Problem
Fast jedes Informationssystem benötigt eine fortlaufende Datenspeicherung. In den meisten Systemen mit kleiner und mittlerer Last wird diese Funktion von relationalen DBMS ausgeführt, deren unbestreitbarer Vorteil die Garantie der Datenkonsistenz ist.
Ein klassisches Beispiel, das erklärt, was Datenkonsistenz ist - das Überweisen von Geldern von einem Konto auf ein anderes. In dem Moment, in dem die Änderung des Kontostands eines Kontos bereits abgeschlossen ist und das andere noch keine Zeit hatte, kann ein Fehler auftreten. Dann wird das Geld von einem Konto abgebucht, aber nicht einem anderen gutgeschrieben. Dieser Zustand der Systemdaten wird als inkonsistent bezeichnet, und es besteht möglicherweise keine Notwendigkeit zu erklären, zu welchen Konsequenzen dies führen kann. Relationale DBMS bieten einen Transaktionsmechanismus, der jederzeit Datenkonsistenz garantiert. Eine Transaktion ist eine endliche Menge von Operationen, die einen konsistenten Zustand in einen anderen konsistenten Zustand übertragen.
Im Falle eines Fehlers bei einem Schritt bricht das DBMS alle zuvor ausgeführten Vorgänge ab und bringt die Daten in den ursprünglich vereinbarten Zustand zurück. Mit anderen Worten, entweder werden alle Operationen ausgeführt oder keine einzige.
Bei großen Systemen ist es aufgrund der zu hohen Last bei weitem nicht immer möglich, eine einzige Datenbank in ihnen zu verwenden. In solchen Fällen wird jedem Systemmodul (Dienst) eine eigene Datenbank zur Verfügung gestellt. In diesem Fall stellt sich die Frage, wie die Datenkonsistenz für eine solche Clusterarchitektur sichergestellt werden kann.
Datenkonsistenz lösen
Eine Lösung sind verteilte Transaktionen. Zuerst müssen alle Knoten des Clusters zustimmen, dass die Operation möglich ist, dann werden die Änderungen an alle Knoten übergeben. Da die Knoten kein gemeinsames Speichergerät haben, besteht die einzige Möglichkeit, zu einer gemeinsamen Meinung zu gelangen, darin, sich auf ein verteiltes Konsensprotokoll zu einigen.
Ein einfaches Protokoll zum Erfassen globaler Transaktionen ist das Two-Phase-Commit (2PC). Der Knoten, der die Transaktion ausführt, wird als Koordinator betrachtet. In der Vorbereitungsphase (Vorbereitung) informiert der Koordinator die anderen Knoten über das Transaktions-Commit und wartet auf die Bestätigung von ihnen, dass sie zum Commit bereit sind. Wenn mindestens ein Knoten nicht bereit ist, wird die Transaktion unterbrochen. In der Festschreibungsphase informiert der Koordinator alle Knoten über die Entscheidung, die Transaktion festzuschreiben. Nach Erhalt der Bestätigung von allen, dass alles in Ordnung ist, erfasst der Koordinator auch die Transaktion.

Abbildung 1 - Allgemeines Schema eines Zwei-Phasen-Commits
Dieses Protokoll vermeidet ein Minimum an Nachrichten, ist jedoch nicht robust. Wenn der Koordinator beispielsweise nach der Vorbereitungsphase ausfällt, haben die verbleibenden Knoten keine Informationen darüber, ob die Transaktion festgeschrieben oder abgebrochen werden soll (sie müssen warten, bis der Fehler behoben ist). Ein weiterer schwerwiegender Nachteil von 2PC (und anderen verteilten Transaktionsprotokollen, z. B. 3PC) besteht darin, dass mit zunehmender Anzahl von Clusterknoten die Leistung von zweiphasigen Commits abnimmt.

Abbildung 2 - Abhängigkeit der Geschwindigkeit eines Zwei-Basen-Commits von der Anzahl der Server in einem DBMS-Cluster
Darüber hinaus unterliegt der verteilte Transaktionsansatz einer Einschränkung: Alle Module des Systems müssen dasselbe DBMS verwenden, was nicht immer praktisch ist.
Eine weitere Option besteht darin, einen Mechanismus bereitzustellen, mit dem Sie mit verschiedenen Datenbanken (für Dienste) als einzelne Datenbank arbeiten können (um das Problem mit der Datenintegrität in einer verteilten Datenbank zu lösen). Gleichzeitig ist ein bestimmtes Analogon einer Transaktion für ein verteiltes System („Geschäftstransaktion“) erforderlich.
Bei normalen Transaktionen sowie bei zweiphasigen Festschreibungen werden alle Vorgänge vom Transaktionsmechanismus gesteuert (unter Verwendung von Sperren). Dies geschieht, um die Möglichkeit zu bieten, jeden Vorgang zurückzusetzen (pessimistischer Ansatz - wir betrachten jeden Vorgang als potenziell fehlerhaft). Dies ist der Engpass des Systems. Eine Alternative ist der sogenannte optimistische Ansatz: Wir glauben, dass die meisten Operationen erfolgreich abgeschlossen werden. Wir führen auch zusätzliche Maßnahmen durch, wenn ein Fehler vorliegt. Das heißt, Reduzierung der Kosten für die meisten Vorgänge, was zu einer Steigerung der Produktivität führt.
Was ist eine Saga und wie funktioniert sie?
Eine Alternative zu Transaktionen für die Microservice-Architektur ist Saga. Saga (Saga) ist eine Reihe von Schritten, die von verschiedenen Modulen des Systems (Dienste) ausgeführt werden. Außerdem ist der Saga-Service erforderlich, der für den gesamten Betrieb (Geschäftsvorgang) verantwortlich ist. Schritte werden durch ein Ereignisdiagramm verknüpft. Nach Abschluss der Saga muss das System von einem vereinbarten Zustand in einen anderen wechseln (bei erfolgreicher Ausführung) oder zum vorherigen vereinbarten Zustand zurückkehren (im Falle einer Stornierung).
Wie kann eine solche Rückgabe oder ein Rollback eines Geschäftsvorfalls implementiert werden? Zu diesem Zweck verwendet die Saga den Mechanismus der Aufhebung von Schritten (Ausgleichsmaßnahmen). Beispielsweise war einer der Schritte erfolgreich (z. B. wurde der Benutzerdatenbanktabelle ein Eintrag hinzugefügt), aber einer der folgenden Schritte schlug fehl und die gesamte Saga sollte abgebrochen werden. Dann erhält derselbe Dienst einen Befehl - brechen Sie die Aktion ab. Im Service-DBMS wurde die lokale Transaktion jedoch bereits abgeschlossen und der Benutzerdatensatz hinzugefügt. Um zum vorherigen Status zurückzukehren, muss der Dienst eine Ausgleichsaktion ausführen (in unserem Beispiel löschen Sie den Datensatz). Durch die Aufhebung von Schritten kann die Atomizität („alles oder nichts“) im Rahmen der Saga implementiert werden - alle Schritte werden ausgeführt oder kompensiert.
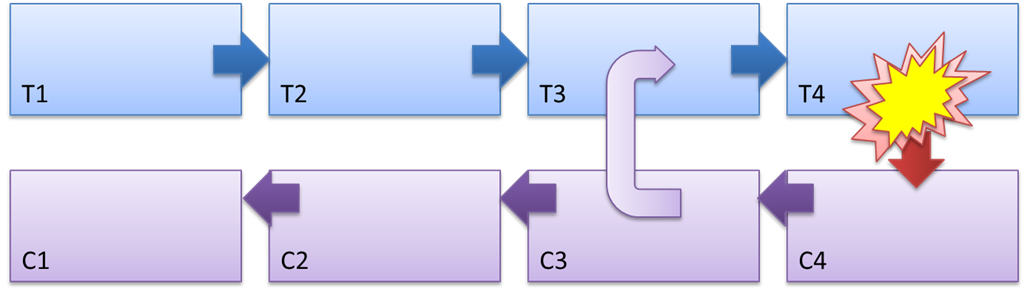
Abbildung 3 - Der Arbeitsmechanismus von Saga und die Art des Ausgleichseffekts
In Abbildung 3 sind die Schritte der Saga als T1 ... T4 bezeichnet, wobei die Aktionen kompensiert werden: C1 ... C4.
Sagas unterstützen die Idempotenz von Schritten (eine Aktion, deren wiederholte Wiederholung einer einzelnen entspricht). Der Sag-Ansatz bietet die Möglichkeit, einen beliebigen Schritt zu wiederholen (z. B. wenn Sie nach erfolgreichem Abschluss keine Antwort erhalten haben). Mit Idempotenz können Sie auch den Status wiederherstellen, wenn Daten auf einem Knoten verloren gehen (Fehler und Wiederherstellung). Bei der Ausführung eines Schritts sollte jeder Dienst (anhand des Idempotenzschlüssels) bestimmen, ob er diesen Schritt bereits ausgeführt hat oder nicht (falls nicht, ausführen, andernfalls überspringen). Zur Kompensation von Aktionen können auch Idempotenzschlüssel und Wiederholungen von Vorgängen hinzugefügt werden (um Persistenz / Stabilität zu gewährleisten).
Zusammenfassung
Von den vier Anforderungen für das ACID-Transaktionssystem (Atomizität, Konsistenz, Isolation, Stabilität) ermöglicht der Durchhangmechanismus die Implementierung von drei - alle außer Isolation. Mangelnde Isolation kann zu Anomalien führen ("Dirty Reads", "nicht wiederholbare Lesevorgänge", Umschreiben von Änderungen zwischen verschiedenen Geschäftsvorfällen usw.). Um solche Situationen zu überwinden, müssen zusätzliche Mechanismen verwendet werden, beispielsweise die Versionierung veränderlicher Objekte.
Mit Sagas können Sie die folgenden Aufgaben lösen:
- Bereitstellung abhängiger Datenänderungen für geschäftskritische Daten;
- In der Lage sein, eine strikte Reihenfolge der Schritte festzulegen;
- 100% ige Konsistenz einhalten (Daten auch bei Unfällen koordinieren);
- Stellen Sie Leistungsprüfungen auf allen Ebenen bereit.
Anwendungsbereich und Anwendungsbeispiele
Sagas werden häufig auf Systemen mit einer großen Anzahl von Anforderungen verwendet. Zum Beispiel beliebte E-Mail-Dienste, soziale Netzwerke. Der Ansatz kann jedoch in kleineren Projekten Anwendung finden.
Unser Unternehmen hat Erfahrung in der Entwicklung eines Buchhaltungssystems für ein großes Unternehmen, das für mehrere Dutzend Benutzer konzipiert wurde und in dem alle Daten in einem relationalen DBMS gespeichert wurden. Das Problem trat bei der Implementierung der automatischen Berechnung der geplanten Arbeit auf: In einigen Fällen waren die Berechnungen sehr umfangreich und erforderten das Einfügen von Millionen von Datensätzen in die DBMS-Tabellen, wodurch das DBMS erheblich belastet und der Betrieb des gesamten Systems verlangsamt wurde.
Es wurde eine Lösung gefunden - die Arbeitsberechnungslogik in einen separaten Dienst mit einem eigenen DBMS zu stellen, um die Arbeit selbst und verwandte Objekte zu speichern. Die Datenkonsistenz wurde durch die Saga sichergestellt. Wenn die Berechnung fehlgeschlagen ist, hat das Hauptmodul der Anwendung einen Befehl zum Abbrechen der logischen Berechnungsoperation erhalten.
Saga-fähige Bibliotheken
Die Anwendung wurde auf .Net entwickelt, und für diese Technologie gibt es mehrere Service Manager-Bibliotheken mit Unterstützung für Sagen. Wir haben uns die Bibliotheken NServiceBus, MassTransit und Rebus angesehen. Infolgedessen haben wir uns für Rebus entschieden - diese Bibliothek ist leichter zu erlernen, während das Prinzip der Sagen vollständig verwirklicht wird und kostenlos verwendet werden kann. NServiceBus und MassTransit sind anspruchsvollere Tools mit unzähligen zusätzlichen Funktionen. Sie wurden im Rahmen unserer Aufgabe nicht benötigt, es kann jedoch ratsam sein, sie in zukünftigen Projekten mit komplexerer Logik zu verwenden.