Ende des Arrays
s[(len)-2] anstelle von nur
s[-2] benötigt, um die folgenden Fehler zu beseitigen:
- Wenn es zum Beispiel erforderlich ist, das vorherige Zeichen mit
s[i-1] , aber für i = 0 wird ein solcher / dieser Datensatz anstelle eines Fehlers stillschweigend das letzte Zeichen der Zeichenfolge zurückgeben [ und in der Praxis ist ein solcher Fehler aufgetreten - Festschreiben ] . - Der Ausdruck
s[i:] nach i = s.find(":") funktioniert falsch, wenn das Zeichen nicht in der Zeichenfolge gefunden wird [ anstelle von '' Teil der Zeichenfolge ab dem ersten Zeichen : und dann '' wird das letzte Zeichen der Zeichenfolge verwendet ] (und im Allgemeinen Ich denke, dass die Rückgabe von -1 mit der Funktion find() in Python ebenfalls falsch ist [ sollte null / None zurückgeben [ und wenn -1 erforderlich ist, sollte dies explizit geschrieben werden: i = s.find(":") ?? -1 ] ] ) - Das Schreiben von
s[-n:] , um die letzten n Zeichen einer Zeichenfolge zu erhalten, funktioniert nicht richtig, wenn n = 0 ist.
Ketten von Vergleichsoperatoren
Auf den ersten Blick ist es ein herausragendes Merkmal der Python-Sprache, aber in der Praxis kann es leicht aufgegeben und auf die Bereiche verzichtet werden:
Listenverständnis
Wie sich herausstellte, können Sie eine weitere interessante Funktion des Python-Listenverständnisses ablehnen.
Während einige das
Listenverständnis verherrlichen und sogar vorschlagen, `filter ()` und` map () `aufzugeben , fand ich Folgendes:
An allen Stellen, an denen ich Pythons Listenverständnis gesehen habe, können Sie mit den Funktionen `filter ()` und` map () `problemlos auskommen. dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
`filter ()` und `map ()` in 11l sehen hübscher aus als in Python dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
und folglich verschwindet die Notwendigkeit des Listenverständnisses in 11l tatsächlich [das Ersetzen des Listenverständnisses durch filter() und / oder map() wird während der Konvertierung von Python-Code in 11l automatisch durchgeführt ] .
Konvertieren Sie die if-elif-else-Kette in einen Schalter
Während Python keine switch-Anweisung enthält, ist dies eines der schönsten Konstrukte in 11l, und deshalb habe ich beschlossen, switch automatisch einzufügen:
Der Vollständigkeit halber ist hier der generierte C ++ - Code switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
Konvertieren Sie kleine Wörterbücher in nativen Code
Betrachten Sie diese Zeile des Python-Codes:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
Höchstwahrscheinlich ist diese Form der Aufzeichnung
[ in Bezug auf die Leistung ] nicht sehr effektiv, aber sehr praktisch.
In 11l ist der Eintrag, der dieser Zeile entspricht
[ und vom Python-Transporter → 11l erhalten wird ], nicht nur praktisch
[ jedoch nicht so elegant wie in Python ] , sondern auch schnell:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
Die obige Zeile wird übersetzt in:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ Der Lambda-Funktionsaufruf wird vom C ++ - Compiler \ inline während des Optimierungsprozesses kompiliert und es bleibt nur die Operatorkette übrig ?/: ]]Wenn eine Variable zugewiesen wird, bleibt das Wörterbuch unverändert:
Externe Variablen erfassen \ erfassen
In Python wird das nichtlokale Schlüsselwort verwendet, um anzuzeigen, dass eine Variable nicht lokal ist, sondern außerhalb
[ der aktuellen Funktion ] verwendet werden soll.
Andernfalls wird beispielsweise found = True so behandelt, als würde eine neue gefundene lokale Variable erstellt, anstatt bereits einen Wert zuzuweisen vorhandene externe Variable ] .
In 11l wird das @ -Präfix dafür verwendet:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
Globale Variablen
Ähnlich wie bei externen Variablen tritt ein unsichtbarer Fehler auf, wenn Sie vergessen, eine globale Variable in Python
[ mit dem globalen Schlüsselwort ] zu deklarieren:
11l-Code
[ rechts ] break_label_index Gegensatz zu Python
[ links ] beim Kompilieren den Fehler 'nicht
break_label_index Variable
break_label_index '.
