Eine der unauffälligen, aber wichtigen Funktionen
unserer Anzeigenseiten ist das Speichern und Anzeigen der Anzahl ihrer Aufrufe. Unsere Websites verfolgen seit über 10 Jahren Anzeigenaufrufe. Die technische Implementierung der Funktionalität hat sich in dieser Zeit mehrmals geändert. Jetzt handelt es sich um einen (Mikro-) Dienst für unterwegs, der mit Redis als Cache- und Task-Warteschlange und mit MongoDB als persistentem Speicher arbeitet. Vor einigen Jahren lernte er, nicht nur mit der Summe der Anzeigenansichten, sondern auch mit Statistiken für jeden Tag zu arbeiten. Aber das alles hat er erst vor kurzem sehr schnell und zuverlässig gelernt.

Insgesamt verarbeitet der Dienst ~ 300.000 Leseanforderungen und ~ 9.000 Schreibanforderungen pro Minute, von denen 99% bis zu 5 ms ausgeführt werden. Dies sind natürlich keine astronomischen Indikatoren und kein Raketenstart auf dem Mars - aber auch keine so triviale Aufgabe, wie es eine einfache Speicherung von Zahlen erscheinen mag. Es stellte sich heraus, dass all dies, um eine verlustfreie Datenspeicherung sicherzustellen und konsistente, relevante Werte zu lesen, einige Anstrengungen erfordert, die wir weiter unten diskutieren werden.
Projektaufgaben und Übersicht
Obwohl Ansichtszähler für das Geschäft nicht so wichtig sind wie beispielsweise die Verarbeitung von Zahlungen oder
Kreditanträgen , sind sie für unsere Benutzer in erster
Linie wichtig. Die Leute sind fasziniert davon, die Popularität ihrer Anzeigen zu verfolgen: Einige rufen sogar den Support an, wenn sie ungenaue Anzeigeinformationen bemerken (dies geschah bei einer der vorherigen Service-Implementierungen). Darüber hinaus speichern und zeigen wir detaillierte Statistiken in den persönlichen Konten der Benutzer an (um beispielsweise die Effektivität der Nutzung kostenpflichtiger Dienste zu bewerten). All dies sorgt dafür, dass jedes Anzeigeereignis gespeichert und die relevantesten Werte angezeigt werden.
Im Allgemeinen sehen die Funktionalität und die Prinzipien des Projekts folgendermaßen aus:
- Die Webseite oder der Anwendungsbildschirm stellen eine Anfrage hinter den Anzeigenanzeigezählern (die Anfrage ist normalerweise asynchron, um die Ausgabe grundlegender Informationen zu priorisieren). Wenn die Seite der Anzeige selbst angezeigt wird, fordert der Kunde Sie stattdessen auf, die aktualisierte Anzahl der Aufrufe zu erhöhen und zurückzugeben.
- Durch die Verarbeitung von Leseanforderungen versucht der Dienst, Informationen aus dem Redis-Cache abzurufen, und ergänzt das Unbekannte, indem er eine Anforderung an MongoDB abschließt.
- Schreibanforderungen werden an zwei Strukturen im Rettich gesendet: die inkrementelle Aktualisierungswarteschlange (asynchron im Hintergrund verarbeitet) und den Cache der Gesamtzahl der Ansichten.
- Ein Hintergrundprozess im selben Dienst liest Elemente aus der Warteschlange, sammelt sie im lokalen Puffer und schreibt sie regelmäßig in MongoDB.
Record View Counters: Fallstricke
Obwohl die oben beschriebenen Schritte recht einfach aussehen, besteht das Problem hier in der Organisation der Interaktion zwischen der Datenbank und den Microservice-Instanzen, damit die Daten nicht verloren gehen, nicht dupliziert werden und nicht verzögert werden.
Die Verwendung nur eines Repositorys (z. B. nur MongoDB) würde einige dieser Probleme lösen. Tatsächlich funktionierte der Service früher, bis wir auf die Probleme der Skalierung, Stabilität und Geschwindigkeit stießen.
Eine naive Implementierung des Verschiebens von Daten zwischen Speichern könnte beispielsweise zu solchen Anomalien führen:
- Datenverlust beim kompetitiven Schreiben in den Cache:
- Prozess A erhöht die Anzahl der Ansichten im Redis-Cache, stellt jedoch fest, dass für diese Entität noch keine Daten vorhanden sind (es kann sich entweder um eine neue oder eine alte Deklaration handeln, die aus dem Cache extrudiert wurde). Daher muss der Prozess diesen Wert zuerst von MongoDB abrufen.
- Prozess A erhält die Anzahl der Ansichten von MongoDB - zum Beispiel die Nummer 5; fügt dann 1 hinzu und schreibt an Redis 6 .
- Prozess B (beispielsweise von einem anderen Benutzer der Website initiiert, der ebenfalls dieselbe Anzeige eingegeben hat) führt gleichzeitig dasselbe aus.
- Prozess A schreibt einen Wert von 6 in Redis.
- Prozess B schreibt einen Wert von 6 in Redis.
- Infolgedessen geht beim Aufzeichnen von Daten eine Ansicht aufgrund des Rennens verloren.
Das Szenario ist nicht so unwahrscheinlich: Wir haben beispielsweise einen kostenpflichtigen Dienst, der eine Anzeige auf der Hauptseite der Website platziert. Bei einer neuen Ankündigung kann ein solcher Ablauf dazu führen, dass aufgrund ihres plötzlichen Zustroms viele Ansichten gleichzeitig verloren gehen.
- Ein Beispiel für ein anderes Szenario ist der Datenverlust beim Verschieben von Ansichten von Redis nach MongoDb:
- Der Prozess nimmt einen ausstehenden Wert von Redis auf und speichert ihn im Speicher, um später in MongoDB zu schreiben.
- Eine Schreibanforderung schlägt fehl (oder der Prozess stürzt ab, bevor er ausgeführt wird).
- Die Daten gehen wieder verloren, was beim nächsten Herausgeben des zwischengespeicherten Werts und Ersetzen durch den Wert aus der Datenbank deutlich wird.
Andere Fehler können auftreten, deren Gründe auch in der nichtatomaren Natur von Operationen zwischen Datenbanken liegen, z. B. ein Konflikt beim Löschen und Erhöhen von Ansichten derselben Entität.
Anzahl der Aufzeichnungsansichten: Lösung
Unser Ansatz zum Speichern und Verarbeiten von Daten in diesem Projekt basiert auf der Erwartung, dass MongoDB zu jedem Zeitpunkt wahrscheinlicher ausfällt als Redis. Dies ist natürlich keine absolute
Regel - zumindest nicht für jedes Projekt -, aber in unserer Umgebung sind wir es gewohnt, periodische Zeitüberschreitungen für Abfragen in MongoDB zu beobachten, die durch die Ausführung von Festplattenoperationen verursacht werden, was zuvor einer der Gründe für den Verlust einiger Ereignisse war.
Um viele der oben genannten Probleme zu vermeiden, verwenden wir Task-Warteschlangen für verzögertes Speichern und Lua-Skripte, die es ermöglichen, Daten in mehreren Rettichstrukturen gleichzeitig atomar zu ändern. In diesem Sinne lauten die Details zum Speichern von Ansichten wie folgt:
- Wenn eine Schreibanforderung in den Microservice fällt, wird das Lua-Skript IncrementIfExists ausgeführt , um den Zähler nur dann zu erhöhen, wenn er bereits im Cache vorhanden ist. Das Skript gibt sofort -1 zurück, wenn keine Daten für die Entität vorhanden sind, die im Rettich angezeigt wird. Andernfalls wird der Wert der Ansichten im Cache über HINCRBY erhöht , das Ereignis zur Warteschlange für die nachfolgende Speicherung in MongoDB ( von uns als ausstehende Warteschlange bezeichnet ) über LPUSH hinzugefügt und die aktualisierte Anzahl von Ansichten zurückgegeben.
- Wenn IncrementIfExists eine positive Zahl zurückgibt, wird dieser Wert an den Client zurückgegeben und die Anforderung endet.
Andernfalls nimmt der Microservice den Ansichtszähler von MongoDb auf, erhöht ihn um 1 und sendet ihn an den Rettich.
- Das Schreiben auf den Rettich erfolgt über ein anderes Lua-Skript - Upsert -, das die Gesamtzahl der Ansichten im Cache speichert, wenn dieser noch leer ist, oder um 1 erhöht, wenn jemand anderes es geschafft hat, den Cache zwischen den Schritten 1 und 3 zu füllen.
- Upsert fügt der ausstehenden Warteschlange auch ein Ansichtsereignis hinzu und gibt einen aktualisierten Betrag zurück, der dann an den Client gesendet wird.
Aufgrund der Tatsache, dass Lua-Skripte
atomar ausgeführt werden , vermeiden wir viele potenzielle Probleme, die durch ein wettbewerbsfähiges Schreiben verursacht werden könnten.
Ein weiteres wichtiges Detail ist die sichere Übertragung von Updates aus der ausstehenden Warteschlange an MongoDB. Zu diesem Zweck haben wir die in der
Redis-Dokumentation beschriebene Vorlage "Zuverlässige Warteschlange" verwendet, die das Risiko eines Datenverlusts erheblich verringert, indem eine Kopie der verarbeiteten Elemente in einer separaten, anderen Warteschlange erstellt wird, bis sie schließlich in einem dauerhaften Speicher gespeichert werden.
