Beispiele für die Rekonstruktion eines Videofragments, das von verschiedenen Codecs mit ungefähr demselben BPP-Wert (Bits pro Pixel) komprimiert wurde. Vergleichstestergebnisse siehe unter Kat.-Nr.Forscher von WaveOne
behaupten , einer Revolution in der Videokomprimierung nahe zu sein. Bei der Verarbeitung von hochauflösendem 1080p-Video komprimiert der
neue Codec für maschinelles Lernen Videos etwa 20% besser als die modernsten herkömmlichen Video-Codecs wie H.265 und VP9. In einem Video mit „Standard Definition“ (SD / VGA, 640 × 480) beträgt der Unterschied 60%.
Die Entwickler nennen die aktuellen Videokomprimierungsmethoden, die in H.265 und VP9 implementiert sind, nach den Standards moderner Technologien „uralt“: „In den letzten 20 Jahren haben sich die Grundlagen bestehender Videokomprimierungsalgorithmen nicht wesentlich geändert“, schreiben die Autoren des wissenschaftlichen Artikels in der Einleitung ihres Artikels. "Obwohl sie sehr gut gestaltet und sorgfältig abgestimmt sind, bleiben sie fest codiert und können sich als solche nicht an die wachsende Nachfrage und ein zunehmend vielseitiges Anwendungsspektrum für Videomaterial anpassen, einschließlich Austausch in sozialen Medien, Objekterkennung, Virtual-Reality-Streaming usw."
Der Einsatz von maschinellem Lernen sollte die Videokomprimierungstechnologie endlich ins 21. Jahrhundert bringen. Der neue Komprimierungsalgorithmus ist vorhandenen Video-Codecs deutlich überlegen. „Soweit wir wissen, ist dies die erste Methode des maschinellen Lernens, die ein solches Ergebnis gezeigt hat“, heißt es.
Die Hauptidee der Videokomprimierung besteht darin, redundante Daten zu entfernen und durch eine kürzere Beschreibung zu ersetzen, mit der Sie das Video später wiedergeben können. Die meisten Videokomprimierungen erfolgen in zwei Schritten.
Die erste Stufe ist die Bewegungskomprimierung, wenn der Codec nach sich bewegenden Objekten sucht und versucht, vorherzusagen, wo sie sich im nächsten Frame befinden werden. Anstatt die diesem sich bewegenden Objekt zugeordneten Pixel aufzuzeichnen, codiert der Algorithmus in jedem Bild nur die Form des Objekts zusammen mit der Bewegungsrichtung. In der Tat betrachten einige Algorithmen zukünftige Frames, um die Bewegung noch genauer zu bestimmen, obwohl dies bei Live-Übertragungen offensichtlich nicht funktioniert.
Der zweite Komprimierungsschritt entfernt andere Redundanzen zwischen einem Frame und dem nächsten. Anstatt die Farbe jedes Pixels am blauen Himmel aufzuzeichnen, kann der Komprimierungsalgorithmus den Bereich dieser Farbe bestimmen und anzeigen, dass sie sich in den nächsten paar Bildern nicht ändert. Somit bleiben diese Pixel dieselbe Farbe, bis sie aufgefordert werden, sich zu ändern. Dies wird als Restkomprimierung bezeichnet.
Der neue Ansatz, den Wissenschaftler eingeführt haben, nutzt erstmals maschinelles Lernen, um diese beiden Komprimierungsmethoden zu verbessern. Beim Komprimieren von Bewegungen fanden die maschinellen Lernmethoden des Teams neue Redundanzen basierend auf Bewegungen, die herkömmliche Codecs nie erkennen konnten, geschweige denn verwenden. Wenn Sie beispielsweise den Kopf einer Person von einer Frontalansicht in ein Profil verwandeln, erhalten Sie immer ein ähnliches Ergebnis: "Herkömmliche Codecs können das Profil einer Person nicht anhand einer Frontalansicht vorhersagen", schreiben die Autoren des wissenschaftlichen Artikels. Im Gegenteil, der neue Codec untersucht diese Arten von räumlich-zeitlichen Mustern und verwendet sie, um zukünftige Frames vorherzusagen.
Ein weiteres Problem ist die Zuweisung der verfügbaren Bandbreite zwischen Bewegung und Restkomprimierung. In einigen Szenen ist die Bewegungskomprimierung wichtiger, während in anderen die Restkomprimierung den größten Gewinn bietet. Der optimale Kompromiss zwischen ihnen ist von Bild zu Bild unterschiedlich.