Index / Nummer des aktuellen Containerelements
Ich vergesse immer wieder die Reihenfolge der Variablen, die
enumerate Python-
enumerate zurückgibt (der Wert kommt zuerst, dann der Index oder umgekehrt). Das analoge Verhalten in Ruby -
each.with_index - ist viel einfacher zu merken: Mit index bedeutet, dass der Index nach dem Wert kommt, nicht vor dem Wert. In 11l ist die Logik jedoch noch einfacher zu merken:
Leistung
Das
Programm zum Konvertieren von PC-Markups in HTML wird als Testprogramm verwendet, und der Quellcode für den
Artikel über PC-Markups wird als Quelldaten verwendet
[ da dieser Artikel derzeit der größte der auf PC-Markups geschriebenen Artikel ist ] und 10-mal wiederholt erhalten von 48,8 Kilobyte Artikel Dateigröße 488Kb.
Hier ist ein Diagramm, das zeigt, wie oft die entsprechende Ausführung von Python-Code schneller ist als die ursprüngliche Implementierung
[ CPython ] :
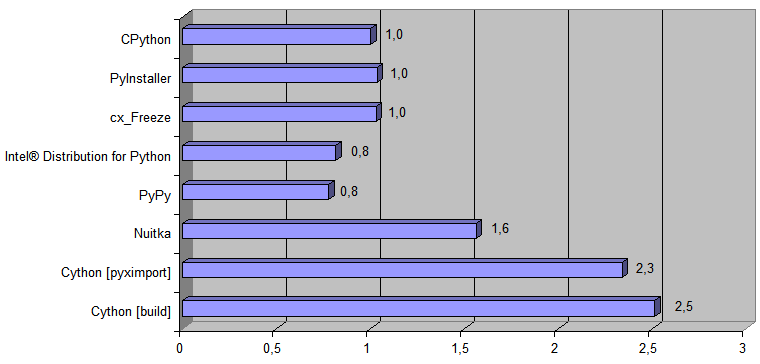
Fügen Sie nun dem Diagramm die vom Python → 11l → C ++ - Transpiler generierte Implementierung hinzu: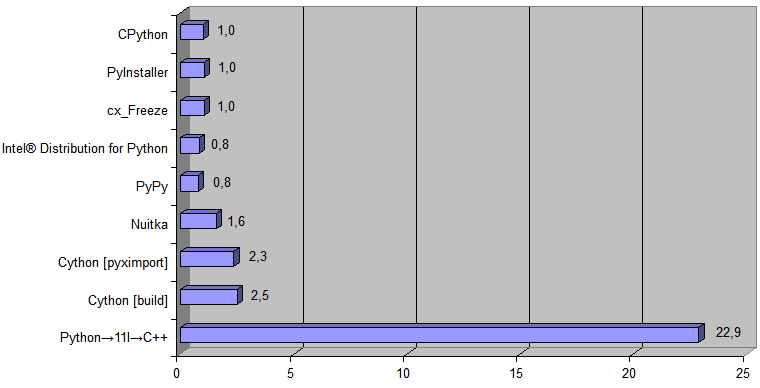
Die Laufzeit
[ 488 KB Dateikonvertierungszeit ] betrug 868 ms für CPython und 38 ms für den generierten C ++ - Code
[ diesmal einschließlich vollwertiger [ d.h. nicht nur mit Daten im RAM arbeiten ] das Programm vom Betriebssystem ausführen und alle Ein- / Ausgaben [ Lesen der Quelldatei [ .pq ] und Speichern der neuen Datei [ .html ] auf der Festplatte ] ] .
Ich wollte auch
Shed Skin ausprobieren, aber es unterstützt keine lokalen Funktionen.
Numba konnte ebenfalls nicht verwendet werden (es wird der Fehler 'Verwendung des unbekannten Opcodes LOAD_BUILD_CLASS' ausgegeben).
Hier ist das Archiv mit dem Programm zum Vergleichen der Leistung
[ unter Windows ] (erfordert Python 3.6 oder höher und die folgenden Python-Pakete: pywin32, cython).
Quellcode in Python und Ausgabe von Python-Transpilern -> 11l und 11l -> C ++: