Am 8. November wurde in der Haupthalle der
HighLoad ++ 2018- Konferenz im Rahmen des Abschnitts DevOps and Operations ein Bericht mit dem Titel Databases and Kubernetes erstellt. Es geht um die hohe Verfügbarkeit von Datenbanken und Ansätze zur Fehlertoleranz gegenüber Kubernetes und damit sowie um praktische Optionen für die Platzierung von DBMS in Kubernetes-Clustern und bestehende Lösungen dafür (einschließlich Stolon für PostgreSQL).

Aus Tradition freuen wir uns, ein
Video mit einem Bericht (ungefähr eine Stunde,
viel informativer
als der Artikel) und dem Hauptdruck in Textform zu präsentieren. Lass uns gehen!
Theorie
Dieser Bericht erschien als Antwort auf eine der beliebtesten Fragen, die uns in den letzten Jahren unermüdlich an verschiedenen Orten gestellt wurden: Kommentare im Hub oder auf YouTube, in sozialen Netzwerken usw. Es klingt einfach: "Ist es möglich, die Datenbank in Kubernetes auszuführen?", Und wenn wir normalerweise mit "allgemein ja, aber ..." geantwortet haben, gab es eindeutig nicht genug Erklärungen für diese "allgemein" und "aber", sondern um sie anzupassen in einer kurzen Nachricht nicht erfolgreich.
Für den Anfang fasse ich das Problem jedoch von der "Datenbank [Daten]" bis zum Stateful als Ganzes zusammen. Ein DBMS ist nur ein Sonderfall von zustandsbehafteten Entscheidungen, von denen eine vollständigere Liste wie folgt dargestellt werden kann:
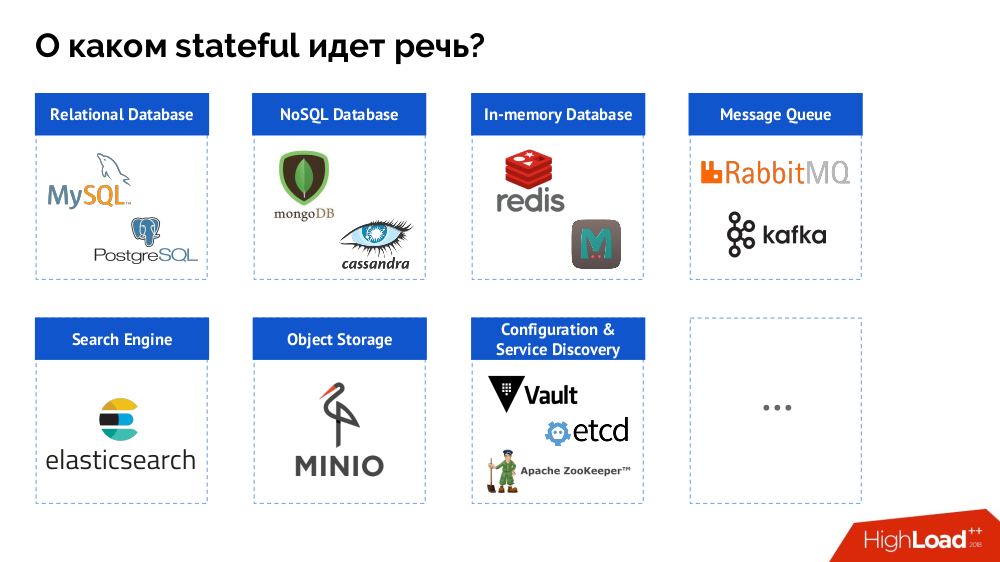
Bevor ich mich mit bestimmten Fällen befasse, werde ich auf drei wichtige Merkmale der Arbeit / Verwendung von Kubernetes eingehen.
1. Kubernetes Hochverfügbarkeitsphilosophie
Jeder kennt die Analogie „Haustiere
gegen Rinder “ und versteht, dass klassische DBMS nur Haustiere sind, wenn Kubernetes eine Geschichte aus der Herdenwelt ist.
Und wie sah die Architektur der „Haustiere“ in der „traditionellen“ Version aus? Ein klassisches Beispiel für die Installation von MySQL ist die Replikation auf zwei Iron-Servern mit redundanter Stromversorgung, Festplatte, Netzwerk ... und allem anderen (einschließlich eines Ingenieurs und verschiedener Hilfstools), um sicherzustellen, dass der MySQL-Prozess nicht fehlschlägt und wenn ein Problem mit einem der kritischen Probleme auftritt Für seine Komponenten wird die Fehlertoleranz eingehalten:
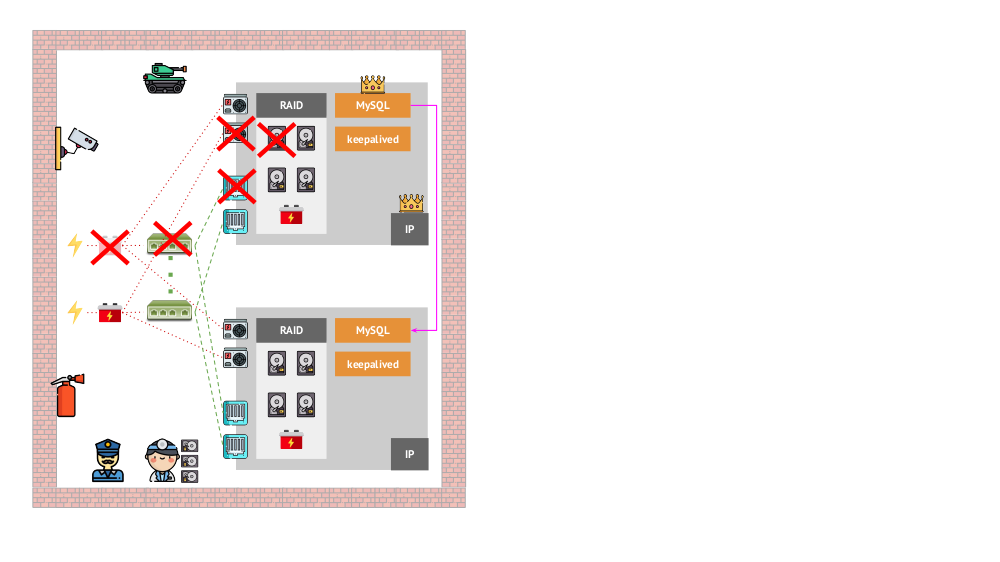
Wie wird das gleiche in Kubernetes aussehen? Hier gibt es normalerweise viel mehr Eisenserver, sie sind einfacher und sie haben keine redundante Stromversorgung und kein redundantes Netzwerk (in dem Sinne, dass der Verlust einer Maschine nichts beeinflusst) - all dies wird zu einem Cluster zusammengefasst. Die Fehlertoleranz wird von der Software bereitgestellt: Wenn dem Knoten etwas passiert, erkennt Kubernetes die erforderlichen Instanzen auf dem anderen Knoten und startet sie.
Was sind die Mechanismen für eine hohe Verfügbarkeit in K8?
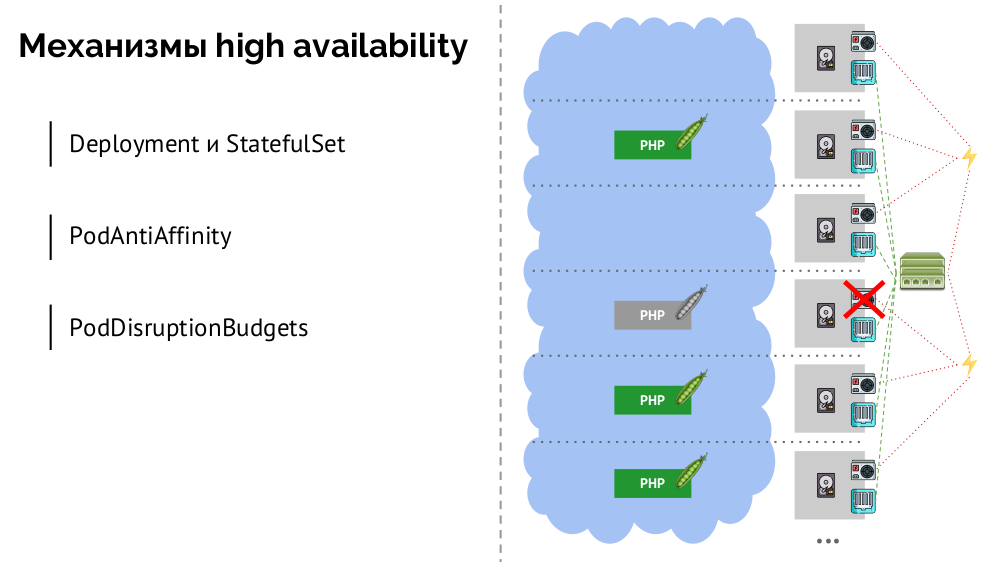
- Controller Es gibt viele, aber zwei Hauptprobleme:
Deployment (für zustandslose Anwendungen) und StatefulSet (für zustandsbehaftete Anwendungen). Sie speichern die gesamte Logik der Aktionen, die im Falle eines Knotenabsturzes ausgeführt werden (Pod-Unzugänglichkeit). PodAntiAffinity - Die Möglichkeit, bestimmte Pods so anzugeben, dass sie sich nicht auf demselben Knoten befinden.PodDisruptionBudgets - PodDisruptionBudgets die Anzahl der Pod-Instanzen, die bei geplanten Arbeiten gleichzeitig PodDisruptionBudgets können.
2. Kubernetes Konsistenzgarantien
Wie funktioniert das bekannte Single-Master-Fehlertoleranzschema? Zwei Server (Master und Standby), auf die ständig von der Anwendung zugegriffen wird, die wiederum über den Load Balancer verwendet wird. Was passiert bei einem Netzwerkproblem?
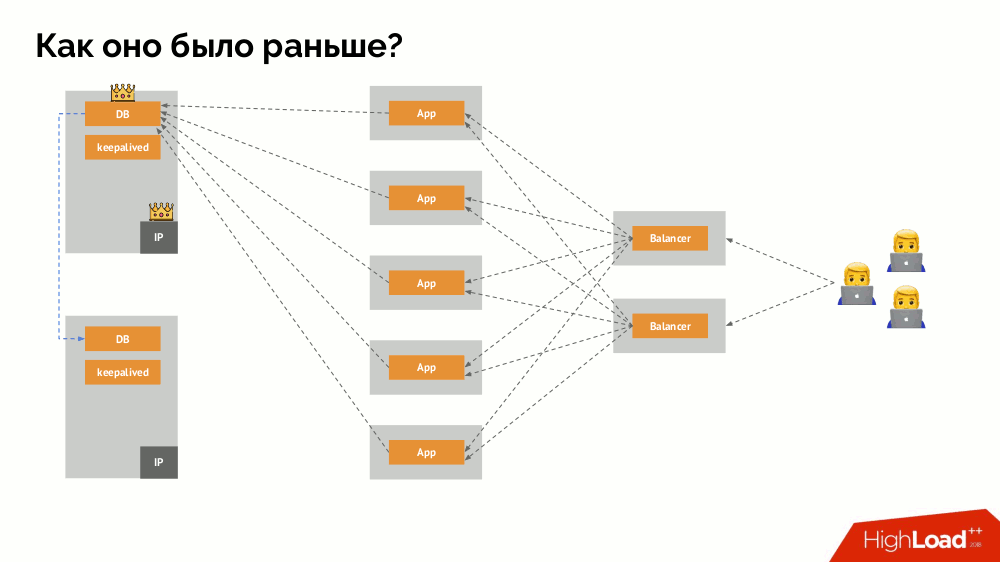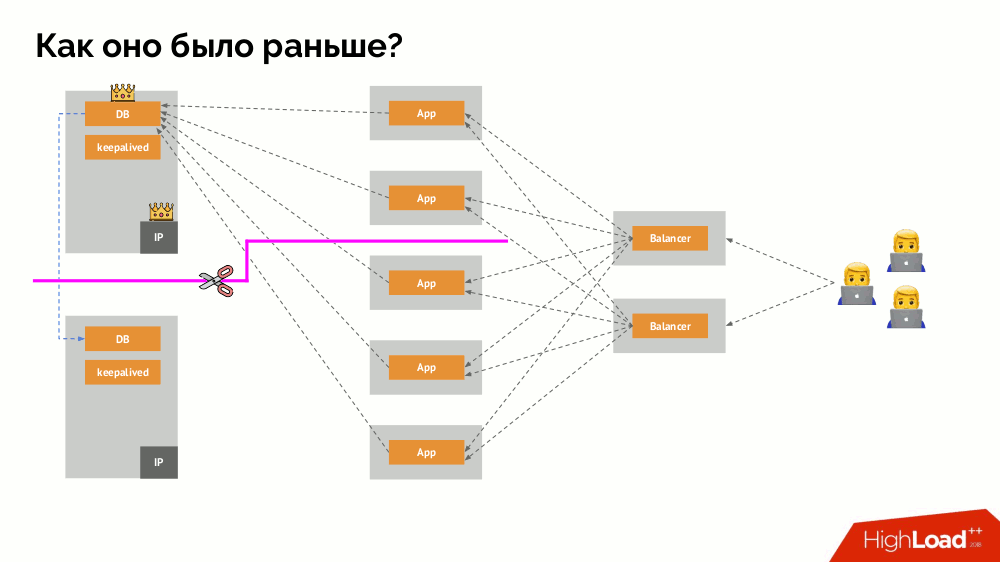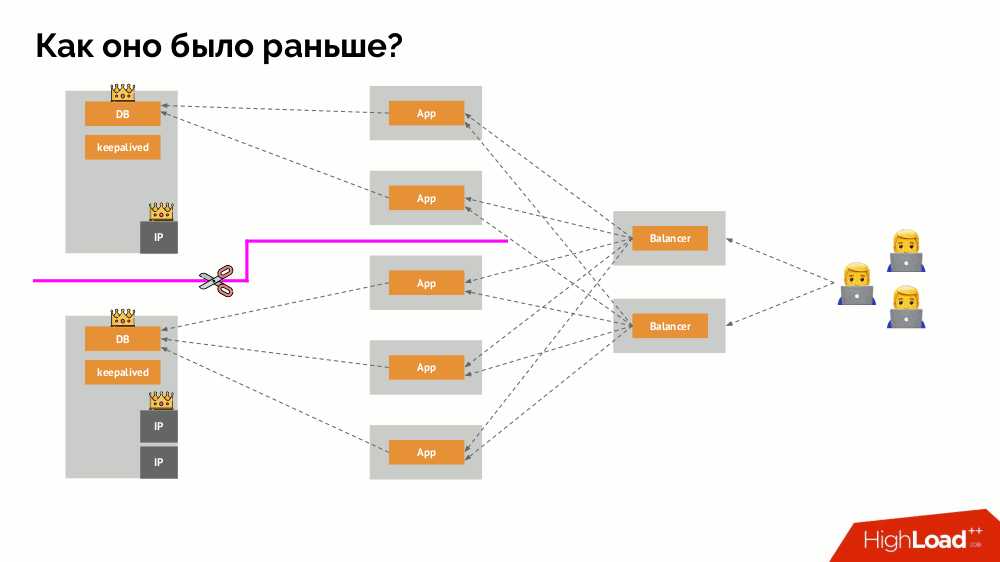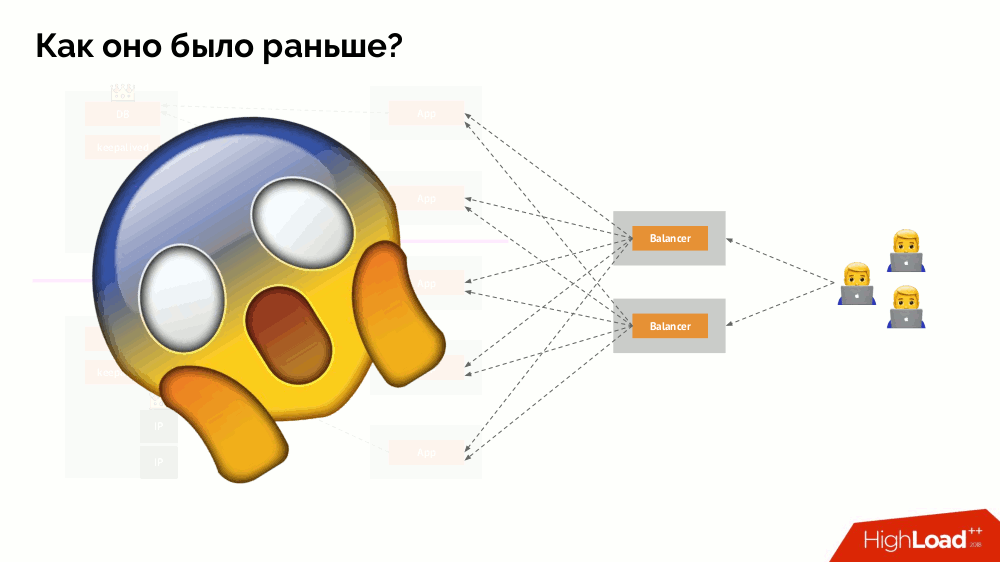
Klassisches
Split-Brain : Die Anwendung beginnt mit dem Zugriff auf beide DBMS-Instanzen, von denen sich jede als die Hauptinstanz betrachtet. Um dies zu vermeiden, wurde keepalived durch corosync mit bereits drei Instanzen ersetzt, um bei der Abstimmung für den Master ein Quorum zu erreichen. Selbst in diesem Fall gibt es jedoch Probleme: Wenn eine heruntergefallene DBMS-Instanz versucht, sich auf jede mögliche Weise "umzubringen" (IP-Adresse entfernen, Datenbank in schreibgeschützt übersetzen ...), weiß der andere Teil des Clusters nicht, was mit dem Master passiert ist - es kann passieren, dass dieser Knoten tatsächlich noch funktioniert und Anforderungen an ihn gelangen, was bedeutet, dass wir den Assistenten immer noch nicht wechseln können.
Um diese Situation zu lösen, gibt es einen Mechanismus zum Isolieren des Knotens, um den gesamten Cluster vor fehlerhaften Vorgängen zu schützen. Dieser Vorgang wird als
Fencing bezeichnet . Die praktische Essenz läuft darauf hinaus, dass wir mit externen Mitteln versuchen, das heruntergefallene Auto zu "töten". Die Ansätze können unterschiedlich sein: vom Ausschalten des Computers über IPMI und Blockieren des Ports am Switch bis zum Zugriff auf die API des Cloud-Anbieters usw. Und erst nach diesem Vorgang können Sie den Assistenten wechseln. Dies gewährleistet eine
höchstens einmalige Garantie, die uns
Konsistenz garantiert.
