
Der Ozon Online-Shop bietet fast alles: Kühlschränke, Babynahrung, Laptops für 100.000 usw. Dies bedeutet, dass sich all dies auch in den Lagern des Unternehmens befindet - und je länger die Waren dort sind, desto teurer ist das Unternehmen. Um herauszufinden, wie viel und was die Leute bestellen möchten und was Ozon kaufen müsste, haben wir maschinelles Lernen verwendet.
Umsatzprognose: Herausforderungen
Bevor wir uns mit der Problemstellung befassen, beginnen wir mit einem Beispiel. Dies ist ein echter Ozon-Verkaufsplan für eine Weile. Frage: Wohin wird er als nächstes gehen?
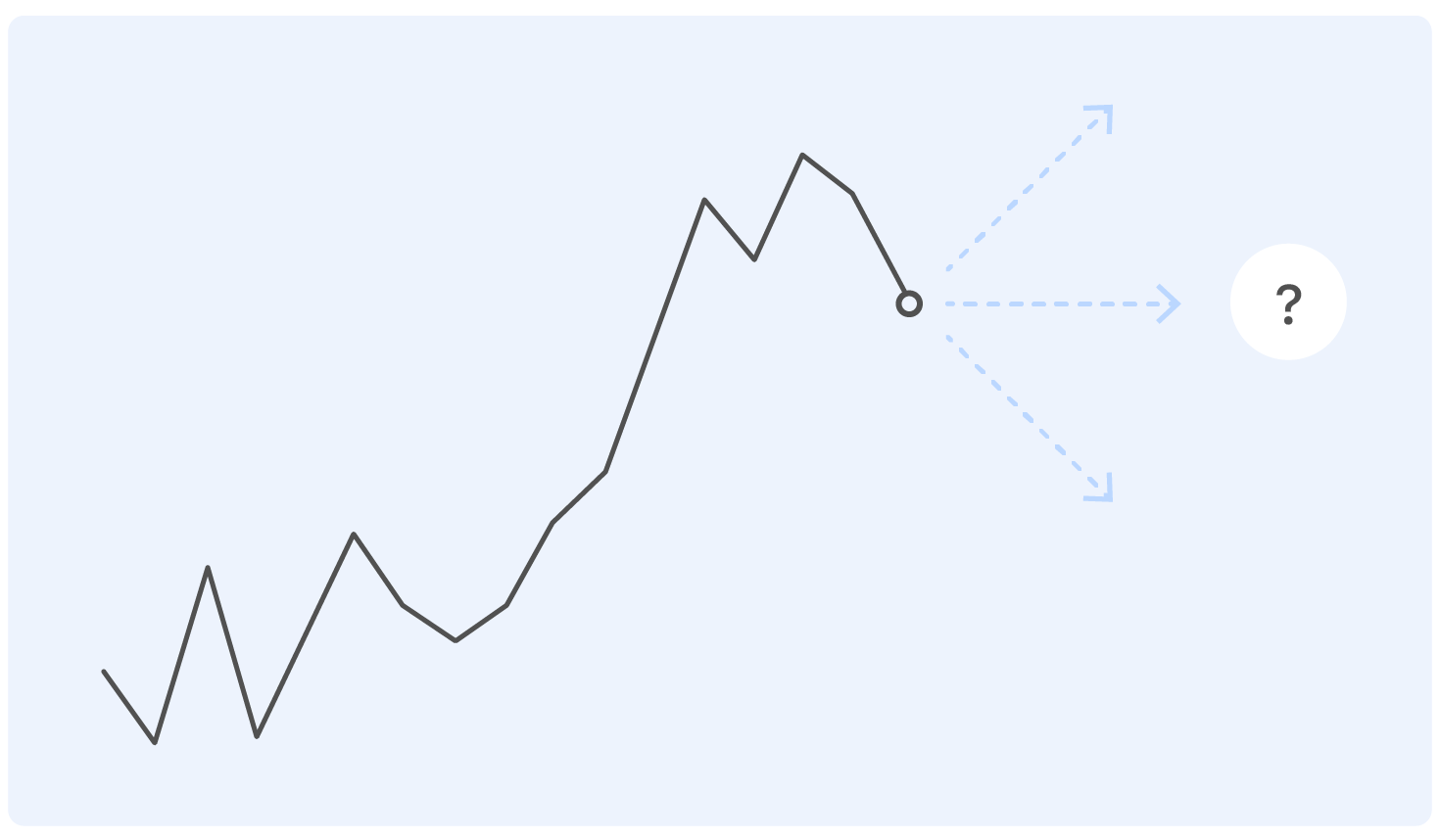
Eine Person mit einer nahezu technischen Ausbildung für eine solche Formulierung des Problems wird Fragen haben: Wo sind die Achsen? Und was für ein Produkt? Und in welchen Einheiten? An welchem Institut haben Sie Ihren Abschluss gemacht? - und viele andere, die aus ethischen Gründen nicht in diesem Artikel enthalten sind.
Tatsächlich kann niemand die Frage in einer solchen Aussage richtig beantworten, und wenn jemand dies kann, wird er sich höchstwahrscheinlich irren.
Fügen Sie dieser Tabelle weitere Informationen hinzu: Achsen und Preisänderungen auf der Ozon-Website (blau) und auf der Website des Mitbewerbers (orange).
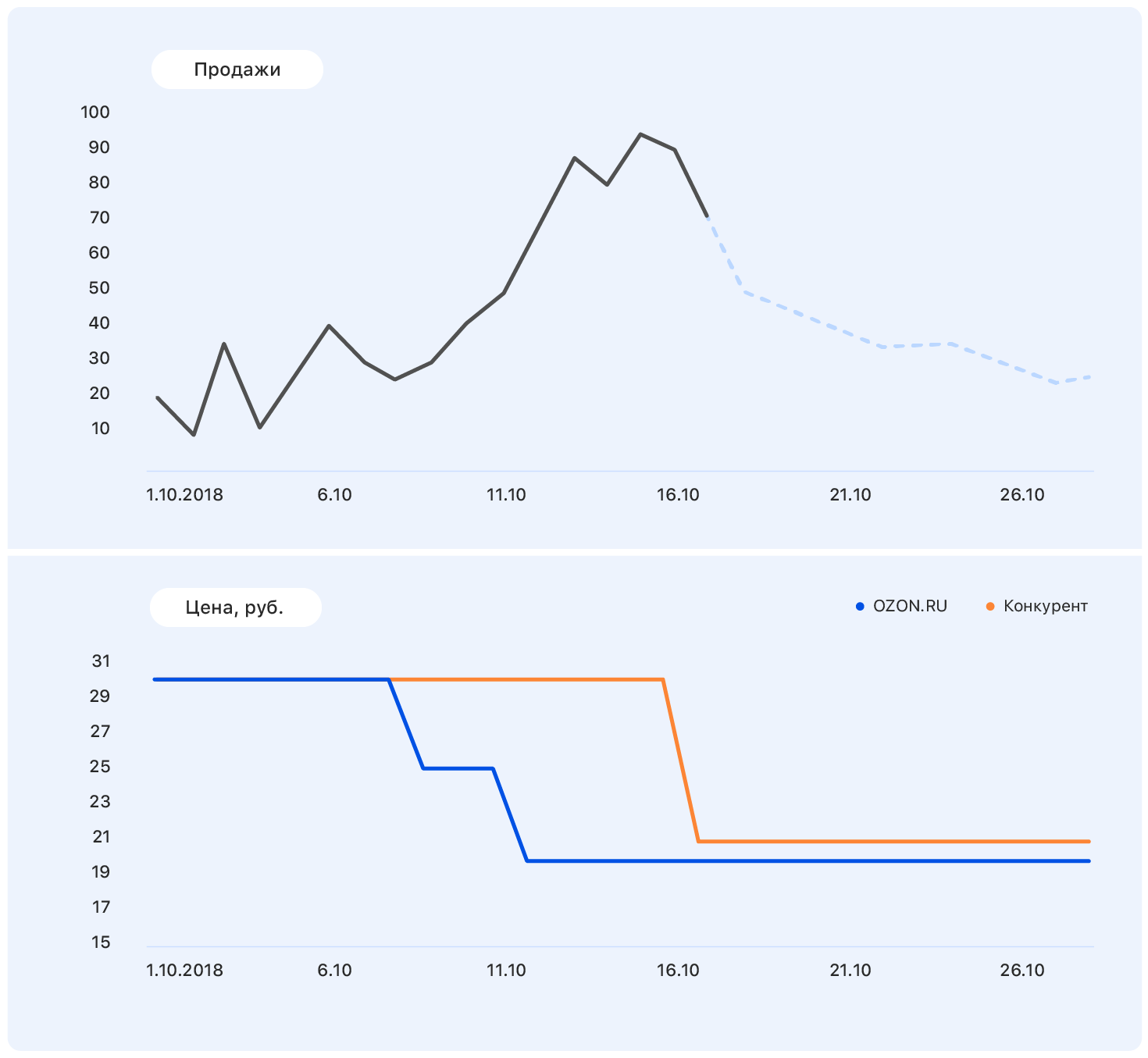
Unser Preis fiel irgendwann, aber die Konkurrenz blieb gleich - und die Verkäufe von Ozon stiegen. Wir kennen die Preispläne: Unser Preis wird auf dem gleichen Niveau bleiben, aber der Wettbewerber hat nach Ozon den Preis auf fast unseren gesenkt.
Diese Daten reichen aus, um eine aussagekräftige Annahme zu treffen - zum Beispiel, dass der Umsatz auf das vorherige Niveau zurückkehren wird. Und wenn Sie sich das Diagramm ansehen, stellt sich heraus, dass es so sein wird.
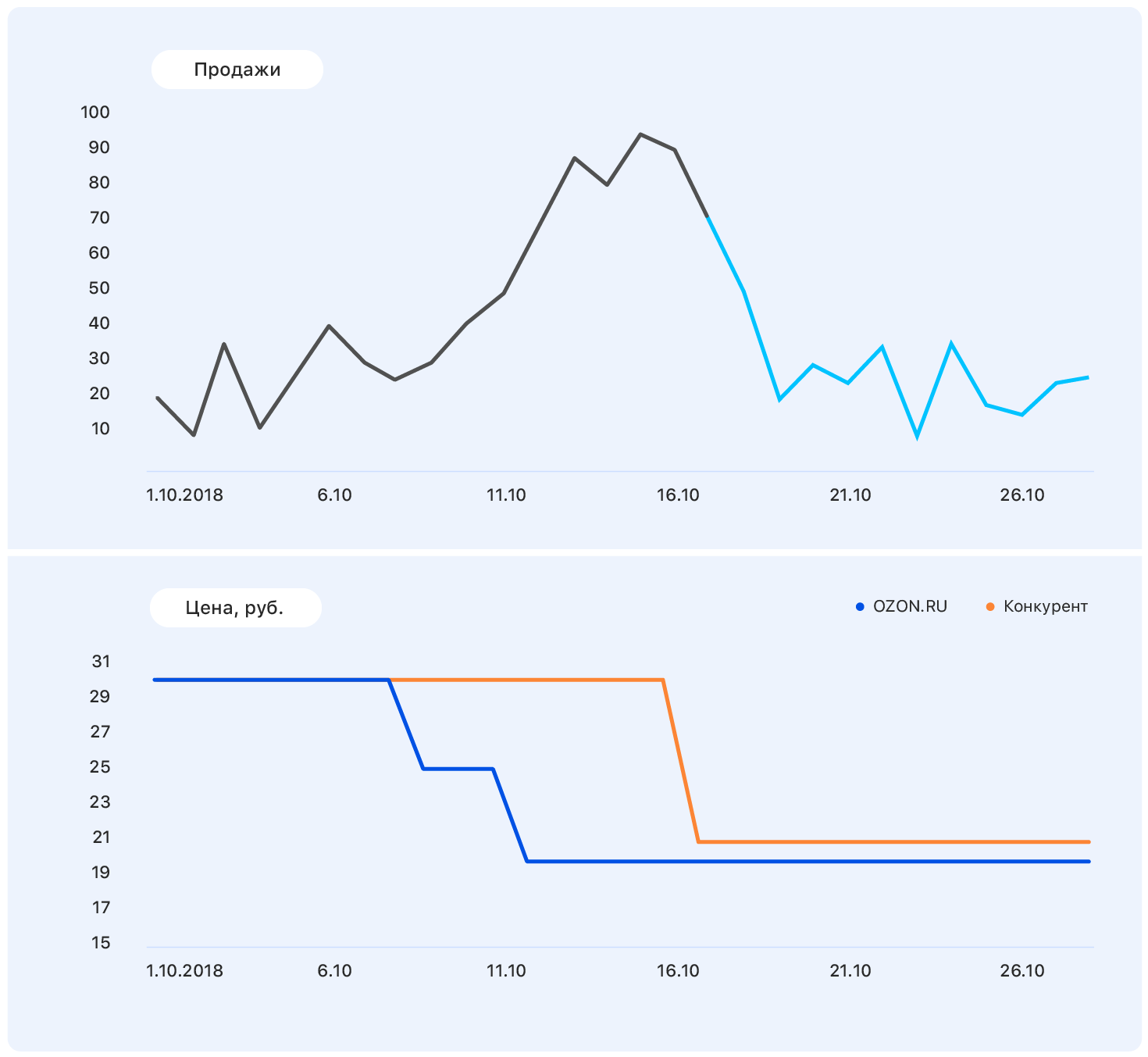
Das Problem ist, dass die Nachfrage nach diesem Produkt in der Tat nicht so stark vom Preis beeinflusst wird und das Umsatzwachstum unter anderem durch das Fehlen der meisten Wettbewerber dieses Produkts in unserem Geschäft verursacht wurde. Es gibt noch viele Faktoren, die wir nicht berücksichtigt haben: Wurden die Waren im Fernsehen beworben? oder vielleicht sind es Süßigkeiten und bald der 8. März?
Eines ist klar: Eine Vorhersage "auf dem Knie" zu machen, wird nicht funktionieren. Wir folgten dem Standardpfad eines
Rechen und von Krücken, um einen beliebigen ML-Algorithmus
zu erstellen. Und so war es auch.
Metrische Auswahl
Wenn Sie eine Metrik auswählen, beginnen Sie, wenn mindestens eine andere Person neben Ihnen Ihre Prognose verwendet.
Betrachten Sie ein Beispiel: Wir haben drei Prognoseoptionen. Welches ist besser?
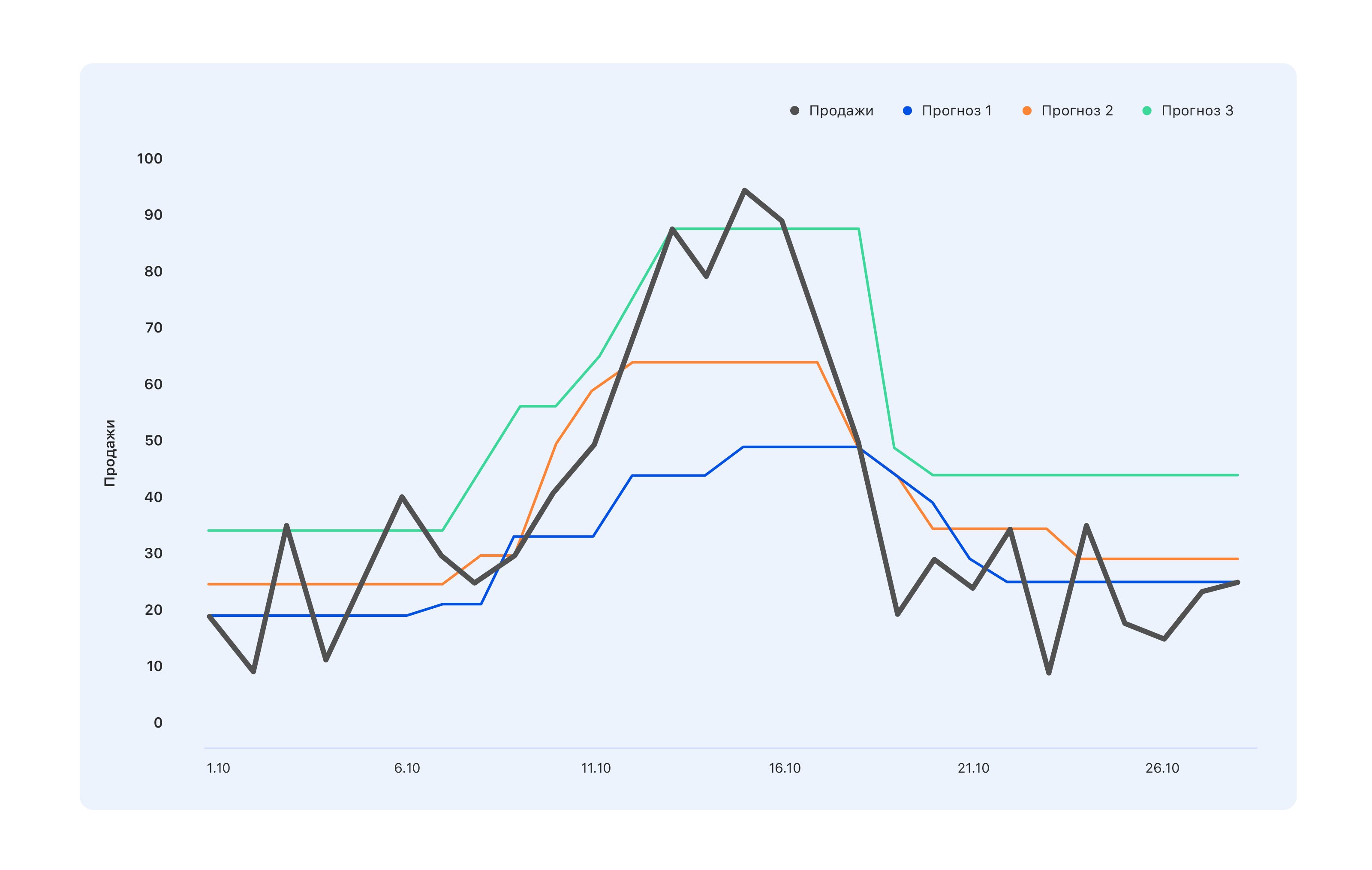
Aus Sicht der Spezialisten im Lager brauchen wir eine blaue Prognose - wir werden etwas weniger kaufen und Mitte Oktober den Höhepunkt verpassen, aber nichts wird im Lager bleiben. Experten, deren KPI an den Umsatz gebunden ist, sind der gegenteiligen Meinung: Selbst die türkisfarbene Prognose ist nicht ganz richtig, nicht alle Nachfragesprünge haben sich widerspiegelt - ändern Sie sie. Aber aus der Sicht eines Menschen von außen ist im Allgemeinen etwas Besseres angebracht - damit sich jeder gut fühlt oder umgekehrt.
Bevor Sie eine Prognose erstellen, müssen Sie daher festlegen, wer sie verwenden wird und warum. Wählen Sie also eine Metrik aus und verstehen Sie, was Sie von einer Prognose erwarten können, die auf einer solchen Metrik basiert. Und warte darauf.
Wir haben MAE gewählt - den durchschnittlichen absoluten Fehler. Diese Metrik eignet sich für unser stark unausgeglichenes Trainingsmuster. Da das Sortiment sehr breit ist (1,5 Millionen Artikel), wird jedes Produkt einzeln in einer bestimmten Region in kleinen Mengen verkauft. Und wenn wir insgesamt Hunderte von grünen Kleidern verkaufen, wird ein bestimmtes grünes Kleid mit Katzen zu 2-3 pro Tag verkauft. Infolgedessen verschiebt sich die Stichprobe in Richtung kleiner Werte. Auf der anderen Seite gibt es iPhones, Spinner, ein neues Buch von Olga Buzova (ein Witz) usw. - und sie werden in jeder Stadt in großen Mengen verkauft. Mit MAE können Sie auf bedingten iPhones keine hohen Bußgelder erhalten und arbeiten im Allgemeinen gut mit dem Großteil der Waren.
Erste Schritte
Wir haben zunächst die dümmste Prognose erstellt, die es geben könnte: Eine Zufallszahl von 0 bis 1000 wird in der nächsten Woche verkauft und erhält die Metrik MAE = 496. Wahrscheinlich kann es schlimmer sein, aber das ist bereits sehr schlecht. Wir haben also eine Richtlinie: Wenn wir einen solchen metrischen Wert erhalten, dann machen wir offensichtlich etwas falsch.
Dann haben wir angefangen, Leute zu spielen, die wissen, wie man eine Prognose ohne maschinelles Lernen erstellt, und haben versucht, den Verkauf von Waren in der nächsten Woche vorherzusagen, der dem durchschnittlichen Umsatz aller letzten Wochen entspricht, und haben die Metrik MAE = 1,45 erhalten - was viel besser ist.
Wir haben weiter entschieden, dass die Verkäufe der letzten Woche für die Umsatzprognose für die nächste Woche nicht relevanter sind. Für eine solche Prognose betrug der MAE 1,26. In der nächsten Runde des prognostischen Denkens haben wir beschlossen, beide Faktoren zu berücksichtigen und den Umsatz für die nächste Woche als Summe von 50% des durchschnittlichen Umsatzes und 50% des Umsatzes der letzten Woche vorherzusagen - wir haben MAE = 1,23.
Aber es schien uns zu einfach, und wir beschlossen, die Dinge zu komplizieren. Wir haben eine kleine Trainingsstichprobe gesammelt, in der die Anzeichen vergangen waren und der durchschnittliche Umsatz, und die Ziele waren Verkäufe in der nächsten Woche, und wir haben darauf eine einfache lineare Regression trainiert. Wir haben Gewichte von 0,46 und 0,55 für den Durchschnitt und die letzten Wochen und die MAE auf der Testprobe gleich 1,2.
Fazit: Unsere Daten haben Vorhersagepotential.
Feature Engineering
Nachdem wir entschieden hatten, dass die Erstellung einer Prognose aus zwei Gründen nicht unser Niveau ist, haben wir uns zusammengesetzt, um neue komplexe Funktionen zu generieren. Dies sind Informationen über vergangene Verkäufe - vor 1, 2, 3, 4 Wochen, vor einer Woche genau vor einem Jahr usw. Und Ansichten der letzten Wochen, Ergänzungen zum Warenkorb, Konvertierung von Ansichten und Ergänzungen zum Warenkorb in Bestellungen - und das alles für verschiedene Zeiträume.
Wir mussten ein Modell des Wissens darüber geben, wie das Produkt als Ganzes verkauft wird, wie sich die Dynamik seines Verkaufs in letzter Zeit verändert hat, wie sich das Interesse daran entwickelt, wie sein Verkauf vom Preis abhängt und von anderen Faktoren, die unserer Meinung nach nützlich sein können.
Als unsere Ideen ausgegangen waren, gingen wir zu den Experten der Verkaufsabteilung. Dort haben wir zum Beispiel erfahren, dass das nächste Jahr das Jahr des Schweins ist, daher werden Waren, die zumindest aus der Ferne Schweinen ähneln, sehr beliebt sein. Oder zum Beispiel, dass unsere Leute „nicht gefrieren“ nicht im Voraus kaufen, sondern genau am Tag des ersten Frosts - berücksichtigen Sie also bitte die Wettervorhersage. Im Allgemeinen waren alle zufrieden. Wir - weil wir eine Reihe neuer Ideen erhalten haben, an die wir nie gedacht hätten, und Geschäftsleute - werden bald etwas Interessanteres als die Umsatzprognose tun können.
Aber es ist immer noch zu einfach - und wir haben kombinierte Symptome hinzugefügt:
- Umstellung von Ansichten auf Verkäufe - wie es war, wie es sich verändert hat;
- das Verhältnis von Verkäufen über 4 Wochen zu Verkäufen in der letzten Woche (wenn diese Zahl stark von 4 abweicht, unterliegt die Nachfrage nach diesem Produkt derzeit "Turbulenzen");
- das Verhältnis von Produktverkäufen zu Verkäufen in der gesamten Kategorie - wenn diese Zahl nahe eins liegt, ist das Produkt ein „Monopolist“.
In dieser Phase müssen Sie so viel wie möglich einfallen lassen - werfen Sie in der Trainingsphase nicht informative Zeichen weg.
Als Ergebnis haben wir 170 Zeichen. Mit Blick auf die Zukunft hatte das größte Merkmal Bedeutung
- Verkäufe der letzten Woche (für zwei, drei und vier).
- Die Produktverfügbarkeit in der letzten Woche ist der Prozentsatz der Zeit, in der das Produkt auf der Website vorhanden war.
- Der Winkelkoeffizient des Verkaufsplans für Waren der letzten 7 Tage.
- Das Verhältnis des vergangenen Preises zur Zukunft - mit einem enormen Rabatt beginnen Sie, Waren aktiver zu kaufen.
- Die Anzahl der direkten Wettbewerber auf unserer Website. Wenn zum Beispiel dieser Stift der einzige in seiner Kategorie ist, ist der Umsatz ziemlich stationär.
- Produktabmessungen - Es stellte sich heraus, dass Länge und Breite die Vorhersehbarkeit des Umsatzes erheblich beeinflussen. Aus irgendeinem Grund ist der Zeitplan für lange und schmale Objekte - zum Beispiel Regenschirme oder Angelruten - viel volatiler. Wir wissen noch nicht, wie wir das erklären sollen.
- Tagesnummer des Jahres - zeigt an, ob das neue Jahr kommt, der 8. März, der Beginn einer saisonalen Umsatzsteigerung usw.
Probenahme
Das Trainingsmuster ist Schmerz. Wir haben es für ungefähr 4 Wochen gesammelt, von denen zwei nur zu verschiedenen Datenverwaltern gingen und nach einem Blick darauf fragten, was sie haben. Dies geschieht jedes Mal, wenn Sie Daten für einen längeren Zeitraum benötigen. Selbst in einem idealen Datenerfassungssystem wird lange Zeit etwas im Sinne von „Früher haben wir so gedacht, aber dann haben wir angefangen, anders zu denken und die Daten in dieselbe Spalte zu schreiben“ geschehen. Oder vor ein oder zwei Jahren stürzte der Server ab, aber niemand schrieb genau auf, wann - und die Nullen bedeuten nicht mehr, dass es keine Verkäufe gab.
Als Ergebnis hatten wir Informationen darüber, was die Leute auf der Website gemacht haben, was und in welcher Menge sie zu Favoriten und einem Warenkorb hinzugefügt und gekauft wurden. Wir haben eine Stichprobe von ungefähr 15 Millionen Stichproben mit jeweils 170 Merkmalen gesammelt. Das Ziel war die Anzahl der Verkäufe für die nächste Woche.
Wir haben zweitausend Codezeilen auf Spark geschrieben. Es funktionierte langsam, erlaubte aber das Kauen großer Datenmengen. Es scheint nur, dass die Berechnung der Steigung einer Linie einfach ist. Und es 10kk Mal zu tun, wenn Verkäufe von mehreren Basen abgezogen werden - die Aufgabe ist nichts für schwache Nerven.
Eine weitere Woche lang beschäftigten wir uns mit der Datenbereinigung, damit das Modell nicht durch Emissionen und lokale Stichprobenmerkmale abgelenkt wurde, sondern nur die tatsächlichen Abhängigkeiten extrahierte, die mit dem Verkauf von Ozon verbunden sind. Hier werden 3 Sigma und weitere listige Methoden zur Suche nach Anomalien eingesetzt. Der schwierigste Fall ist die Wiederherstellung des Umsatzes in Zeiten mangelnder Lagerbestände. Die einfachste Lösung besteht darin, die Wochen wegzuwerfen, in denen das Produkt während der „Zielwoche“ ausfiel.
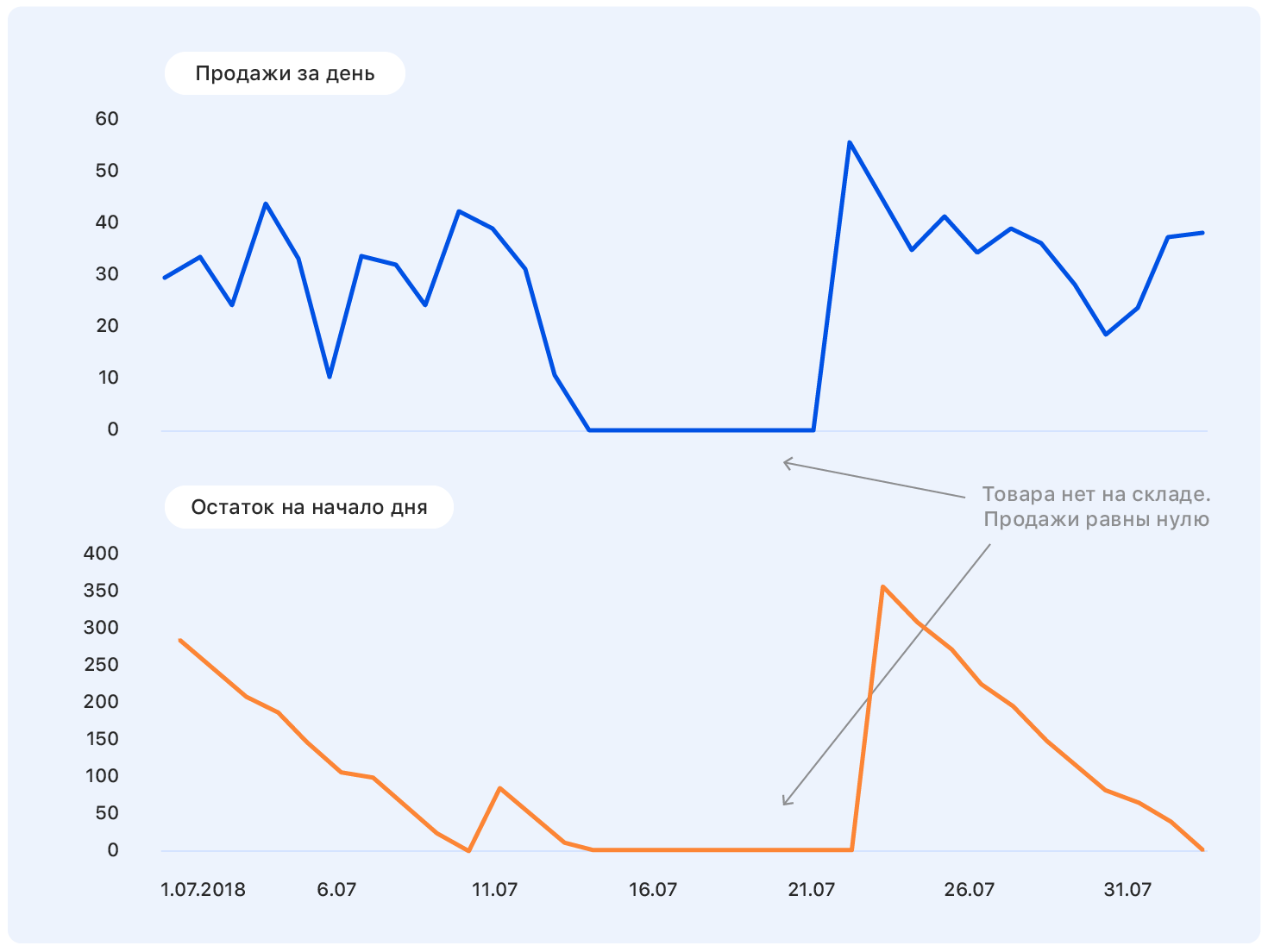
Infolgedessen blieben von 15 Millionen Proben 10 Millionen übrig. Es ist hier wichtig, sich nicht mitreißen zu lassen und die Vollständigkeit der Probe nicht zu verlieren (tatsächlich ist der Mangel an Waren im Lager ein indirektes Merkmal ihrer Bedeutung für das Unternehmen; das Entfernen solcher Waren aus der Probe ist nicht dasselbe wie das Herauswerfen von Stichproben )
ML Zeit
Auf eine saubere Probe und begann Modelle zu trainieren. Natürlich haben wir mit der linearen Regression begonnen und MAE = 1,15 erhalten. Es scheint, dass dies eine sehr kleine Zunahme ist, aber wenn Sie eine Stichprobe von 10 Millionen haben, bei der die Durchschnittswerte 5 bis 10 betragen, führt bereits eine kleine Änderung des metrischen Werts zu einer nicht messbaren Steigerung der visuellen Qualität der Prognose. Und da Sie die Lösung schließlich Geschäftskunden präsentieren müssen, ist die Steigerung ihrer Freude ein wichtiger Faktor.
Als nächstes kam sklearn.ensemble.RandomForestRegressor, der nach einer kurzen Auswahl von Hyperparametern MAE = 1,10 zeigte. Als nächstes haben wir XGBoost (wo ohne) versucht - alles wäre in Ordnung und MAE = 1.03 - nur eine sehr lange Zeit. Leider hatten wir keinen Zugriff auf die GPU, um XGBoost zu trainieren, und auf Prozessoren wurde ein Modell sehr lange trainiert. Wir haben versucht, etwas schneller zu finden, und uns für LightGBM entschieden - es trainierte doppelt so schnell und zeigte MAE sogar etwas weniger - 1,01.
Wir haben alle Produkte in 13 Kategorien unterteilt, wie im Katalog auf der Website: Tische, Laptops, Flaschen, und für jede Kategorie haben wir Modelle mit unterschiedlichen Prognosetiefen trainiert - von 5 bis 16 Tagen.
Das Training dauerte ungefähr fünf Tage, und dafür haben wir riesige Computercluster aufgebaut. Wir haben eine solche Pipeline entwickelt: Die Zufallssuche funktioniert lange, gibt die Top-10-Sätze von Hyperparametern an und der Wissenschaftler arbeitet dann manuell mit ihnen - erstellt zusätzliche Qualitätsmetriken (wir haben die MAE für verschiedene Zielbereiche berechnet), erstellt Lernkurven (zum Beispiel haben wir einen Teil des Trainings verworfen) Proben und erneut trainiert, um zu überprüfen, ob neue Daten den Verlust der Testprobe und anderer Grafiken verringern.
Ein Beispiel für eine detaillierte Analyse für einen der Hyperparametersätze:
Detaillierte QualitätsmetrikZugset:
| Testset:
|
| Für Ziel = 0 ist MAE = 0,142222484602 | Für 0 MAE = 0,141900737761 |
| Für Ziel> 0 ist MAPE = 45.168530676 | Für> 0 MAPE = 45.5771812826 |
| Fehler größer als 0 - 67.931341691% | Fehler größer als 0 - 51.6405939896% |
| Fehler größer als 1 - 19.0346986379% | Fehler größer als 1 - 12.1977096603% |
| Fehler mehr als 2 - 8.94313926245% | Fehler mehr als 2 - 5.16977226441% |
| Fehler mehr als 3 - 5.42406856507% | Fehler mehr als 3 - 3.12760834969% |
Fehler mehr als 4 - 3.67938161595%
| Fehler mehr als 4 - 2.10263125679% |
Fehler mehr als 5 - 2.67322988948%
| Fehler mehr als 5 - 1,56473158807%
|
Fehler mehr als 6 - 2.0618556701%
| Fehler mehr als 6 - 1.19599209102%
|
| Fehler mehr als 7 - 1.65887701209% | Fehler größer als 7 - 0,949300173983%
|
Fehler mehr als 8 - 1.36821095777%
| Fehler mehr als 8 - 0,78310772461% |
| Fehler mehr als 9 - 1.15368611519% | Fehler größer als 9 - 0,659205318158%
|
| Fehler mehr als 10 - 0,99199395014% | Fehler mehr als 10 - 0,554593106723% |
| Fehler mehr als 11 - 0,863969667827% | Fehler mehr als 11 - 0,490045146476%
|
Fehler mehr als 12 - 0,764347266082%
| Fehler mehr als 12 - 0,428835873827%
|
| Fehler mehr als 13 - 0,68086818247% | Fehler mehr als 13 - 0,386545830907%
|
| Fehler mehr als 14 - 0,613446089087% | Fehler mehr als 14 - 0,343884822697%
|
Fehler mehr als 15 - 0,556297016335%
| Fehler mehr als 15 - 0,316433391328%
|
Für Ziel = 0 ist MAE = 0,142222484602
| Für Ziel = 0 ist MAE = 0,141900737761
|
Für Ziel = 1 ist MAE = 0,63978556493
| Für Ziel = 1 ist MAE = 0,660823509405 |
| Für Ziel = 2 ist MAE = 1.01528075312 | Für Ziel = 2 ist MAE = 1.01098070566 |
| Für Ziel = 3 ist MAE = 1,43762342295 | Für Ziel = 3 ist MAE = 1,44836233499 |
Für Ziel = 4 ist MAE = 1,82790678437
| Für Ziel = 4 ist MAE = 1,86539223382
|
Für Ziel = 5 ist MAE = 2.15369976552
| Für Ziel = 5 ist MAE = 2.16017884573 |
Für Ziel = 6 ist MAE = 2,51629758129
| Für Ziel = 6 ist MAE = 2,51987403661
|
Für Ziel = 7 ist MAE = 2,80225497415
| Für Ziel = 7 ist MAE = 2,97580015564
|
Für Ziel = 8 ist MAE = 3.09405048248
| Für Ziel = 8 ist MAE = 3,21914648525
|
Für Ziel = 9 ist MAE = 3,39256765159
| Für Ziel = 9 ist MAE = 3,54572928241
|
| Für Ziel = 10 ist MAE = 3,6640339953 | Für Ziel = 10 ist MAE = 3,84409605282
|
Für Ziel = 11 ist MAE = 4.02797747118
| Für Ziel = 11 ist MAE = 4,21828735273
|
Für Ziel = 12 ist MAE = 4,17163467899
| Für Ziel = 12 ist MAE = 3,92536509115
|
Für Ziel = 14 ist MAE = 4,78590364522
| Für Ziel = 14 ist MAE = 5,11290428675 |
Für Ziel = 15 ist MAE = 4,89409916994
| Für Ziel = 15 ist MAE = 5.20892023117
|
Zugverlust = 0,535842111392
Testverlust = 0,895529959873
Diagrammvorhersage (Ziel) für den Trainingssatz Graph Vorhersage (Ziel) für Testprobe Vorhersagefehler von Zeit zu Zeit Sortieren Sie den aufsteigenden Fehler am Testmuster Wenn keine übereinstimmen, suchen Sie erneut nach dem Zufallsprinzip. So haben wir das Modell 5 oder 5 Tage im industriellen Tempo trainiert. Wir waren im Dienst, jemand nachts, jemand wachte morgens auf, schaute sich die Top 10 Parameter an, startete das Modell neu oder speicherte es und ging weiter ins Bett. In diesem Modus haben wir eine Woche lang gearbeitet und 130 Modelle geschult - 13 Warentypen und 10 Prognosetiefen mit jeweils 170 Merkmalen. Die durchschnittliche MAE für den 5-fachen Zeitreihen-Lebenslauf betrug 1.
Es scheint, dass dies nicht sehr cool ist - und das ist so, es sei denn, Sie haben einen großen Anteil an der Auswahl der Einheiten. Wie eine Analyse der Ergebnisse zeigt, werden Einheiten am schlimmsten vorhergesagt - die Tatsache, dass ein Produkt einmal pro Woche gekauft wurde, sagt nichts darüber aus, ob eine Nachfrage danach besteht. Sobald etwas verkauft werden kann, gibt es eine Person, die eine Porzellanfigur in Form eines Zahnarztes kauft, und dies sagt nichts über zukünftige oder vergangene Verkäufe aus. Im Allgemeinen waren wir darüber nicht sehr verärgert.
Tipps und Tricks
Was ist schief gelaufen und wie kann dies vermieden werden?
Das erste Problem ist die Auswahl der Parameter. Wir haben angefangen, RandomizedSearchCV zu verwenden - ein bekanntes Tool von sklearn zum Sortieren von Hyperparametern. Hier erwartete uns die erste Überraschung.
Sofrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Die Berechnung bleibt einfach stehen (was wichtig ist, sie fällt nicht ab, sondern funktioniert weiter, aber auf einer immer kleineren Anzahl von Kernen und irgendwann hört sie einfach auf).
Ich musste den Prozess aufgrund von RandomizedSearchCV parallelisierenestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
RandomizedSearchCV erfasst jedoch fast den gesamten Datensatz für jeden „Job“. Dementsprechend ist es notwendig, die RAM-Menge stark zu erweitern, wodurch möglicherweise die Anzahl der Kerne geopfert wird.
Wer würde uns dann von so wunderbaren Dingen wie Hyperopt erzählen! Da wir gelernt haben, verwenden wir es nur.
Ein weiterer Trick, der uns gegen Ende des Projekts einfiel, war die Auswahl von Modellen mit dem Parameter colsample_bytree (dies ist der LightGBM-Parameter, der angibt, wie viel Prozent der Funktionen jedem Lener zugewiesen werden sollen) im Bereich von 0,2 bis 0,3, denn wenn das Auto Es funktioniert in der Produktion, es gibt möglicherweise keine Tabellen und einzelne Features werden möglicherweise nicht richtig gezählt. Durch eine solche Regularisierung können Sie sicherstellen, dass diese nicht berücksichtigten Funktionen zumindest nicht alle Lernenden im Modell betreffen.
Empirisch sind wir zu dem Schluss gekommen, dass wir mehr Schätzer erstellen und die Regularisierung härter verdrehen müssen. Dies ist keine Arbeitsregel für LightGBM, aber ein solches Schema hat bei uns funktioniert.
Nun und natürlich Spark. Zum Beispiel gibt es einen Fehler, den Spark selbst kennt: Wenn Sie mehrere Spalten aus einer Tabelle nehmen und eine neue erstellen und dann andere aus derselben Tabelle nehmen und eine neue erstellen und dann die erhaltenen Tabellen einstellen, wird alles kaputt gehen, obwohl dies nicht der Fall sein sollte. Sie können nur gerettet werden, indem Sie alle faulen Berechnungen loswerden. Wir haben sogar eine spezielle Funktion geschrieben - bumb_df, die den Datenrahmen in eine RDD zurück in einen Datenrahmen verwandelt. Das heißt, es werden alle verzögerten Berechnungen zurückgesetzt. Dies kann Sie vor den meisten Spark-Problemen schützen.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
Die Prognose ist fertig: Wie viel werden wir bestellen?
Die Umsatzprognose ist eine rein mathematische Aufgabe, und wenn die Normalverteilung eines Null-Mittelwert-Fehlers für einen Mathematiker ein Sieg ist, dann ist dies für Händler, die jeden Rubel auf ihrem Konto haben, inakzeptabel.
Wenn ein zusätzliches iPhone oder ein modisches Kleid im Lager kein Problem darstellt, sondern ein Versicherungsbestand, bedeutet das Fehlen desselben iPhones im Lager einen Verlust von mindestens einer Marge und maximalem Image, und dies kann nicht zugelassen werden.
Um dem Algorithmus beizubringen, so viel wie nötig zu kaufen, mussten wir die Kosten für den Wieder- und Unterkauf jedes Produkts berechnen und ein einfaches Modell trainieren, um mögliche Geldverluste zu minimieren.
