Kürzlich sprach Yegor Budnikov, Systemanalyst in der Technologieabteilung von ABBYY, bei Yandex auf der Konferenz
Data & Science: Law and Records Management . Er erzählte, wie Computer Vision funktioniert, wie Textverarbeitung stattfindet, worauf es beim Extrahieren von Informationen aus juristischen Dokumenten ankommt und vieles mehr.
- Ein Unternehmen hat möglicherweise Methoden für die Datenanalyse und das elektronische Dokumentenmanagement entwickelt, während in Word erstellte Dokumente von Kunden oder benachbarten Abteilungen des Unternehmens stammen können, während sie gedruckt, fotokopiert, gescannt und auf ein Flash-Laufwerk gebracht werden.
Was tun mit dem Dokumentenfluss, der jetzt mit „schmutzigen“ Dokumenten und Papierspeicher verbunden ist, bis hin zur Tatsache, dass Dokumente bis zu 70 Jahre gespeichert werden können, bevor sie gescannt werden und erkannt werden müssen?
ABBYY entwickelt Technologien für künstliche Intelligenz für Geschäftsaufgaben. Künstliche Intelligenz sollte in der Lage sein, ungefähr das Gleiche zu tun, was eine Person im Alltag oder in der beruflichen Tätigkeit tut, nämlich Informationen über die reale Welt aus einem Bild oder einem Bildstrom zu lesen. Dies kann nicht nur Computer Vision sein, sondern auch das Hören oder Erkennen von Daten von Sensoren, beispielsweise von Rauch- oder Temperatursensoren. Ferner gelangen die Daten dieser Sensoren in das System und müssen an der Entscheidung teilnehmen. Um diese Funktion erfolgreich zu implementieren, darf das System keine dummen logischen Fehler zulassen, wie im Bild:

Die Texte sind schwer zu analysieren: Die Vielfalt und Entwicklung der Sprache macht sie schön und ausdrucksstark, was jedoch die Aufgabe ihrer automatischen Verarbeitung erschwert. Normalerweise wird die Mehrdeutigkeit von Wörtern durch die Tatsache überwunden, dass wir durch den Kontext bestimmen können, was ein bestimmtes Wort bedeutet, aber manchmal lässt der Kontext Raum für Interpretationen. In der Formulierung "
Diese Stahlsorten sind auf Lager " ist es unmöglich, in Bezug auf den Kontext mit absoluter Genauigkeit zu verstehen, ob es sich um Personen im Raum handelt, die zu Mittag essen, oder ob es sich um einige Stahlsorten handelt, die im Lager gelagert werden. Um diese Mehrdeutigkeit aufzulösen, ist ein breiterer Kontext erforderlich.
Der untere Teil der Collage ist ein Bild aus dem Film "Operation" Y "und Shuriks anderen Abenteuern."Im Allgemeinen muss künstliche Intelligenz oder ein intelligenter Roboter in der Lage sein, sich im Raum zu bewegen und erfolgreich mit Objekten zu interagieren. Nehmen Sie beispielsweise die Kiste immer wieder auf, die der Ausbilder aus seinen Händen schlägt.
Schließlich allgemeine Intelligenz und die Darstellung von Wissen: Wissen unterscheidet sich von Informationen darin, dass seine Teile aktiv miteinander interagieren und neues Wissen erzeugen. Um das Problem des Mischens von Cocktails effektiv zu lösen, können Sie den einfachen Weg gehen: Listen Sie die Zutaten auf und geben Sie an, in welcher Reihenfolge sie gemischt werden sollen. In diesem Fall kann das System keine willkürlichen Fragen zu dem Thema seines Interesses beantworten. Was passiert zum Beispiel, wenn Sie Tomatensaft durch Ananas ersetzen? Damit das System das Material, Datenbanken und Taxonomien (konzeptionell miteinander verknüpfte Konzeptbäume) besser beherrschen kann, muss eine logische Inferenzprozedur hinzugefügt werden. In diesem Fall können wir wirklich sagen, dass das System versteht, was es tut, und dass es in der Lage sein wird, eine willkürliche Frage über den Prozess zu beantworten.
Die von ABBYY entwickelte künstliche Intelligenz verarbeitet Dokumente, dh verwandelt Papier, gescannte und elektronische Medien in strukturierte Informationen, die aus diesen Dokumenten extrahiert werden. Lassen Sie uns auf zwei Komponenten eingehen, wie Computer Vision und Textverarbeitung. Mit Computer Vision können Sie PDF-Dateien, gescannte Bilder und Bilder in bearbeitbare Textformate umwandeln. Warum ist das eine schwierige Aufgabe? Erstens können Dokumente eine beliebige Struktur haben.
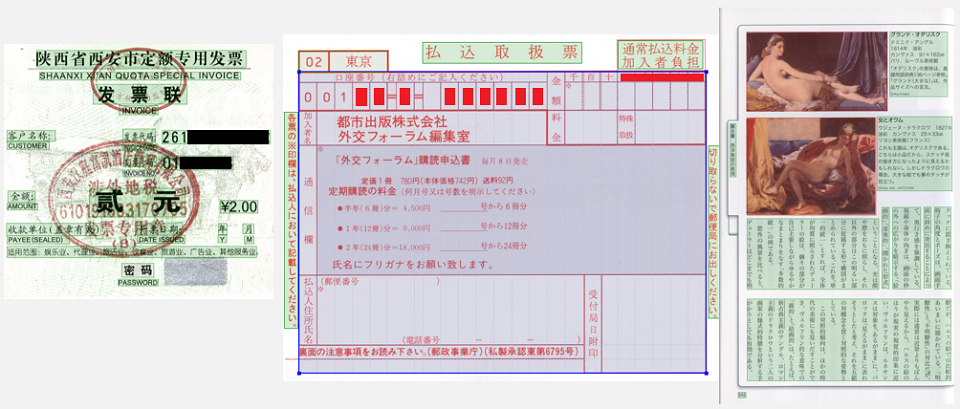
Dies bedeutet, dass Sie zuerst das Problem der Strukturanalyse von Dokumenten lösen müssen: um zu verstehen, wo sich die Textblöcke, Bilder, Tabellen und Listen befinden, und um dann zu bestimmen, wie sie miteinander interagieren. Zweitens können Dokumente in verschiedenen Sprachen vorliegen. Dies bedeutet, dass es notwendig ist, die Erkennung verschiedener Arten des Schreibens und die Fähigkeit zu unterstützen, Wörter und Zeichen zu erkennen, die sehr unterschiedlich sein können. Drittens kommen Bilder aus der realen Welt zu uns, was bedeutet, dass ihnen alles passieren kann. Sie sind möglicherweise verzerrt, mit der falschen Perspektive fotografiert, haben möglicherweise Kaffeeflecken, Streifen vom Drucker und dann vom Scanner. All dies muss irgendwie verwaltet werden, um anschließend Informationen zu extrahieren.
Wie funktioniert die Bilderkennung bei uns? In der ersten Phase empfangen und verarbeiten wir Bilder. Das Dokument wird geebnet, Verzerrungen werden korrigiert. Anschließend wird eine Analyse der Seitenstruktur durchgeführt. In diesem Stadium werden die Blocktypen gefunden und bestimmt. Wenn die Blöcke definiert und die Zeilen oder Spalten ausgerichtet sind, können Sie diese Zeilen in Wörter und Symbole unterteilen - beispielsweise durch vertikale und horizontale Histogramme der Verteilung der schwarzen Farbe.
Somit ist es möglich zu bestimmen, wo sich die Grenzen von Symbolen und Wörtern befinden, und dann zu erkennen, was diese Symbole und Wörter sind. Schließlich werden die erkannten Blöcke zu einzelnen Textdokumenten zusammengefasst und exportiert.
Sie können diesen Prozess aus der Sicht von Entitäten verschiedener Ebenen betrachten. Zuerst haben wir ein Dokument, das paginiert ist. Dann sollten diese Seiten in Blöcke, Blöcke in Zeilen, Zeilen in Wörter, Wörter in Zeichen unterteilt werden, und dann müssen diese Zeichen erkannt werden. Danach sammeln wir die erkannten Zeichen in Wörter, Wörter in Zeilen, Zeilen in Blöcke, Blöcke in Seiten, Seiten in ein Dokument. Darüber hinaus kann auf dem Rückweg die anfängliche Partition variieren. Das einfachste Beispiel ist, wenn die anfangs unterbrochenen Blöcke zu derselben nummerierten Liste gehörten, sodass sie letztendlich zu demselben Block mit dem strukturierten Listentyp gehören sollten. Mit anderen Worten können benachbarte Schritte sich gegenseitig beeinflussen, um die Erkennungsqualität zu verbessern.
Das Dokument wurde erkannt, dann müssen Sie Informationen daraus extrahieren. Dokumente können in strukturiertere und weniger strukturierte Dokumente unterteilt werden. Zu den strukturierteren gehören Visitenkarten, Schecks und Rechnungen. Zu den weniger strukturierten gehören Vollmachten, Urkunden und Artikel in Zeitschriften. Wenn der Typ des Dokuments festgelegt ist, mehr oder weniger strukturiert ist und sich die Dokumente innerhalb dieses Typs in ihrer Struktur kaum voneinander unterscheiden, können Sie Methoden anwenden, mit denen Sie lernen, die erforderlichen Attribute mithilfe von Text- und Grafikattributen direkt aus einem Textdokument zu extrahieren. Mithilfe wiederkehrender neuronaler Netze können Sie beispielsweise Produktpositionen aus Rechnungen extrahieren. Rechnungen sind Dokumente, in denen die Positionen der Waren und eine Beschreibung der Zahlungsmethoden für diese Waren dargestellt werden.

Ein weiteres Beispiel sind Schecks. Mithilfe von Faltungsnetzwerken können Sie einzelne Attribute wie TIN, Prüfnummer, Datum und Uhrzeit sowie die Gesamtpunktzahl abrufen. Ehrlich gesagt werden sowohl Methoden als auch Schecks in Schecks und Rechnungen verwendet, jedoch für unterschiedliche Zwecke. Faltungs-Neuronale Netze eignen sich für einzelne Attribute, die eine bestimmte Position haben, und wiederkehrende Netze eignen sich für wiederholte Elemente.
Wenn die Dokumente weniger strukturiert sind, kommen die Verarbeitung natürlicher Sprache, die Verarbeitung natürlicher Sprache oder NLP-Methoden ins Spiel. Warum ist es schwierig? Ich habe bereits über die Polysemie der Wörter gesprochen. Das Wort Adresse kann beispielsweise die Adresse eines Unternehmens oder die Verpflichtung zur Lösung einiger Kundenprobleme bedeuten.
Auch Texte werden oft weggelassen, aber Wörter werden impliziert. Um Informationen zu extrahieren, müssen Sie diese fehlenden Wörter wiederherstellen. Dieser Effekt in der Linguistik wird als "Ellipse" bezeichnet.
Die Sprache ist vielfältig und es gibt normalerweise unzählige Möglichkeiten, ein und denselben Gedanken auszudrücken. Um Texte automatisch zu verarbeiten, muss diese Variabilität irgendwie reduziert werden: die Verwendung von Synonymen und ähnlichen Konstruktionen, um ein einzelnes Wort oder einen einzelnen Ausdruck zu ersetzen; Permutation von Wörtern oder Änderung der grammatikalischen Stimme. Zum Beispiel "Unternehmen haben eine Vereinbarung geschlossen" und "eine Vereinbarung wurde zwischen Unternehmen geschlossen", um dasselbe zu sagen. Bei Synonymen kann man den sogenannten semantischen Raum einführen, einen Vektorraum, in dem Wörter als Punkte dargestellt werden. Nahe Punkte zeigen verwandte Konzepte an, entfernte Punkte zeigen weiter entfernte Konzepte an. Um die Variabilität von Formulierungen zu verringern, können Sie syntaktische und semantische Analysebäume einführen. In diesem Fall wird auch ein ähnliches Problem gelöst, und der Informationsextraktionsalgorithmus kann Informationen extrahieren, selbst wenn er auf Konstruktionen oder Wörter stößt, die zuvor nicht im Trainingssatz gefunden wurden.
Wie werden Informationen extrahiert? In der ersten Phase wird eine lexikalische Analyse des Dokuments durchgeführt. Der Text ist in Absätze, Absätze in Sätze, Sätze in Wörter unterteilt. Dies ist möglicherweise nicht trivial: Diejenigen unter Ihnen, die mit NLP vertraut sind, wissen möglicherweise, dass selbst eine scheinbar einfache Aufgabe wie das Aufteilen von Text in Sätze schwierig sein kann: Punkte zeigen nicht immer das Ende eines Satzes an. Dies können unbekannte Abkürzungen sein, daher versuchen wir in der lexikalischen Analyse, alle möglichen Optionen zum Aufteilen von Sätzen in Wörter zu sortieren und die wahrscheinlichste zu belassen. Dieses Problem tritt in der Regel in Sprachen auf, in denen nur wenige oder gar keine Leerzeichen vorhanden sind, z. B. Japanisch oder Chinesisch. Oder die eine reiche Wortbildung haben. Dies ist zum Beispiel eine Sprache wie Deutsch: Sie hat sehr lange Wörter, die aus mehreren Wörtern bestehen (solche Wörter werden zusammengesetzte Wörter genannt). Außerdem werden für alle diese Wörter alle möglichen Interpretationen berechnet. Wenn beispielsweise „g“ im Text mit einem Punkt angezeigt wird, kann dies viel bedeuten: Stadt, Jahr, Gramm, Herr und sogar den vierten Absatz (a, b, c, d).

Dann wird eine Segmentierung durchgeführt, dh eine Suche nach den für uns interessanten Abschnitten. Es wird aus verschiedenen Gründen erstellt, um beispielsweise die Dokumentenverarbeitung zu beschleunigen oder Informationen zu finden, die uns interessieren. um einen Teil des Dokuments zu finden, der die Verpflichtungen der Partei beschreibt. Oder dies ist eine Beschleunigung der Verarbeitung. Beispielsweise kann unser Dokument in besonders fortgeschrittenen Fällen aus mehreren zehn oder sogar Hunderten von Seiten bestehen, während interessante Informationen nur auf wenigen Seiten enthalten sind. Durch Segmentierung können Sie diese interessanten Teile finden und nur analysieren. Dann kann eine semantische Analyse des Dokuments durchgeführt werden oder nicht, dies hängt von der Aufgabe ab, und in dieser Phase wird nach den besten Interpretationen von Sätzen, allen Sätzen des Dokuments oder nur denen gesucht, die wir in der vorherigen Phase gefunden haben. Im nächsten Schritt werden auch semantische Merkmale für den Klassifikator generiert.
Schließlich die Phase der direkten Extraktion von Attributen. Hier werden maschinell trainierte Modelle verwendet oder einfache Muster geschrieben. Auf die eine oder andere Weise stützen sie sich auf Zeichen, die durch vorherige Schritte erzeugt wurden. Dies sind sowohl lexikalische als auch semantische Strukturmerkmale. Abhängig von der Komplexität der Aufgabe verwenden wir viele verschiedene Methoden: Methoden des maschinellen Lernens und Methoden zum Schreiben von Vorlagen. In dieser Phase suchen wir nach den Attributen, die uns interessieren. Dies können die Namen der Parteien, Verpflichtungen, das Datum der Unterzeichnung usw. sein.
Schließlich müssen einige Attribute möglicherweise nachbearbeitet werden. Zur normalen Form bringen oder zu einer Datumsvorlage gießen. Einige Attribute können grundsätzlich berechnet werden, sie werden nicht aus dem Vertrag extrahiert, sondern auf der Grundlage der Attribute, die aus dem Vertrag extrahiert werden. Zum Beispiel die Vertragsdauer basierend auf dem Beginn und dem Ende der Aktion.
Betrachten Sie dies in einem der Szenarien als "Eröffnung eines Kontos bei einer juristischen Person". Was ist die Herausforderung? Eine juristische Person oder vielmehr ihr Vertreter kommt zur Bank und bringt einen großen Stapel Dokumente mit. In einem guten Fall hat er diese Dokumente bereits gescannt, aber es ist nicht klar, mit welcher Qualität. Um den Prozess zu optimieren, die Anzahl der Fehler bei der Eingabe dieser Informationen in das System zu verringern, diesen Prozess zu beschleunigen und daher die Entscheidungsfindung zu beschleunigen und die Kundenbindung zu erhöhen, wurde das folgende Schema vorgeschlagen:
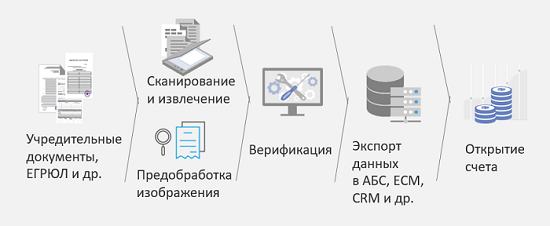
Konstituierende Dokumente, die viele verschiedene Typen enthalten, werden zuerst gescannt und dann erkannt. Darüber hinaus werden sie nach der Erkennung nach verschiedenen Typen klassifiziert, und je nach Typ können verschiedene Algorithmen verwendet werden, um Informationen zu erkennen und zu extrahieren. Diese extrahierten Informationen werden dann bei Bedarf zur Überprüfung an Personen gesendet, und danach ist es bereits möglich, eine Entscheidung zu treffen: Eröffnen Sie ein Konto, oder es werden andere zusätzliche Dokumente benötigt. Das Hauptergebnis dieser Entscheidung ist die Halbierung der Kosten für die Dateneingabe bei der Kontoeröffnung. Ergebnisse basieren auf Messungen unseres Kunden.
Welche Attribute müssen Sie abrufen? Viele Dinge. Nehmen wir an, wir haben eine Art Charter. Zuerst erkennen wir es. Wie wir uns erinnern, kann dies ziemlich problematisch sein, wenn es sich um einen Scan oder ein Foto handelt. Dann bestimmen wir den Dokumenttyp, und dies ist wichtig, da die benötigten Informationen in einem bestimmten Kapitel oder Unterabschnitt enthalten sein können. Daher hilft die Kenntnis, wann dieses Kapitel oder dieser Unterabschnitt beginnt oder endet, dem Algorithmus zur Informationsextraktion erheblich.
Dann ruft die Maschine alle grundlegenden Entitäten ab, die sie erreichen kann:
Dies ist erforderlich, damit der Algorithmus in der nächsten Phase des Extrahierens von Attributen oder des Definierens von Rollen nicht nur den Kontext verwenden kann, sondern auch die Merkmale, die in den vorherigen Phasen generiert wurden. Zum Beispiel kann es die Aufgabe, zu bestimmen, wer der Direktor einer juristischen Person ist, erheblich vereinfachen und darüber informieren, dass es sich um eine Person handelt. Dementsprechend müssen wir sie unter den Personen, die in dem Dokument aufgeführt sind, dem Direktor oder nicht dem Direktor zuordnen. Wenn wir eine begrenzte Anzahl von Objekten haben, vereinfacht dies die Aufgabe erheblich.
In den letzten zwei Jahren sind wir auf mehrere weitere Aufgaben von Kunden gestoßen und haben diese erfolgreich gelöst. Zum Beispiel Medienüberwachung auf Unternehmensrisiken.
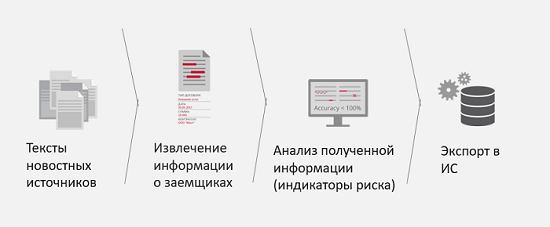
Was ist hier die geschäftliche Herausforderung? Sie haben beispielsweise einen potenziellen Partner oder Kunden, der einen Kredit von Ihnen aufnehmen möchte. Um die Verarbeitung der Daten dieses Kunden zu beschleunigen und das Risiko einer schlechten Partnerschaft oder des künftigen Konkurses dieser juristischen Person zu verringern, wird empfohlen, die Medien auf Verweise auf diese Person oder juristische Person und auf das Vorhandensein sogenannter Risikoindikatoren in den Nachrichten zu überwachen. Das heißt, wenn beispielsweise in den Nachrichten ständig auftaucht, dass eine juristische Person in Gerichtsverfahren verwickelt ist oder ein Unternehmen durch Aktionärskonflikte gebrochen wird, ist es besser, dies früher herauszufinden, um diese Informationen an Analysten oder das Analysesystem weiterzugeben und zu verstehen, wie schlecht oder gut sie für Ihr Unternehmen sind . Das Ergebnis der Lösung dieses Problems besteht darin, vollständigere und genauere Informationen über den Kreditnehmer zu erhalten, und die Zeit, um diese Informationen zu erhalten, wird ebenfalls reduziert.

Ein weiteres Beispiel für eine Anwendung, bei der die Routine und die Anzahl der Fehler bei der Eingabe von Informationen in das System reduziert werden müssen, ist die Extraktion von Daten aus Verträgen. Es wird vorgeschlagen, dass Verträge Informationen erkennen, daraus extrahieren und sofort an das System senden. Danach bedankt sich die Personalabteilung bei Ihnen unter Tränen und herzlich bei jedem Treffen.
Nicht nur die Personalabteilung leidet unter viel Routinearbeit mit eingehenden Dokumentationen, sondern auch die Buchhaltungsabteilungen, Verkaufsabteilungen und Einkaufsabteilungen. Die Mitarbeiter müssen viel Zeit damit verbringen, Informationen aus Rechnungen, eingehenden Handlungen usw. einzugeben.

Tatsächlich sind alle diese Dokumente strukturiert, und daher ist es einfach, Informationen daraus zu erkennen und daraus zu extrahieren. Die Geschwindigkeit der Dateneingabe wird um das Fünffache erhöht und die Anzahl der Fehler verringert, da der Faktor Mensch ausgeschlossen ist. Wenn ein Mitarbeiter nach dem Mittagessen zurückkehrt, kann er möglicherweise unaufmerksam Daten eingeben. Unsere eigenen Messungen und die Branche, die auf die eine oder andere Weise mit der manuellen Eingabe von Informationen in die Systeme befasst ist, legen nahe, dass eine Person, die Daten aus einem Dokument eingibt und dies fortlaufend und in einem Stream tut, selten eine Qualität von mehr als 95% erhält häufiger und mehr als 90%. Daher muss eine Person gezählt und noch mehr als hinter einer Maschine überprüft werden.
Wenn das Gerät eine Art Vertrauensbewertung abgibt, die es nicht extrahiert hat - beispielsweise ist ein Dokument möglicherweise verschmutzt - und das Gerät nicht sicher ist, ob dies der Fall ist, kann es dem Prüfer signalisieren, dass es sich dieses Ergebnisses nicht sehr sicher ist : "Bitte überprüfen Sie." Und eine Person überprüft einzelne Informationen noch einmal, um sie von hoher Qualität zu erhalten. Dies ist keine solche Routineoperation: Er überprüft nur wirklich wichtige und schwierige Momente, seine Augen sind nicht verschwommen.
Wenn Informationen aus Dokumenten extrahiert werden können, können diese Informationen verglichen werden.
Dies ist in zwei Fällen wichtig. Um verschiedene Versionen eines Dokuments zu vergleichen, beispielsweise einen Vertrag, der seit langem konsistent ist, werden von beiden Seiten ständig Änderungen daran vorgenommen. Zweitens handelt es sich um einen Vergleich von Dokumenten unterschiedlicher Art. Wenn beispielsweise eine Vereinbarung vorliegt, die angibt, was von unserem Partner stammen soll, gibt es unterschiedliche Rechnungen und Berichte, Schätzungen usw. Wir müssen sie korrelieren und verstehen, dass alles in Ordnung ist, und wenn nicht in Ordnung, signalisieren wir dies irgendwie den Verantwortlichen.
Die derzeitige technologische Entwicklung in der Bildverarbeitung, die Verarbeitung strukturierter und unstrukturierter Dokumente, ist so hoch, dass Routineprozesse in Unternehmen auch jetzt und in den kommenden Jahren digital transformiert werden, da sie billiger, schneller und oft besser sind.
Darüber hinaus sollen alle diese Methoden keinesfalls Menschen ersetzen. Ich mag eher das Beispiel eines Vergleichs mit dem Excel-Tool, in dem Sie viel tun können und das weder Analysten, Manager noch andere ersetzen soll. Es soll die menschlichen Fähigkeiten erweitern und die Lösung von Aufgaben für ihn vereinfachen.
Daher sind Lösungen im Zusammenhang mit künstlicher Intelligenz auch darauf ausgelegt, die Anzahl sich wiederholender Routineoperationen zu verringern, bei denen eine Person häufig mehr Fehler als eine Maschine macht, um die Ressourcen des Unternehmens zu entladen und sie zur Lösung kreativerer und intellektuellerer Aufgaben zu führen. Und es scheint, dass wir mit Volldampf dorthin ziehen. Vielen Dank.