Es gibt verschiedene Möglichkeiten, Fehler in Programmiersprachen zu behandeln:
- Standardausnahmen für viele Sprachen (Java, Scala und andere JVMs, Python und viele andere)
- Statuscodes oder Flags (Go, Bash)
- verschiedene algebraische Datenstrukturen, deren Werte sowohl erfolgreiche Ergebnisse als auch Fehlerbeschreibungen sein können (Scala, Haskell und andere funktionale Sprachen)
Ausnahmen werden sehr häufig verwendet, andererseits werden sie oft als langsam bezeichnet. Gegner eines funktionalen Ansatzes appellieren jedoch häufig an die Leistung.
Vor kurzem habe ich mit Scala gearbeitet, wo ich sowohl Ausnahmen als auch verschiedene Datentypen für die Fehlerbehandlung gleichermaßen verwenden kann. Daher frage ich mich, welcher Ansatz bequemer und schneller sein wird.
Wir werden die Verwendung von Codes und Flags sofort verwerfen, da dieser Ansatz in den JVM-Sprachen nicht akzeptiert wird und meiner Meinung nach zu fehleranfällig ist (das Wortspiel tut mir leid). Daher werden wir Ausnahmen und verschiedene Arten von ADT vergleichen. Darüber hinaus kann das ADT als Verwendung von Fehlercodes in einem funktionalen Stil betrachtet werden.
UPDATE : Ausnahmen ohne Stack-Traces werden zum Vergleich hinzugefügt
Teilnehmer
Ein bisschen mehr über algebraische DatentypenFür diejenigen, die mit ADT ( ADT ) nicht allzu vertraut sind - ein algebraischer Typ besteht aus mehreren möglichen Werten, von denen jeder ein zusammengesetzter Wert sein kann (Struktur, Datensatz).
Ein Beispiel ist der Typ Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None , die anstelle von Nullen verwendet wird: Ein Wert dieses Typs kann entweder Some(t) wenn es einen Wert gibt, oder None wenn dies nicht der Fall ist.
Ein anderes Beispiel wäre Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) , der das Ergebnis einer Berechnung beschreibt, die erfolgreich oder mit einem Fehler abgeschlossen werden konnte.
Also unsere Teilnehmer:
- Gute alte Ausnahmen
- Ausnahmen ohne Stack-Trace, da das Füllen eines Stack-Trace sehr langsam ist
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) - dieselben Ausnahmen, jedoch in einem funktionalen WrapperEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) - Ein Typ, der entweder das Ergebnis oder eine Beschreibung des Fehlers enthältValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - Ein Typ aus der Cats-Bibliothek , der im Fehlerfall mehrere Meldungen zu verschiedenen Fehlern enthalten kann (dort wird nicht ganz List verwendet, aber das spielt keine Rolle).
HINWEIS Im Wesentlichen werden Ausnahmen mit der Stapelverfolgung ohne und ADT verglichen, es werden jedoch mehrere Typen ausgewählt, da Scala keinen einzigen Ansatz hat und es interessant ist, mehrere zu vergleichen.
Zusätzlich zu Ausnahmen werden Zeichenfolgen verwendet, um Fehler zu beschreiben, aber mit dem gleichen Erfolg in einer realen Situation würden verschiedene Klassen verwendet ( Either[Failure, T] ).
Das Problem
Zum Testen der Fehlerbehandlung nehmen wir das Problem der Analyse und Datenvalidierung:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
d.h. Mit Rohdaten Map[String, String] müssen Sie Person oder einen Fehler erhalten, wenn die Daten ungültig sind.
Werfen
Eine Lösung für die Stirn mit Ausnahmen (im Folgenden werde ich nur die person , Sie können den vollständigen Code auf Github sehen ):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
Hier validieren string , integer und boolean das Vorhandensein und Format einfacher Typen und führen die Konvertierung durch.
Im Allgemeinen ist es ganz einfach und klar.
ThrowNST (No Stack Trace)
Der Code ist der gleiche wie im vorherigen Fall, jedoch werden Ausnahmen nach Möglichkeit ohne Stack-Trace verwendet: ThrowNSTParser.scala
Versuchen Sie es
Die Lösung fängt Ausnahmen früher ab und ermöglicht das Kombinieren der Ergebnisse über for (nicht zu verwechseln mit Schleifen in anderen Sprachen):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
etwas ungewöhnlicher für ein zerbrechliches Auge, aber aufgrund der Verwendung von for ist es der Version mit Ausnahmen sehr ähnlich. Außerdem erfolgt die Validierung des Vorhandenseins eines Feldes und das Parsen des gewünschten Typs separat ( flatMap kann hier ab and then zu gelesen werden).