Das Modell erhält am Eingang eine Umsatzprognose, fügt zufälliges, normalverteiltes Rauschen hinzu (wir simulieren die Mängel der Lieferanten) und lernt, genau so viel zur Prognose für jedes einzelne Produkt hinzuzufügen, um Geldverluste zu minimieren.
Ein Auftrag ist also eine Prognose + Sicherheitsbestand, der die Abdeckung des Prognosefehlers und der Unvollkommenheit der Außenwelt garantiert.
Wie in prod
Ozon hat einen eigenen ziemlich großen Computercluster, in dem jede Nacht eine Pipeline (wir verwenden Luftstrom) von mehr als 15 Jobs gestartet wird. Es sieht so aus:

Jede Nacht wird der Algorithmus gestartet, zieht etwa 20 GB Daten aus verschiedenen Quellen in lokale HDFS, wählt einen Lieferanten für jedes Produkt aus, sammelt Funktionen für jedes Produkt, erstellt eine Verkaufsprognose und generiert Bestellungen basierend auf dem Lieferplan. Um 6-7 Uhr geben wir dem Tisch Personen, die für die Arbeit mit Lieferanten verantwortlich sind, vorgefertigte Tische, die per Knopfdruck an die Lieferanten fliegen.
Keine einzige Prognose
Das trainierte Modell kennt die Abhängigkeit der Prognose von einem Merkmal. Wenn Sie also N-1-Zeichen einfrieren und eines ändern, können Sie beobachten, wie sich dies auf die Prognose auswirkt. Das Interessanteste daran ist natürlich, wie der Umsatz vom Preis abhängt.
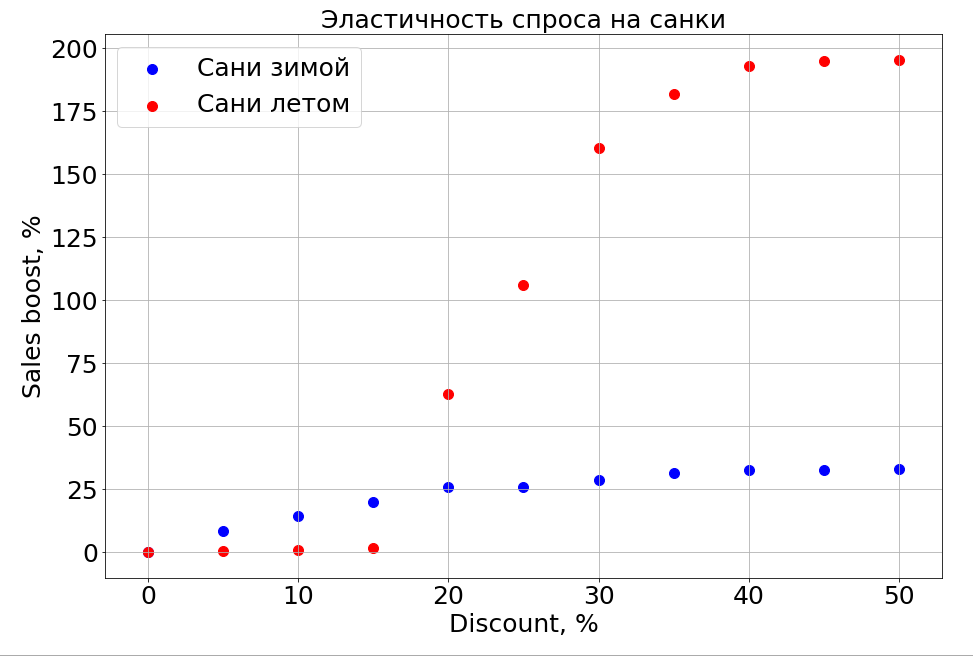
Es ist wichtig zu beachten, dass die Nachfrage nicht nur vom Preis abhängt. Wenn Sie beispielsweise im Sommer kleine Rabatte auf Schlitten gewähren, hilft dies ihnen immer noch nicht beim Verkauf. Wir machen mehr Rabatt und es erscheinen Leute, die "im Sommer einen Schlitten vorbereiten". Bis zu einem bestimmten Preisnachlass können wir jedoch immer noch nicht den Teil des Gehirns erreichen, der für die Planung verantwortlich ist. Im Winter funktioniert es wie bei jedem Produkt - Sie machen einen Rabatt und es verkauft sich schneller.
Pläne
Jetzt untersuchen wir aktiv die Clusterbildung von Zeitreihen, um Waren basierend auf der Art der Kurve, die ihre Verkäufe beschreibt, auf Cluster zu verteilen. Zum Beispiel saisonal, traditionell beliebt im Sommer oder umgekehrt im Winter. Wenn wir lernen, wie Produkte mit einer langen Verkaufshistorie getrennt werden, möchten wir artikelbasierte Funktionen hervorheben, die Ihnen das Verkaufsmuster für ein neues, gerade erschienenes Produkt zeigen - dies ist vorerst unsere Hauptaufgabe.
Neuronale Netze und parametrische Modelle von Zeitreihen und all dies im Ensemble werden sicherlich weiter gehen.
Insbesondere dank des neuen Prognosesystems wechselte Ozon vom Einkauf von Waren mit Lagerbeständen zu zyklischen Lieferungen, wenn wir von einer Lieferung zur nächsten kaufen und keine Salden auf Lager lagern.
Jetzt müssen wir entscheiden, wie der Algorithmus gelehrt werden soll, um den Verkauf neuer Produkte und ganzer Kategorien vorherzusagen. Nächstes Jahr plant das Unternehmen, den Umsatz um 10 x in Kategorien und um 2,5 in Erfüllungsbereichen zu steigern. Und wir müssen den Modellen mitteilen, dass diese alten Daten relevant sind, aber für einen anderen, früheren Speicher. Und während wir darüber nachdenken, wie es geht.
Die zweite irrationale Sache, die wir vorhersagen müssen, ist Mode. Wie könnte man vorhersagen, dass sich ein Spinner so verkaufen würde? Wie kann man den Verkauf neuer Bücher von Dan Brown vorhersagen, wenn eines seiner Bücher ausverkauft ist und das andere nicht? Während wir daran arbeiten.
Wenn Sie wissen, wie man es besser macht, oder wenn Sie in den Kommentaren Geschichten über den Einsatz von maschinellem Lernen im Kampf haben, werden wir darüber diskutieren.