Stellen Sie sich vor: Bei einem Anruf um drei Uhr morgens nehmen Sie den Hörer ab und hören einen Schrei, dass niemand anderes Ihr Produkt verwendet. Beängstigend Im Leben ist dies natürlich nicht der Fall, aber wenn Sie das Problem des Abflusses von Benutzern nicht angemessen berücksichtigen, befinden Sie sich möglicherweise in einer ähnlichen Situation.
Wir haben bereits ausführlich beschrieben, was ein Abfluss ist: Wir haben uns mit der Theorie befasst und gezeigt, wie man ein neuronales Netzwerk in ein digitales Orakel verwandelt. Experten im Plarium Krasnodar kennen eine andere Art der Vorhersage. Wir werden über ihn sprechen.

Dies ist nicht das RFM, das wir brauchen.
RFM ist eine Methode, mit der Kunden segmentiert und ihr Verhalten analysiert werden. Basierend auf den erhaltenen Daten können Sie für jede Gruppe ein Treueprogramm erstellen, eine Verteilung der Benutzer erstellen und vorhersagen, wann sie für Einkäufe zurückkehren werden.
Die Geschichte der RFM-Entwicklung begann 1987 mit der Veröffentlichung des Artikels
Zählen Ihrer Kunden: Wer sind sie und was werden sie als Nächstes tun? Es wurde eine Analysemethode beschrieben, die auf der Pareto-Verteilung basiert (eine Zwei-Parameter-Familie absolut kontinuierlicher Verteilungen).
Das Modell hieß Pareto / NBD und berücksichtigte nur die Kaufhistorie der Benutzer. In der klassischen Interpretation wurde die Arbeit dieser Methode auf fünf Säulen oder Annäherungen aufgebaut:
- Solange Benutzer aktiv sind, entspricht die Anzahl der vom Käufer während des Zeitraums t getätigten Transaktionen der Pareto-Verteilung mit einem durchschnittlichen λt.
- Die Heterogenität des Parameters λ (Transaktionsrate) folgt einer Gammaverteilung mit den Parametern r und α.
- Jeder Käufer hat eine unbegrenzte Zeitspanne "Leben" τ. Der Punkt, an dem der Benutzer inaktiv wird, wird exponentiell mit dem Parameter μ (Abbrecherquote) verteilt.
- Die Heterogenität des Parameters μ unter den Benutzern folgt einer Gammaverteilung mit den Parametern s (Form) und β (Skala).
- Die Parameter λ und μ können unabhängig voneinander zwischen den Käufern variieren.
Die Nachteile dieses Modells waren sowohl die hohe Komplexität der Berechnung der hypergeometrischen Gauß-Funktionen als auch die Suche nach der Maximum-Likelihood-Funktion.
In einem Artikel aus dem Jahr 2003,
„Zählen Ihrer Kunden“, der einfache Weg: Eine Alternative zum Pareto / NBD-Modell , wurde die Idee der Implementierung eines besseren Modells veröffentlicht. Zusätzlich zur Kaufhistorie wurden zwei weitere Parameter verwendet: Häufigkeit und Verschreibung. Der Hauptunterschied zu Pareto / NBD bestand darin, wie der Moment bestimmt wird, in dem der Kunde das Unternehmen verlässt.
In der klassischen Umgebung wurde angenommen, dass der Benutzer jederzeit abreisen kann, unabhängig von der Häufigkeit und dem Muster seiner Einkäufe in der Vergangenheit. Der neue Ansatz basiert auf der Hypothese, dass der Käufer unmittelbar nach Abschluss der Transaktion das Interesse verlieren könnte.
Dies vereinfachte die Berechnung und führte zum Beta-geometrischen Modell (BG / NBD). Es werden drei Hauptparameter verwendet: Aktualität, Häufigkeit, Geld, - sowie vier zusätzliche Parameter: r, α, a, b (Parameter a und b wurden aus der
Beta-Verteilung hinzugefügt).
RFM hilft bei der Vorhersage, ob ein Kunde in Zukunft einen Kauf tätigen wird. Die Spezialisten von Plarium Krasnodar haben diese Methode modifiziert.