Herkömmliche Algorithmen verarbeiten beide Prozesse getrennt voneinander. Dies bedeutet, dass es keine einfache Möglichkeit gibt, dem einen oder anderen einen Vorteil zu verschaffen und einen Kompromiss zu finden.
Die Autoren umgehen dies, indem sie beide Signale gleichzeitig komprimieren und basierend auf der Komplexität des Rahmens bestimmen, wie die Bandbreite zwischen den beiden Signalen am effizientesten verteilt werden soll.
Diese und andere Verbesserungen haben es Forschern ermöglicht, einen Komprimierungsalgorithmus zu erstellen, der herkömmliche Codecs weit übertrifft (siehe Benchmarks unten).
 Beispiele für die Rekonstruktion eines Fragments, das von verschiedenen Codecs mit ungefähr demselben BPP-Wert komprimiert wurde, zeigen einen signifikanten Vorteil des WaveOne-Codecs
Beispiele für die Rekonstruktion eines Fragments, das von verschiedenen Codecs mit ungefähr demselben BPP-Wert komprimiert wurde, zeigen einen signifikanten Vorteil des WaveOne-Codecs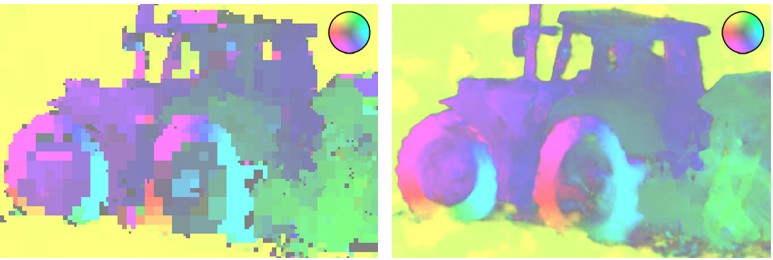 H.265 optische Stream-Karten (links) und WaveOne-Codec (rechts) mit derselben Bitrate
H.265 optische Stream-Karten (links) und WaveOne-Codec (rechts) mit derselben BitrateDer neue Ansatz ist jedoch nicht ohne Nachteile, so
der MIT Technology Review . Möglicherweise ist der Hauptnachteil die geringe Recheneffizienz, dh die Zeit, die zum Codieren und Decodieren des Videos erforderlich ist. Auf der Nvidia Tesla V100-Plattform und bei Videos im VGA-Format arbeitet der neue Decoder mit einer Durchschnittsgeschwindigkeit von etwa 10 Bildern pro Sekunde und der Encoder mit einer Geschwindigkeit von etwa 2 Bildern pro Sekunde. Solche Geschwindigkeiten können in Live-Videoübertragungen einfach nicht verwendet werden, und mit der Offline-Codierung von Materialien wird der neue Encoder einen sehr begrenzten Umfang haben.
Darüber hinaus reicht die Geschwindigkeit des Decoders nicht einmal aus,
um ein mit diesem Codec komprimiertes Video auf einem normalen Personal Computer
anzusehen . Das heißt, um diese Videos auch in minimaler SD-Qualität anzusehen, ist derzeit ein gesamter Computercluster mit mehreren Grafikbeschleunigern erforderlich. Und um Videos in HD-Qualität (1080p) anzusehen, benötigen Sie eine ganze Computerfarm.
Man kann nur hoffen, dass die Leistung von Grafikprozessoren in Zukunft gesteigert und die Technologie verbessert wird: "Die derzeitige Geschwindigkeit reicht nicht für die Bereitstellung in Echtzeit aus, sollte aber in zukünftigen Arbeiten erheblich verbessert werden", schreiben sie.
