
Ein für uns typisches Systemintegrationsprojekt sieht folgendermaßen aus: Der Kunde verfügt über einen Systemtransport für Buchhaltungskunden. Die Aufgabe besteht darin, Kundenkarten in einer einzigen Datenbank zu sammeln. Und nicht nur zum Sammeln, sondern auch zum Entfernen von Duplikaten und Müll. Um saubere, strukturierte und vollständige Kundenkarten zu erhalten.
Für Anfänger werde ich erklären, dass die Migration nach diesem Schema verläuft:
Quellen → Datenkonvertierung ( ETL oder Bus antwortet) → Empfänger .
Bei einem Projekt haben wir drei Monate verloren, nur weil ein Drittanbieter-Team von Integratoren die Daten in den Quellsystemen nicht untersucht hat. Das nervigste war, dass dies hätte vermieden werden können.
Sie arbeiteten so:
- Systemintegratoren passen den ETL-Prozess an.
- ETL transformiert die Quelldaten und gibt sie mir.
- Ich studiere das Entladen und sende Fehler an Integratoren.
- Integratoren korrigieren ETLs und starten die Migration erneut.
In dem Artikel werde ich zeigen, wie Daten während der Systemintegration analysiert werden. Ich habe ETL-Uploads studiert, es war sehr nützlich. Bei den Quelldaten würden dieselben Techniken die Arbeit jedoch zweimal beschleunigen.
Tipps sind nützlich für Tester, Implementierer von Unternehmensprodukten, Systemintegratoren und Analysten. Empfänge sind universell für relationale Datenbanken und werden vollständig auf Volumina von einer Million Kunden offengelegt.
Aber zuerst über einen der Hauptmythen der Systemintegration.
Die Dokumentation und der Architekt helfen (eigentlich nicht)
Integratoren untersuchen Daten häufig nicht vor der Migration - sie sparen Zeit. Sie lesen die Dokumentation, schauen sich die Struktur an, sprechen mit dem Architekten - und das reicht. Danach planen sie bereits die Integration.
Es stellt sich als schlecht heraus. Nur eine Analyse zeigt, was wirklich in der Datenbank vor sich geht. Wenn Sie nicht mit hochgekrempelten Ärmeln und einer Lupe in die Daten gelangen, geht die Migration schief.
Die Dokumentation lügt. Ein typisches Unternehmenssystem läuft 5–20 Jahre. In all den Jahren wurden Änderungen von verschiedenen Abteilungen und Auftragnehmern dokumentiert. Jedes mit einem eigenen Glockenturm. Daher gibt es keine Integrität in der Dokumentation, niemand versteht die Logik und Struktur der Datenspeicherung vollständig. Ganz zu schweigen davon, dass die Fristen immer eingehalten werden und nicht genügend Zeit für die Dokumentation vorhanden ist.
Eine gemeinsame Geschichte: In der Kundentabelle befindet sich ein Feld „SNILS“, auf dem Papier ist es sehr wichtig. Aber wenn ich mir die Daten ansehe, sehe ich - das Feld ist leer. Infolgedessen stimmt der Kunde zu, dass die Zielbasis auf ein Feld für SNILS verzichten wird, da noch keine Daten vorhanden sind.
Ein Sonderfall der Dokumentation sind Vorschriften und Beschreibungen von Geschäftsprozessen: Wie gelangen die Daten unter welchen Umständen in welchem Format in die Datenbank? All dies wird auch nicht helfen.
Geschäftsprozesse sind nur auf dem Papier perfekt. Am frühen Morgen kommt der verschlafene Operator Anatoly in das Büro der Bank am Stadtrand von Vyksa. Unter dem Fenster schrien sie die ganze Nacht und am Morgen hatte Anatoly einen Streit mit dem Mädchen. Er hasst die ganze Welt.
Die Nerven sind noch nicht in Ordnung gebracht, und Anatoly treibt den Namen des neuen Kunden vollständig in das Feld für den Nachnamen. Er vergisst seinen Geburtstag völlig - der Standardwert „01.01.1900 g“ bleibt in der Form. Ich kümmere mich nicht um Vorschriften, wenn alles so wütend ist !!!
Chaos erobert Geschäftsprozesse, die auf dem Papier sehr gut proportioniert sind.
Ein Systemarchitekt weiß nicht alles. Es geht wieder um die ehrwürdige Lebensdauer von Unternehmenssystemen. Im Laufe der Jahre, in denen sie arbeiten, haben sich die Architekten verändert. Selbst wenn Sie mit dem aktuellen sprechen, werden die Entscheidungen der vorherigen während des Projekts als Überraschungen erscheinen.
Und seien Sie sicher: Selbst ein angenehmer Architekt wird in jeder Hinsicht seine Fälschung und Krücken des Systems geheim halten.
Die Integration "durch Instrumente" ohne Datenanalyse ist ein Fehler. Ich werde zeigen, wie wir bei HFLabs Daten durch Systemintegration lernen. Im letzten Projekt habe ich nur ETL-Uploads analysiert. Wenn der Kunde jedoch Zugriff auf die Quelldaten gewährt, überprüfe ich diese auf jeden Fall nach denselben Grundsätzen.
Gefüllte Felder und Nullwerte
Die einfachsten Überprüfungen betreffen die Vollständigkeit der Tabellen insgesamt und die Vollständigkeit einzelner Felder. Ich fange mit ihnen an.
Wie viele Zeilen insgesamt sind in der Tabelle. Die einfachste Anfrage möglich.
SELECT COUNT(*) FROM <table_name>;
Ich bekomme das erste Ergebnis.
Hier schaue ich auf die Angemessenheit der Daten. Wenn nur zwei Millionen Kunden für eine große Bank zum Entladen kamen, stimmt etwas eindeutig nicht. Aber während alles wie erwartet aussieht, geht es weiter.
Wie viele Zeilen werden für jedes Feld separat ausgefüllt? Ich überprüfe alle Spalten der Tabelle.
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
Der erste stieß auf ein Happy Birthday-Feld und war sofort neugierig: Aus irgendeinem Grund kamen die Daten überhaupt nicht.
Wenn alle Werte im Feld beim Upload "NULL" sind, sehe ich mir zuerst das Quellsystem an. Möglicherweise werden die Daten dort ordnungsgemäß gespeichert, sie gingen jedoch während der Migration verloren.
Ich sehe, dass im Quellsystem die Geburtstage vorhanden sind. Ich gehe zu den Integratoren: Leute, Fehler. Es stellte sich heraus, dass im ETL-Prozess die Dekodierungsfunktion nicht richtig funktionierte. Der Code wurde behoben, beim nächsten Upload werden wir die Änderungen überprüfen.
Ich gehe mit der TIN weiter zum Feld.
Die Datenbank enthält 100 Millionen Menschen, und nur 65.000 sind mit TINs gefüllt - das sind 0,07%. Eine solch schwache Belegung ist ein Signal dafür, dass das Feld in der Empfängerbasis möglicherweise überhaupt nicht notwendig ist.
Ich überprüfe das Quellsystem, alles ist korrekt: Die TIN ähnelt den tatsächlichen, aber es gibt fast keine. Es geht also nicht um Migration. Es bleibt abzuwarten, ob der Kunde ein fast leeres Feld unter der TIN in der Zieldatenbank benötigt.
Ich bin zum Client-Entfernungsflag gekommen.
Flaggen sind leer. Aber was, das Unternehmen entfernt keine Kunden? Ich schaue auf das Quellsystem und spreche mit dem Kunden. Es stellt sich heraus, dass ja: Die Flagge ist formal, anstatt Kunden zu löschen, werden ihre Konten gelöscht. Keine Konten - als ob der Client gelöscht worden wäre.
Im Zielsystem ist das Remote-Client-Flag erforderlich. Dies ist ein Merkmal der Architektur. Wenn der Client also keine Konten im Empfängersystem hat, muss er durch zusätzliche Logik geschlossen oder überhaupt nicht importiert werden. Dann, wie der Kunde entscheidet.
Als nächstes ist das Adressschild. Normalerweise stimmt etwas mit solchen Tabellen nicht, da Adressen eine komplizierte Sache sind und auf unterschiedliche Weise eingegeben werden.
Ich überprüfe die Vollständigkeit der Komponenten der Adresse.
Die Adressen sind nicht einheitlich ausgefüllt, aber es ist noch zu früh, um Schlussfolgerungen zu ziehen: Zuerst frage ich den Kunden, wofür sie bestimmt sind. Wenn für die Segmentierung nach Ländern alles in Ordnung ist: Es gibt genügend Daten. Wenn für Mailinglisten, dann ist das Problem: Die Häuser sind fast leer, es gibt keine Wohnungen.
Infolgedessen stellte der Kunde fest, dass die ETL Adressen von einem alten und irrelevanten Tablet abnahm. Sie ist in der Basis wie ein Denkmal. Aber es gibt noch eine andere Tabelle, neu und gut, die Daten müssen daraus entnommen werden.
Während der Analyse fülle ich die Felder, die mit Verzeichnissen verknüpft sind, besonders aus. Die Bedingung "IST NICHT NULL" funktioniert bei ihnen nicht: Anstelle von "NULL" ist die Zelle normalerweise "0". Überprüfen Sie daher die Referenzfelder separat.
Änderungen beim Ausfüllen von Feldern. Also habe ich die Gesamtbelegung und die Belegung jedes Feldes überprüft. Gefundene Probleme, Integratoren haben den ETL-Prozess behoben und die Migration erneut gestartet.
Ich führe das zweite Entladen für alle oben aufgeführten Schritte aus. Ich schreibe Statistiken in dieselbe Datei, um die Änderungen zu sehen.
Vollständigkeit aller Bereiche.
Zwischen den Uploads sind 5 Millionen Datensätze verschwunden. Ich gehe zu den Integratoren und stelle typische Fragen:
- "Warum gingen die Aufzeichnungen verloren?";
- "Welche Daten wurden herausgefiltert?";
- "Welche Daten haben Sie hinterlassen?"
Es stellt sich heraus, dass es kein Problem gibt: Sie haben einfach die „technischen“ Kunden aus dem neuen Entladen entfernt. Sie sind in der Datenbank für Tests, sie sind keine lebenden Menschen. Bei gleicher Wahrscheinlichkeit können die Daten jedoch versehentlich verloren gehen.
Aber die Geburtstage beim neuen Entladen erschienen, wie ich erwartet hatte.
Aber! Nicht unbedingt gut, wenn zuvor fehlende Daten plötzlich in einem neuen Upload angezeigt wurden. Zum Beispiel könnten Geburtstage mit Standarddaten gefüllt sein - es gibt nichts, worüber man sich freuen könnte. Deshalb überprüfe ich immer, welche Daten gekommen sind.
Was zu überprüfen, auf den Punkt gebracht.
- Die Gesamtzahl der Einträge in den Tabellen. Entspricht diese Menge den Erwartungen?
- Die Anzahl der ausgefüllten Zeilen in jedem Feld.
- Das Verhältnis der Anzahl der gefüllten Zeilen in jedem Feld zur Anzahl der Zeilen in der Tabelle. Wenn es zu klein ist, ist dies eine Gelegenheit, darüber nachzudenken, ob das Feld auf die Zielbasis gezogen werden soll.
Wiederholen Sie die ersten drei Schritte für jeden Upload. Folgen Sie der Dynamik: Wo und warum hat sie zugenommen oder abgenommen.Länge der Werte in Zeichenfolgenfeldern
Ich folge einer der Grundregeln des Testens - ich überprüfe die Grenzwerte.
Welche Werte sind zu kurz. Zu den kürzesten Werten gehört Junk, daher ist es interessant, hier zu graben.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
Auf diese Weise überprüfe ich den Namen, die Telefonnummer, die TIN, OKVED und die Website-Adressen. Unsinn erscheint wie "A * 1", "0", "11", "-" und "...".
Ist alles in Ordnung mit Maximalwerten. Das Nahfeld ist ein Hinweis darauf, dass die Daten während der Übertragung nicht passten und automatisch abgeschnitten wurden. MySQL knackt dies berühmt ohne Vorwarnung. Gleichzeitig scheint die Migration reibungslos verlaufen zu sein.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
Auf diese Weise fand ich im Feld mit der Art des Dokuments die Zeile "Bescheinigung über die Registrierung des Antrags des Einwanderers auf Anerkennung von ihm". Sie sagte den Integratoren, die Feldlänge sei korrigiert worden.
Wie die Werte über die Länge verteilt sind. In HFLabs rufen wir die Längenverteilungstabelle für die Zeilen auf.
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
Hier suche ich nach Anomalien in der Verteilung entlang der Länge. Hier ist beispielsweise eine Häufigkeit für eine Tabelle mit Postanschriften.
Werte mit einer Länge von 125 sind zu viele. Ich schaue in die Quellendatenbank und stelle fest, dass einige der Adressen vor drei Jahren aus irgendeinem Grund auf 125 Zeichen gekürzt wurden. In anderen Jahren ist alles in Ordnung. Ich gehe mit diesem Problem zum Kunden und zu den Integratoren, wir verstehen.
Was zu überprüfen, auf den Punkt gebracht.
- Die kürzesten Werte in Zeichenfolgenfeldern. Oft sind Zeilen mit weniger als drei Zeichen Müll.
- Werte, die entlang der Länge der Feldbreite „anliegen“. Oft werden sie beschnitten.
- Anomalien in der Verteilung der Zeilen entlang der Länge.
Beliebte Werte
Ich teile die Werte, die zu den beliebtesten gehören, in drei Kategorien ein:
- sehr häufig , wie der Name "Tatyana" oder der zweite Vorname "Vladimirovich". Hier muss daran erinnert werden, dass Tatyana im allgemeinen Fall nicht 100-mal populärer sein sollte als Anna, und Ismail kann kaum populärer sein als Egor;
- Müll , wie ".", "1", "-" und dergleichen;
- Standard auf dem Eingabeformular, als "01/01/1900" für Daten.
Zwei von drei Fällen sind Marker für das Problem. Es ist nützlich, nach ihnen zu suchen.
Ich suche nach beliebten Werten in drei Arten von Feldern:
- Gewöhnliche Zeichenfolgenfelder.
- Referenzzeichenfolgenfelder. Dies sind gewöhnliche Zeichenfolgenfelder, aber die Anzahl der verschiedenen Werte in ihnen ist natürlich geregelt. In diesen Feldern werden Länder, Städte, Monate und Telefontypen gespeichert.
- Klassifiziererfelder - Sie enthalten einen Link zu einem Eintrag in einer Klassifizierertabelle eines Drittanbieters.
Ich studiere die Felder jedes dieser Typen etwas anders.
Für Zeichenfolgenfelder - Was sind die 100 beliebtesten Werte? Wenn Sie möchten, können Sie mehr nehmen, aber in den ersten hundert Werten werden normalerweise alle Anomalien platziert.
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
Ich überprüfe die Felder folgendermaßen:
- Vollständiger Name sowie separate Nachnamen, Vornamen und Patronymien;
- Geburtsdaten und im Allgemeinen alle Daten;
- Adressen Sowohl die vollständige Adresse als auch die einzelnen Komponenten, sofern diese in der Datenbank gespeichert sind;
- Telefone
- Serie, Nummer, Art, Ausstellungsort der Dokumente.
Fast immer unter den populären - Test- und Standardwerten, einige Stubs.

Es kommt vor, dass das gefundene Problem überhaupt kein Problem ist. Einmal fand ich eine verdächtig beliebte Telefonnummer in der Datenbank. Es stellte sich heraus, dass die Kunden diese Nummer als funktionierend angaben und sich einfach viele Mitarbeiter in derselben Datenbank befanden.
Auf dem Weg dorthin zeigt eine solche Analyse versteckte Referenzfelder. Logischerweise sollen diese Felder keine Verzeichnisse sein, sondern befinden sich tatsächlich in der Datenbank. Zum Beispiel wähle ich beliebte Werte aus dem Feld "Position" aus, und es gibt nur fünf davon.
Vielleicht dient das Unternehmen nur fünf Berufen. Nicht sehr wahr, oder? Vielmehr haben sie im Formular für die Operatoren anstelle einer Zeile ein Verzeichnis erstellt und vergessen, Werte auszugeben. Die wichtige Frage hier ist: Ist es sinnvoll, Beiträge überhaupt über das Verzeichnis auszufüllen? Durch die Datenanalyse gehe ich auf mögliche Probleme mit der Bedienersoftware ein.
Für Referenzfelder und Klassifikatoren überprüfe ich die Beliebtheit aller Werte. Zunächst finde ich heraus, welche Felder Verzeichnisse sind. Mit Skripten kommt man nicht zurecht, ich nehme die Dokumentation und gebe vor, es zu sein. In der Regel werden Verzeichnisse für Werte erstellt, deren Anzahl natürlich und relativ gering ist:
- Länder
- Sprachen
- Währungen
- Monate
- die Stadt.
In einer idealen Welt ist der Inhalt von Referenzfeldern klar und konsistent. Aber unsere Welt ist nicht so, also überprüfe ich mit einer Anfrage.
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
Normalerweise liegt dies in Zeichenfolgenfeldern von Verzeichnissen.
Häufige Probleme:
- Tippfehler;
- Räume
- anderer Fall.
Nachdem ich ein Durcheinander gefunden habe, gehe ich mit Beispielen zu den Integratoren. Lassen Sie sie Müll in der Quelle lassen und beseitigen Sie die Unstimmigkeiten. Dann ist es in der Zieldatenbank möglich, die Referenzlinien in Klassifikatoren umzuwandeln.
Ich überprüfe die gängigen Werte in den Klassifikatorfeldern, um den Mangel an Optionen festzustellen. Angesichts solcher Fälle.
Solche Klassifikatoren sehen sehr seltsam aus, sie sollten dem Kunden gezeigt werden. Jedes Mal, wenn ich einen Fehler hinter solchen Fällen hatte: Entweder stimmt etwas in der Datenbank nicht oder die Daten wurden von der falschen Stelle heruntergeladen.
Was zu überprüfen, auf den Punkt gebracht.
- Welche Zeichenfolgenfelder sind Referenz und welche nicht.
- Bei einfachen Zeichenfolgenfeldern die beliebtesten Werte. Normalerweise im oberen Müll und Standarddaten.
- Bei Zeichenfolgenreferenzfeldern die Verteilung aller Werte nach Beliebtheit. Die Auswahl zeigt Abweichungen in den Referenzwerten.
- Für Klassifizierer - gibt es genügend Optionen in der Datenbank.
Konsistenz und gegenseitige Versöhnung
Von der Analyse der Daten in Tabellen wende ich mich der Analyse der Beziehungen zu.
Gibt an, ob Daten miteinander verknüpft sein müssen. Wir nennen diesen Parameter "Konsistenz". Ich nehme den untergeordneten Tisch zum Beispiel mit Telefonen. Dazu in einem Paar - die übergeordnete Tabelle der Kunden. Und ich sehe, wie viele Clients in der untergeordneten Tabelle Bezeichner sind, die nicht im übergeordneten Element enthalten sind.
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
Wenn die Anfrage ein Delta ergab, bedeutet dies kein Glück - der Upload enthält nicht verwandte Daten. Also überprüfe ich die Tische mit Telefonen, Verträgen, Adressen, Rechnungen und so weiter. Einmal fand sie während eines Projekts 23 Millionen Nummern, die einfach in der Luft hingen.
Es funktioniert auch in die entgegengesetzte Richtung - ich suche Kunden, die aus irgendeinem Grund keinen einzigen Vertrag, keine einzige Adresse und keine einzige Telefonnummer haben. Manchmal ist es in Ordnung - der Kunde hat keine Adresse. Hier müssen Sie vom Kunden erfahren, dass die Dokumentation leicht täuscht.
Gibt es Duplikate von Primärschlüsseln in verschiedenen Tabellen? Manchmal werden identische Entitäten in verschiedenen Tabellen gespeichert. Zum Beispiel heterosexuelle Kunden. (Niemand weiß warum, weil Breschnew immer noch die Struktur beansprucht.) Die Tabelle ist jedoch im Empfänger einzeln, und bei der Migration treten Client-IDs in Konflikt.
Ich drehe meinen Kopf um und betrachte die Struktur der Basis: wo eine Fragmentierung ähnlicher Entitäten möglich ist. Dies können Kundentabellen, Kontakttelefone, Pässe usw. sein.
Wenn es mehrere Tabellen mit ähnlichen Entitäten gibt, mache ich eine Gegenprüfung: Ich überprüfe den Schnittpunkt von Bezeichnern. Schneiden - Kleben Sie einen Patch. Zum Beispiel sammeln wir Bezeichner für eine einzelne Tabelle gemäß dem Schema „Name der Quelltabelle + ID“.
Was zu überprüfen, auf den Punkt gebracht.
- Wie viele nicht verwandte Daten befinden sich in verknüpften Tabellen?
- Gibt es potenzielle Primärschlüsselkonflikte?
Was noch zu überprüfen
Gibt es lateinische Zeichen, zu denen sie nicht gehören? Zum Beispiel in Nachnamen.
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
Also fange ich den wunderbaren lateinischen Buchstaben "C", der mit dem Kyrillischen übereinstimmt. Der Fehler ist unangenehm, da der Bediener laut dem Namen mit dem lateinischen "C" niemals einen Kunden finden wird.
Gibt es in den Zeichenfolgenfeldern, die für Zahlen vorgesehen sind, überflüssige Zeichen? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
In den Feldern treten Probleme mit der Passnummer der Russischen Föderation oder der TIN auf. Telefone sind die gleichen, aber dort erlaube ich Plus, Klammern und Bindestriche. Die Anfrage zeigt auch den Buchstaben "O", der anstelle von Null gesetzt wurde.
Wie angemessen sind die Daten? Sie wissen nie, wo das Problem auftauchen wird, deshalb bin ich immer auf der Hut. Ich habe solche Fälle getroffen:
- Ist „Sofya Vladimirovna“ ein Kunde mit 50.000 Telefonen - ist das normal? Antwort: nicht normal. Der Kunde ist technisch versiert, er gibt ihm "inhaberlose" Telefonnummern, um SMS-Mailings zu machen. Es ist nicht erforderlich, den Client auf eine neue Basis zu ziehen.
- TINs sind gefüllt, tatsächlich enthält die Spalte "79853617764", "89109462345", "4956780966" und so weiter. Was für Telefone, okuda? Wo ist das Gasthaus? Antwort: Welche Art von Zahlen - es ist nicht bekannt, wer sie ausdrückt - ist unklar. Niemand benutzt sie. Die aktuelle TIN wird in einem anderen Feld einer anderen Tabelle gespeichert und von dort übernommen.
- Das Feld „Adresse in einer Zeile“ entspricht nicht den Feldern, in denen die Adresse in Teilen gespeichert ist. Warum sind die Adressen unterschiedlich? Antwort: Sobald die Bediener die Adressen mit einer Zeile gefüllt haben und das externe System die Adressen in separate Felder sortiert hat. Zur Segmentierung. Im Laufe der Zeit änderten die Leute ihre Adressen. Die Betreiber haben sie regelmäßig aktualisiert, jedoch nur als Zeichenfolge: Die Adresse blieb teilweise alt.
Sie benötigen lediglich SQL und Excel
Für die Analyse von Daten wird keine teure Software benötigt. Genug gutes altes Excel und SQL-Kenntnisse.
Excel Ich verwende, um eine lange Abfrage zu kompilieren. Zum Beispiel überprüfe ich die Felder auf Vollständigkeit und es gibt 140 in der Tabelle. Ich werde mit meinen Händen vor der Karottenverschwörung schreiben, also sammle ich die Anfrage mit den Formeln in der Excel-Platte.
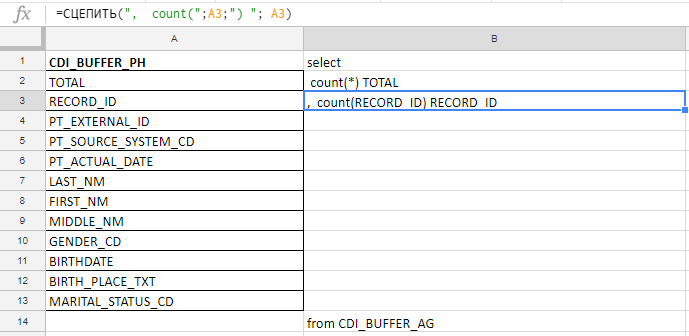 In der Spalte "A" füge ich die Namen der Felder ein, ich nehme sie in die Dokumentation oder Servicetabellen. In Spalte "B" - eine Formel zum Kleben einer Anfrage
In der Spalte "A" füge ich die Namen der Felder ein, ich nehme sie in die Dokumentation oder Servicetabellen. In Spalte "B" - eine Formel zum Kleben einer AnfrageIch füge die Namen der Felder ein, schreibe die erste Formel in Spalte "B", ziehe an der Ecke - und fertig.
 Funktioniert in Excel, in Google Text & Tabellen und in Excel Online (verfügbar auf Yandex.Disk)
Funktioniert in Excel, in Google Text & Tabellen und in Excel Online (verfügbar auf Yandex.Disk)Die Datenanalyse spart dem Auto Zeit und die Nerven der Manager. Damit ist es einfacher, die Frist einzuhalten. Wenn das Projekt groß ist, spart die Analyse Millionen Rubel und einen guten Ruf.
Keine Zahlen, sondern Schlussfolgerungen
Sie formulierte eine Regel für sich selbst: Wenn Sie dem Kunden keine bloßen Zahlen zeigen möchten, erhalten Sie immer noch nicht den Effekt. Meine Aufgabe ist es, die Daten zu analysieren, Schlussfolgerungen zu ziehen und die Zahlen als Beweismittel beizufügen. Schlussfolgerungen sind primär, Zahlen sind sekundär.
Was ich für den Bericht sammle:
- der Wortlaut der Probleme in Form einer Hypothese oder Frage : „Die TIN ist zu 0,07% gefüllt. Wie verwenden Sie diese Daten, wie relevant sind sie, wie sind sie zu interpretieren? Gibt es nur eine INN in einer Tabelle? " Sie können nicht beschuldigen: "Ihre TIN ist überhaupt nicht gefüllt." Als Antwort erhalten Sie nur Aggression;
- Beispiele für Probleme. Dies sind die Tabletten, die so viele in dem Artikel sind;
- Optionen für die Vorgehensweise : "Es könnte sich lohnen, die TIN von der Zielbasis zu entfernen, um keine leeren Felder zu erzeugen."
Ich habe kein Recht zu entscheiden, was genau aus der Quellendatenbank ausgewählt und wie Daten während der Migration geändert werden sollen. Daher gehe ich mit dem Bericht zum Kunden oder zu den Integratoren, und wir finden heraus, wie wir vorgehen sollen.
Manchmal antwortet der Kunde, wenn er das Problem sieht: „Mach dir keine Sorgen, pass nicht auf. Wir werden ein zusätzliches Terabyte Speicher kaufen, das ist alles. Es ist billiger als zu optimieren. " Sie können dem nicht zustimmen: Wenn Sie alles hintereinander nehmen, hat der Empfänger keine Qualität. Dieselben müllredundanten Daten werden migriert.
Deshalb fragen wir sanft, aber stetig: "Sagen Sie uns, wie Sie diese bestimmten Daten im Zielsystem verwenden werden." Nicht "warum Sie brauchen", sondern "wie Sie verwenden werden". Die Antworten "Dann kommen wir auf" oder "Nur für den Fall" sind nicht geeignet. Früher oder später versteht der Kunde, auf welche Daten verzichtet werden kann.
Die Hauptsache ist, alle Probleme zu finden und zu lösen, bis das System in prod gestartet wird. Wenn Sie die Architektur und das Datenmodell lebendig ändern, verlieren Sie den Verstand.
Das ist alles mit grundlegenden Überprüfungen, studieren Sie die Daten!