Prognostizieren Sie den Abfluss einfach und geschmackvoll
Für Berechnungen benötigen wir eine Reihe von Daten zu Spielsitzungen. Es wird in eine Matrix aus RFM-Parametern und in vier weitere Koeffizienten neu berechnet, die vom Modell im Lernprozess ausgewählt werden.
Im Kontext eines Spiels erhalten Parameter die folgenden Bedeutungen:
- Aktualität - wie lange der Benutzer zum Zeitpunkt der letzten Anmeldung gespielt hat;
- Häufigkeit - wie oft der Benutzer das Spiel erneut betreten hat;
- M onetary - wie lange der Benutzer gespielt hat ("Lebenszeit").
Parameter werden zu einer Matrix zusammengefasst. Dann wird es in ein Modell geladen, das die Wahrscheinlichkeit des "Lebens" der Benutzer berechnet - die Chance, dass sie weiter spielen.
Die Berechnungen erfolgen nach folgender Formel:
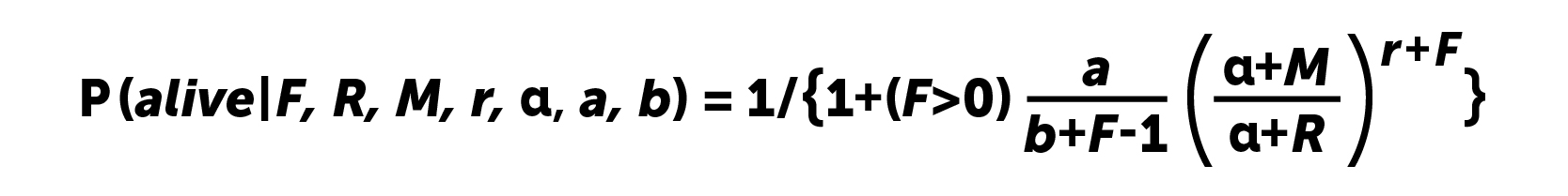
Für Benutzer ohne erneute Eingabe ist die Wahrscheinlichkeit eines „Lebens“ offensichtlich eins. 2008 schlugen die Autoren des Artikels
Computing P (lebendig) unter Verwendung des BG / NBD-Modells eine Lösung für dieses Problem vor. Spielefirmen können zwei Optionen verwenden, die ähnliche Ergebnisse liefern.
Methode 1 - Der Parameter π wird für alle Benutzer eingegeben. Es zeigt, welche Spieler als inaktiv gelten.
Methode 2 - Eine Einheit wird zum Frequenzparameter hinzugefügt. Diese Maßnahme vermeidet die Degeneration der Formel bei Frequenz = 0, fügt jedoch jedem Benutzer künstlich einen weiteren Eintrag ins Spiel hinzu.
So passen Sie die RFM-Methode für Spieleentwickler an
Angenommen, wir haben einen neuen Benutzer. Er hat gerade das Spiel betreten. Parameter
F = 1 (oder 0, abhängig von den Berechnungen), da der erste Eintrag nicht berücksichtigt wird und der Spieler noch keine wiederholten Einträge hatte.
Der Benutzer spielt drei Tage. Die Parameter ändern sich:
F berücksichtigt nur tägliche Eingaben, daher ist sein Wert 2 und die Indikatoren
M und
R sind 3. Mit diesen Daten erhalten wir die Wahrscheinlichkeit eines "Lebens" nahe der Einheit.
Am nächsten Tag betritt der Benutzer das Spiel nicht. Der Parameter
M wird aktualisiert, während
F und
R gleich bleiben. Wenn wir alle Werte in der Formel einsetzen, sehen wir, dass der Wahrscheinlichkeitsindikator niedriger geworden ist.
Wenn der Benutzer während der Woche nicht spielt, wird die
M- Anzeige erneut aktualisiert und die Wahrscheinlichkeit eines „Lebens“ sinkt noch mehr.
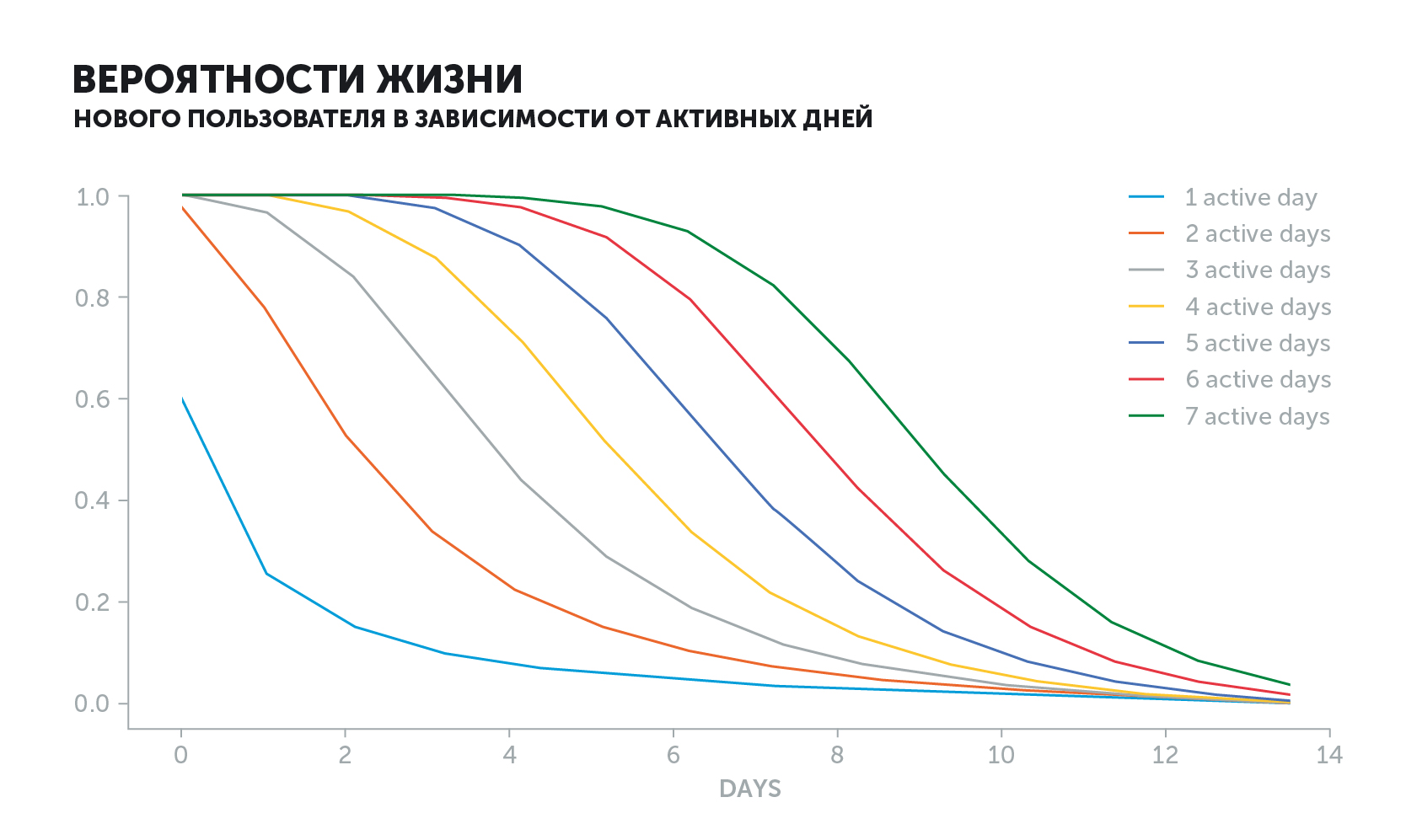
Das Diagramm des aktiven Benutzers sieht anders aus. Die Wahrscheinlichkeit eines "Lebens" wird abhängig von seiner Geschichte abnehmen. Wenn er jeden Tag ins Spiel ging und plötzlich aufhörte, fiel der Wert des Indikators viel schneller als wenn er alle zwei Tage spielte.

Wichtige Vor- und Nachteile von RFM
Der Hauptvorteil dieser Methode ist ihre Einfachheit:
- Für Berechnungen benötigen Sie keinen komplexen mathematischen Apparat.
- Indikatoren werden nach einer relativ einfachen Formel berechnet;
- Sie können auf komplexe Pipelines für Daten verzichten.
- Alle optimalen Modellparameter werden automatisch ausgewählt.
Darüber hinaus sind RFM-Daten leicht zu interpretieren. Wenn man die Geschichte des Benutzers studiert, kann man verstehen, warum er eine solche Wahrscheinlichkeit des "Lebens" hat. Bei der Arbeit mit komplexeren Methoden ist es oft schwieriger, spezifische Schlussfolgerungen zu ziehen.
RFM hat auch Nachteile.
Erstens ist dies nicht die genaueste Methode. Es funktioniert gut, aber eine Reihe von Parametern werden in den Berechnungen nicht verwendet. Zum Beispiel betreten viele Benutzer, die aus Gewohnheit das Interesse verlieren, das Spiel. Das heißt, die durchschnittliche Anzahl von Spielesitzungen pro Tag nimmt ab, und die Häufigkeit von erneuten Einträgen ändert sich nicht.
Zweitens berücksichtigt die Methode nicht die Aktivität des Benutzers: wie viele Ressourcen er übertragen hat, ob er den Feind angegriffen oder Truppen geschaffen hat. Wenn wir alle Spieler mit einer Wahrscheinlichkeit des "Lebens" von ~ 0,8 nehmen, dann gibt es abhängig von den Parametern und ihrer Geschichte zusätzlich zu den aktiven diejenigen, die alle drei Tage teilnehmen.
Drittens wird der verstorbene Benutzer "lebendig", wenn er das Spiel erneut startet. Was muss er einen Monat nach dem letzten Login tun? Solche Situationen erschweren die Erkennung von Spielern mit großen Pausen zwischen den Sitzungen. Im Allgemeinen ist dies nicht kritisch, obwohl es zu einem gewissen Ungleichgewicht kommt, wenn wir versuchen zu verstehen, ob der Benutzer "lebt" oder nicht.
Ist es nicht besser, ein neuronales Netzwerk zu verwenden?
Besser, aber zuallererst müssen Sie verstehen, wie das Projekt umgesetzt wird: um große Aufgaben im Handumdrehen zu lösen oder schrittweise auf das Ziel zuzugehen.
Die RFM-Analyse zeigt die Wahrscheinlichkeit des „Lebens“ des Benutzers zum Zeitpunkt der Berechnung. Wir werden nicht verstehen können, ob der Spieler in zwei oder drei Wochen abreisen wird, und das neuronale Netzwerk wird es können. Angesichts der gesamten Infrastruktur ist die Schaffung eines solchen integrierten Systems zur Analyse des Verhaltens von Spielern von Grund auf viel schwieriger. Darüber hinaus benötigen Sie eine Basislinie, mit der Sie die Qualität des neuronalen Netzwerks vergleichen können. Ein solcher Ansatz führt wahrscheinlich zu finanziellen Verlusten, wenn Sie die Stärke nicht berechnen.
Unsere Erfahrung zeigt, dass globale Aufgaben schrittweise umgesetzt werden müssen. Das Erstellen eines funktionierenden Prototyps ist nicht schwierig, aber das Sammeln und Verarbeiten von Daten, das Einrichten und Trainieren eines neuronalen Netzwerks ist eine andere Sache. Diese Prozesse können lange dauern, was immer fehlt.
Aus diesem Grund haben wir uns zunächst für ein einfacheres Modell entschieden: Wir haben Nachforschungen angestellt, die Vor- und Nachteile ermittelt und in der Arbeit getestet. Die Ergebnisse passten zu uns. RFM weist Mängel auf, die jedoch durch die einfache Bedienung großzügig ausgeglichen werden. Und das neuronale Netzwerk ist der nächste Schritt zur Verbesserung des Systems.