
Es war einmal ein belauschtes Gespräch
vor einem entfernten, entfernten Geschäft :
NB: - ?
GURU : - «» . . . , ...
NB: - , ?
GURU : - google yandex , . . , .
NB: - ?
GURU : - ?… ...
NB hörte auf zu fragen und befürchtete offenbar, einen deutlich erfahreneren Gesprächspartner zu ärgern.
GURU verdrehte die Augen, als betonte er die Erschöpfung des Proxy-Themas und schwieg ...
Natürlich wusste
GURU , dass eine Suchabfrage (zum Beispiel mit dem Wort: Proxy)
NB sehr bald dazu bringen würde, die gewünschte Adresse zu erhalten: Portliste. Aber nach den ersten Experimenten wird
NB genauso schnell verstehen:
- Nicht alle Adressen auf seiner Liste funktionieren.
- Nicht alle Proxies sind gleich gut.
- Das manuelle „Ankleben“ einer Site durch einen Proxy ist eine Aufgabe, die erheblichen Willen erfordert.
- Ein "falscher" Proxy schadet der Situation, weil Die Site kann durch Skripte von Riesen im Wrap vermutet werden.
In diesem Artikel werde ich darüber sprechen, wie improvisiert (und vor allem universell) bedeutet
(ohne spezielle proprietäre Software wie
ZennoPoster usw. zu verwenden)
Erstellen Sie ein automatisiertes Tool, um eine Liste der „wirklich geeigneten“ Proxys zu erhalten und diese zu verwenden, um (automatisierte) Besuche bei den beförderten Vertretern zu organisieren
Website mit dem
Chrome-Browser .
Wenn Sie den Anweisungen folgen, erhalten Sie ein vorgefertigtes Tool, mit dem Sie:
- Klicken Sie ganz automatisch auf die Zielwebsite, ohne Kompromisse einzugehen.
- Benutzerverhalten vollständig emulieren;
- Organisieren Sie alle Besuche nach einem Zeitplan (Szenario).
- Führen Sie alle oben genannten Schritte so oft aus, bis Sie vorankommen.
Obwohl meine gesamte Arbeit (zusammen mit der Recherche) eine Woche dauerte, benötigen Sie keine zwei Tage, um ein solches Tool zu erstellen, das über Grundkenntnisse in
Befehlszeile ,
PHP und
JavaScript verfügt .
Bevor Sie jedoch unter das
folgende Diagramm scrollen, möchte ich einige Worte darüber sagen, warum und für wen dieses Material vorbereitet ist.
Das Material ist nützlich, wenn Sie verstehen möchten, wie die Konstruktionen (? Oder Konstruktoren?) Angelegt sind, mit denen Sie eine Anwendung relativ schnell, einfach und kostenlos erstellen können, die an Laständerungen angepasst werden kann. Wenn Sie an der Möglichkeit interessiert sind, eine Anwendung basierend auf einem Service Bus (
ESB ) zu erstellen.
Der Text ist hilfreich, wenn Sie sich mit der Verwendung von
Docker für
Instant Building-Systeme vertraut machen möchten. Oder wenn Sie nur an
Selenium Server und den Nuancen des Empfangs von Inhalten / Manifestationen von HTTPx-Aktivitäten interessiert sind.
Für "sofort verwenden" lohnt es sich nicht, all dies nachdenklich zu lesen. Der Code ist sicher.
Fahren Sie direkt mit dem Einrichten des fertigen Werkzeugs fort. Die Einrichtung dauert weniger als 20 Minuten.In diesem Handbuch wird davon ausgegangen, dass Ihnen 2 Computer mit installiertem Ubuntu 18.04 zur Verfügung stehen.
Eine für die Infrastruktur (
Docker ), die andere für die Prozesssteuerung (
Prozess ).
Es wird davon ausgegangen, dass die folgenden Pakete bereits auf
Docker installiert sind:
Git, Docker, Docker-Compose
Es wird davon ausgegangen, dass die folgenden Pakete bereits auf dem
Prozess installiert
sind :
Git, PHP-Common, PHP-Cli, PHP-Curl, PHP-Zip, PHP-Memcached, Komponist
Wenn Sie an dieser Stelle Fragen haben, empfehle ich Ihnen, 15 Minuten lang das gesamte Material zu lesen.
Docker
Prozess
Warten Sie und beobachten Sie, was über das Web-Panel passiert (http: // IP-Adresse-Docker-Maschinen: 8080).
Das Ergebnis wird in der gefundenen Warteschlange verfügbar sein.
Crushing und Planung
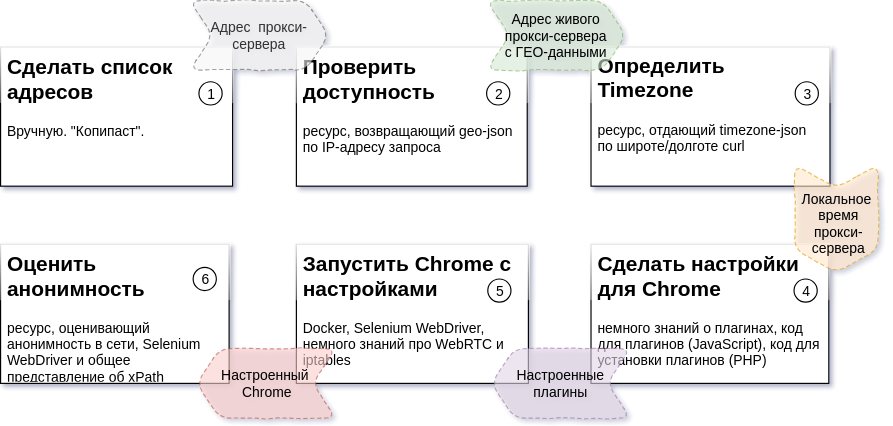
Das obige Diagramm beschreibt die Abfolge der Prozessschritte, das erwartete Ergebnis für jeden Schritt und die Ressourcen, die zum Erstellen jedes Teils erforderlich sind (Details:
Aufgabe 2 ,
Aufgabe 3 ,
Aufgabe 4,5,6 ).
In meinem Fall passiert alles auf zwei
Ubuntu 18.04- Rechnern. Einer von ihnen steuert den Prozess. Auf der anderen Seite werden mehrere Docker-Container für die Infrastruktur ausgeführt.
Ausreden und Misserfolge
Der gesamte Paketcode besteht aus drei Teilen.
Einer von ihnen gehört nicht mir (ich stelle fest, dass dies ein ordentlicher und schöner Code ist). Die Quelle für diesen Code ist packagist.org .
Ich selbst habe einen anderen geschrieben, ich habe versucht, ihn verständlich zu machen und habe ungefähr eine Woche diesem Teil des Codes gewidmet.
Der Rest ist ein „schwieriges historisches Erbe“. Dieser Teil des Codes wurde über einen längeren Zeitraum erstellt. Einschließlich zu einer Zeit, als ich nicht viel Programmierkenntnisse hatte.
Dies ist genau der Grund für die Position von Repositorys auf meinem GitLab und Paketen auf meinem Satis . Um auf GitHub.com und packagist.org zu veröffentlichen, muss dieser Code verarbeitet und ausführlicher dokumentiert werden.
Alle Teile des Codes können unbegrenzt verwendet werden. Repositories und Pakete sind für immer verfügbar.
Bei der erneuten Veröffentlichung des Codes bin ich jedoch dankbar, dass ich einen Link zu mir oder zu diesem Artikel veröffentlicht habe.
Ein bisschen über Architektur
Der Ansatz, der zum Erstellen unseres Tools verwendet wurde, besteht darin, ein vorgefertigtes Dienstprogramm zum Lösen jeder bestimmten Aufgabe zu schreiben (oder zu verwenden). Darüber hinaus hat jedes Dienstprogramm unabhängig von der zu lösenden Aufgabe zwei Eigenschaften, die allen gemeinsam sind:
- Das Dienstprogramm kann unabhängig von den anderen über die Befehlszeile mit Parametern gestartet werden, die die Aufgabe enthalten.
- Das Dienstprogramm kann das Ergebnis der Ausführung an stdout zurückgeben (nachdem es auf eine bestimmte Weise konfiguriert wurde).
Mit einer nach diesem Prinzip erstellten Lösung können Sie die Anzahl der ausgeführten Task-Handler (Worker) für jeden der Prozessschritte ändern. Eine unterschiedliche Anzahl von Mitarbeitern für jeden Schritt führt aufgrund der Länge der Verarbeitungsaufgaben der vorherigen Schritte zu einer Ausfallzeit von „0“ für die folgenden Schritte.
Die Zeit, die zum Abrufen einer Einheit des Ergebnisses des Prozesses (in unserem Fall eines verifizierten Proxys) aufgewendet wird, hängt von externen Faktoren ab (Anzahl der ungeeigneten Proxys, Antwortzeit einer externen Ressource usw.).
Indem wir die Anzahl der Arbeiter für jeden der Prozessschritte ändern, wandeln wir diese Abhängigkeit in eine Abhängigkeit von der Anzahl der laufenden Arbeiter um (d. H. Abhängig von den beteiligten Rechen- und Kanalkapazitäten).
Um den Betrieb einzelner unabhängiger Teile zu synchronisieren, ist es zweckmäßig, den Messaging-Warteschlangenserver als einzelnen Datenbus zu verwenden. Auf diese Weise können Sie die Ergebnisse der abgeschlossenen Schritte in der Warteschlange sammeln und sie zum richtigen Zeitpunkt als Eingabe an das Dienstprogramm "Nächster Schritt" weitergeben.
Messaging-Warteschlange. MQ und ESB
Als untere Ebene (
MQ ) verwenden wir
Beanstalkd . Klein, leicht, konfigurationsfrei, verfügbar im Deb-Paket und im Docker-Container, ein unauffälliger harter Arbeiter. Die logische Ebene (
ESB ) implementiert den Code in
PHP .
Für die Implementierung werden zwei Klassen verwendet.
esbTask und
nextStepWorker .
esbTask class esbTask // , {
Eine Instanz dieser Klasse dient dazu,
Paylod durch die Schritte des Prozesses zu "adressieren". Das
ESB- Konzept wendet mehrere Prinzipien / Muster an. Zwei davon sind es wert, getrennt betrachtet zu werden:
- Über den Pfad (Abfolge von Schritten) des Prozesses, zu jedem Zeitpunkt des Prozesses
niemand weiß es außer dem zu sendenden Umschlag;
- Jeder Umschlag hat drei mögliche Ergebnisrichtungen:
- der nächste Schritt des Prozesses (normale Fortsetzung);
- Stoppschritt (Stoppziel - wird im nächsten Schritt ausgewählt, wenn es keinen Sinn macht, die Prozess- / Stoppsituation fortzusetzen);
- Fehlerschritt (Notfallbeendigungsziel - wird im Falle eines Arbeitsfehlers im nächsten Schritt ausgewählt).
Das in die Warteschlange gestellte Objekt wird in json dargestellt, hier versteckt ... nextStepWorkerJede Nachricht, die in der Warteschlange angezeigt wird, wird von dem dafür verantwortlichen Mitarbeiter verarbeitet. Zu diesem Zweck werden die folgenden Funktionen implementiert:
class nextStepWorker extends workerConstructor {
Arbeiter für jeden der Prozessschritte werden auf der Basis dieser Klasse implementiert. Die gesamte Routine zum Verarbeiten, Adressieren und Senden des nächsten Schritts auf der Route erledigt die Klasse.
Die Lösung für jedes der Probleme lautet:
- Holen Sie sich esbTask und führen Sie den Worker aus.
- Implementieren Sie die Logik, indem Sie die Ergebnisse in der Nutzlast speichern.
- Schließen Sie die Hinrichtung des Arbeiters ab (Notfall oder normal - es spielt keine Rolle).
Wenn die Schritte abgeschlossen sind, wird das Ergebnis mit dem entsprechenden Namen in die Warteschlange gestellt und der nächste Mitarbeiter beginnt mit der Verarbeitung.
Mach es einmal. Verfügbarkeit prüfen
In der Tat ist die Schaffung eines Arbeitnehmers zur Lösung eines der Probleme die Implementierung einer Methode. Ein Beispiel (vereinfacht) für die Implementierung eines Arbeiters, der
Problem 2 löst,
lautet wie folgt:
Ein paar Codezeilen und alles ist erledigt und wird zur nächsten Stufe „abgeordnet“.
Zeitzone definieren. TimeZoneDB und wofür es ist ...
Beim eingehenden Testen eingehender Anforderungen wird die Zeit des Browserfensters mit dem Zeitpunkt abgeglichen, zu dem die IP-Adresse der Anforderungsquelle vorhanden ist.
Um den Verdacht der Zähler zu vermeiden, müssen wir die lokale Proxy-Zeit kennen.
Um die Zeit herauszufinden, nehmen wir den Breiten- und Längengrad aus den Ergebnissen des vorherigen Schrittes des Prozesses und erhalten Daten über die Zeitzone, in der unsere zukünftige Instanz des Browserfensters arbeiten wird. Diese Daten werden uns von
Fachleuten auf dem Gebiet der Zeit zur Verfügung gestellt .
Ein vereinfachter Mitarbeiter zur Lösung dieses Problems (
Aufgabe 3 ) ist dem
vorherigen völlig ähnlich. Der einzige Unterschied ist die Anforderungs-URL. Die Vollversion finden Sie in der Datei:
// app / src / Process / worker / timeZone.php
Ein bisschen über Infrastruktur
Zusätzlich zu der beschriebenen
Bohnenstange benötigt unser Tool:
- Memcached - zum Zwischenspeichern von Aufgaben;
- Selenium Server - Es ist praktisch, den Selenium Web Driver in einem separaten Container auszuführen, und Sie können den Prozess über VNC überwachen.
- Dashboards zur Überwachung von Beanstald , Memcached und VNC .
Für eine schnelle Bereitstellung all dessen ist Docker (
Installation unter Ubuntu ) sehr praktisch.
Und der "Orchestrator" für ihn ist Docker-Compose (Befehle zur Installation) ... sudo apt-get -y update sudo apt-get -y install docker-compose
Mit diesen Tools können Sie bereits konfigurierte und konfigurierte (von einer früheren Person) Server / Prozesse in separaten „Containern“ des übergeordneten Betriebssystems ausführen. Für Details empfehle ich, auf
diesen oder
diesen Artikel zu verweisen.
Also ...
Zum Starten der Infrastruktur benötigen Sie mehrere Befehle in der Konsole:
Als Ergebnis der erfolgreichen Ausführung des Befehls auf dem Computer mit der Adresse XXX.XXX.XXX.XXX,
Sie erhalten die folgenden Dienstleistungen:
- XXX.XXX.XXX.XXX:11300 - Beanstalkd
- XXX.XXX.XXX.XXX:11211 - Memcached
- XXX.XXX.XXX.XXX-00-00444 - Selenium Server
- XXX.XXX.XXX.XXX:5930 - VNC- Server zur Steuerung der Vorgänge in Chrome
- XXX.XXX.XXX.XXX:8081 - Webpanel für die Kommunikation mit Memcached (admin: pass)
- XXX.XXX.XXX.XXX:8082 - Webpanel für die Kommunikation mit Beanstalkd
- XXX.XXX.XXX.XXX:8083 - Webpanel für die Kommunikation mit VNC (Passwort: geheim)
- XXX.XXX.XXX.XXX:8080 - Allgemeines Webpanel
"Sehen Sie, ob alles vorhanden ist", "In die Konsole zum Container gelangen", "Infrastruktur stoppen" können Befehle im Spoiler sein. Aufgaben 4,5,6 - zu einem Dienstprogramm zusammenfassen
Nachdem Sie sich eingehend mit Aufgaben befasst haben (
Abbildung oben ), können Sie leicht sicherstellen, dass nur eine der verbleibenden Aufgaben (
Aufgabe 6 ) von einer externen Ressource abhängt. Wenn wir Aufgaben mit "bedingt garantierten" Laufzeiten ausführen (unabhängig von unkontrollierten Faktoren), erhalten wir keine zusätzlichen Vorteile für die Geschwindigkeit des gesamten Prozesses. In dieser Hinsicht wurden diese Aufgaben (
4,5,6 ) zu einem Arbeiter zusammengefasst. Die Worker-Datei heißt:
// app / src / Process / worker / whoerChecker.php
Nehmen Sie Einstellungen für Chrome vor. Plugins
Chrome ist flexibel mit Plugins konfiguriert.
Ein Plugin für
Chrome ist ein Archiv, das eine Datei
manifest.json enthält. Er beschreibt das Plugin. Das Archiv enthält auch eine Reihe von
JavaScript-, HTML-, CSS- und anderen Dateien, die vom Plugin benötigt werden (
Details ).
In unserem Fall wird eine der
JavaScript- Dateien im Kontext des
Chrome- Arbeitsfensters ausgeführt und alle erforderlichen Einstellungen werden wirksam.
Wir müssen nur die Plugin-Vorlage nehmen und die erforderlichen Daten (Interaktionsprotokoll, Adresse und Port oder Zeitzone) für den zu testenden Proxyserver an den richtigen Stellen ersetzen.
Ein Codeausschnitt, der das Archiv erstellt:
Die Vorlage für das Proxy-Tuning-Plugin wurde
im Sparschwein der Arbeitsergebnisse von Menschen gefunden, die ihren Beruf lieben , im Protokollteil geändert und dem Repository hinzugefügt.
Fensterzeitänderung
Um die globale Zeit einer laufenden Chrome-Instanz zu ändern, müssen wir
window.Date durch eine Klasse mit ähnlicher Funktionalität ersetzen, die jedoch in der richtigen Zeitzone gültig ist.
Ich schätze
die Arbeit von Sampo Juustila sehr . Das Skript wurde zum automatisierten Testen der
Benutzeroberfläche erstellt , aber nach einer kleinen Verfeinerung wurde es angewendet.
Hier gibt es eine Nuance, auf die ich Ihre Aufmerksamkeit lenken möchte. Es ist mit dem Kontext der in
manifest.json beschriebenen Skripte verknüpft.
Das ganze Geheimnis ist, dass der globale Kontext (derjenige, in dem das Hauptskript des Plug-Ins gestartet und die Einstellungen festgelegt werden, z. B. mit dem Netzwerk verbunden) vom Kontext der Registerkarte isoliert ist, in die die Seite geladen wird.
Empirisch wurde festgestellt, dass die Auswirkungen auf den Prototyp der Klasse im globalen Kontext nicht zu einer Änderung der Registerkarte führten. Nachdem das Skript auf der bereits geladenen Seite registriert und vor den anderen ausgeführt wurde, wurde das Problem behoben.
Die Lösung wird durch das folgende Codefragment dargestellt:
Proxy-Einstellungen
Das Einrichten eines Proxys in Chrome ist so einfach, dass ich den js-Code in einem Spoiler verstecke Pfad der Chrome-Plugins
Alle Plugins werden gemäß dem Schema benannt und dem temporären Ordner des Computers hinzugefügt, der den Prozess steuert.// Namensschema für Proxy-Plugin:
Proxy- [Adresse] - [Port] - [Protokoll]>. zip
Zeitverschiebung - ["-" | ""] - [shift_in_minutes_from_GMT] .zip
Als Nächstes müssen wir diese Plugins in einem Docker-Container installieren, der auf dem für die Infrastruktur verantwortlichen Computer ausgeführt wird.
Wir werden dies mit ssh tun.
Dazu habe ich phpseclib getroffen (noch später bereut). Fasziniert von dem ungewöhnlichen Verhalten der Bibliothek verbrachte ich einen Tag damit, sie zu studieren.Der SSH-Konsolen-Client funktioniert hier besser und schneller, aber die Aufgabe wurde bereits erledigt.Für die niedrige Ebene (Arbeit mit SFTP und SSH) ist die Basisklasse verantwortlich (siehe unten). Durch Ersetzen dieser Klasse wird phpseclib durch den Konsolenclient ersetzt.
Abgeleitet vom Basis-sshDocker und der bereits bekannten proxyHelper-Klasse werden Plugins nicht nur erstellt, sondern auch in einem temporären Ordner des Infrastrukturcontainers abgelegt.
Starten Sie Chome mit Einstellungen
Selenium Server hilft uns beim Start von angepasstem Chrome . Selenium Server ist ein Framework, das vom FaceBook- Team speziell zum Testen von WEB-Schnittstellen erstellt wurde. Die Rahmenarbeit ermöglicht es dem Entwickler, jede Benutzeraktion in einem Browserfenster (mit Chrome oder Firefox ) programmgesteuert zu emulieren . Selenium Server ist für die Verwendung in vielen Sprachen angepasst und de facto ein Standardwerkzeug zum Schreiben von Testskripten. Der beste Weg, um eine neue Version für ein Projekt zu erhalten: composer require facebook/webdriver
Die traditionelle Konfiguration der Hauptinstanz des Selenium Server-Objekts (RemoteWebDriver) erschien mir ausführlich. Deshalb habe ich das alles leicht reduziert und die Konfiguration für meine Bedürfnisse optimiert:
Das Auge klammert sich sofort an $ Plugins. $ plugins ist eine Datenstruktur, die für die Konfiguration von Plugins verantwortlich ist. Für jedes Verzeichnis und zum Ersetzen von Platzhaltern in den Plugin- JavaScript- Dateien.Die Struktur wird in der Datei app / plugs.php beschrieben und ist Teil der globalen Optionen app / settings.php. Das Parsen einer Seite mit Selenium WebDriver ist sehr einfach. .... $url = 'https://__/_-_'; $page = $chrome->get($url); ....
Wie ich bereits geschrieben habe, werden alle diese Aktionen durch den Nutzen des dritten Schritts ( Aufgabe 4,5,6 ) implementiert :// app / src / Process / worker / whoerChecker.php
Abschließen der Beschreibung der Arbeit mit Selenium Server , möchte ich Ihre Aufmerksamkeit auf die Tatsache lenken , dass , wenn Sie diese Technologie in industriellem Maßstab nutzen (1000 - 3000 Öffnungen Seiten), ungewöhnlich , dass die Sitzung mit dem Selenium Server korrekt abgeschlossen ist. Das Fenster ist besitzerlos. Und solche Fenster können sich sehr ansammeln.Es wurden verschiedene Möglichkeiten zur Bekämpfung der "Broschen" in Betracht gezogen. Arbeit "aß" 2 Tage. Am effektivsten war Cron . Die korrekte Installation und Konfiguration im Docker-Container wurde zu einer separaten Aufgabe, die von renskiy in einem Artikel, der NUR DIESEM THEMA gewidmet war , sorgfältig und sehr gründlich beschrieben wurde (was mich überraschte).Die automatische Neuerstellung des ursprünglichen Docker-Images und die Installation mehrerer Skripte zum Schließen von Broschen und zum Bereinigen nicht verwendeter Plugins wird in docker-compose.yml, dem Infrastruktur-Repository, beschrieben . Die Reinigungshäufigkeit wird in der Killcron-Datei desselben Repositorys festgelegt.WebRTC
Trotz der Tatsache, dass wir bereits die richtige Zeit eingestellt haben und der Datenverkehr unseres Browsers über einen Proxy erfolgt, können wir dennoch erkannt werden.Neben dem Zeitunterschied (Browser und IP-Adresse) gibt es zwei weitere Quellen für die Dekanonymisierung von „hinter einem Proxy sitzen“. Hierbei handelt es sich um im Browser eingebettete Flash- und WebRTC- Technologien. Flash ist in unserem Browser deaktiviert, WebRTC nicht.Der Grund für beide Fehlermöglichkeiten ist der gleiche - die allgegenwärtigen und flinken UDP- Pakete. Für WebRTC sind dies zwei Ports: 3478 und 19302 .Um den Exodus von Scouts aus dem Chrome-Container zu stoppen, wird die iptables-Regel auf den Host-Computer mit den Infrastruktur-Containern angewendet: iptables -t raw -I PREROUTING -p udp -m multiport --dports 3478,19302 -j DROP
Der gleiche ProxyHelper implementiert diese Aufgabe.Der Rest der Arbeiter
Für die erfolgreiche Erreichung des Ziels - die Implementierung eines „Klicks“ auf die Zielwebsite über einen anonymen Proxy - benötigen wir einen weiteren Mitarbeiter.Es wird eine abgeschnittene Version von whoerChecker sein . Ich denke, es alleine zu machen und alles zu verwenden, was geschrieben steht, wird nicht schwierig sein.Das Ergebnis des gesamten Prozesses eine Warteschlange zur Eingabe befindet , enthält Daten über den „Grad“ jeder Anonymität Proxyserveradresse authentifiziert.Wenn Sie gegen die Spielmarken „spielen“, sollten Sie sich vor allem an die Anonymität erinnern und sich nicht von Roboterbesuchen mitreißen lassen. Die Einhaltung des Grundsatzes " Lassen Sie sich nicht von Klicks mitreißen " wird durch die Möglichkeit sichergestellt, Aktionen nach einem Zeitplan zu organisieren, der in esbTask ( seit dem Feld unseres ESB- Umschlags) eingebettet ist .Wenn Sie versuchen, alles sorgfältig zu machen, ähnelt die Yandex-Metrik der Zielwebsite der folgenden Abbildung.
Wie man alles zusammensetzt
Also gegeben:- Dienstprogramme, die "als Eingabe" (als Befehlszeilenargument) esbTask in json-string-Form akzeptieren und eine Logik ausführen und die Ergebnisse an beanstalkd senden können ;
- Message Queuing ( MQ ), basierend auf Beanstalkd ;
- Linux-Maschine (Prozessmaschine);
Mit diesem "Given" verwende ich normalerweise libevent und React PHP . All dies, ergänzt durch mehrere Tools, ermöglicht es Ihnen, die Anzahl (innerhalb bestimmter Grenzen) von Handlerinstanzen für jede Phase des Prozesses automatisch zu steuern.Angesichts der Größe des Artikels und der Besonderheiten des Themas werde ich dies jedoch gerne in einem separaten Artikel beschreiben. Dieser Artikel ist Noserver- Technologie . Zukünftiges Zeug ist " Server ".Das Datum der Veröffentlichung hängt mit Ihrem Interesse zusammen, lieber Leser.. , ,… . , , , , , .
habr , . , , .
. , " server ", README.md .
In " noserver " verarbeitet eine Instanz eine Warteschlange (einen Prozessschritt). Dieser Ansatz kann nur die Geister verärgern, die ich beim Debuggen von Arbeitern verwende.Abhängig von der Verarbeitungsgeschwindigkeit, die Sie benötigen, können Sie beliebig viele Kopien „manuell“ starten.Es kann so aussehen:
Der seltsame Start des Arbeiters ist auffällig ... Trotz der Tatsache, dass jeder der Arbeiter ein PHP-Objekt ist, habe ich exec (...) verwendet .Dies wurde durchgeführt, um Zeit zu sparen, um keine separaten Worker für " noserver " zu erstellen oder um den Worker nicht zu ändern, um im " Server " -Modus zu starten .Ein paar Worte zur Konfiguration und Bereitstellung
Konfigurationskonstanten
Die Konfigurationsdatei für Ihre Instanz lautet app / settings.php . Es sollte von Ihnen sofort nach dem Klonen des Repositorys erstellt werden. Benennen Sie dazu die Datei app / settings.php.dist um . Alle Konstanten werden intern beschrieben.app / settings.php enthält unter anderem Dateien mit anderen Konstanten.- app / queues.php enthält die Namen von Warteschlangen und Jobs
- app / plugs.php enthält eine Beschreibung der Chrome- Plugins
- app / techs.php enthält berechnete Konstanten
Dienstprogramme
Um die Ergebnisse des Prozesses zu verarbeiten und Aufgaben zu platzieren, gibt es mehrere Dienstprogramme. Dienstprogramme werden über die Befehlszeile gestartet. Mit Argumentbeschreibungen versehen. Gefunden: app / src / Utils . backup.php - speichert Warteschlangen in einer Datei
clear.php - bereinigt Warteschlangen
exporter.php - Exportiert aus einer Datei mit einer gespeicherten Warteschlange
Paaradresse: Port
givethejob.php - stellt Aufgaben in den Prozess
(Quelladresse: Port-Kombinationsfeld).
kann einige Adressen von der Liste ausschließen
restore.php - Stellt eine gespeicherte Warteschlange wieder her
Feinabstimmung der Arbeiter
Bei Verwendung schriftlicher Mitarbeiter kann es zweckmäßig sein, die folgenden Konfigurationsoptionen zu verwenden:
Bereitstellung
In diesem Handbuch wird davon ausgegangen, dass Ihnen 2 Computer mit installiertem Ubuntu 18.04 zur Verfügung stehen .Eine für die Infrastruktur ( Docker ), die andere für die Prozesssteuerung ( Prozess ).Docker
Prozess
Warten Sie und beobachten Sie, was über das Web-Panel passiert (http: // IP-Adresse-Docker-Maschinen: 8080).Das Ergebnis wird zur Verfügung stehen in der Warteschlange befindet .Und zum Schluss
Überraschenderweise dauerte das Schreiben und Bearbeiten dieses Artikels länger als das Schreiben des Codes selbst.Meiner Meinung nach könnte alles umgekehrt sein (und der Zeitunterschied könnte um ein Vielfaches größer sein), wenn nicht zwei Ideologien: Message Queue und Enterprise Service Bus .Ich würde mich sehr freuen, wenn Sie den vorgestellten Ansatz zum Schreiben von Anwendungen nützlich finden, dessen Belastung für verschiedene Teile in der Entwurfsphase nicht klar ist.Vielen Dank.