Entweder
Hier ist der Typ "Beide" hinter dem Alias " Result verborgen, da der Fehlertyp behoben ist:
EntwederParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
Da der Standard Either wie Try in Scala eine Monade bildet, wurde der Code genau gleich ausgegeben. Der Unterschied besteht darin, dass die Zeichenfolge hier als Fehler angezeigt wird und die Ausnahmen nur minimal verwendet werden (nur um Fehler beim Parsen einer Zahl zu behandeln).
Validiert
Hier wird die Cats-Bibliothek verwendet, um nicht das erste zu erhalten, was passiert ist, sondern so viel wie möglich (wenn beispielsweise mehrere Felder nicht gültig waren, enthält das Ergebnis Analysefehler für alle diese Felder).
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
Dieser Code ist mit Ausnahmen der Originalversion bereits weniger ähnlich, aber die Überprüfung zusätzlicher Einschränkungen ist nicht von der Analyse von Feldern getrennt, und es werden immer noch mehrere Fehler anstelle von einem angezeigt. Es lohnt sich!
Testen
Zum Testen wurde ein Datensatz mit einem unterschiedlichen Prozentsatz an Fehlern generiert und auf jede der Arten analysiert.
Ergebnis bei allen Prozentsätzen der Fehler:

Genauer gesagt, bei einem geringen Prozentsatz an Fehlern (die Zeit ist hier anders, da eine größere Stichprobe verwendet wurde):
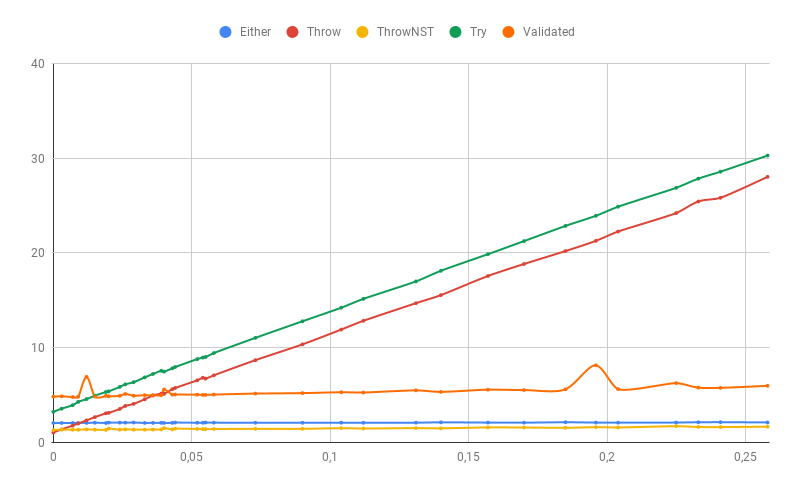
Wenn ein Teil der Fehler immer noch eine Ausnahme bei der Stapelverfolgung darstellt (in unserem Fall ist der Fehler beim Parsen der Nummer eine Ausnahme, die wir nicht kontrollieren), wird sich die Leistung der "schnellen" Fehlerbehandlungsmethoden natürlich erheblich verschlechtern. Validated besonders betroffen, da es alle Fehler sammelt und daher mehr als andere eine langsame Ausnahme erhält:

Schlussfolgerungen
Wie das Experiment gezeigt hat, sind Ausnahmen mit Stapelspuren sehr langsam (100% Fehler sind der Unterschied zwischen Throw und Either mehr als 50 Mal!). Und wenn es praktisch keine Ausnahmen gibt, hat die Verwendung von ADT seinen Preis. Die Verwendung von Ausnahmen ohne Stack-Traces ist jedoch genauso schnell (und mit einem geringen Prozentsatz an Fehlern schneller) wie ADT. Wenn solche Ausnahmen jedoch die Grenzen derselben Validierung überschreiten, ist die Verfolgung ihrer Quelle nicht einfach.
Wenn die Wahrscheinlichkeit einer Ausnahme mehr als 1% beträgt, funktionieren Ausnahmen ohne Stack-Traces insgesamt am schnellsten. Validated oder regelmäßig. Either fast genauso schnell. Bei einer großen Anzahl von Fehlern kann Either nur aufgrund der ausfallsicheren Semantik etwas schneller als Validated .
Die Verwendung von ADT zur Fehlerbehandlung bietet einen weiteren Vorteil gegenüber Ausnahmen: Die Möglichkeit eines Fehlers ist mit dem Typ selbst verbunden und es ist schwieriger zu übersehen, als wenn Option anstelle von Nullen verwendet wird.