Über Montezumas Revenge-Spiel auf Habré wurde nicht so viel geschrieben. Dies ist ein komplexes klassisches Spiel, das früher sehr beliebt war, aber jetzt wird es entweder von denen gespielt, mit denen es nostalgische Gefühle hervorruft, oder von Forschern, die KI entwickeln.
In diesem Sommer wurde
berichtet, dass DeepMind seiner KI beibringen konnte, wie man Spiele für Atari spielt, einschließlich Montezumas Rache. Am Beispiel desselben Spiels haben die Entwickler von OpenAI auch ihre Entwicklung
gelehrt . Jetzt hat Uber ein ähnliches Projekt aufgenommen.
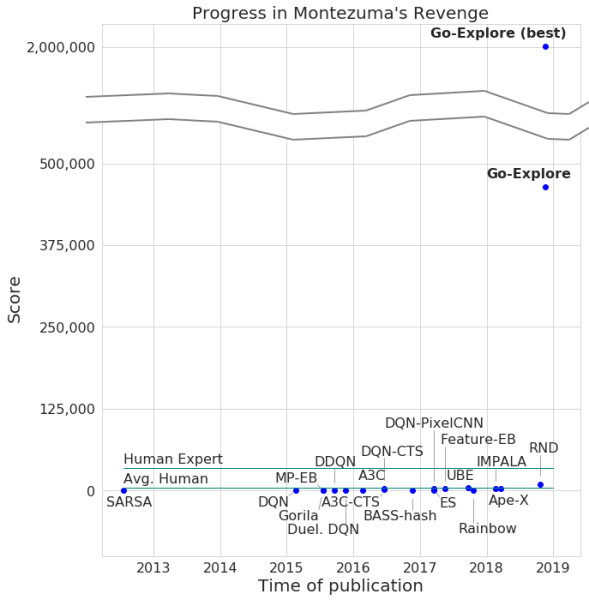
Die Entwickler kündigten die Weitergabe des Spiels durch ihr neuronales Netzwerk mit einer maximalen Anzahl von 2 Millionen Punkten an. Zwar verdiente das System im Durchschnitt nicht mehr als 400.000 pro Versuch. Für die Passage erreichte der Computer Level 159.
Darüber hinaus lernte Go-Explore, wie man durch Pitfall geht, mit einem hervorragenden Ergebnis, das dem durchschnittlichen Spieler überlegen ist, ganz zu schweigen von anderen KI-Agenten. Die Anzahl der von Go-Explore in diesem Spiel erzielten Punkte beträgt 21.000.
Der Unterschied zwischen Go-Explore und seinen „Kollegen“ besteht darin, dass neuronale Netze nicht nachweisen müssen, dass sie unterschiedliche Ebenen für das Training bestehen. Das System lernt während des Spiels alles selbst und zeigt Ergebnisse, die viel höher sind als die von neuronalen Netzen, die visuelles Training erfordern. Laut den Entwicklern von Go-Explore unterscheidet sich die Technologie erheblich von allen anderen und ihre Funktionen ermöglichen die Verwendung eines neuronalen Netzwerks in einer Reihe von Bereichen, einschließlich der Robotik.
Die meisten Algorithmen finden es schwierig, mit Montezumas Rache umzugehen, da das Spiel kein sehr explizites Feedback hat. Zum Beispiel kämpft ein neuronales Netzwerk, das „geschärft“ ist, um beim Passieren eines Levels Belohnungen zu erhalten, eher gegen den Feind als auf eine Leiter zu springen, die zum Ausgang führt und es Ihnen ermöglicht, schneller vorwärts zu kommen. Andere KI-Systeme ziehen es vor, hier und jetzt eine Belohnung zu erhalten und nicht in der "Hoffnung" auf mehr voranzukommen.
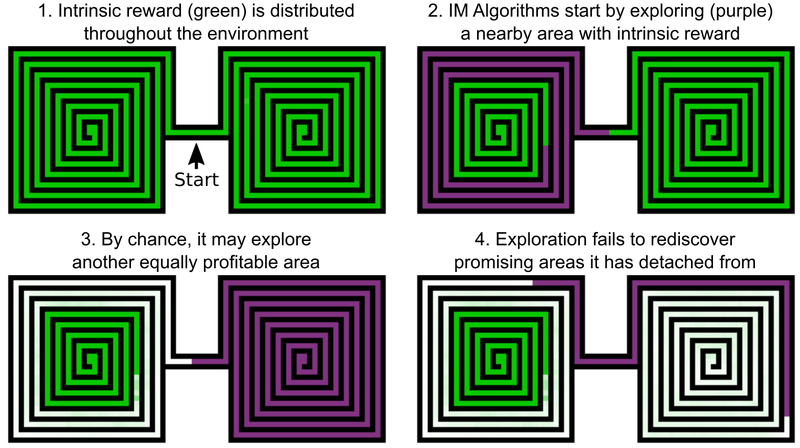
Eine der Entscheidungen der Uber-Ingenieure ist es, Boni für die Erkundung der Spielwelt hinzuzufügen. Dies kann als interne Motivation der KI bezeichnet werden. Aber selbst KI-Elemente mit zusätzlicher intrinsischer Motivation passen nicht gut zu Montezumas Revenge and Pitfall. Das Problem ist, dass die KI vielversprechende Orte nach dem Passieren "vergisst". Infolgedessen bleibt der KI-Agent auf einer Ebene stecken, auf der anscheinend alles untersucht wurde.
Ein Beispiel ist der KI-Agent, der zwei Labyrinthe untersuchen muss - Ost und West. Er beginnt einen von ihnen zu durchlaufen, entscheidet dann aber plötzlich, dass es möglich sein würde, den zweiten zu durchlaufen. Der erste bleibt bei 50% untersucht, der zweite bei 100%. Und der Agent kehrt nicht zum ersten Labyrinth zurück - einfach weil er „vergessen“ hat, dass er nicht bis zum Ende fertig ist. Und da der Durchgang zwischen dem östlichen und dem westlichen Labyrinth bereits untersucht wurde, hat die KI keine Motivation, zurückzukehren.
Die Lösung für dieses Problem umfasst laut Entwicklern von Uber zwei Phasen: Forschung und Verstärkung. Was den ersten Teil betrifft, erstellt die KI hier ein Archiv verschiedener Spielzustände - Zellen (Zellen) - und verschiedener Trajektorien, die zu ihnen führen. AI wählt die Möglichkeit, die maximale Anzahl von Punkten zu erhalten, wenn die optimale Flugbahn ermittelt wird.
Zellen sind vereinfachte Spielbilder - 11 x 8 Bilder in Graustufen mit einer Intensität von 8 Pixeln, wobei sich die Bilder ausreichend unterscheiden -, um den weiteren Spielverlauf nicht zu behindern.

Infolgedessen erinnert sich AI an vielversprechende Orte und kehrt zu ihnen zurück, nachdem sie andere Teile der Spielwelt untersucht hat. Der „Wunsch“, die Spielwelt und die vielversprechenden Orte bei Go-Explore zu erkunden, ist stärker als der Wunsch, hier und jetzt eine Auszeichnung zu erhalten. Go-Explore verwendet auch Informationen zu den Zellen, in denen der KI-Agent geschult ist. Für Montezumas Rache sind es Pixeldaten wie ihre X- und Y-Koordinaten, der aktuelle Raum und die Anzahl der gefundenen Schlüssel.
Die Verstärkungsstufe schützt vor „Rauschen“. Wenn KI-Lösungen gegenüber „Rauschen“ instabil sind, verstärkt KI sie mithilfe eines mehrstufigen neuronalen Netzwerks, das am Beispiel menschlicher Gehirnneuronen arbeitet.

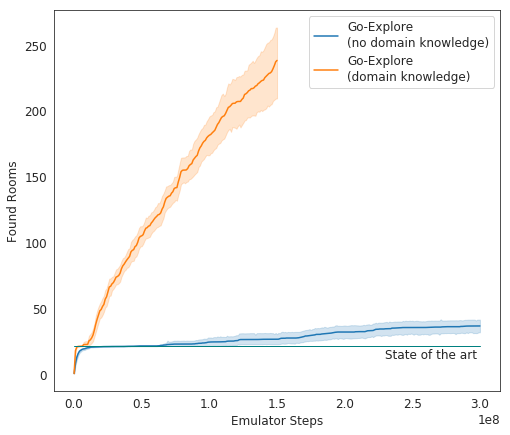
In Tests schneidet Go-Explore sehr gut ab - im Durchschnitt untersucht AI 37 Räume und löst 65% der Rätsel der ersten Stufe. Dies ist viel besser als frühere Versuche, das Spiel zu erobern - dann studierte AI durchschnittlich 22 Räume des ersten Levels.

Beim Hinzufügen von Gain zum vorhandenen Algorithmus begann die KI, durchschnittlich 29 Level (keine Räume) mit einer durchschnittlichen Punktzahl von 469,209 erfolgreich abzuschließen.
Die endgültige Inkarnation von Ubers KI begann das Spiel viel besser als andere KI-Agenten und besser als Menschen zu führen. Jetzt verbessern Entwickler ihr System so, dass es ein noch beeindruckenderes Ergebnis zeigt.