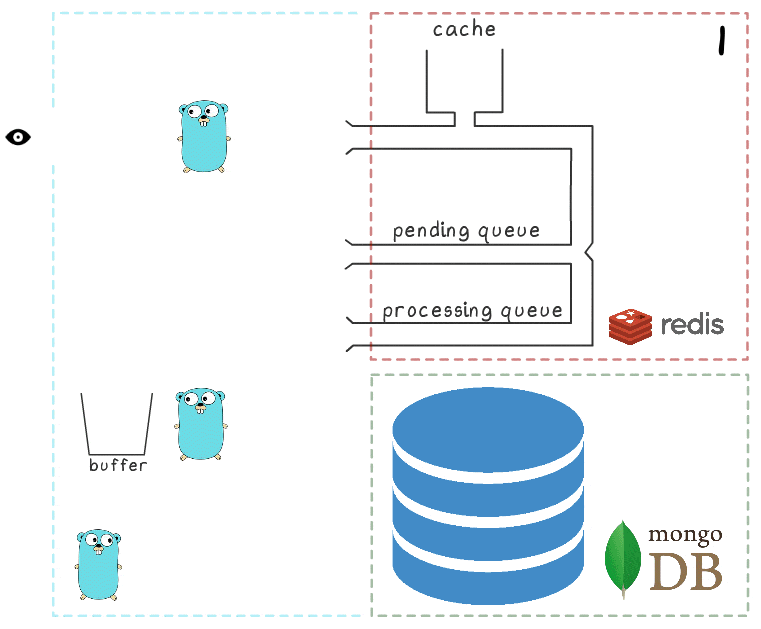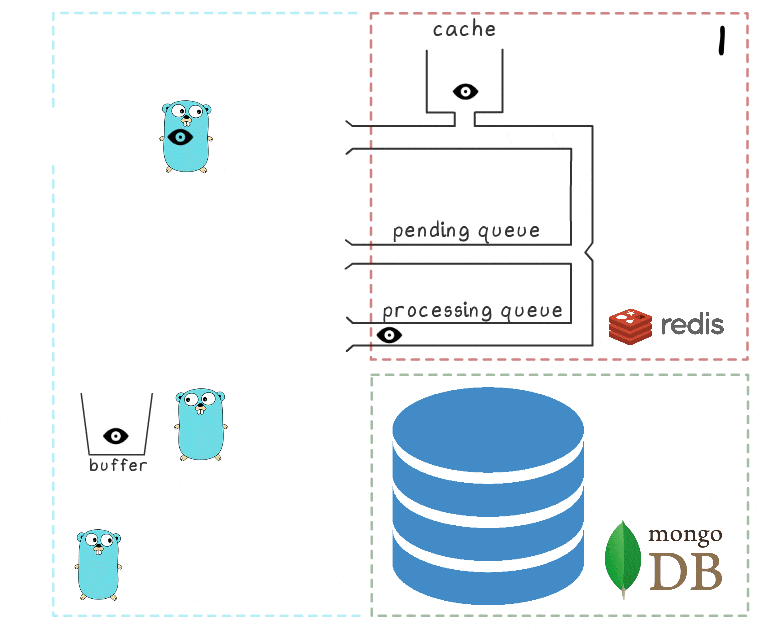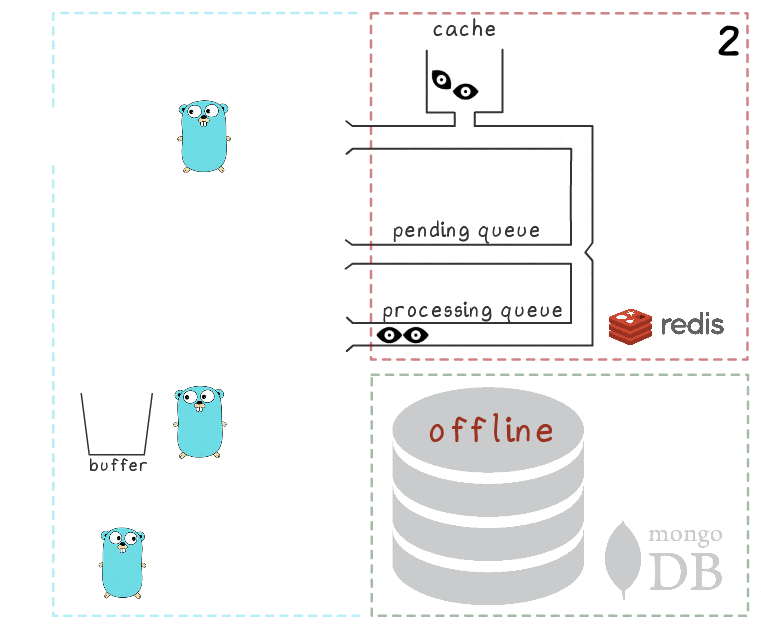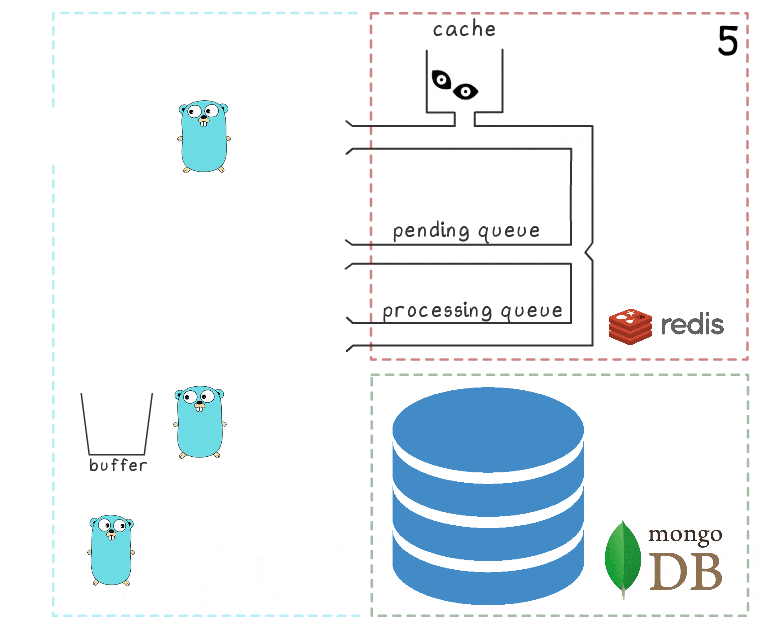
Um die gesamten Prozessschritte besser zu verstehen, haben wir eine kleine Visualisierung vorbereitet. Schauen wir uns zunächst ein normales, erfolgreiches Szenario an (die Schritte sind in der oberen rechten Ecke nummeriert und werden im Folgenden ausführlich beschrieben):
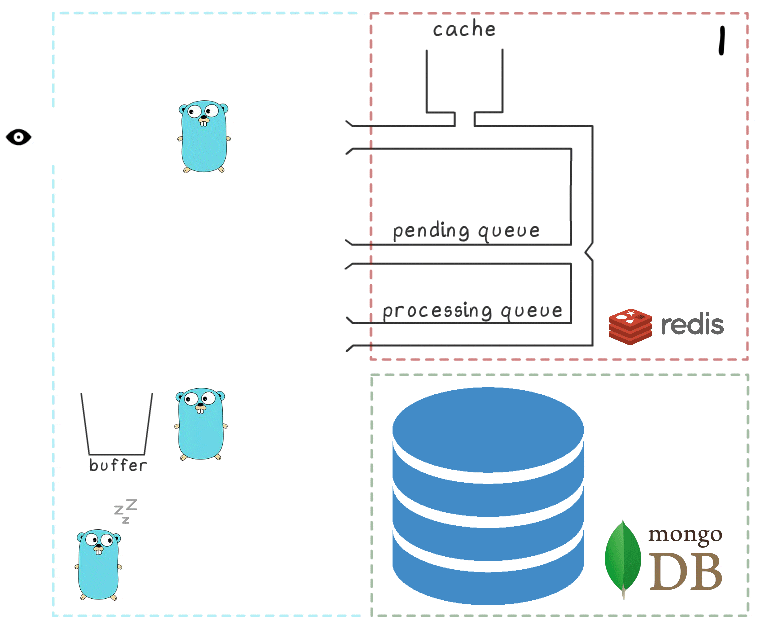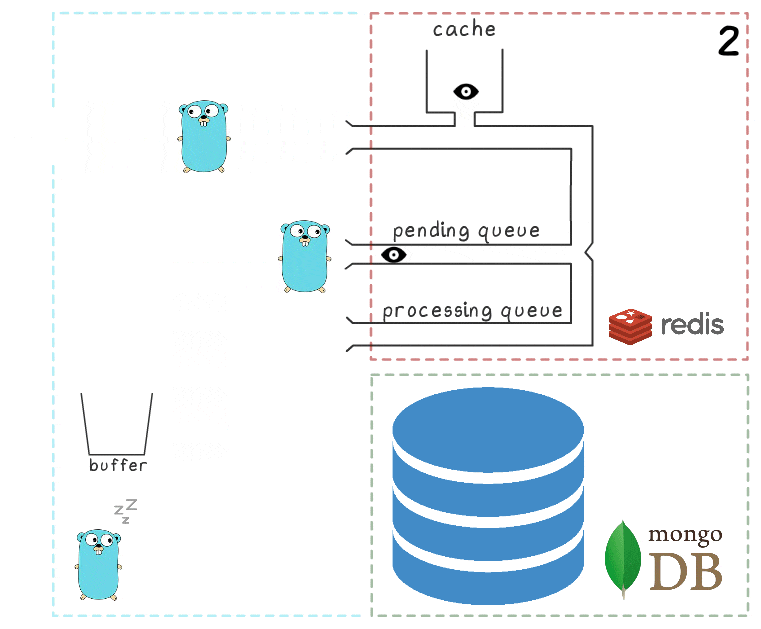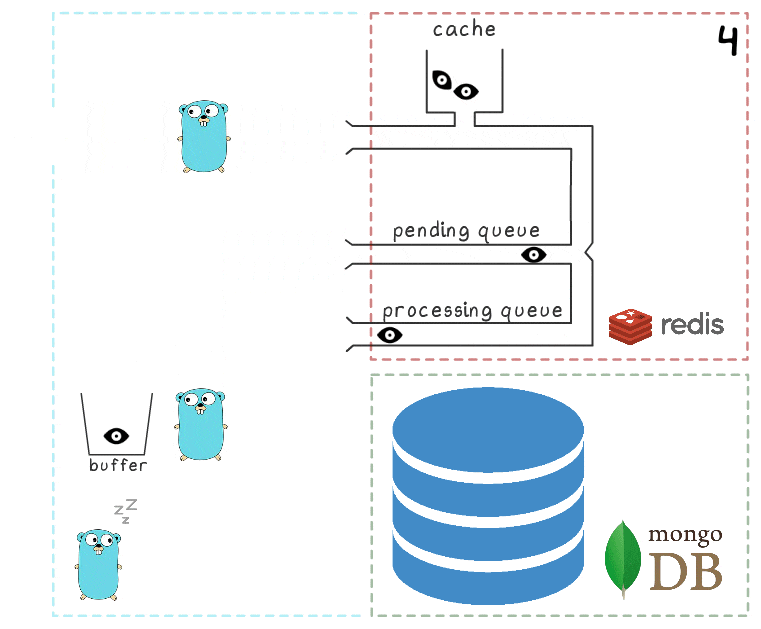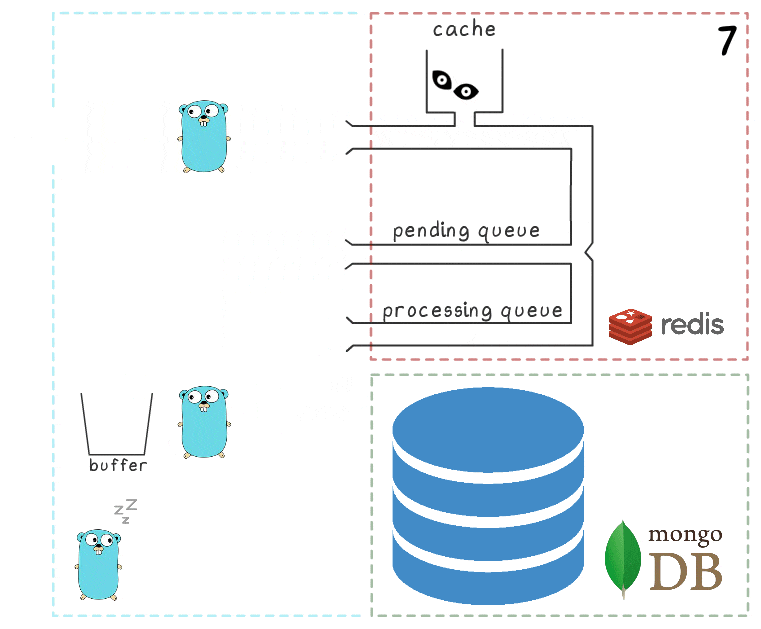
- Der Microservice erhält eine Schreibanforderung
- Der Request-Handler übergibt es an ein Lua-Skript, das die Suche in den Cache schreibt (um sie sofort lesbar zu machen) und zur weiteren Verarbeitung in die Warteschlange.
- Die Hintergrund-Goroutine führt (periodisch) die BRPopLPush- Operation aus, bei der ein Element atomar von einer Warteschlange in eine andere verschoben wird (wir nennen es "Verarbeitungswarteschlange" - eine Warteschlange mit aktuell verarbeiteten Elementen). Das gleiche Element wird dann in einem Puffer im Prozessspeicher gespeichert.
- Eine weitere Schreibanforderung kommt an und wird verarbeitet, sodass 2 Elemente im Puffer und 2 Elemente in der Verarbeitungswarteschlange verbleiben.
- Nach einiger Zeit entscheidet der Hintergrundprozess, den Puffer in MongoDB zu leeren. Das Schreiben mehrerer Werte aus dem Puffer wird von einer einzelnen Anforderung ausgeführt, was sich positiv auf den Durchsatz auswirkt. Außerdem versucht der Prozess vor der Aufzeichnung, mehrere Ansichten zu einer zusammenzufassen und deren Werte für dieselben Anzeigen zusammenzufassen.
In jedem unserer Projekte werden 3 Microservice-Instanzen mit jeweils einem eigenen Puffer verwendet, der alle 2 Sekunden in der Datenbank gespeichert wird. Während dieser Zeit werden ungefähr 100 Elemente in einem Puffer akkumuliert.
- Nach einem erfolgreichen Schreibvorgang entfernt der Prozess Elemente aus der Verarbeitungswarteschlange und signalisiert, dass die Verarbeitung erfolgreich abgeschlossen wurde.
Wenn alle Subsysteme in Ordnung sind, scheinen einige dieser Schritte redundant zu sein. Und der aufmerksame Leser hat möglicherweise auch eine Frage dazu, was der Gopher in der unteren linken Ecke tut.
Alles wird erklärt, wenn man das Szenario betrachtet, in dem MongoDB nicht verfügbar ist:
- Der erste Schritt ist identisch mit den Ereignissen aus dem vorherigen Szenario: Der Dienst empfängt zwei Anforderungen zum Aufzeichnen und Verarbeiten von Ansichten.
- Der Prozess verliert die Verbindung zu MongoDB (der Prozess selbst weiß dies natürlich noch nicht).
Der Gorutin-Handler versucht nach wie vor, seinen Puffer in die Datenbank zu leeren - diesmal jedoch ohne Erfolg. Sie wartet wieder auf die nächste Iteration.
- Eine andere Hintergrund-Goroutine wacht auf und überprüft die Verarbeitungswarteschlange. Sie entdeckt, dass die Elemente ihr vor langer Zeit hinzugefügt wurden; Als sie zu dem Schluss kommt, dass ihre Verarbeitung fehlgeschlagen ist, verschiebt sie sie zurück in die ausstehende Warteschlange.
- Nach einer Weile wird die Verbindung mit MongoDB wiederhergestellt.
- Die erste Hintergrund-Goroutine versucht erneut, eine Schreiboperation auszuführen - diesmal erfolgreich - und entfernt schließlich Elemente dauerhaft aus der Verarbeitungswarteschlange.
In diesem Schema gibt es mehrere wichtige Zeitüberschreitungen und Heuristiken, die durch Tests und gesunden Menschenverstand abgeleitet wurden: Beispielsweise werden Elemente nach 15 Minuten Inaktivität von der Verarbeitungswarteschlange zurück in die ausstehende Warteschlange verschoben. Darüber hinaus führt die für diese Aufgabe verantwortliche Goroutine vor der Ausführung eine
Sperre durch, damit mehrere Instanzen des Mikrodienstes nicht gleichzeitig versuchen, die "eingefrorenen" Ansichten wiederherzustellen.
Genau genommen bieten selbst diese Maßnahmen keine theoretisch fundierten Garantien (zum Beispiel ignorieren wir Szenarien wie das Einfrieren des Prozesses für 15 Minuten) - aber in der Praxis funktioniert dies recht zuverlässig.
Auch in diesem Schema sind uns mindestens zwei weitere Sicherheitslücken bekannt, deren Kenntnis wichtig ist:
- Wenn der Microservice unmittelbar nach dem erfolgreichen Speichern in MongoDb, jedoch vor dem Löschen der Verarbeitungswarteschlangenliste abgestürzt ist, werden diese Daten als nicht gespeichert betrachtet und nach 15 Minuten erneut gespeichert.
Um die Wahrscheinlichkeit eines solchen Szenarios zu verringern, haben wir wiederholt versucht, bei Fehlern aus der Verarbeitungswarteschlange zu entfernen. In der Realität haben wir solche Fälle in der Produktion noch nicht beobachtet.
- Beim Neustart kann der Rettich nicht nur den Cache verlieren, sondern auch einige nicht gespeicherte Ansichten aus den Warteschlangen, da er so konfiguriert ist, dass RDB-Snapshots regelmäßig alle paar Minuten gespeichert werden.
Obwohl dies theoretisch ein ernstes Problem sein kann (insbesondere wenn sich das Projekt mit wirklich kritischen Daten befasst), werden Knoten in der Praxis äußerst selten neu gestartet. Gleichzeitig verbringen Elemente laut Überwachung weniger als 3 Sekunden in Warteschlangen, dh die möglichen Verluste sind sehr begrenzt.
Es scheint, dass es mehr Probleme gibt, als wir möchten. Tatsächlich stellt sich jedoch heraus, dass das Szenario, gegen das wir uns ursprünglich verteidigt haben - das Scheitern von MongoDB - tatsächlich eine viel realere Bedrohung darstellt und das neue Datenverarbeitungsschema die Verfügbarkeit des Dienstes erfolgreich sicherstellt und Verluste verhindert.
Ein anschauliches Beispiel dafür war, als die MongoDB-Instanz bei einem der Projekte die ganze Nacht über absurd nicht verfügbar war. Während dieser ganzen Zeit sammelten sich die Anzahl der Ansichten und drehten sich im Rettich von einer Warteschlange zur nächsten, bis sie nach Behebung des Vorfalls schließlich in der Datenbank gespeichert wurden. Die meisten Benutzer haben den Fehler nicht einmal bemerkt.
Leseansicht zählt
Leseanforderungen sind viel einfacher als Schreibanforderungen: Der Microservice überprüft zuerst den Cache im Rettich. Alles, was nicht im Cache gefunden wird, wird mit Daten aus MongoDb gefüllt und an den Client zurückgegeben.
Während der Lesevorgänge wird nicht durchgehend in den Cache geschrieben, um den Aufwand für den Schutz vor wettbewerbsfähigen Schreibvorgängen zu vermeiden. Die Trefferquote des Caches bleibt gut, da er häufig dank anderer Schreibanforderungen bereits aufgewärmt wird.
Tägliche Ansichtsstatistiken werden direkt aus MongoDB gelesen, da sie viel seltener angefordert werden und das Zwischenspeichern schwieriger ist. Dies bedeutet auch, dass das Lesen von Statistiken nicht mehr funktioniert, wenn die Datenbank nicht verfügbar ist. Es betrifft jedoch nur einen kleinen Teil der Benutzer.
MongoDB-Datenspeicherungsschema
Das MongoDB-Erfassungsschema für das Projekt basiert auf
diesen Empfehlungen der Datenbankentwickler selbst und sieht folgendermaßen aus:
- Ansichten werden in 2 Sammlungen gespeichert: in einer gibt es ihren Gesamtbetrag, in der anderen - Statistiken nach Tag.
- Die Daten in der Statistiksammlung basieren auf einem Dokument pro Anzeige und Monat . Bei neuen Ankündigungen wird ein Dokument mit einunddreißig Null für den aktuellen Monat in die Sammlung eingefügt. Gemäß dem oben genannten Artikel können Sie so sofort genügend Speicherplatz für ein Dokument auf der Festplatte zuweisen, sodass die Datenbank es beim Hinzufügen von Daten nicht verschieben muss.
Dieser Punkt macht das Lesen von Statistiken etwas umständlich (Anfragen müssen auf der Microservice-Seite monatelang generiert werden), aber insgesamt bleibt das Schema recht intuitiv.
- Die Upsert- Operation wird zum Aufzeichnen verwendet, um innerhalb derselben Anforderung ein Dokument für die gewünschte Entität zu aktualisieren und gegebenenfalls zu erstellen.
Wir verwenden die Transaktionsfunktionen von MongoDb nicht, um mehrere Sammlungen gleichzeitig zu aktualisieren. Dies bedeutet, dass wir das Risiko eingehen, dass die Daten nur in eine Sammlung geschrieben werden können. Vorerst melden wir uns einfach in solchen Fällen an; Es gibt nur wenige davon, und dies stellt bislang nicht das gleiche signifikante Problem dar wie andere Szenarien.
Testen
Ich würde meinen eigenen Worten nicht vertrauen, dass die beschriebenen Szenarien wirklich funktionieren, wenn sie nicht durch Tests abgedeckt würden.
Da der größte Teil des Projektcodes eng mit Radieschen und MongoDb zusammenarbeitet, handelt es sich bei den meisten darin enthaltenen Tests um Integrationstests. Die Testumgebung wird durch Docker-Compose unterstützt, was bedeutet, dass sie schnell bereitgestellt werden kann, Reproduzierbarkeit durch Zurücksetzen und Wiederherstellen des Status bei jedem Start bietet und das Experimentieren ermöglicht, ohne die Datenbanken anderer Personen zu beeinträchtigen.
In diesem Projekt gibt es drei Haupttestbereiche:
- Validierung der Geschäftslogik in typischen Szenarien, den sogenannten Glückspfad. Diese Tests beantworten die Frage: Wenn alle Subsysteme in Ordnung sind, funktioniert der Service gemäß den funktionalen Anforderungen?