Benchmarks
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0,
-auto-alt-ref 0 -lag-in-frames 0 . MS-SSIM, ,
-ssim.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
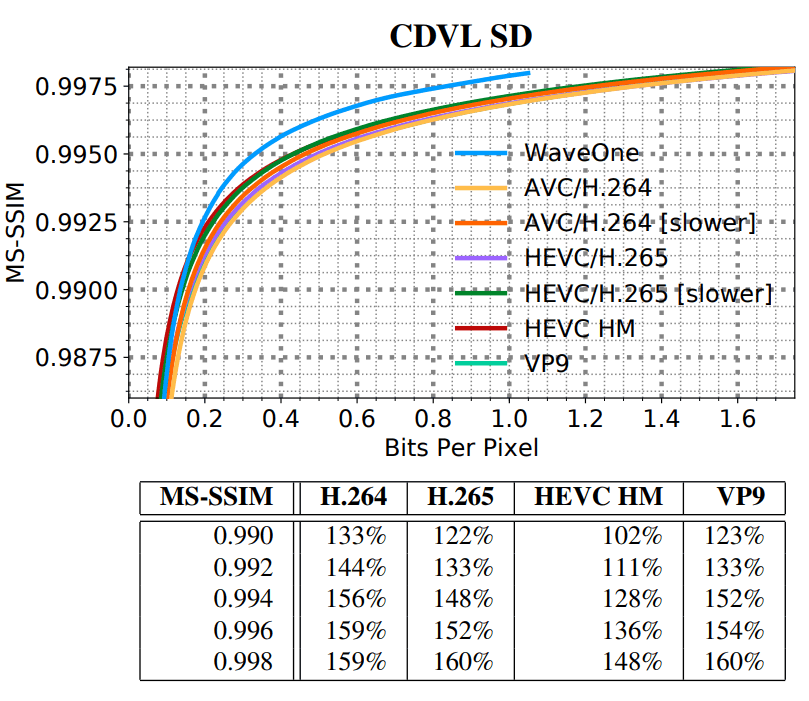 (SD)
(SD)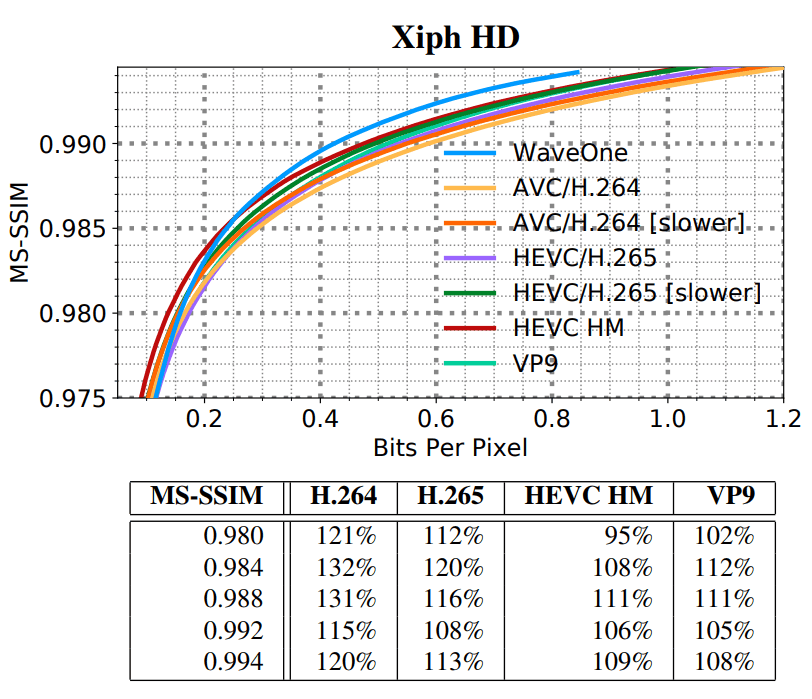 (HD)
(HD)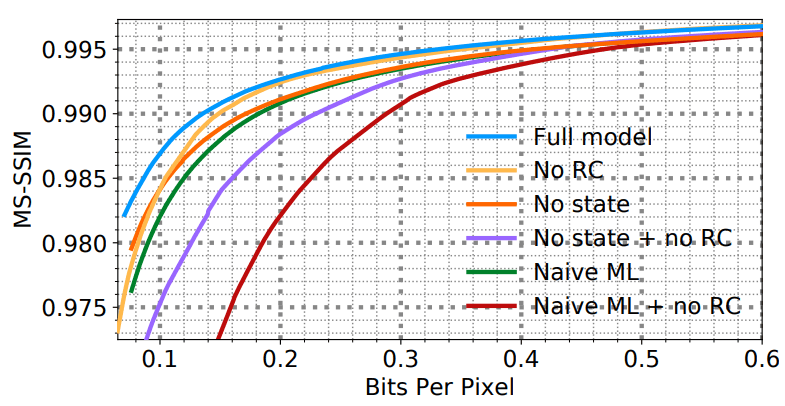 WaveOne
WaveOne. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar.
Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell.
Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli.
End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici.
Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl.
Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .