Eintrag
Im Rahmen des Kreditprogramms kooperiert die Bank mit vielen Einzelhandelsgeschäften.
Eines der Schlüsselelemente eines Kreditantrags ist ein Foto des Kreditnehmers - ein Vertreter des Partnergeschäfts fotografiert den Käufer; Ein solches Foto fällt in die „Personalakte“ des Kunden und wird in Zukunft als eine Möglichkeit verwendet, seine Anwesenheit zum Zeitpunkt der Beantragung eines Darlehens zu bestätigen.
Leider besteht immer die Gefahr eines unehrlichen Verhaltens eines Agenten, der möglicherweise ungenaue Fotos an die Bank überträgt - beispielsweise Kundenbilder aus sozialen Netzwerken oder Pässen.
In der Regel lösen Banken dieses Problem, indem sie überprüfen, ob die Mitarbeiter des Fotobüros Fotos betrachten und versuchen, ungenaue Bilder zu identifizieren.
Wir wollten versuchen, den Prozess zu automatisieren und das Problem mithilfe neuronaler Netze zu lösen.
Aufgabenformalisierung
Wir haben nur Fotos untersucht, auf denen sich Menschen befinden. Gesichtslose Bilder können mit der geöffneten
Dlib- Bibliothek
abgeschnitten werden.
Zur Verdeutlichung geben wir Beispiele für Fotos (Bankangestellte sind abgebildet):
 Abb. 1. Fotos vom Point of Sale
Abb. 1. Fotos vom Point of Sale Abb. 2. Fotos aus sozialen Netzwerken
Abb. 2. Fotos aus sozialen Netzwerken Abb. 3. Passfoto
Abb. 3. PassfotoAlso mussten wir ein Modell schreiben, das den Hintergrund des Fotos analysiert. Das Ergebnis ihrer Arbeit war es, die Wahrscheinlichkeit zu bestimmen, mit der das Foto an einer der Verkaufsstellen unserer Partner aufgenommen wurde. Wir haben drei Möglichkeiten zur Lösung dieses Problems identifiziert: Segmentierung, Vergleich mit anderen Fotos am selben Verkaufsort, Klassifizierung. Lassen Sie uns jeden von ihnen genauer betrachten.
A) Segmentierung
Das erste, was mir in den Sinn kam, war, dieses Problem zu lösen, indem das Bild segmentiert und Bereiche mit dem Hintergrund von Partnergeschäften identifiziert wurden.
Nachteile:
- Die Vorbereitung der Trainingsmuster dauert zu lange.
- Ein auf diesem Modell basierender Dienst funktioniert nicht schnell.
Es wurde beschlossen, zu dieser Methode nur zurückzukehren, wenn alternative Optionen aufgegeben wurden. Spoiler: ist nicht zurückgekehrt.
B) Vergleich mit anderen Fotos an derselben Verkaufsstelle
Zusammen mit dem Foto erhalten wir Informationen darüber, in welchem Einzelhandelsgeschäft es hergestellt wurde. Das heißt, wir haben Gruppen von Bildern, die an denselben Verkaufsstellen aufgenommen wurden. Die Gesamtzahl der Fotos in jeder Gruppe variiert zwischen einigen Einheiten und mehreren Tausend.
Eine andere Idee kam auf: ein Modell zu bauen, das zwei Fotos vergleicht und die Wahrscheinlichkeit vorhersagt, dass sie an einer Verkaufsstelle aufgenommen wurden. Dann können wir das neu empfangene Foto mit den vorhandenen Fotos im selben Geschäft vergleichen. Wenn sich herausstellt, dass sie ihnen ähnlich sind, ist das Bild definitiv zuverlässig. Wenn das Bild aus dem Bild herausgeschlagen wird, senden wir es zusätzlich zur manuellen Überprüfung.
Nachteile:
- Unausgeglichene Probenahme.
- Der Service wird lange funktionieren, wenn am Point of Sale viele Fotos vorhanden sind.
- Wenn eine neue Verkaufsstelle angezeigt wird, müssen Sie das Modell neu trainieren.
Trotz der Nachteile haben wir das Modell aus dem
Artikel unter Verwendung der Blöcke der neuronalen Netze VGG-16 und ResNet-50 implementiert. Und ... sie haben in beiden Fällen einen Prozentsatz korrekter Antworten erhalten, der nicht viel höher als 50% ist :(
B) Klassifizierung!
Die verlockendste Idee war es, einen einfachen Klassifikator zu erstellen, der die Fotos in drei Gruppen unterteilt: Fotos von Verkaufsstellen, Pässen und sozialen Netzwerken. Es bleibt nur zu überprüfen, ob dieser Ansatz funktioniert. Nehmen Sie sich auch etwas Zeit, um die Daten für das Training vorzubereiten.
Datenaufbereitung
Im Datensatz von Bildern aus sozialen Netzwerken, die die Dlib-Bibliothek verwenden, wurden nur diejenigen Fotos ausgewählt, die Personen enthalten.
Passfotos mussten anders geschnitten werden, so dass nur das Gesicht übrig blieb. Auch hier kam Dlib zur Rettung. Das Prinzip der Arbeit stellte sich folgendermaßen heraus: Mit Hilfe der Bibliothek wurden die Koordinaten des Gesichts ermittelt -> das Passfoto abgeschnitten und das Gesicht verlassen.
In jeder der 3 Klassen blieben 40.000 Fotos. Vergessen Sie nicht
die DatenerweiterungModell
Gebrauchtes ResNet-50. Sie lösten das Problem als Mehrklassenklassifizierungsproblem mit disjunkten Klassen. Das heißt, es wurde angenommen, dass ein Foto nur einer Klasse angehören kann.
model = keras.applications.resnet50.ResNet50() model.layers.pop() for layer in model.layers: layer.trainable=True last = model.layers[-1].output x = Dense(3, activation="softmax")(last) resnet50_1 = Model(model.input, x) resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
Ergebnisse
In der Testprobe blieben 24.000 Bilder übrig, d. H. 20%. Die Fehlermatrix war wie folgt:
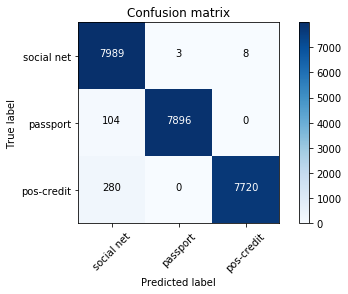
soziales Netz - soziale Netzwerke;
Reisepass - Reisepässe;
pos-credit - Verkaufsstellen, Partner, die Kredite vergeben.
Der Gesamtfehleranteil beträgt 1,6% für Fotos von Verkaufsstellen - 1,2%. Die meisten der falsch definierten Bilder sind Bilder, die zwei Klassen gleichzeitig ähnlich sind. Zum Beispiel wurden fast alle falsch definierten Fotos aus der Pos-Credit-Klasse aus erfolglosen Winkeln aufgenommen (an der weißen Wand ist nur das Gesicht sichtbar). Daher ähnelten sie auch den Fotos aus der Klasse der sozialen Netze. Solche Fotografien hatten eine geringe maximale Wahrscheinlichkeit.
Wir haben einen Schwellenwert für die maximale Wahrscheinlichkeit hinzugefügt. Wenn der Endwert höher ist - wir vertrauen dem Klassifikator, niedriger - senden wir das Bild zur manuellen Überprüfung.
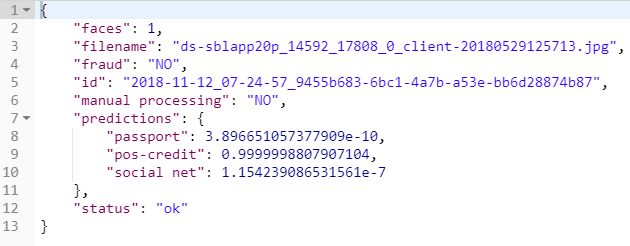
Als Ergebnis das Ergebnis des Dienstes für die Fotografie

sieht so aus:
Zusammenfassung
Anhand eines einfachen Modells haben wir gelernt, wie wir automatisch feststellen können, dass ein Foto an einer der Verkaufsstellen unserer Partner aufgenommen wurde. Dies ermöglichte es uns, einen Teil des umfangreichen Prozesses zur Genehmigung eines Kreditantrags zu automatisieren.