- Überprüfen negativer Szenarien, in denen der Dienst voraussichtlich seine Arbeit fortsetzen wird. Verliert der Dienst beispielsweise wirklich keine Daten, wenn MongoDb abstürzt?
Sind wir sicher, dass die Informationen mit regelmäßigen Zeitüberschreitungen, Einfrierungen und wettbewerbsfähigen Aufzeichnungsvorgängen übereinstimmen? - Überprüfen Sie negative Szenarien, in denen wir nicht erwarten, dass der Dienst fortgesetzt wird, aber dennoch ein Mindestmaß an Funktionalität bereitgestellt werden sollte. Beispielsweise besteht keine Chance, dass der Dienst weiterhin Daten speichert und weitergibt, wenn weder Rettich noch Mongo verfügbar sind. Wir möchten jedoch sicherstellen, dass er in solchen Fällen nicht abstürzt, sondern eine Systemwiederherstellung erwartet und dann wieder funktioniert.
Um nach erfolglosen Szenarien zu suchen, arbeitet der Service Business Logic Code mit den Datenbank-Client-Schnittstellen, die in den erforderlichen Tests durch Implementierungen ersetzt werden, die Fehler zurückgeben und / oder Netzwerkverzögerungen simulieren. Wir simulieren auch den Parallelbetrieb mehrerer Dienstinstanzen mithilfe des Musters "
Umgebungsobjekt ". Dies ist eine Variante des bekannten "Control Inversion" -Ansatzes, bei dem Funktionen nicht auf die Abhängigkeiten selbst zugreifen, sondern sie über das in den Argumenten übergebene Umgebungsobjekt empfangen. Mit diesem Ansatz können Sie unter anderem mehrere unabhängige Kopien des Dienstes in einem Test simulieren, von denen jede über einen eigenen Pool von Verbindungen zur Datenbank verfügt und die Produktionsumgebung mehr oder weniger effizient reproduziert. Einige Tests führen jede dieser Instanzen parallel aus und stellen sicher, dass alle dieselben Daten sehen und keine Rennbedingungen vorliegen.
Wir haben auch einen rudimentären, aber immer noch recht nützlichen Stresstest durchgeführt
Belagerung , die dazu beitrug, die zulässige Last und die Reaktionsgeschwindigkeit des Dienstes grob abzuschätzen.
Über die Leistung
Bei 90% der Anfragen ist die Verarbeitungszeit sehr gering und vor allem stabil. Hier ist ein Beispiel für Messungen an einem der Projekte über mehrere Tage:
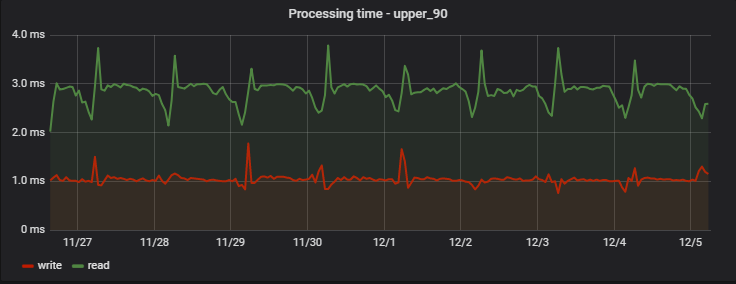
Interessanterweise ist ein Datensatz (der eigentlich eine Schreib- + Leseoperation ist, da er aktualisierte Werte zurückgibt) etwas schneller als das Lesen (jedoch nur aus der Sicht eines Clients, der den tatsächlich ausstehenden Schreibvorgang nicht beobachtet).
Eine regelmäßige Zunahme der Verzögerungen am Morgen ist ein Nebeneffekt der Arbeit unseres Analyseteams, das täglich eigene Statistiken auf der Grundlage der Daten des Dienstes sammelt und so eine „künstliche Hochlast“ für uns schafft.
: ( — MongoDB), ( ), :
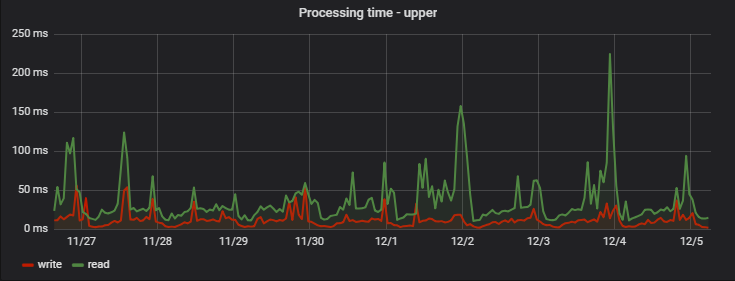
Fazit
, - , , Redis .
, 95% , . , . 5.
Go, Redis MongoDB . , . , — .