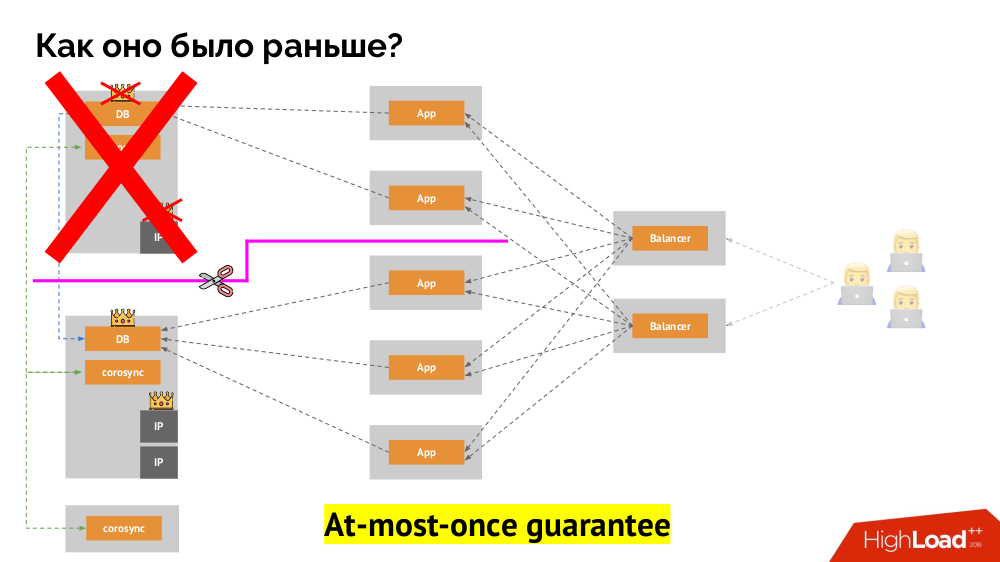
Wie kann man das auch in Kubernetes erreichen? Zu diesem Zweck gibt es bereits erwähnte Controller, deren Verhalten im Falle einer Unzugänglichkeit eines Knotens unterschiedlich ist:
Deployment : "Mir wurde gesagt, dass es 3 Pods geben soll, und jetzt gibt es nur noch 2 Pods - ich werde einen neuen erstellen";StatefulSet : "Pod weg?" Ich werde warten: Entweder wird dieser Knoten zurückkehren oder sie werden uns sagen, dass wir ihn töten sollen. " Die Container selbst (ohne Bedienereingriff) werden nicht neu erstellt. Auf diese Weise wird höchstens die gleiche Garantie erreicht.
Im letzteren Fall ist jedoch ein Zaun erforderlich: Wir benötigen einen Mechanismus, der bestätigt, dass dieser Knoten definitiv verschwunden ist. Die automatische Ausführung ist zum einen sehr schwierig (viele Implementierungen sind erforderlich), und zum anderen werden Knoten normalerweise nur langsam getötet (der Zugriff auf IPMI kann Sekunden, zehn Sekunden oder sogar Minuten dauern). Nur wenige Leute sind mit der Wartezeit pro Minute zufrieden, um die Basis auf den neuen Master umzustellen. Es gibt jedoch einen anderen Ansatz, für den kein Zaunmechanismus erforderlich ist ...
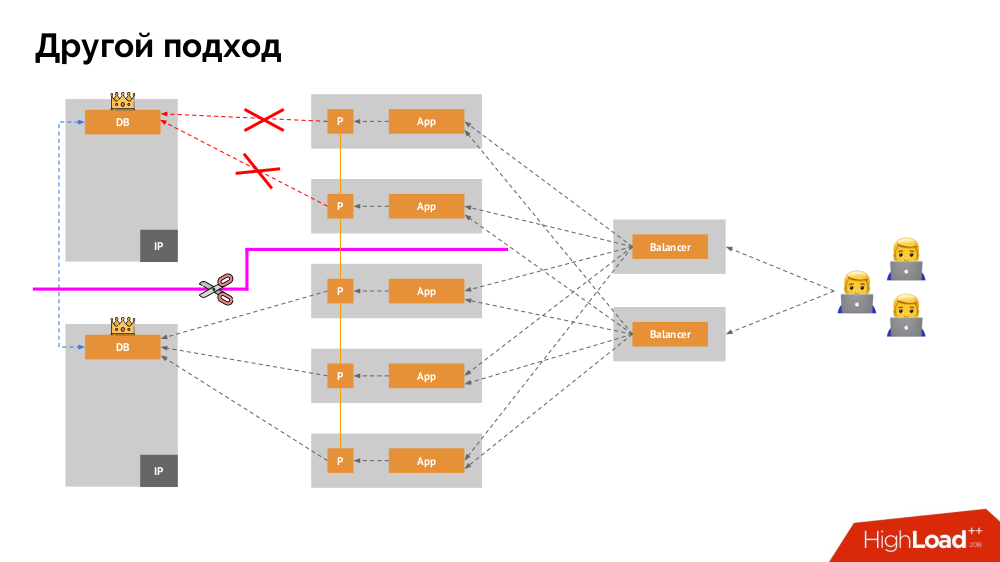
Ich werde seine Beschreibung außerhalb von Kubernetes beginnen. Es verwendet einen speziellen Load Balancer, über den Backends auf das DBMS zugreifen. Seine Spezifität liegt in der Tatsache, dass es die Eigenschaft der Konsistenz hat, d.h. Schutz vor Netzwerkfehlern und Split-Brain, da Sie damit alle Verbindungen zum aktuellen Master entfernen, auf die Synchronisierung (Replikat) auf einem anderen Knoten warten und zu diesem wechseln können. Ich habe keinen etablierten Begriff für diesen Ansatz gefunden und ihn als
konsistente Umschaltung bezeichnet .
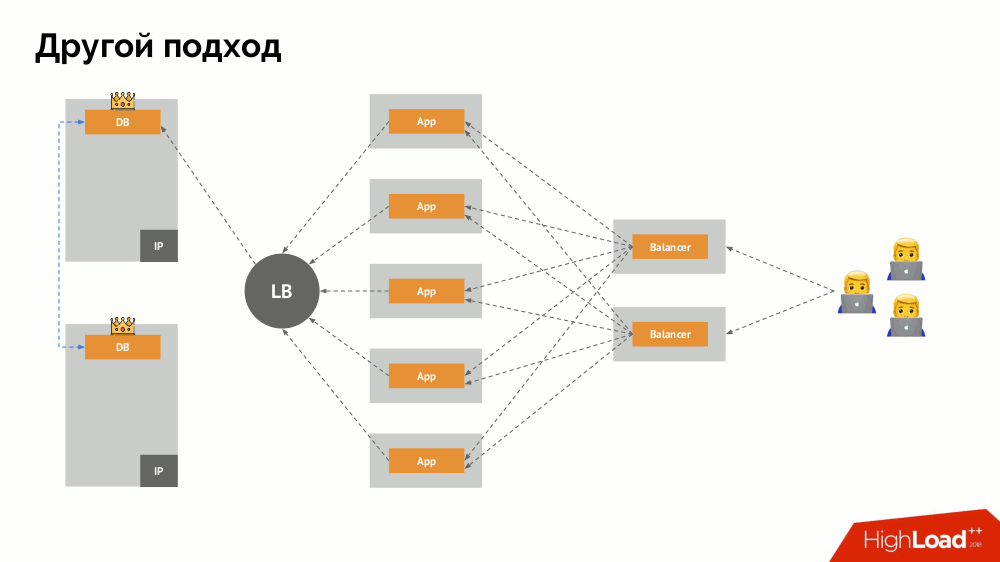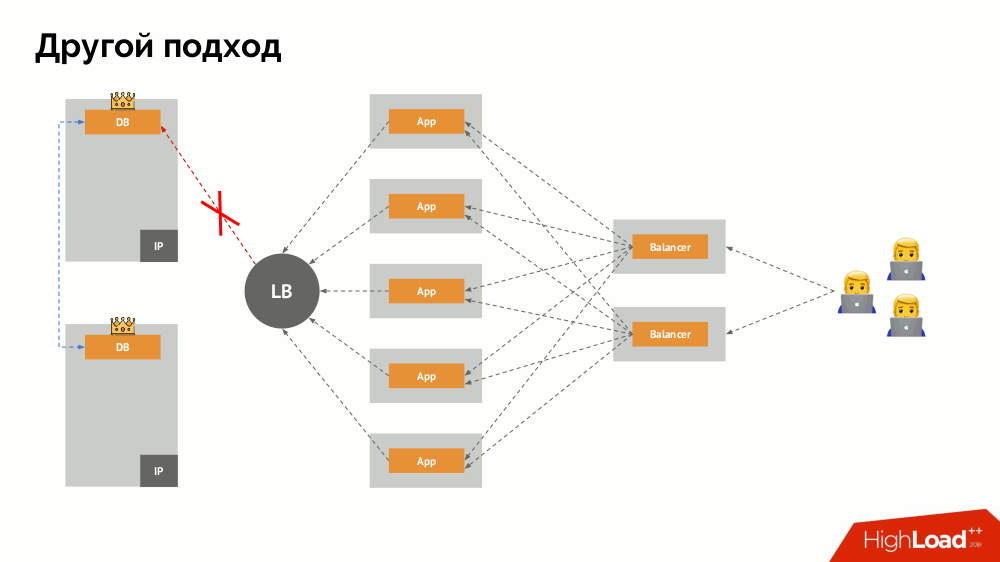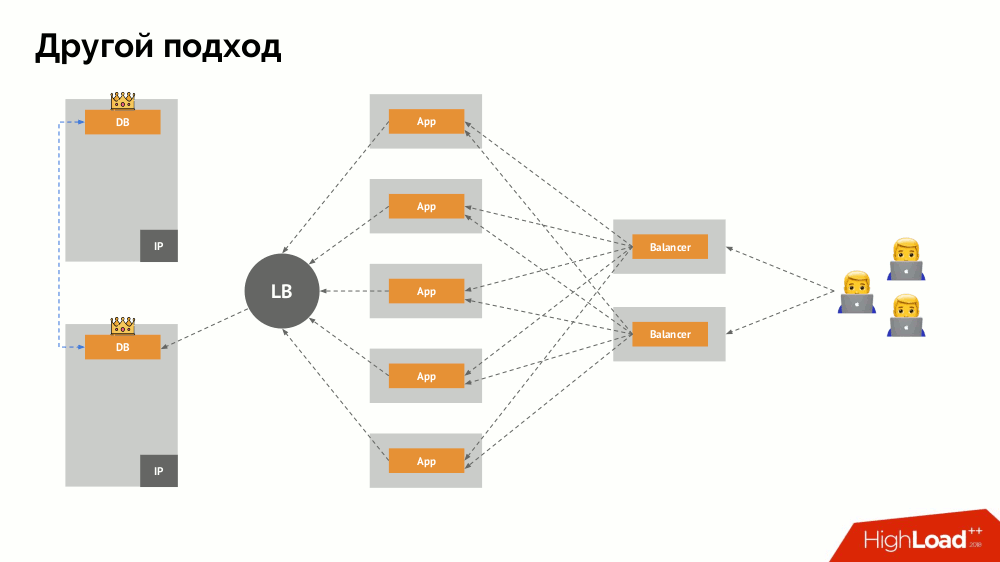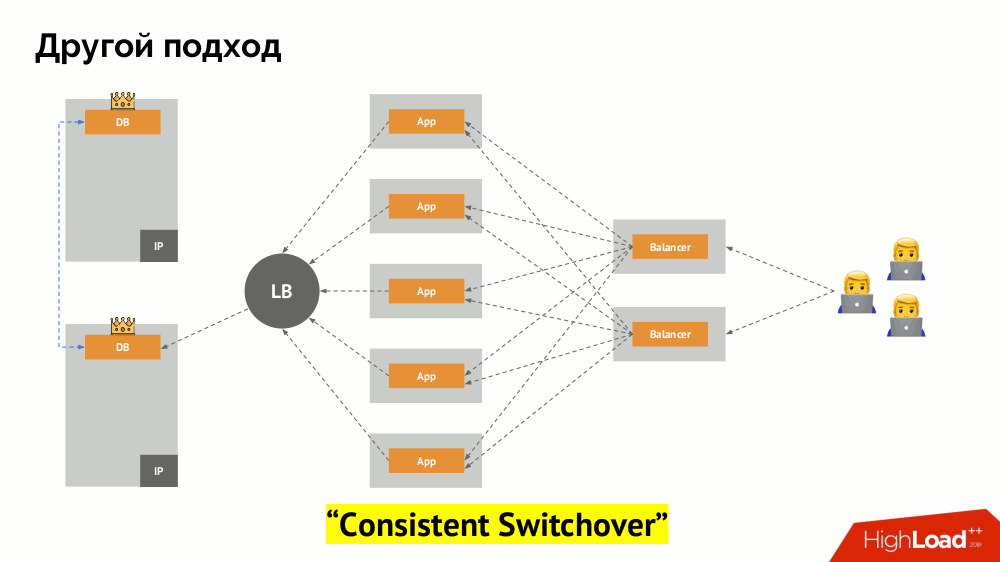
Die Hauptfrage bei ihm ist, wie man es universell macht und sowohl Cloud-Anbieter als auch private Installationen unterstützt. Zu diesem Zweck werden den Anwendungen Proxyserver hinzugefügt. Jeder von ihnen akzeptiert Anfragen aus seiner Bewerbung (und leitet sie an das DBMS weiter), und von allen wird ein Quorum eingeholt. Sobald ein Teil des Clusters ausfällt, entfernen die Proxys, die das Quorum verloren haben, sofort ihre Verbindungen zum DBMS.
