GitHub verwendet MySQL als primäres Data Warehouse für alles, was nicht mit git tun hat. git ist die Verfügbarkeit von MySQL der Schlüssel zum normalen Betrieb von GitHub. Die Site selbst, die GitHub-API, das Authentifizierungssystem und viele andere Funktionen erfordern Zugriff auf Datenbanken. Wir verwenden mehrere MySQL-Cluster, um verschiedene Dienste und Aufgaben zu erledigen. Sie werden nach dem klassischen Schema konfiguriert, wobei ein Hauptknoten für die Aufzeichnung und seine Replikate verfügbar ist. Replikate (andere Clusterknoten) reproduzieren asynchron Änderungen am Hauptknoten und bieten Lesezugriff.
Die Verfügbarkeit von Host-Sites ist entscheidend. Ohne den Hauptknoten unterstützt der Cluster keine Aufzeichnung, sodass Sie die erforderlichen Änderungen nicht speichern können. Das Beheben von Transaktionen, das Registrieren von Problemen, das Erstellen neuer Benutzer, Repositorys, Überprüfungen und vieles mehr ist einfach unmöglich.
Zur Unterstützung der Aufzeichnung ist ein entsprechender zugänglicher Knoten erforderlich - der Hauptknoten im Cluster. Die Fähigkeit, einen solchen Knoten zu identifizieren oder zu erkennen , ist jedoch ebenso wichtig.
Bei einem Ausfall des aktuellen Hauptknotens ist es wichtig, dass ein neuer Server sofort angezeigt wird, um ihn zu ersetzen, und dass alle Dienste schnell über diese Änderung informiert werden können. Die gesamte Ausfallzeit besteht aus der Zeit, die benötigt wird, um einen Fehler zu erkennen, ein Failover durchzuführen und über einen neuen Hauptknoten zu benachrichtigen.

Diese Veröffentlichung beschreibt eine Lösung zur Sicherstellung einer hohen Verfügbarkeit von MySQL in GitHub und zur Ermittlung des Hauptdienstes, mit der wir zuverlässig Vorgänge in mehreren Rechenzentren ausführen, die Funktionsfähigkeit aufrechterhalten können, wenn einige dieser Zentren nicht verfügbar sind, und im Ausfallfall minimale Ausfallzeiten gewährleisten können.
Hochverfügbarkeitsziele
Die in diesem Artikel beschriebene Lösung ist eine neue, verbesserte Version früherer Hochverfügbarkeitslösungen (HA), die auf GitHub implementiert wurden. Während wir wachsen, müssen wir die MySQL HA-Strategie anpassen, um sie zu ändern. Wir bemühen uns, ähnliche Ansätze für MySQL und andere Dienste auf GitHub zu verfolgen.
Um die richtige Lösung für Hochverfügbarkeit und Serviceerkennung zu finden, sollten Sie zunächst einige spezifische Fragen beantworten. Hier ist eine Beispielliste von ihnen:
- Welche maximale Ausfallzeit ist für Sie unkritisch?
- Wie zuverlässig sind Fehlererkennungswerkzeuge? Sind Fehlalarme (vorzeitige Fehlerverarbeitung) für Sie kritisch?
- Wie zuverlässig ist das Failover-System? Wo kann ein Fehler auftreten?
- Wie effektiv ist die Lösung in mehreren Rechenzentren? Wie effektiv ist die Lösung in Netzwerken mit niedriger und hoher Latenz?
- Funktioniert die Lösung auch bei einem vollständigen Ausfall des Rechenzentrums (DPC) oder einer Netzwerkisolation weiter?
- Welcher Mechanismus (falls vorhanden) verhindert oder mildert die Folgen der Entstehung von zwei Hauptservern im Cluster, die unabhängig voneinander aufzeichnen?
- Ist Datenverlust für Sie kritisch? Wenn ja, in welchem Umfang?
Um dies zu demonstrieren, betrachten wir zunächst die vorherige Lösung und diskutieren, warum wir beschlossen haben, sie aufzugeben.
Verweigerung der Verwendung von VIP und DNS zur Ermittlung
Als Teil der vorherigen Lösung haben wir verwendet:
- Orchestrator zur Fehlererkennung und zum Failover;
- VIP und DNS für die Hosterkennung.
In diesem Fall haben Clients einen Aufzeichnungsknoten anhand seines Namens entdeckt, z. B. mysql-writer-1.github.net . Der Name wurde verwendet, um die virtuelle IP-Adresse (VIP) des Hauptknotens zu bestimmen.
In einer normalen Situation mussten Kunden lediglich den Namen auflösen und eine Verbindung zur empfangenen IP-Adresse herstellen, auf die der Hauptknoten bereits gewartet hatte.
Betrachten Sie die folgende Replikationstopologie, die drei verschiedene Rechenzentren umfasst:
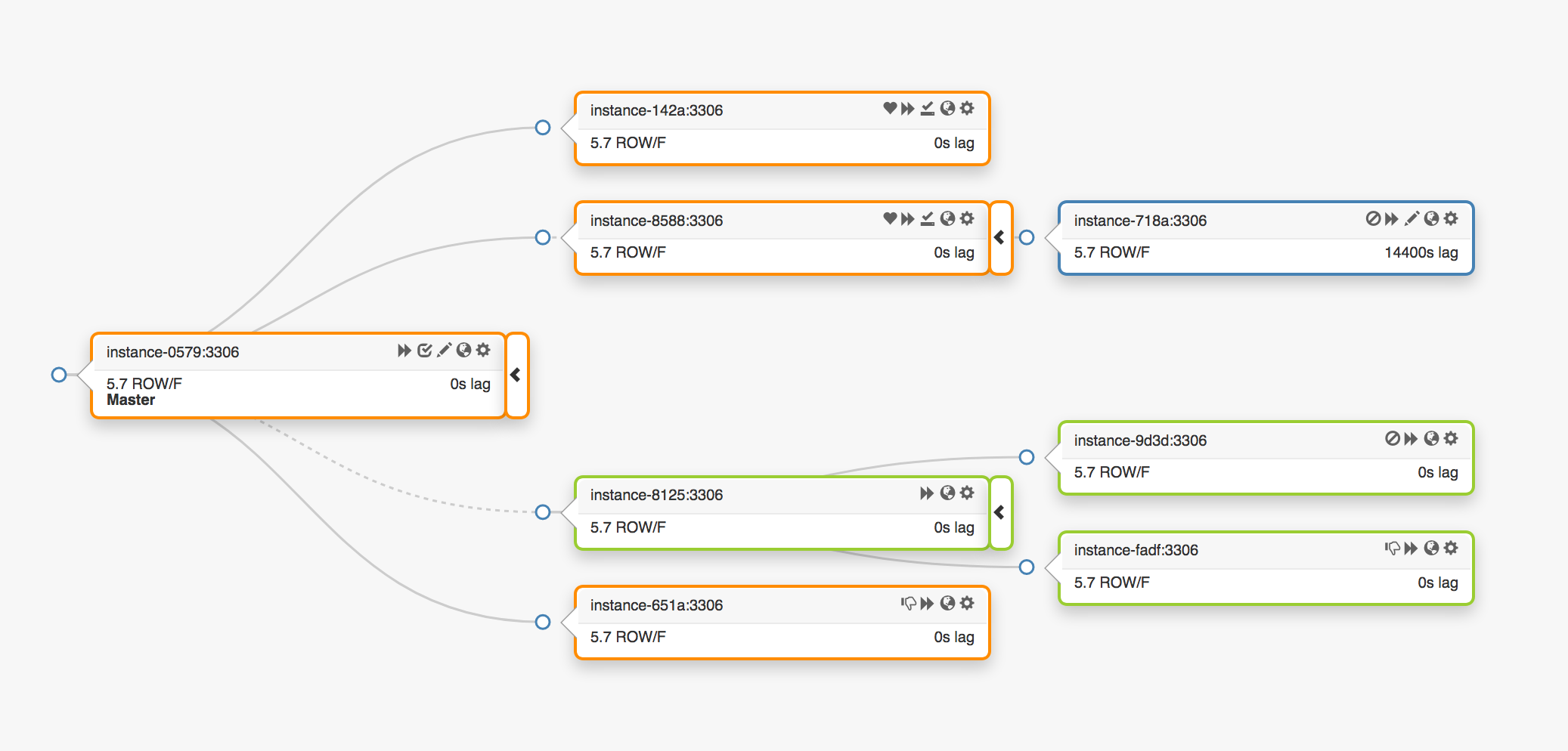
Bei einem Ausfall des Hauptknotens muss seinem Platz ein neuer Server zugewiesen werden (einer der Replikate).
orchestrator erkennt einen Fehler, wählt einen neuen Masterknoten aus und weist dann den Namen / VIP zu. Clients kennen die Identität des Hauptknotens nicht, sondern nur den Namen, der jetzt auf den neuen Knoten verweisen soll. Beachten Sie dies jedoch.
VIP-Adressen werden gemeinsam genutzt, Datenbankserver selbst fordern sie an und besitzen sie. Um einen VIP zu empfangen oder freizugeben, muss der Server eine ARP-Anfrage senden. Der Server, dem der VIP gehört, muss ihn zuerst freigeben, bevor der neue Master auf diese Adresse zugreifen kann. Dieser Ansatz führt zu einigen unerwünschten Konsequenzen:
- Im normalen Modus kontaktiert das Failover-System zuerst den ausgefallenen Hauptknoten und fordert ihn auf, den VIP freizugeben, und wendet sich dann mit einer Anforderung zur VIP-Zuweisung an den neuen Hauptserver. Was tun, wenn der erste Hauptknoten nicht verfügbar ist oder eine Anforderung zur Freigabe der VIP-Adresse ablehnt? Angesichts der Tatsache, dass sich der Server derzeit in einem Ausfallzustand befindet, ist es unwahrscheinlich, dass er rechtzeitig oder überhaupt auf eine Anfrage antworten kann.
- Infolgedessen kann es vorkommen, dass zwei Hosts ihre Rechte an demselben VIP geltend machen. Abhängig vom kürzesten Netzwerkpfad können verschiedene Clients eine Verbindung zu jedem dieser Server herstellen.
- Der korrekte Betrieb in dieser Situation hängt von der Interaktion zweier unabhängiger Server ab, und eine solche Konfiguration ist unzuverlässig.
- Selbst wenn der erste Hauptknoten auf Anfragen reagiert, verschwenden wir wertvolle Zeit: Der Wechsel zum neuen Hauptserver erfolgt nicht, während wir den alten kontaktieren.
- Darüber hinaus gibt es auch bei einer Neuzuweisung von VIPs keine Garantie dafür, dass vorhandene Clientverbindungen auf dem alten Server getrennt werden. Auch hier laufen wir Gefahr, in einer Situation mit zwei unabhängigen Hauptknoten zu sein.
Hier und da in unserer Umgebung sind VIP-Adressen einem physischen Standort zugeordnet. Sie sind einem Switch oder Router zugeordnet. Daher können wir eine VIP-Adresse nur einem Server zuweisen, der sich in derselben Umgebung wie der ursprüngliche Host befindet. Insbesondere können wir in einigen Fällen keinen VIP-Server in einem anderen Rechenzentrum zuweisen und müssen Änderungen am DNS vornehmen.
- Das Verteilen von Änderungen an den DNS dauert länger. Clients speichern DNS-Namen für einen vordefinierten Zeitraum. Ein Failover mit mehreren Rechenzentren führt zu längeren Ausfallzeiten, da es länger dauert, bis alle Kunden Informationen über den neuen Hauptknoten erhalten.
Diese Einschränkungen reichten aus, um uns zu zwingen, nach einer neuen Lösung zu suchen, aber wir mussten auch Folgendes berücksichtigen:
- Die Hauptknoten sendeten unabhängig Impulspakete über den
pt-heartbeat , um die Verzögerung und die Lastregelung zu messen . Der Dienst musste auf den neu ernannten Hauptknoten übertragen werden. Wenn möglich, sollte es auf dem alten Server deaktiviert sein. - In ähnlicher Weise steuerten die Hauptknoten unabhängig den Betrieb der Pseudo-GTID . Es war notwendig, diesen Prozess auf dem neuen Hauptknoten zu starten und vorzugsweise auf dem alten zu stoppen.
- Der neue Masterknoten wurde beschreibbar. Der alte Knoten (falls möglich) sollte
read_only (schreibgeschützt) haben.
Diese zusätzlichen Schritte führten zu einer Erhöhung der Gesamtausfallzeit und fügten ihre eigenen Fehlerquellen hinzu.
Die Lösung funktionierte und GitHub behandelte erfolgreich MySQL-Fehler im Hintergrund, aber wir wollten unseren Ansatz für HA wie folgt verbessern:
- Gewährleistung der Unabhängigkeit von bestimmten Rechenzentren;
- Gewährleistung der Funktionsfähigkeit bei Ausfällen von Rechenzentren;
- Geben Sie unzuverlässige kollaborative Workflows auf
- Reduzierung der gesamten Ausfallzeiten;
- Führen Sie das Failover so weit wie möglich ohne Verlust durch.
GitHub HA-Lösung: Orchestrator, Consul, GLB
Unsere neue Strategie beseitigt zusammen mit den damit verbundenen Verbesserungen die meisten der oben genannten Probleme oder mildert deren Folgen. Unser derzeitiges HA-System besteht aus folgenden Elementen:
- Orchestrator zur Fehlererkennung und zum Failover. Wir verwenden das Orchestrator / Raft- Schema mit mehreren Rechenzentren, wie in der folgenden Abbildung gezeigt.
- Hashicorp- Konsul für Service Discovery;
- GLB / HAProxy als Proxy-Schicht zwischen Clients und Aufzeichnungsknoten. Der Quellcode für den GLB Director ist geöffnet.
anycast Technologie für das Netzwerk-Routing.
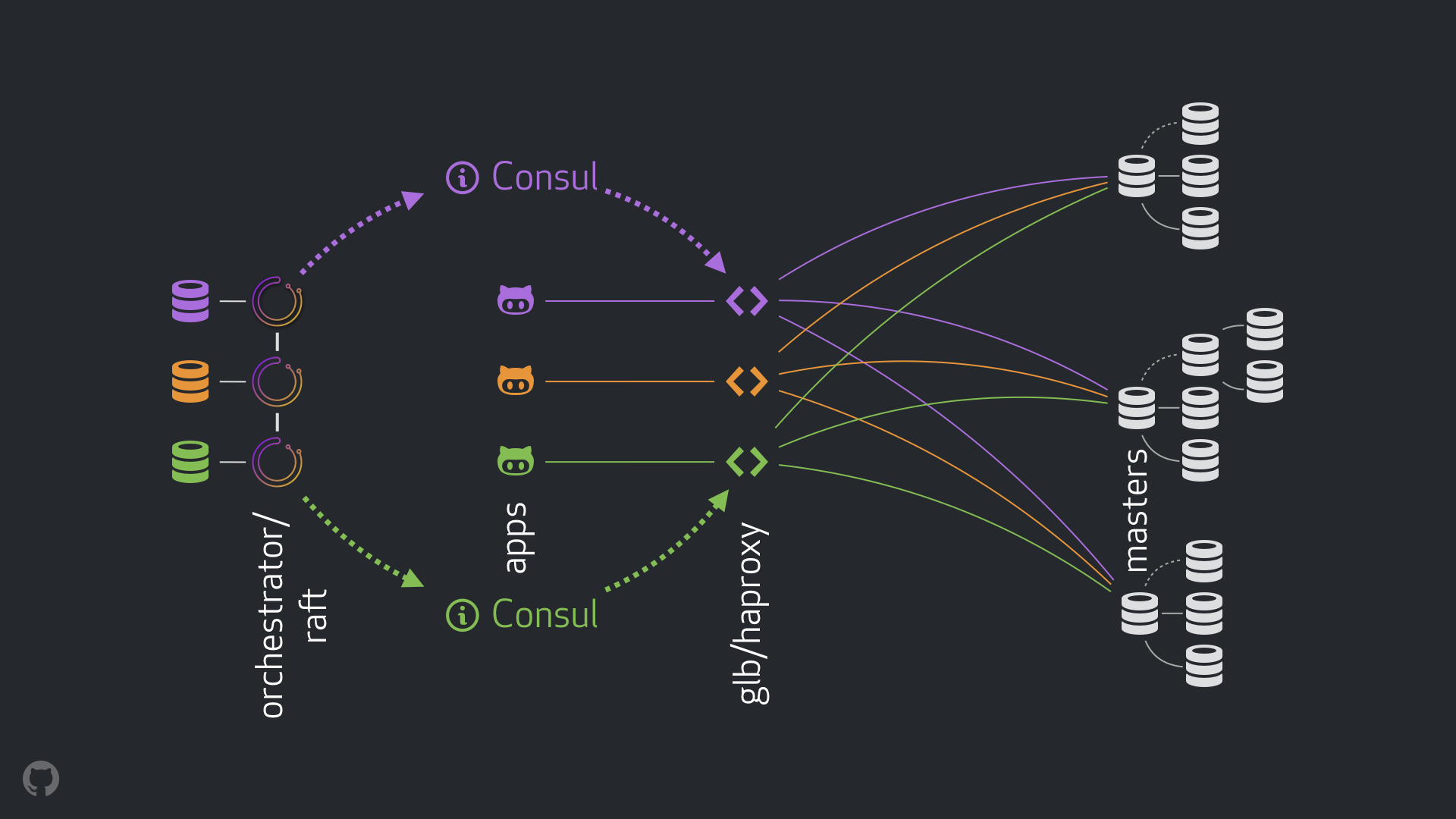
Mit dem neuen Schema konnten Änderungen an VIP und DNS vollständig aufgegeben werden. Wenn wir jetzt neue Komponenten einführen, können wir sie trennen und die Aufgabe vereinfachen. Darüber hinaus hatten wir die Möglichkeit, zuverlässige und stabile Lösungen zu verwenden. Eine detaillierte Analyse der neuen Lösung ist unten angegeben.
Normaler Durchfluss
In einer normalen Situation stellen Anwendungen über GLB / HAProxy eine Verbindung zu Aufzeichnungsknoten her.
Anwendungen erhalten nicht die Identität des Hauptservers. Nach wie vor verwenden sie nur den Namen. Der Hauptknoten für cluster1 wäre beispielsweise mysql-writer-1.github.net . In unserer aktuellen Konfiguration wird dieser Name jedoch in die Anycast- IP-Adresse aufgelöst.
Dank der anycast Technologie wird der Name überall in dieselbe IP-Adresse aufgelöst, der Datenverkehr wird jedoch je nach Standort des Clients unterschiedlich geleitet. Insbesondere werden in jedem unserer Rechenzentren mehrere Instanzen von GLB, unserem hochverfügbaren Load Balancer, bereitgestellt. Der mysql-writer-1.github.net auf mysql-writer-1.github.net immer an den GLB-Cluster des lokalen Rechenzentrums weitergeleitet. Aus diesem Grund werden alle Clients von lokalen Proxys bedient.
Wir führen GLB auf HAProxy aus . Unser HAProxy-Server bietet Schreibpools : einen für jeden MySQL-Cluster. Außerdem hat jeder Pool nur einen Server (den Hauptknoten des Clusters). Alle GLB / HAProxy-Instanzen in allen Rechenzentren haben dieselben Pools und alle verweisen auf dieselben Server in diesen Pools. Wenn die Anwendung Daten auf mysql-writer-1.github.net in die Datenbank schreiben mysql-writer-1.github.net , spielt es keine Rolle, mit welchem GLB-Server sie eine Verbindung herstellt. In beiden Fällen wird eine Umleitung zum eigentlichen cluster1 durchgeführt.
Bei Anwendungen endet die Erkennung mit GLB, und eine erneute Erkennung ist nicht erforderlich. Dieser GLB leitet den Verkehr an den richtigen Ort um.
Woher erhält der GLB Informationen darüber, welche Server aufgelistet werden sollen? Wie nehmen wir Änderungen am GLB vor?
Entdeckung durch Konsul
Der Consul-Dienst ist allgemein als Service Discovery-Lösung bekannt und übernimmt auch DNS-Funktionen. In unserem Fall verwenden wir es jedoch als leicht zugängliche Speicherung von Schlüsselwerten (KV).
Im KV-Repository in Consul zeichnen wir die Identität der Hauptclusterknoten auf. Für jeden Cluster gibt es eine Reihe von KV-Datensätzen, die auf die Daten des entsprechenden Hauptknotens fqdn : seine fqdn , port, ipv4 und ipv6.
Jeder GLB / HAProxy-Knoten startet eine Konsul-Vorlage , einen Dienst, der Änderungen an den Konsul-Daten verfolgt (in unserem Fall Änderungen an den Daten der Hauptknoten). Der consul-template erstellt eine Konfigurationsdatei und kann HAProxy beim Ändern von Einstellungen neu laden.
Aus diesem Grund stehen jeder GLB / HAProxy-Instanz Informationen zum Ändern der Identität des Hauptknotens in Consul zur Verfügung. Basierend auf diesen Informationen wird die Konfiguration der Instanzen durchgeführt. Die neuen Hauptknoten werden als einzige Entität im Cluster-Server-Pool angegeben. Danach werden die Instanzen neu geladen, damit die Änderungen wirksam werden.
Wir haben Consul-Instanzen in jedem Rechenzentrum bereitgestellt, und jede Instanz bietet hohe Verfügbarkeit. Diese Instanzen sind jedoch unabhängig voneinander. Sie replizieren nicht und tauschen keine Daten aus.
Woher erhält Consul Informationen über Änderungen und wie werden diese zwischen Rechenzentren verteilt?
Orchestrator / Floß
Wir verwenden das orchestrator/raft Schema: orchestrator Knoten kommunizieren über Raft- Konsens miteinander. In jedem Rechenzentrum haben wir einen oder zwei orchestrator .
orchestrator ist für die Erkennung von Fehlern, das MySQL-Failover und die Übertragung der geänderten Masterknotendaten an Consul verantwortlich. Das Failover wird von einem einzelnen orchestrator/raft Host verwaltet, aber Änderungen , die besagen, dass der Cluster jetzt ein neuer Master ist, werden mithilfe des raft Mechanismus an alle orchestrator Knoten weitergegeben.
Wenn die orchestrator Nachrichten über eine Änderung der Daten des Hauptknotens erhalten, kontaktiert jeder von ihnen seine eigene lokale Instanz von Consul und initiiert eine KV-Aufzeichnung. Rechenzentren mit mehreren Instanzen von orchestrator erhalten mehrere (identische) Datensätze in Consul.
Verallgemeinerte Ansicht des gesamten Streams
Wenn der Masterknoten ausfällt:
orchestrator erkennen Fehler;orchestrator/raft Master initiiert die Wiederherstellung. Ein neuer Masterknoten wird zugewiesen.- Das
orchestrator/raft Schema überträgt die Daten zum Wechsel des Hauptknotens an alle Knoten des raft Clusters. - Jede Instanz von
orchestrator/raft erhält eine Benachrichtigung über einen Knotenwechsel und schreibt die Identität des neuen Masterknotens in den lokalen KV-Speicher in Consul. - Auf jeder GLB / HAProxy-Instanz wird der
consul-template Dienst gestartet, der Änderungen im KV-Repository in Consul überwacht, HAProxy neu konfiguriert und neu startet. - Der Clientverkehr wird auf den neuen Masterknoten umgeleitet.
Für jede Komponente sind die Verantwortlichkeiten klar verteilt und die gesamte Struktur ist diversifiziert und vereinfacht. orchestrator interagiert nicht mit Load Balancern. Der Konsul benötigt keine Informationen über die Herkunft der Informationen. Proxyserver funktionieren nur mit Consul. Clients arbeiten nur mit Proxyservern.
Außerdem:
- Es ist nicht erforderlich, Änderungen am DNS vorzunehmen und Informationen darüber zu verbreiten.
- TTL wird nicht verwendet;
- Der Thread wartet nicht auf Antworten vom Host in einem Fehlerzustand. Im Allgemeinen wird es ignoriert.
Um den Fluss zu stabilisieren, wenden wir auch die folgenden Methoden an:
- Der HAProxy-
hard-stop-after Parameter ist auf einen sehr kleinen Wert eingestellt. Wenn HAProxy mit dem neuen Server im Schreibpool neu gestartet wird, beendet der Server automatisch alle vorhandenen Verbindungen zum alten Masterknoten.
- Durch Festlegen des
hard-stop-after Parameters können Sie nicht auf Aktionen von Clients warten. Außerdem werden die negativen Folgen des möglichen Auftretens von zwei Hauptknoten im Cluster minimiert. Es ist wichtig zu verstehen, dass es hier keine Magie gibt, und auf jeden Fall vergeht einige Zeit, bis die alten Bindungen gebrochen sind. Aber es gibt einen Zeitpunkt, nach dem wir aufhören können, auf unangenehme Überraschungen zu warten.
- Wir benötigen keine ständige Verfügbarkeit des Konsulendienstes. Tatsächlich muss es nur während des Failovers verfügbar sein. Wenn der Konsulendienst nicht reagiert, arbeitet GLB weiterhin mit den neuesten bekannten Werten und ergreift keine drastischen Maßnahmen.
- Der GLB ist so konfiguriert, dass die Identität des neu zugewiesenen Masterknotens überprüft wird. Wie bei unseren kontextsensitiven MySQL-Pools wird eine Überprüfung durchgeführt, um zu bestätigen, dass der Server tatsächlich beschreibbar ist. Wenn wir versehentlich die Identität des Hauptknotens in Consul löschen, gibt es keine Probleme, ein leerer Datensatz wird ignoriert. Wenn wir versehentlich den Namen eines anderen Servers (nicht des Hauptservers) an Consul schreiben, ist dies in diesem Fall in Ordnung: GLB aktualisiert ihn nicht und arbeitet weiterhin mit dem letzten gültigen Status.
In den folgenden Abschnitten werden Probleme untersucht und die Ziele der Hochverfügbarkeit analysiert.
Absturzerkennung mit Orchestrator / Floß
orchestrator einen umfassenden Ansatz zur Fehlererkennung, der eine hohe Zuverlässigkeit des Tools gewährleistet. Es treten keine falsch positiven Ergebnisse auf, es werden keine vorzeitigen Fehler ausgeführt, sodass unnötige Ausfallzeiten ausgeschlossen sind.
Die orchestrator/raft Schaltung bewältigt auch Situationen einer vollständigen Netzwerkisolation des Rechenzentrums (Data Center Fencing). Die Netzwerkisolation des Rechenzentrums kann zu Verwirrung führen: Die Server im Rechenzentrum können miteinander kommunizieren. Wie kann man verstehen, wer wirklich isoliert ist - Server in einem bestimmten Rechenzentrum oder in allen anderen Rechenzentren?
Im orchestrator/raft Schema ist der orchestrator/raft Master ein Failover. Der Knoten wird zum Leiter, der die Unterstützung der Mehrheit in der Gruppe erhält (Quorum). Wir haben den orchestrator Knoten so bereitgestellt, dass kein einzelnes Rechenzentrum die Mehrheit bereitstellen kann, während jedes n-1 Rechenzentrum dies bereitstellen kann.
Bei vollständiger Netzwerkisolation des Rechenzentrums werden die orchestrator in diesem Zentrum von ähnlichen Knoten in anderen Rechenzentren getrennt. Infolgedessen können die orchestrator in einem isolierten Rechenzentrum nicht in einem raft führend werden. Wenn ein solcher Knoten der Master war, verliert er diesen Status. Einem neuen Host wird einer der Knoten der anderen Rechenzentren zugewiesen. Dieser Leiter wird von allen anderen Rechenzentren unterstützt, die miteinander interagieren können.
Auf diese Weise befindet sich der orchestrator Master immer außerhalb des netzwerkisolierten Rechenzentrums. Wenn sich der Masterknoten im isolierten Rechenzentrum befand, initiiert der orchestrator ein Failover, um ihn durch den Server eines der verfügbaren Rechenzentren zu ersetzen. Wir verringern die Auswirkungen der Isolation von Rechenzentren, indem wir Entscheidungen an das Quorum der verfügbaren Rechenzentren delegieren.
Schnellere Benachrichtigung
Die Gesamtausfallzeit kann weiter reduziert werden, indem die Benachrichtigung über eine Änderung im Hauptknoten beschleunigt wird. Wie erreicht man das?
Wenn der orchestrator Failover startet, berücksichtigt er eine Gruppe von Servern, von denen einer als Hauptserver zugewiesen werden kann. Aufgrund der Replikationsregeln, -empfehlungen und -einschränkungen kann er eine fundierte Entscheidung über die beste Vorgehensweise treffen.
Anhand der folgenden Anzeichen kann er auch verstehen, dass ein zugänglicher Server ein idealer Kandidat für die Ernennung zum Hauptserver ist:
- Nichts verhindert, dass der Server erhöht wird (und der Benutzer empfiehlt diesen Server möglicherweise).
- Es wird erwartet, dass der Server alle anderen Server als Replikate verwenden kann.
In diesem Fall konfiguriert orchestrator den Server zunächst als beschreibbar und kündigt sofort eine Erhöhung seines Status an (in unserem Fall schreibt er den Datensatz in das KV-Repository in Consul). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
Ergebnisse
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
Fazit
«// » , , . . , .