Ceph ist ein Objektspeicher, mit dem ein Failovercluster erstellt werden kann. Trotzdem passieren Fehler. Jeder, der mit Ceph arbeitet, kennt die Legende über CloudMouse oder Rosreestr. Leider ist es nicht üblich, negative Erfahrungen mit uns zu teilen, die Ursachen von Fehlern werden meistens vertuscht und erlauben zukünftigen Generationen nicht, aus den Fehlern anderer zu lernen.
Nun, lassen Sie uns einen Testcluster einrichten, der jedoch dem realen nahe kommt, und die Katastrophe anhand von Knochen analysieren. Wir werden alle Leistungseinbußen messen, Speicherlecks finden und den Service-Wiederherstellungsprozess analysieren. Und all dies unter der Führung von Artemy Kapitula, der fast ein Jahr lang Fallstricke studierte, führte dazu, dass die Clusterleistung bei Null versagte und die Latenz nicht auf unanständige Werte sprang. Und ich habe eine rote Grafik, die viel besser ist.
Als nächstes finden Sie eine Video- und Textversion eines der besten Berichte von
DevOpsConf Russia 2018.
Über den Sprecher: Artemy Kapitula Systemarchitekt RCNTEC. Das Unternehmen bietet IP-Telefonielösungen an (Zusammenarbeit, Organisation eines Remote-Büros, softwaredefinierte Speichersysteme und Energieverwaltungs- / Verteilungssysteme). Das Unternehmen ist hauptsächlich im Unternehmensbereich tätig und daher auf dem DevOps-Markt nicht sehr bekannt. Dennoch wurden einige Erfahrungen mit Ceph gesammelt, das in vielen Projekten als Grundelement der Speicherinfrastruktur verwendet wird.
Ceph ist ein softwaredefiniertes Repository mit vielen Softwarekomponenten.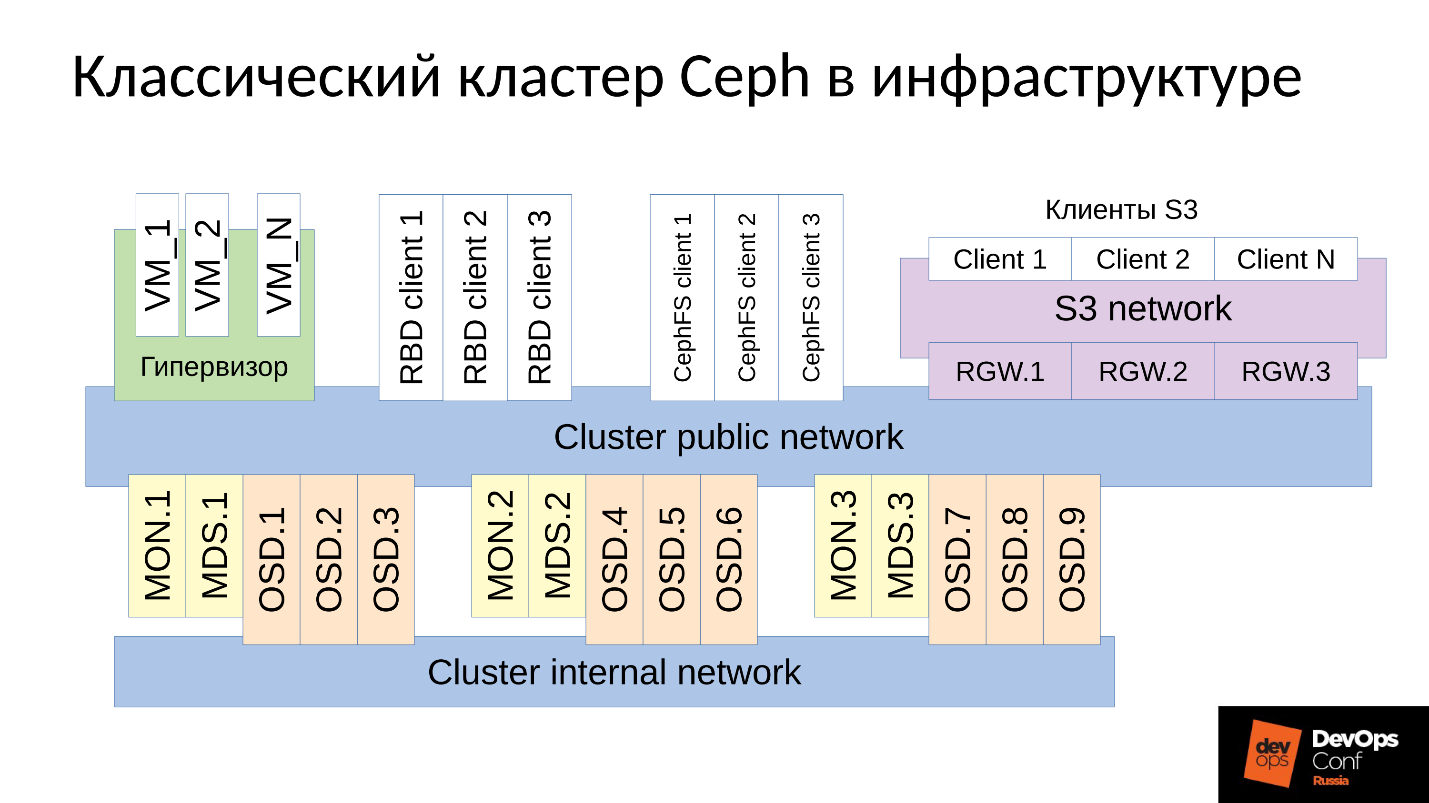
Im Diagramm:
- Die obere Ebene ist das interne Clusternetzwerk, über das der Cluster selbst kommuniziert.
- Die untere Ebene - eigentlich Ceph - ist eine Reihe von internen Ceph-Dämonen (MON, MDS und OSD), die Daten speichern.
In der Regel werden alle Daten repliziert. Im Diagramm habe ich absichtlich drei Gruppen mit jeweils drei OSDs ausgewählt, und jede dieser Gruppen enthält normalerweise eine Datenreplik. Infolgedessen werden Daten in drei Kopien gespeichert.
Ein übergeordnetes Clusternetzwerk ist das Netzwerk, über das Ceph-Clients auf Daten zugreifen. Über sie kommunizieren Clients mit dem Monitor, mit MDS (wer benötigt es) und mit OSD. Jeder Client arbeitet mit jedem OSD und mit jedem Monitor unabhängig. Daher weist das
System keinen einzigen Fehlerpunkt auf , was sehr erfreulich ist.
Kunden
● S3-Kunden
S3 ist eine API für HTTP. S3-Clients arbeiten über HTTP und stellen eine Verbindung zu RGW-Komponenten (Ceph Rados Gateway) her. Sie kommunizieren fast immer mit einer Komponente über ein dediziertes Netzwerk. Dieses Netzwerk (ich habe es S3-Netzwerk genannt) verwendet nur HTTP, Ausnahmen sind selten.
● Hypervisor mit virtuellen Maschinen
Diese Kundengruppe wird häufig verwendet. Sie arbeiten mit Monitoren und mit OSD, von denen sie allgemeine Informationen über den Clusterstatus und die Datenverteilung erhalten. Für Daten gehen diese Clients über das öffentliche Cluster-Netzwerk direkt zu OSD-Daemons.
● RBD-Clients
Es gibt auch physische BR-Metall-Hosts, bei denen es sich normalerweise um Linux handelt. Sie sind RBD-Clients und erhalten Zugriff auf Images, die in einem Ceph-Cluster gespeichert sind (Images der virtuellen Maschine).
● CephFS-Clients
Die vierte Gruppe von Clients, die noch nicht viele haben, aber von wachsendem Interesse sind, sind CephFS-Cluster-Dateisystem-Clients. Das CephFS-Clustersystem kann gleichzeitig von vielen Knoten bereitgestellt werden, und alle Knoten erhalten Zugriff auf dieselben Daten, wobei sie mit jedem OSD arbeiten. Das heißt, es gibt keine Gateways als solche (Samba, NFS und andere). Das Problem ist, dass ein solcher Client nur Linux und eine ziemlich moderne Version sein kann.

Unser Unternehmen arbeitet auf dem Unternehmensmarkt, und dort wird der Ball von ESXi, HyperV und anderen regiert. Dementsprechend muss der Ceph-Cluster, der irgendwie im Unternehmenssektor verwendet wird, die entsprechenden Techniken unterstützen. Dies war uns bei Ceph nicht genug, daher mussten wir den Ceph-Cluster mit unseren Komponenten verfeinern und erweitern und tatsächlich etwas mehr als Ceph aufbauen, unsere eigene Plattform zum Speichern von Daten.
Darüber hinaus arbeiten Kunden im Unternehmenssektor nicht unter Linux, aber die meisten von ihnen, Windows, gelegentlich Mac OS, können nicht selbst zum Ceph-Cluster wechseln. Sie müssen durch eine Art Gateway laufen, die in diesem Fall zu Engpässen werden.
Wir mussten alle diese Komponenten hinzufügen und erhielten einen etwas breiteren Cluster.

Wir haben zwei zentrale Komponenten: die
SCSI-Gateways-Gruppe , die über FibreChannel oder iSCSI den Zugriff auf Daten in einem Ceph-Cluster ermöglicht. Diese Komponenten werden verwendet, um HyperV und ESXi mit einem Ceph-Cluster zu verbinden. PROXMOX-Kunden arbeiten immer noch auf ihre eigene Art und Weise - über RBD.
Wir lassen Dateiclients nicht direkt in das Clusternetzwerk, da ihnen mehrere fehlertolerante Gateways zugewiesen sind. Jedes Gateway bietet Zugriff auf das Dateiclustersystem über NFS, AFP oder SMB. Dementsprechend erhält fast jeder Client, sei es Linux, FreeBSD oder nicht nur ein Client, Server (OS X, Windows), Zugriff auf CephFS.
Um all dies zu bewältigen, mussten wir tatsächlich unser eigenes Ceph-Orchester und alle unsere Komponenten entwickeln, die dort zahlreich sind. Aber jetzt darüber zu sprechen macht keinen Sinn, da dies unsere Entwicklung ist. Die meisten werden sich wahrscheinlich für den "nackten" Ceph selbst interessieren.
Ceph wird häufig verwendet, und gelegentlich treten Fehler auf. Sicher kennt jeder, der mit Ceph arbeitet, die Legende über CloudMouse. Dies ist eine schreckliche urbane Legende, aber dort ist nicht alles so schlimm, wie es scheint. Es gibt ein neues Märchen über Rosreestr. Ceph drehte sich überall und überall versagte es. Irgendwo endete es tödlich, irgendwo gelang es, die Konsequenzen schnell zu beseitigen.
Leider ist es für uns nicht üblich, negative Erfahrungen auszutauschen, jeder versucht, die relevanten Informationen zu verbergen. Ausländische Unternehmen sind etwas offener, insbesondere DigitalOcean (ein bekannter Anbieter, der virtuelle Maschinen vertreibt) erlitt fast einen Tag lang einen Ceph-Ausfall. Es war der 1. April - ein wunderbarer Tag! Sie haben einige der Berichte veröffentlicht, ein kurzes Protokoll unten.

Die Probleme begannen um 7 Uhr morgens, um 11 Uhr verstanden sie, was geschah, und begannen, den Fehler zu beseitigen. Zu diesem Zweck haben sie zwei Befehle zugewiesen: Einer lief aus irgendeinem Grund um die Server herum und installierte dort Speicher, und der zweite startete aus irgendeinem Grund manuell einen Server nach dem anderen und überwachte sorgfältig alle Server. Warum? Wir sind alle daran gewöhnt, alles mit einem Klick einzuschalten.
Was passiert grundsätzlich in einem verteilten System, wenn es effektiv aufgebaut ist und fast an der Grenze seiner Fähigkeiten arbeitet?Um diese Frage zu beantworten, müssen wir uns ansehen, wie der Ceph-Cluster funktioniert und wie der Fehler auftritt.

Ceph-Fehlerszenario
Zuerst funktioniert der Cluster gut, alles läuft gut. Dann passiert etwas, wonach die OSD-Dämonen, in denen die Daten gespeichert sind, den Kontakt zu den zentralen Komponenten des Clusters (Monitore) verlieren. Zu diesem Zeitpunkt tritt eine Zeitüberschreitung auf und der gesamte Cluster erhält einen Einsatz. Der Cluster bleibt eine Weile stehen, bis er erkennt, dass etwas mit ihm nicht stimmt, und korrigiert danach sein internes Wissen. Danach wird der Kundenservice bis zu einem gewissen Grad wiederhergestellt, und der Cluster arbeitet wieder in einem herabgesetzten Modus. Und das Lustige ist, dass es schneller funktioniert als im normalen Modus - das ist eine erstaunliche Tatsache.
Dann beseitigen wir den Fehler. Angenommen, wir haben den Strom verloren, das Rack wurde komplett abgeschnitten. Elektriker kamen angerannt, sie alle restauriert, sie versorgten die Server mit Strom, die Server wurden eingeschaltet und dann
beginnt der Spaß .
Jeder ist daran gewöhnt, dass bei einem Serverausfall alles schlecht wird und beim Einschalten des Servers alles gut wird. Hier ist alles völlig falsch.
Der Cluster stoppt praktisch, führt die primäre Synchronisation durch und beginnt dann eine reibungslose, langsame Wiederherstellung, wobei er allmählich in den normalen Modus zurückkehrt.

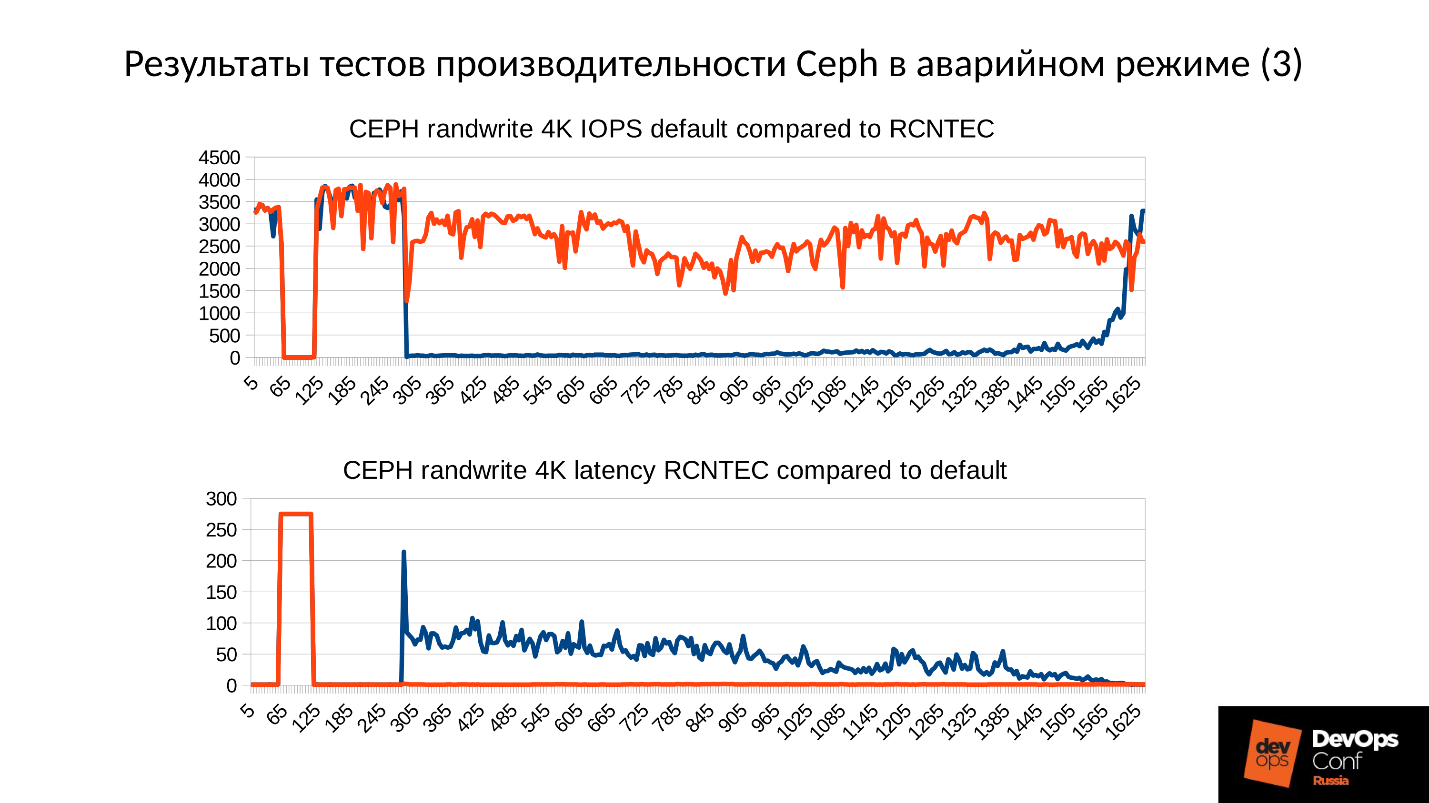
Oben sehen Sie eine grafische Darstellung der Ceph-Clusterleistung, wenn sich ein Fehler entwickelt. Bitte beachten Sie, dass hier genau die Intervalle, über die wir gesprochen haben, sehr deutlich nachvollzogen werden:
- Normalbetrieb bis ca. 70 Sekunden;
- Ausfall für eine Minute bis ca. 130 Sekunden;
- Ein Plateau, das merklich höher als der normale Betrieb ist, ist die Arbeit von degradierten Clustern;
- Dann schalten wir den fehlenden Knoten ein - dies ist ein Trainingscluster, es gibt nur 3 Server und 15 SSDs. Wir starten den Server irgendwo um 260 Sekunden.
- Der Server wurde eingeschaltet und trat in den Cluster ein - IOPS'y fiel.
Versuchen wir herauszufinden, was dort wirklich passiert ist. Das erste, was uns interessiert, ist ein Eintauchen ganz am Anfang des Diagramms.
OSD-Fehler
Stellen Sie sich ein Beispiel für einen Cluster mit drei Racks mit jeweils mehreren Knoten vor. Wenn das linke Rack ausfällt, pingen sich alle OSD-Daemons (keine Hosts!) In einem bestimmten Intervall mit Ceph-Nachrichten. Wenn mehrere Nachrichten verloren gehen, wird eine Nachricht an den Monitor gesendet: "Ich, OSD so und so, kann OSD so und so nicht erreichen."

In diesem Fall werden Nachrichten normalerweise nach Hosts gruppiert. Wenn also zwei Nachrichten von verschiedenen OSDs auf demselben Host eintreffen, werden sie zu einer Nachricht zusammengefasst. Wenn OSD 11 und OSD 12 melden, dass sie OSD 1 nicht erreichen können, wird dies als Host 11 interpretiert, der über OSD 1 beschwert ist. Wenn OSD 21 und OSD 22 gemeldet wurden, wird dies als Host 21 interpretiert, der mit OSD 1 unzufrieden ist Danach berücksichtigt der Monitor, dass sich OSD 1 im Status "Down" befindet, und benachrichtigt alle Mitglieder des Clusters (durch Ändern der OSD-Zuordnung). Die Arbeit wird im herabgesetzten Modus fortgesetzt.
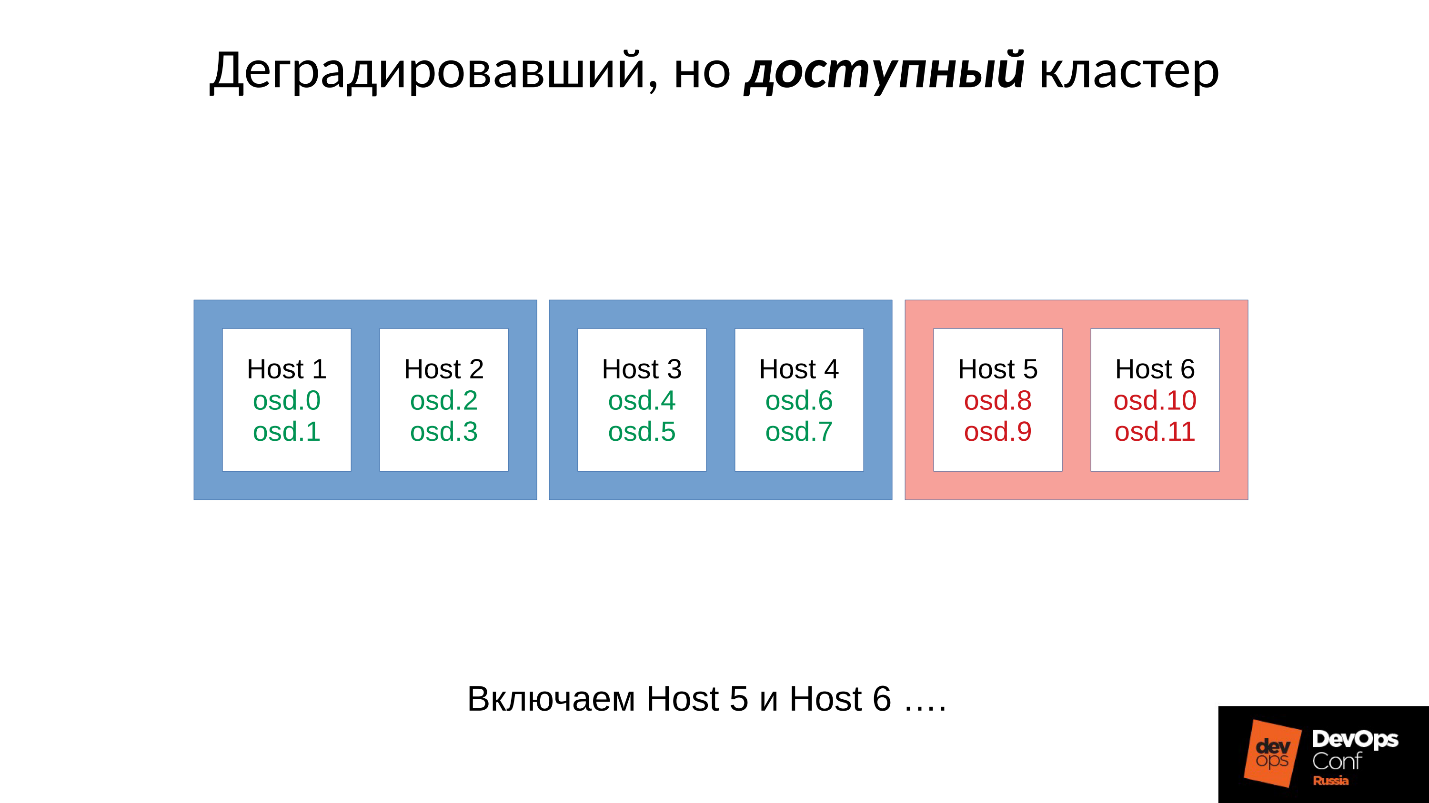
Hier ist also unser Cluster und das ausgefallene Rack (Host 5 und Host 6). Wir schalten Host 5 und Host 6 ein, als die Stromversorgung erschien, und ...
Cephs inneres Verhalten
Und jetzt ist der interessanteste Teil, dass wir mit der
anfänglichen Datensynchronisation beginnen . Da es viele Replikate gibt, müssen diese synchron sein und dieselbe Version haben. Beim Starten des OSD-Starts:
- OSD liest die verfügbaren Versionen und den verfügbaren Verlauf (pg_log - um die aktuellen Versionen von Objekten zu ermitteln).
- Danach wird festgelegt, auf welchem OSD die neuesten Versionen von herabgesetzten Objekten (missing_loc) aktiviert sind und welche sich dahinter befinden.
- Wenn die Rückwärtsversionen gespeichert sind, ist eine Synchronisierung erforderlich, und neue Versionen können als Referenz zum Lesen und Schreiben von Daten verwendet werden.
Es wird eine Geschichte verwendet, die von allen OSDs gesammelt wird, und diese Geschichte kann ziemlich viel sein; Der tatsächliche Standort der Gruppe von Objekten im Cluster, in dem sich die entsprechenden Versionen befinden, wird bestimmt. Wie viele Objekte sich im Cluster befinden, wie viele Datensätze erhalten werden, wenn der Cluster lange Zeit im herabgesetzten Modus gestanden hat, ist die Geschichte lang.
Zum Vergleich: Die typische Größe eines Objekts bei der Arbeit mit einem RBD-Bild beträgt 4 MB. Wenn wir in Löschcode arbeiten - 1 MB. Wenn wir eine 10-TB-Festplatte haben, erhalten wir eine Million Megabyte-Objekte auf der Festplatte. Wenn wir 10 Festplatten auf dem Server haben, gibt es bereits 10 Millionen Objekte. Wenn 32 Festplatten vorhanden sind (wir bauen einen effizienten Cluster auf, wir haben eine enge Zuordnung), müssen 32 Millionen Objekte im Speicher gehalten werden. Darüber hinaus werden Informationen zu jedem Objekt in mehreren Kopien gespeichert, da jede Kopie angibt, dass sie an dieser Stelle in dieser Version und in dieser - in dieser - liegt.
Es stellt sich heraus, dass sich eine große Datenmenge im RAM befindet:
- Je mehr Objekte vorhanden sind, desto größer ist die Historie von missing_loc.
- je mehr PG - desto mehr pg_log und OSD-Map;
Außerdem:
- je größer die Festplattengröße ist;
- je höher die Dichte (die Anzahl der Festplatten in jedem Server);
- Je höher die Belastung des Clusters und desto schneller Ihr Cluster.
- je länger das OSD inaktiv ist (im Offline-Status);
Mit anderen Worten, je
steiler der von uns erstellte Cluster ist und je länger der Teil des Clusters nicht reagiert, desto mehr RAM wird beim Start benötigt .
Extreme Optimierungen sind die Wurzel allen Übels
"... und der schwarze OOM kommt nachts zu den bösen Jungs und Mädchen und tötet alle Prozesse links und rechts ab."
Stadt Sysadmin Legende
RAM benötigt also viel, der Speicherverbrauch steigt (wir haben sofort mit einem Drittel des Clusters begonnen), und das System kann theoretisch in SWAP integriert werden, wenn Sie es natürlich erstellt haben. Ich denke, es gibt viele Leute, die SWAP für schlecht halten und es nicht schaffen: „Warum? Wir haben viel Gedächtnis! “ Dies ist jedoch der falsche Ansatz.
Wenn die SWAP-Datei nicht im Voraus erstellt wurde, da entschieden wurde, dass Linux effizienter arbeitet, wird es früher oder später zu einem Speicherkiller (OOM-Killer) kommen. Und nicht zu der Tatsache, dass derjenige getötet wird, der den gesamten Speicher verschlungen hat, nicht derjenige, der zuerst Pech hatte. Wir wissen, was ein optimistischer Ort ist - wir bitten um eine Erinnerung, sie versprechen es uns, wir sagen: "Jetzt gib uns eine", als Antwort: "Aber nein!" - und aus dem Gedächtnis Killer.
Dies ist ein regulärer Linux-Job, sofern er nicht im Bereich des virtuellen Speichers konfiguriert ist.
Der Prozess wird aus dem Gedächtnis Killer und fällt schnell und rücksichtslos aus. Darüber hinaus wissen keine anderen Prozesse, die er starb, nicht. Er hatte keine Zeit, irgendjemanden über irgendetwas zu informieren, sie kündigten ihn einfach.
Dann wird der Prozess natürlich neu gestartet - wir haben systemd, es startet bei Bedarf auch OSDs, die gefallen sind. Gefallene OSDs beginnen und ... eine Kettenreaktion beginnt.
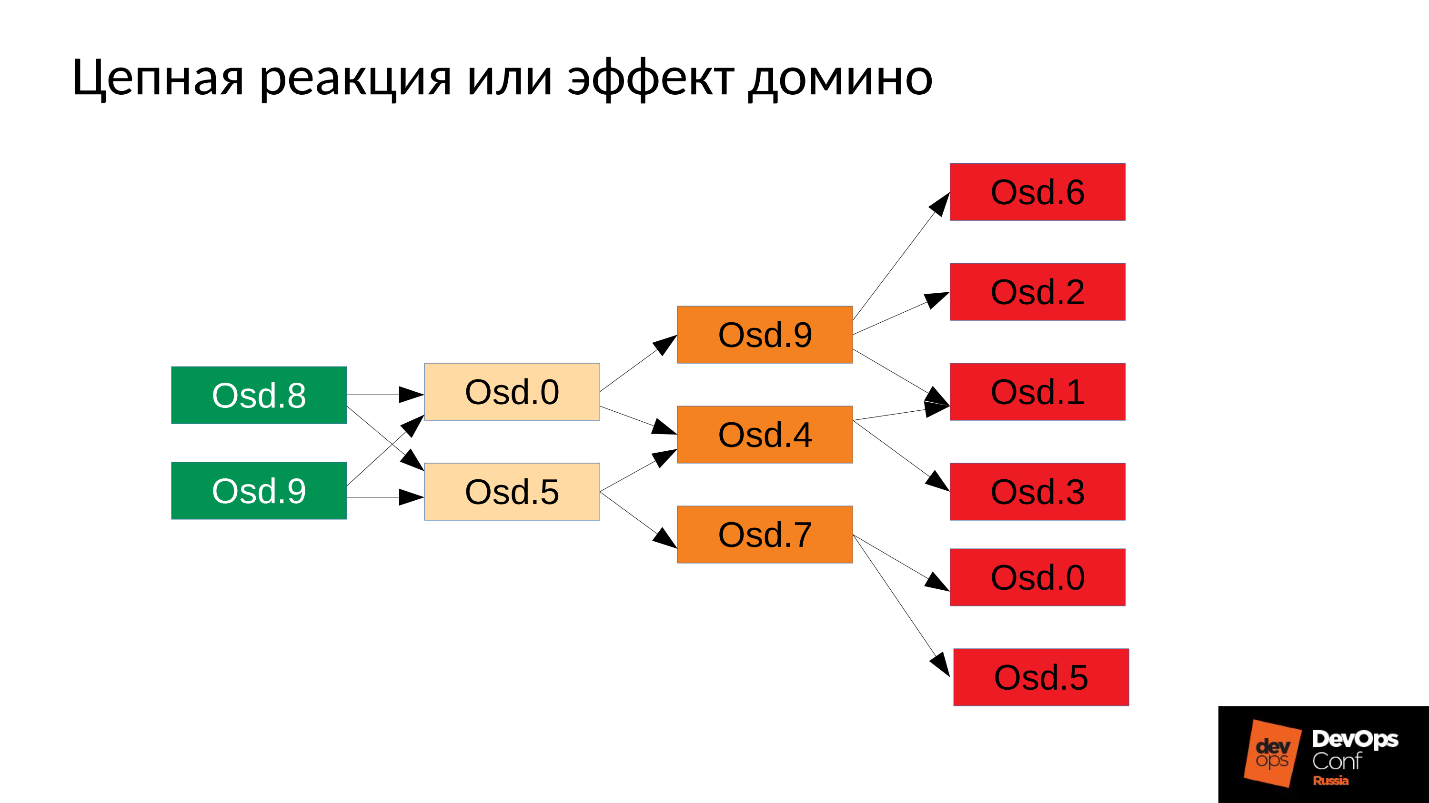
In unserem Fall haben wir OSD 8 und OSD 9 gestartet, sie haben angefangen, alles zu zerstören, aber kein Glück, OSD 0 und OSD 5. Ein Killer ohne Speicher flog zu ihnen und beendete sie. Sie starteten neu - sie lasen ihre Daten, begannen den Rest zu synchronisieren und zu zerstören. Drei weitere Pechvögel (OSD 9, OSD 4 und OSD 7). Diese drei starteten neu, übten Druck auf den gesamten Cluster aus, die nächste Packung hatte Pech.
Der Cluster beginnt buchstäblich vor unseren Augen auseinanderzufallen . Der Abbau erfolgt sehr schnell, und dieses "sehr schnelle" wird normalerweise in Minuten ausgedrückt, maximal zehn Minuten. Wenn Sie 30 Knoten (10 Knoten pro Rack) haben und das Rack aufgrund eines Stromausfalls herunterfahren, liegt nach 6 Minuten die Hälfte des Clusters.
Wir bekommen also so etwas wie das Folgende.
Auf fast jedem Server ist ein OSD ausgefallen. Und wenn dies auf jedem Server der Fall ist, dh in jeder Fehlerdomäne,
die wir für das ausgefallene OSD haben, sind die
meisten unserer Daten nicht zugänglich . Jede Anfrage ist blockiert - zum Schreiben, zum Lesen - es macht keinen Unterschied. Das ist alles! Wir sind aufgestanden.
Was tun in einer solchen Situation? Genauer gesagt,
was musste getan werden ?
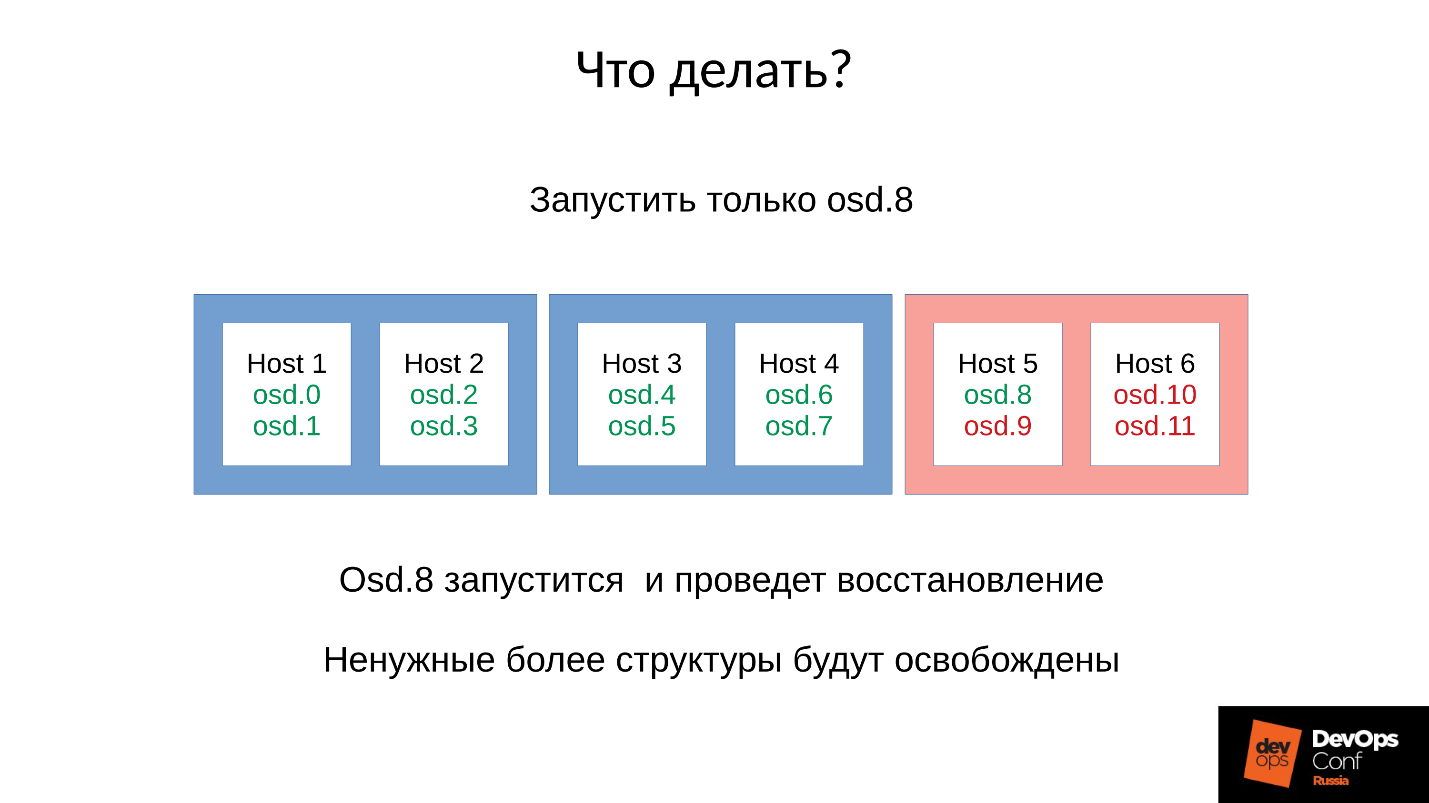
Antwort: Starten Sie den Cluster nicht sofort, dh das gesamte Rack, sondern heben Sie vorsichtig jeweils einen Dämon auf.
Das wussten wir aber nicht. Wir haben sofort angefangen und bekommen, was wir haben. In diesem Fall haben wir einen der vier Daemons (8, 9, 10, 11) gestartet. Der Speicherverbrauch wird um ca. 20% steigen. In der Regel stehen wir vor einem solchen Sprung. Dann beginnt der Speicherverbrauch zu sinken, da einige der Strukturen, die zum Speichern von Informationen darüber verwendet wurden, wie sich der Cluster verschlechtert hat, verlassen werden. Das heißt, ein Teil der Platzierungsgruppen ist in seinen normalen Zustand zurückgekehrt, und alles, was zur Aufrechterhaltung des verschlechterten Zustands erforderlich ist, wird freigegeben -
theoretisch wird es freigegeben .
Sehen wir uns ein Beispiel an. Der C-Code links und rechts ist fast identisch, der Unterschied besteht nur in Konstanten.

Diese beiden Beispiele fordern vom System eine unterschiedliche Speichermenge an:
- links - 2048 Stück à 1 MB;
- rechts - 2097152 Stück von 1 KByte.
Dann warten beide Beispiele darauf, dass wir sie oben fotografieren. Und nach dem Drücken der EINGABETASTE wird Speicher freigegeben - alles außer dem letzten Stück. Das ist sehr wichtig - das letzte Stück bleibt. Und wieder warten sie darauf, dass wir sie fotografieren.
Unten ist, was tatsächlich passiert ist.

- Zuerst haben beide Prozesse gestartet und den Speicher aufgefressen. Klingt nach der Wahrheit - 2 GB RSS.
- Drücken Sie ENTER und lassen Sie sich überraschen. Das erste Programm, das in großen Stücken auffiel, gab Speicher zurück. Das zweite Programm kehrte jedoch nicht zurück.
Die Antwort darauf liegt im Linux-Malloc.
Wenn wir Speicher in großen Blöcken anfordern, wird er unter Verwendung des anonymen mmap-Mechanismus ausgegeben, der dem Adressraum des Prozessors zugewiesen wird, von wo aus der Speicher zu uns geschnitten wird. Wenn wir free () ausführen, wird Speicher freigegeben und Seiten werden in den Seitencache (System) zurückgegeben.
Wenn wir Speicher in kleinen Stücken zuweisen, machen wir sbrk (). sbrk () verschiebt den Zeiger auf das Ende des Heaps. Theoretisch kann das verschobene Ende zurückgegeben werden, indem Speicherseiten an das System zurückgegeben werden, wenn kein Speicher verwendet wird.
Schauen Sie sich nun die Abbildung an. Wir hatten viele Aufzeichnungen in der Geschichte des Standorts degradierter Objekte, und dann kam die Benutzersitzung - ein langlebiges Objekt. Wir haben synchronisiert und alle zusätzlichen Strukturen sind verschwunden, aber das langlebige Objekt ist geblieben, und wir können sbrk () nicht zurückbewegen.

Wir haben immer noch viel ungenutzten Speicherplatz, der mit SWAP frei werden könnte. Aber wir sind schlau - wir haben SWAP deaktiviert.
Natürlich wird dann ein Teil des Speichers vom Anfang des Heaps verwendet, aber dies ist nur ein Teil, und ein sehr bedeutender Rest wird belegt bleiben.
Was tun in einer solchen Situation? Die Antwort ist unten.
Kontrollierter Start
- Wir starten einen OSD-Daemon.
- Wir warten, während es synchronisiert ist, wir überprüfen die Speicherbudgets.
- Wenn wir verstehen, dass wir den Start des nächsten Dämons überleben werden, starten wir den nächsten.
- Wenn nicht, starten Sie schnell den Daemon neu, der den meisten Speicherplatz beansprucht hat. Er konnte für kurze Zeit ausfallen, er hat nicht viel Geschichte, fehlende Locs und andere Dinge, also wird er weniger Speicher essen, das Speicherbudget wird sich leicht erhöhen.
- Wir laufen um den Cluster herum, kontrollieren ihn und erhöhen schrittweise alles.
- Wir prüfen, ob es möglich ist, mit dem nächsten OSD fortzufahren.
DigitalOcean hat dies tatsächlich erreicht:
"Unser Datacenter-Team führt Speichererweiterungen durch, während ein anderes Team langsam weiterhin Knoten aufruft, während das Speicherbudget jedes Hosts manuell verwaltet wird."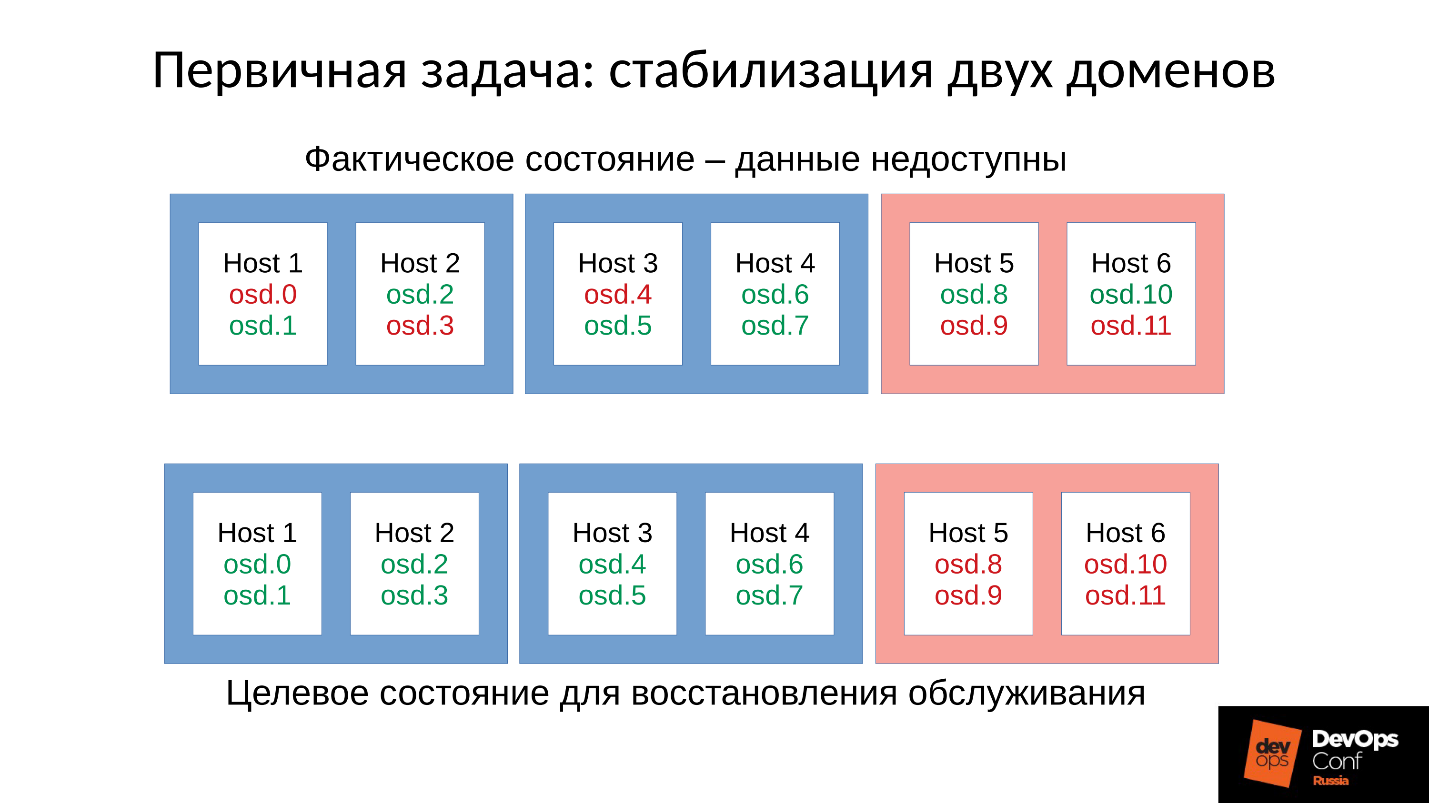
Kehren wir zu unserer Konfiguration und aktuellen Situation zurück. Jetzt haben wir einen zusammengebrochenen Cluster nach einer Kettenreaktion von Out-of-Memory-Killer. Wir verbieten den automatischen Neustart von OSD in der roten Domäne und starten nacheinander Knoten aus den blauen Domänen. Weil
unsere erste Aufgabe immer darin besteht, den Dienst wiederherzustellen , ohne zu verstehen, warum dies passiert ist. Wir werden später verstehen, wenn wir den Dienst wiederherstellen. Im Betrieb ist dies immer der Fall.
Wir bringen den Cluster in den Zielzustand, um den Dienst wiederherzustellen, und beginnen dann, ein OSD nach unserer Methodik nach dem anderen auszuführen. Wir schauen uns den ersten an, starten Sie bei Bedarf die anderen neu, um das Speicherbudget anzupassen, den nächsten - 9, 10, 11 - und der Cluster scheint synchronisiert und bereit zu sein, mit der Wartung zu beginnen.
Das Problem ist, wie die
Schreibwartung in Ceph durchgeführt wird .
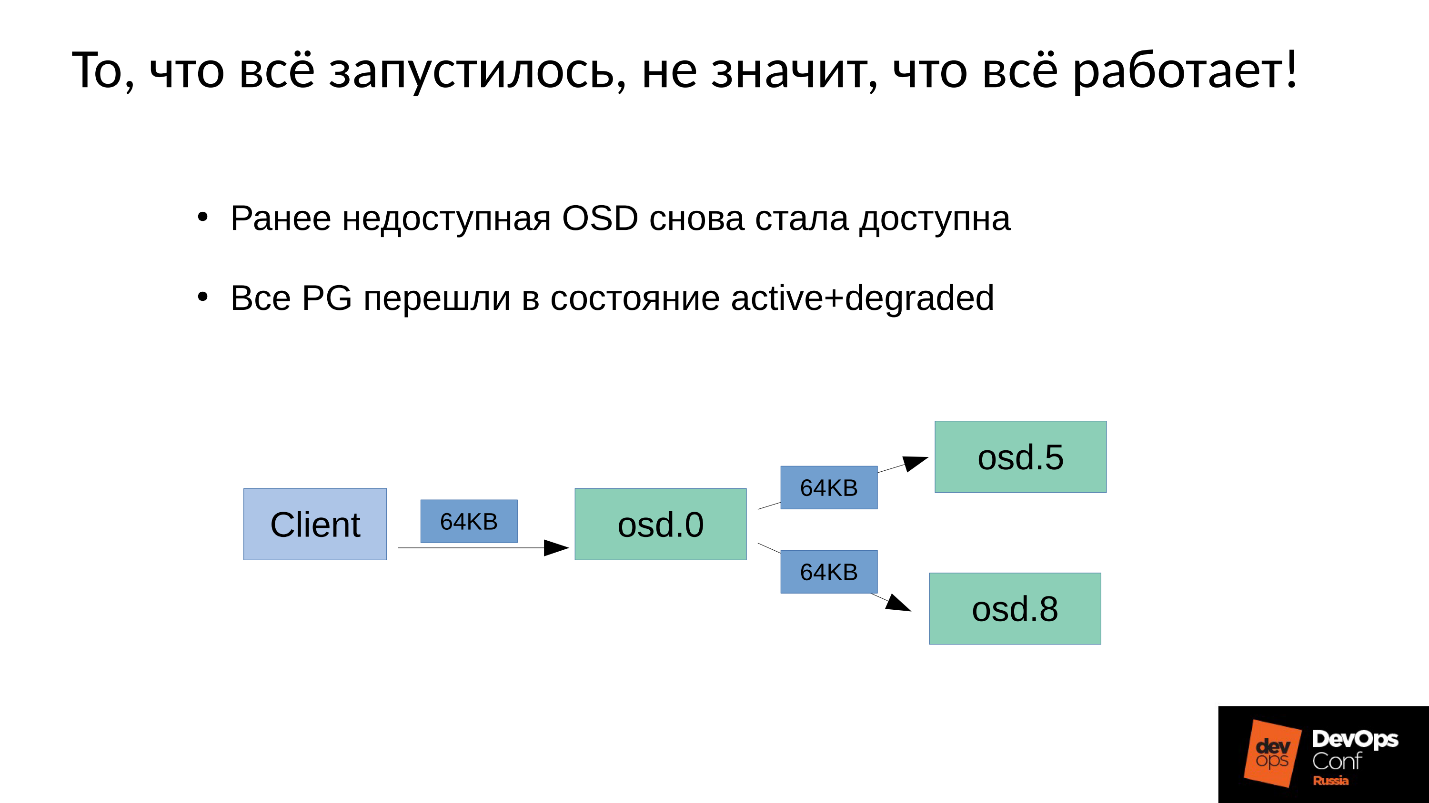
Wir haben 3 Replikate: ein Master-OSD und zwei Slaves dafür. Wir werden klarstellen, dass der Master / Slave in jeder Platzierungsgruppe einen eigenen hat, aber jeder einen Master und zwei Slaves hat.
Die Schreib- oder Leseoperation fällt auf den Master. Wenn der Master beim Lesen die richtige Version hat, gibt er sie dem Kunden. Die Aufnahme ist etwas komplizierter, die Aufnahme muss auf allen Replikaten wiederholt werden. Wenn der Client 64 KB in OSD 0 schreibt, gehen dementsprechend die gleichen 64 KB in unserem Beispiel an OSD 5 und OSD 8.
Tatsache ist jedoch, dass unser OSD 8 stark beeinträchtigt ist, da wir viele Prozesse neu gestartet haben.

Da in Ceph jede Änderung ein Übergang von Version zu Version ist, haben wir unter OSD 0 und OSD 5 eine neue Version, unter OSD 8 - die alte. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
Fazit
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
Dieser Artikel ist eine Abschrift eines der besten Berichte von DevOpsConf Russia. In Kürze werden wir das Video öffnen und in einer Textversion veröffentlichen, wie interessant Themen sind. Abonnieren Sie hier auf Youtube oder im Newsletter, wenn Sie solche nützlichen Materialien nicht verpassen und über die Neuigkeiten von DevOps informiert werden möchten.