3. Datenspeicherung und Kubernetes
Der Hauptmechanismus ist das
Network Block Device (auch bekannt als SAN) -Netzwerklaufwerk in verschiedenen Implementierungen für die gewünschten Cloud-Optionen oder Bare Metal. Das Einfügen einer geladenen Datenbank (z. B. MySQL, für das 50.000 IOPS erforderlich sind) in die Cloud (AWS EBS) funktioniert jedoch aufgrund der
Latenz nicht .
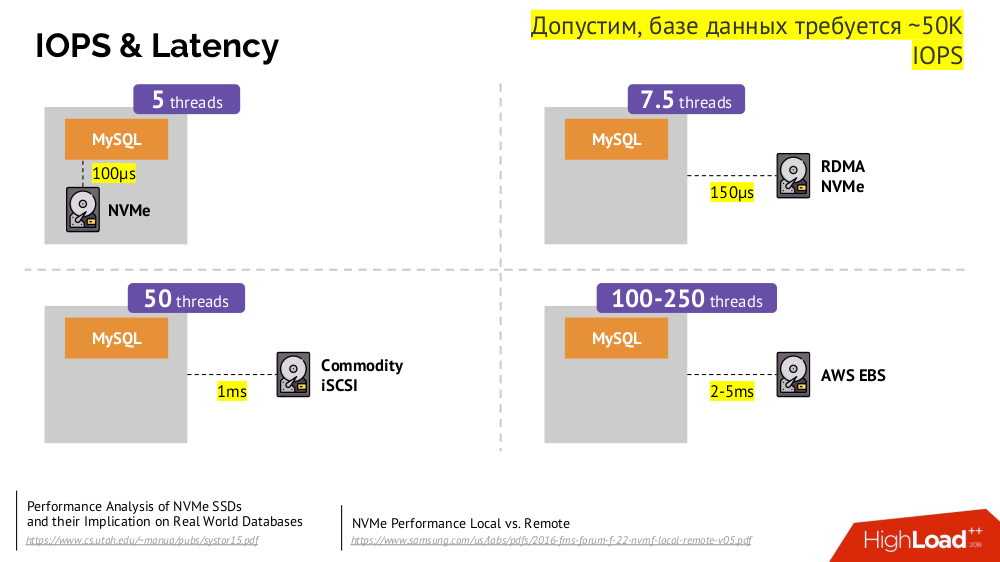
Kubernetes kann in solchen Fällen eine lokale Festplatte anschließen -
Local Storage . Wenn ein Fehler auftritt (die Festplatte ist nicht mehr im Pod verfügbar), müssen wir diesen Computer reparieren - ähnlich wie beim klassischen Schema bei einem Ausfall eines zuverlässigen Servers.
Beide Optionen (
Netzwerkblockgerät und
lokaler Speicher ) gehören zur Kategorie
ReadWriteOnce : Der Speicher kann nicht an zwei Stellen (Pods)
bereitgestellt werden. Für diese Skalierung müssen Sie eine neue Festplatte erstellen und mit einem neuen Pod verbinden (hierfür ist ein K8s-Mechanismus integriert). und füllen Sie dann die erforderlichen Daten aus (bereits von unseren Streitkräften erstellt).
Wenn wir den
ReadWriteMany- Modus benötigen, stehen
Implementierungen des Network File System (oder NAS) zur Verfügung: Für die öffentliche Cloud sind dies
AzureFile und
AWSElasticFileSystem sowie für deren Installationen CephFS und Glusterfs für Fans verteilter Systeme sowie NFS.

Übe
1. Standalone
Diese Option ist der Fall, wenn Sie durch nichts daran gehindert werden, das DBMS im separaten Servermodus mit lokalem Speicher zu starten. Von Hochverfügbarkeit ist keine Rede ... obwohl sie bis zu einem gewissen Grad (d. H. Ausreichend für diese Anwendung) auf Eisenebene implementiert werden kann. Es gibt viele Fälle für diese Anwendung. Zuallererst sind dies alle Arten von Staging- und Entwicklungsumgebungen, aber nicht nur: Auch sekundäre Dienste fallen hierher. Das Deaktivieren für 15 Minuten ist nicht kritisch. In Kubernetes wird dies von
StatefulSet mit einem Pod implementiert:
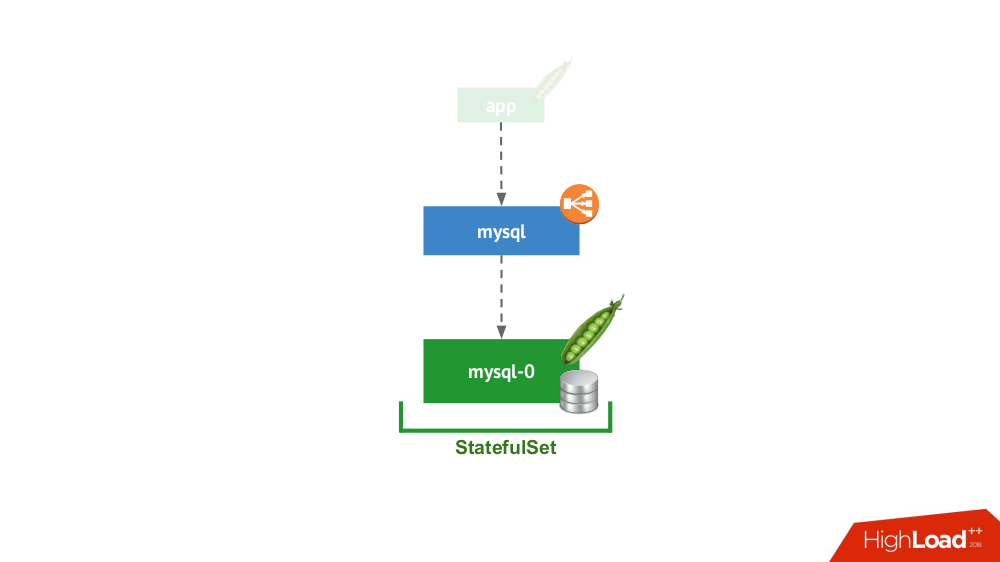
Im Allgemeinen ist dies eine praktikable Option, die aus meiner Sicht keine Nachteile hat, verglichen mit der Installation eines DBMS auf einer separaten virtuellen Maschine.
2. Repliziertes Paar mit manueller Umschaltung
StatefulSet erneut verwendet, aber das allgemeine Schema sieht folgendermaßen aus:
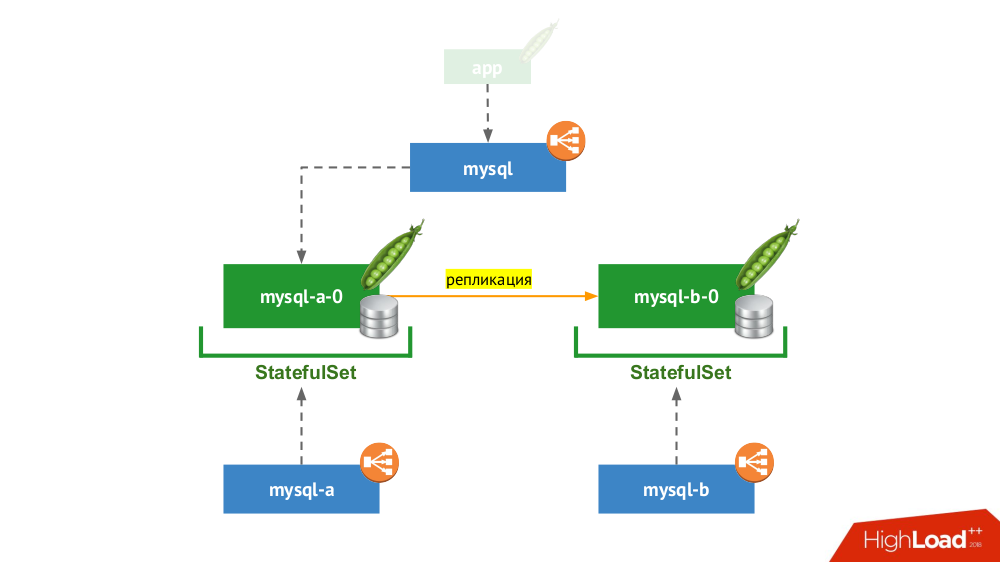
Wenn einer der Knoten abstürzt (
mysql-a-0 ), geschieht kein Wunder, aber wir haben eine Replik (
mysql-b-0 ), auf die wir den Verkehr umschalten können. In diesem Fall ist es wichtig, nicht nur vor dem Umschalten des Datenverkehrs zu vergessen, nicht nur DBMS-Anforderungen aus dem
mysql Dienst zu entfernen, sondern sich auch manuell beim DBMS anzumelden und sicherzustellen, dass alle Verbindungen hergestellt sind (sie zu beenden). Außerdem müssen Sie vom DBMS zum zweiten Knoten wechseln und das Replikat neu konfigurieren in die entgegengesetzte Richtung.
Wenn Sie derzeit die klassische Version mit zwei Servern (Master + Standby) ohne automatisches
Failover verwenden , entspricht diese Lösung Kubernetes. Geeignet für MySQL, PostgreSQL, Redis und andere Produkte.
3. Skalieren der Leselast
In der Tat ist dieser Fall nicht zustandsbehaftet, weil wir nur über das Lesen sprechen. Hier befindet sich der Haupt-DBMS-Server außerhalb des betrachteten Schemas, und im Rahmen von Kubernetes wird eine "Farm von Slave-Servern" erstellt, die schreibgeschützt sind. Der allgemeine Mechanismus - die Verwendung von Init-Containern zum Füllen von DBMS-Daten in jedem neuen Pod dieser Farm (unter Verwendung eines Hot-Dumps oder des üblichen Dumps mit zusätzlichen Aktionen usw. - hängt vom verwendeten DBMS ab). Um sicherzustellen, dass jede Instanz nicht zu weit vom Master entfernt ist, können Sie Lebendigkeitstests verwenden.

4. Smart Client
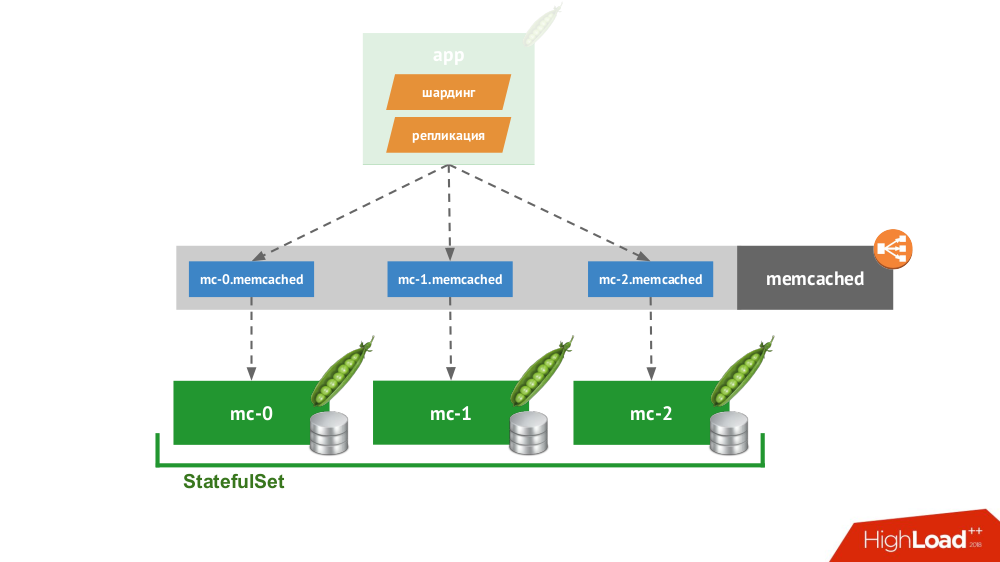
Wenn Sie ein
StatefulSet aus drei Memcaches erstellen, bietet Kubernetes einen speziellen Service, der keine Anforderungen ausgleicht, sondern jeden Pod für seine eigene Domain erstellt. Der Client kann mit ihnen arbeiten, wenn er selbst in der Lage ist, Shards und Replikationen durchzuführen.
Für ein Beispiel müssen Sie nicht weit gehen: So funktioniert der Sitzungsspeicher in PHP sofort. Für jede Sitzungsanforderung werden Anforderungen gleichzeitig an alle Server gestellt, wonach die relevanteste Antwort aus ihnen ausgewählt wird (ähnlich wie bei einem Datensatz).
5. Cloud Native-Lösungen
Es gibt viele Lösungen, die sich anfänglich auf den Ausfall von Knoten konzentrieren, d. H. Sie selbst können ein
Failover und eine Wiederherstellung von Knoten durchführen und bieten
Konsistenzgarantien . Dies ist keine vollständige Liste von ihnen, sondern nur ein Teil der populären Beispiele:

Alle von ihnen werden einfach in
StatefulSet platziert, wonach sich die Knoten finden und einen Cluster bilden. Die Produkte selbst unterscheiden sich darin, wie sie drei Dinge implementieren:
- Wie lernen Knoten voneinander? Es gibt Methoden wie die Kubernetes-API, DNS-Einträge, statische Konfiguration, spezialisierte Knoten (Seed), die Erkennung von Diensten von Drittanbietern ...
- Wie verbindet sich der Client? Durch einen Load Balancer, der an Hosts verteilt wird, oder der Client muss über alle Hosts Bescheid wissen, und er wird entscheiden, wie er vorgehen soll.
- Wie erfolgt die horizontale Skalierung? Auf keinen Fall voll oder schwierig / mit Einschränkungen.
Unabhängig von den gewählten Lösungen für diese Probleme funktionieren alle diese Produkte gut mit Kubernetes, da sie ursprünglich als "Herde"
(Vieh) geschaffen wurden .
6. Stolon PostgreSQL
Mit Stolon können Sie PostgreSQL, das als
Haustier erstellt wurde , in
Vieh verwandeln. Wie wird das erreicht?
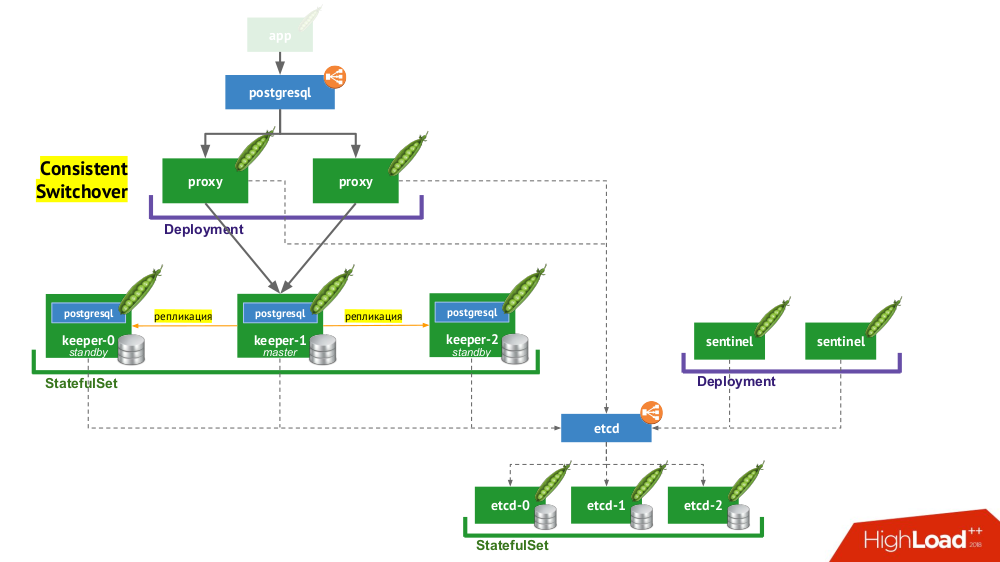
- Erstens benötigen wir eine Serviceerkennung, in deren Rolle möglicherweise etcd steht (andere Optionen sind verfügbar) - ein Cluster von ihnen wird in einem
StatefulSet abgelegt. - Ein weiterer Teil der Infrastruktur ist
StatefulSet mit PostgreSQL-Instanzen. Neben dem eigentlichen DBMS befindet sich neben jeder Installation auch eine Komponente namens Keeper , die die DBMS-Konfiguration ausführt. - Eine andere Komponente, Sentinel, wird als
Deployment bereitgestellt und überwacht die Konfiguration des Clusters. Er entscheidet, wer Master und Standby sein wird, schreibt diese Informationen an etcd. Der Keeper liest Daten aus etcd und führt mit einer Instanz von PostgreSQL Aktionen aus, die dem aktuellen Status entsprechen. - Eine weitere Komponente, die in
Deployment bereitgestellt wird und PostgreSQL-Instanzen gegenübersteht, Proxy, ist eine Implementierung des bereits erwähnten Consistent Switchover- Musters. Diese Komponenten sind mit etcd verbunden, und wenn diese Verbindung unterbrochen wird, beendet der Proxy sofort die ausgehenden Verbindungen, da er von diesem Moment an die Rolle seines Servers nicht kennt (ist er jetzt Master oder Standby?). - Schließlich stehen Proxy-Instanzen dem üblichen
LoadBalancer LoadBalancer gegenüber.
Schlussfolgerungen
Ist es also möglich, in Kubernetes zu stationieren? Ja, natürlich ist es in einigen Fällen möglich ... Und wenn es angebracht ist, wird es so gemacht (siehe Stolon-Workflow) ...
Jeder weiß, dass sich die Technologie in Wellen entwickelt. Anfangs kann jedes neue Gerät sehr schwierig zu bedienen sein, aber im Laufe der Zeit ändert sich alles: Technologie wird verfügbar. Wohin gehen wir? Ja, es wird so drinnen bleiben, aber wir werden nicht wissen, wie es funktionieren wird. Kubernetes entwickelt aktiv
Betreiber . Bisher gibt es nicht so viele von ihnen und sie sind nicht so gut, aber es gibt Bewegung in diese Richtung.
Videos und Folien
Video von der Aufführung (ca. eine Stunde):
Präsentation des Berichts:
PS Wir haben auch im Internet einen sehr (!) Kurzen Textdruck aus diesem Bericht gefunden - danke an Nikolai Volynkin.
PPS
Weitere Berichte in unserem Blog:
Sie könnten auch an folgenden Veröffentlichungen interessiert sein: