Auf den thematischen ausländischen Websites zu Big Data finden Sie heute ein relativ neues Tool für das Hadoop-Ökosystem wie Apache NiFi. Dies ist ein modernes Open Source ETL-Tool. Eine verteilte Architektur für schnelles paralleles Laden und Datenverarbeitung, eine große Anzahl von Plug-Ins für Quellen und Transformationen sowie die Versionierung von Konfigurationen sind nur ein Teil der Vorteile. Bei aller Leistung bleibt NiFi recht einfach zu bedienen.
Wir bei Rostelecom sind bestrebt, die Zusammenarbeit mit Hadoop weiterzuentwickeln. Daher haben wir bereits die Vorteile von Apache NiFi im Vergleich zu anderen Lösungen ausprobiert und bewertet. In diesem Artikel werde ich Ihnen erzählen, wie dieses Tool uns angezogen hat und wie wir es verwenden.
Hintergrund
Vor nicht allzu langer Zeit standen wir vor der Wahl einer Lösung zum Laden von Daten aus externen Quellen in einen Hadoop-Cluster. Lange Zeit haben wir
Apache Flume verwendet , um solche Probleme zu lösen. Es gab keine Beschwerden über Flume als Ganzes, außer ein paar Punkten, die nicht zu uns passten.
Das erste, was uns als Administratoren nicht gefallen hat, war, dass das Schreiben der Flume-Konfiguration für den nächsten einfachen Download nicht einem Entwickler oder Analysten anvertraut werden konnte, der nicht in die Feinheiten dieses Tools vertieft war. Das Anschließen jeder neuen Quelle erforderte einen obligatorischen Eingriff des Verwaltungsteams.
Der zweite Punkt war Fehlertoleranz und Skalierung. Für umfangreiche Downloads, beispielsweise über Syslog, mussten mehrere Flume-Agenten konfiguriert und ein Balancer vor ihnen eingerichtet werden. All dies musste dann im Falle eines Ausfalls irgendwie überwacht und wiederhergestellt werden.
Drittens erlaubte Flume nicht, Daten von verschiedenen DBMS herunterzuladen und mit einigen anderen Protokollen sofort zu arbeiten. Natürlich könnten Sie in den riesigen Weiten des Netzwerks Wege finden, Flume mit Oracle oder SFTP zum Laufen zu bringen, aber die Unterstützung solcher Fahrräder ist überhaupt nicht angenehm. Um Daten von demselben Oracle zu laden, mussten wir ein anderes Tool verwenden -
Apache Sqoop .
Ehrlich gesagt bin ich von Natur aus ein fauler Mensch, und ich wollte den Zoo der Lösungen überhaupt nicht unterstützen. Und es hat mir nicht gefallen, dass all diese Arbeit von mir selbst gemacht werden musste.
Es gibt natürlich ziemlich leistungsfähige Lösungen auf dem ETL-Tool-Markt, die mit Hadoop funktionieren können. Dazu gehören Informatica, IBM Datastage, SAS und Pentaho Data Integration. Dies sind diejenigen, die am häufigsten von Kollegen in der Werkstatt gehört werden und die zuerst in den Sinn kommen. Übrigens verwenden wir IBM DataStage for ETL für Lösungen der Data Warehouse-Klasse. In der Vergangenheit war unser Team jedoch nicht in der Lage, DataStage für Downloads in Hadoop zu verwenden. Auch hier brauchten wir nicht die volle Leistungsfähigkeit von Lösungen dieser Ebene, um relativ einfache Konvertierungen und Daten-Downloads durchzuführen. Was wir brauchten, war eine Lösung mit guter Entwicklungsdynamik, die mit vielen Protokollen arbeiten kann und über eine praktische und intuitive Benutzeroberfläche verfügt, die nicht nur ein Administrator, der alle Feinheiten verstanden hat, handhaben konnte, sondern auch ein Entwickler mit einem Analysten, der oft für uns ist Kunden der Daten selbst.
Wie Sie dem Titel entnehmen können, haben wir die oben genannten Probleme mit Apache NiFi gelöst.
Was ist Apache NiFi?
Der Name NiFi stammt von "Niagara Files". Das Projekt wurde acht Jahre lang von der US-amerikanischen National Security Agency entwickelt. Im November 2014 wurde der Quellcode geöffnet und im Rahmen des
NSA Technology Transfer Program an die Apache Software Foundation
übertragen .
NiFi ist ein Open-Source-ETL / ELT-Tool, das mit vielen Systemen und nicht nur mit den Klassen Big Data und Data Warehouse funktioniert. Hier sind einige davon: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Die vollständige Liste finden Sie in der offiziellen
Dokumentation .
Die Arbeit mit einem bestimmten DBMS wird durch Hinzufügen des entsprechenden JDBC-Treibers implementiert. Es gibt eine API zum Schreiben Ihres Moduls als zusätzlichen Empfänger oder Datenkonverter. Beispiele finden Sie
hier und
hier .
Hauptmerkmale
NiFi verwendet eine Webschnittstelle, um DataFlow zu erstellen. Ein Analyst, der kürzlich mit Hadoop, einem Entwickler und einem bärtigen Administrator zusammengearbeitet hat, wird damit fertig. Die letzten beiden können nicht nur mit „Rechtecken und Pfeilen“ interagieren, sondern auch mit der
REST-API zum Sammeln von Statistiken, Überwachen und Verwalten von DataFlow-Komponenten.
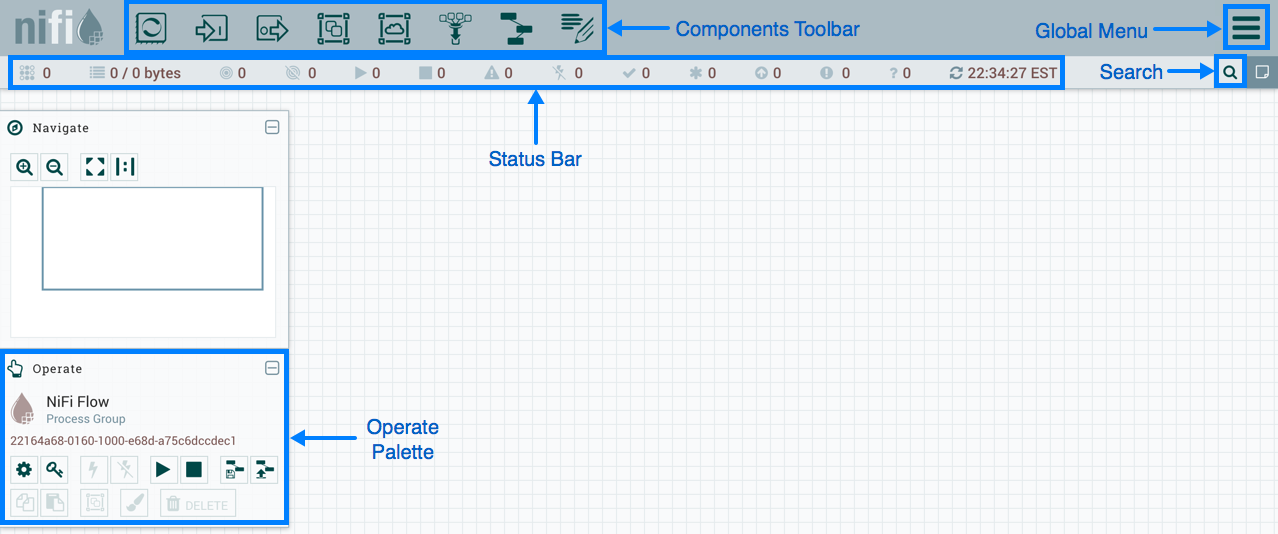 NiFi Web Based Management
NiFi Web Based ManagementIm Folgenden werde ich einige DataFlow-Beispiele für die Ausführung einiger gängiger Operationen zeigen.
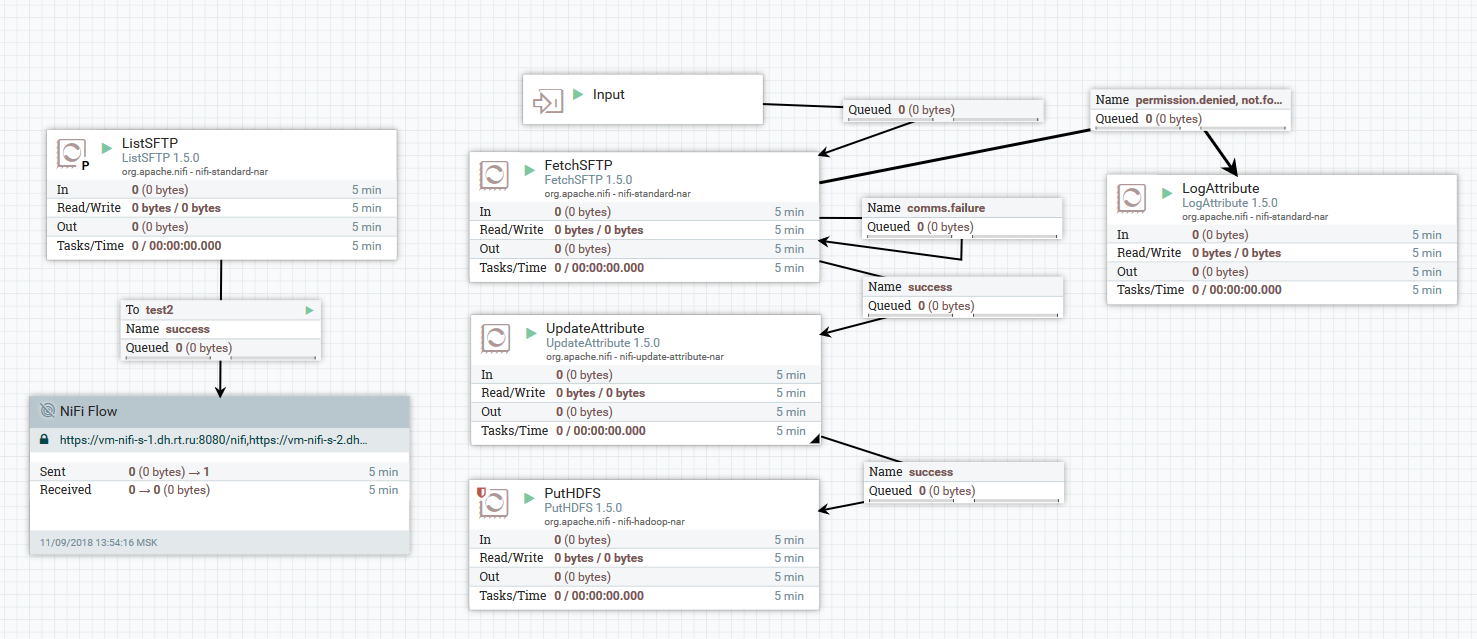 Beispiel für das Herunterladen von Dateien von einem SFTP-Server auf HDFS
Beispiel für das Herunterladen von Dateien von einem SFTP-Server auf HDFSIn diesem Beispiel führt der ListSFTP-Prozessor eine Dateiliste auf dem Remote-Server durch. Das Ergebnis dieser Auflistung wird für das parallele Laden von Dateien durch alle Knoten des Clusters durch den FetchSFTP-Prozessor verwendet. Danach werden jeder Datei Attribute hinzugefügt, die durch Parsen ihres Namens erhalten werden. Diese werden dann vom PutHDFS-Prozessor beim Schreiben der Datei in das endgültige Verzeichnis verwendet.
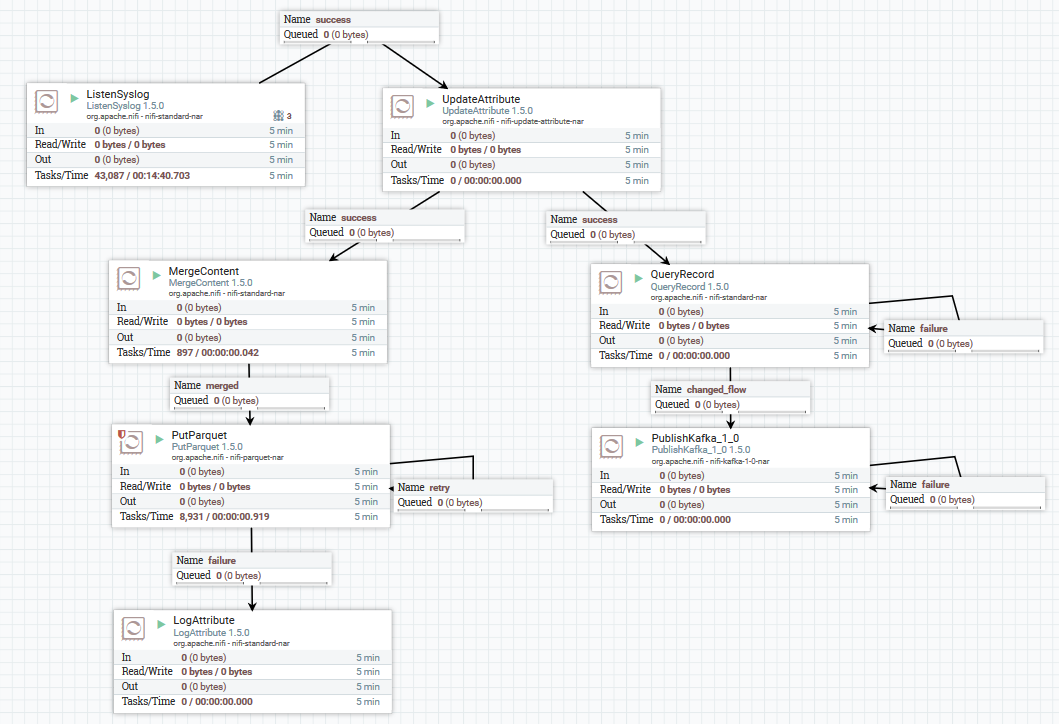 Ein Beispiel für das Herunterladen von Syslog-Daten in Kafka und HDFS
Ein Beispiel für das Herunterladen von Syslog-Daten in Kafka und HDFSHier erhalten wir mit dem ListenSyslog-Prozessor den Eingabenachrichtenstrom. Danach werden jeder Nachrichtengruppe Attribute über den Zeitpunkt ihres Eintreffens in NiFi und den Namen des Schemas in der Avro-Schema-Registrierung hinzugefügt. Als nächstes wird der erste Zweig an die Eingabe des QueryRecord-Prozessors gesendet, der basierend auf dem angegebenen Schema Daten liest, sie mit SQL analysiert und sie dann an Kafka sendet. Der zweite Zweig wird an den MergeContent-Prozessor gesendet, der die Daten 10 Minuten lang aggregiert und sie dann an den nächsten Prozessor zur Konvertierung in das Parkettformat und zur Aufzeichnung in HDFS weiterleitet.
Hier ist ein Beispiel, wie Sie einen DataFlow sonst noch formatieren können:
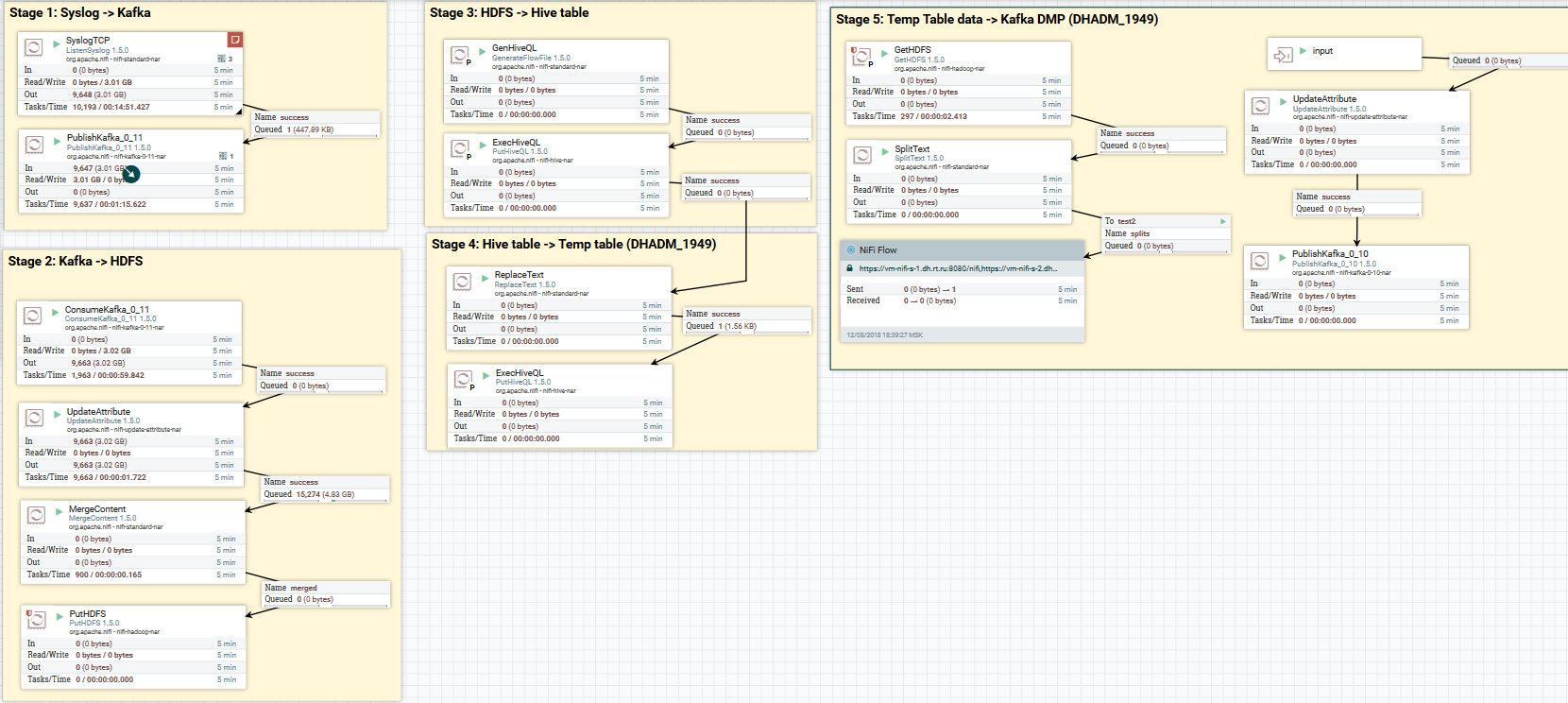 Laden Sie Syslog-Daten auf Kafka und HDFS herunter. Daten in Hive löschen
Laden Sie Syslog-Daten auf Kafka und HDFS herunter. Daten in Hive löschenNun zur Datenkonvertierung. Mit NiFi können Sie Daten mit regulären Daten analysieren, SQL darauf ausführen, Felder filtern und hinzufügen sowie ein Datenformat in ein anderes konvertieren. Es hat auch eine eigene Ausdruckssprache, die reich an verschiedenen Operatoren und integrierten Funktionen ist. Mit ihm können Sie den Daten Variablen und Attribute hinzufügen, Werte vergleichen und berechnen und sie später bei der Bildung verschiedener Parameter verwenden, z. B. den Pfad zum Schreiben in HDFS oder die SQL-Abfrage in Hive. Lesen Sie
hier mehr.
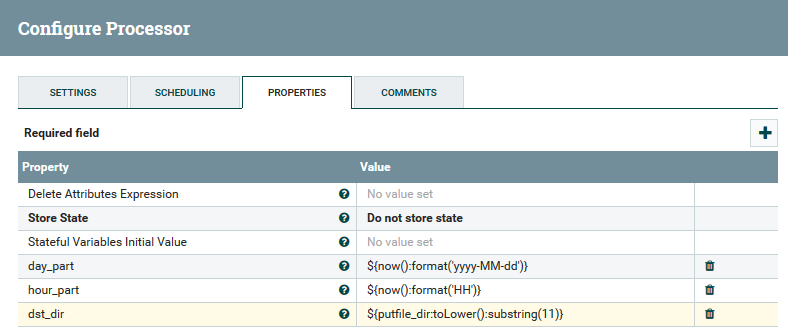 Ein Beispiel für die Verwendung von Variablen und Funktionen im UpdateAttribute-Prozessor
Ein Beispiel für die Verwendung von Variablen und Funktionen im UpdateAttribute-ProzessorDer Benutzer kann den vollständigen Pfad der Daten verfolgen und die Änderung ihrer Inhalte und Attribute beobachten.
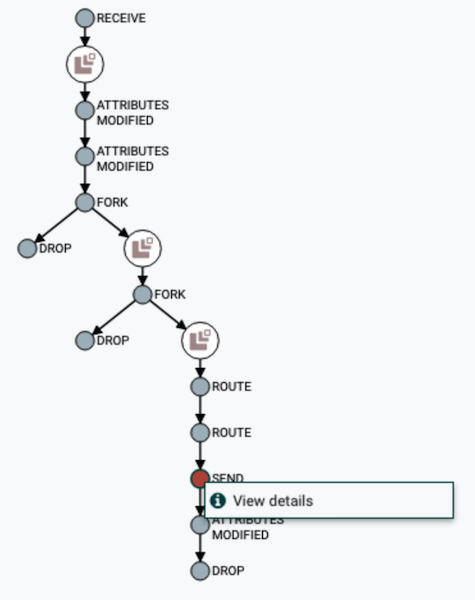 Visualisierung der DataFlow-Kette
Visualisierung der DataFlow-Kette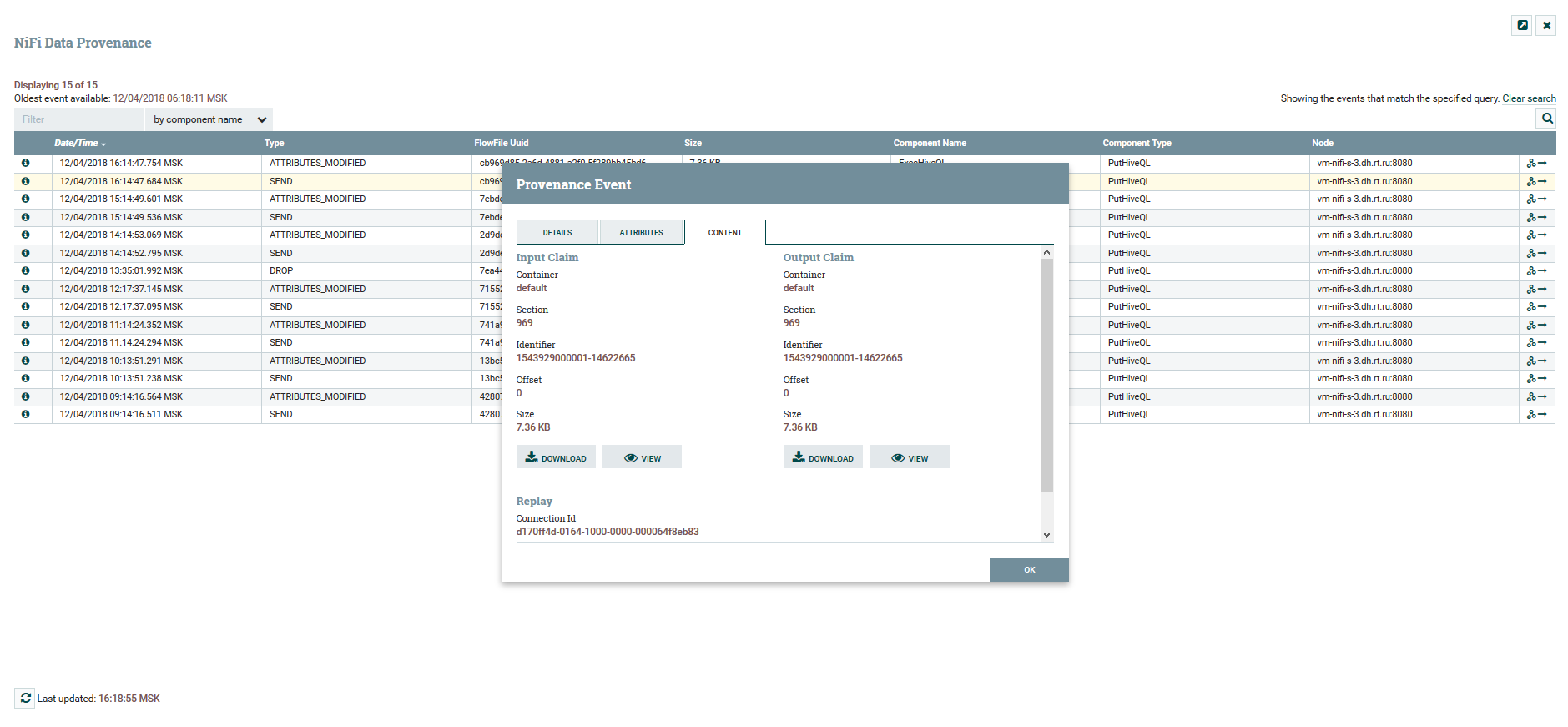 Anzeigen von Inhalten und Datenattributen
Anzeigen von Inhalten und DatenattributenFür die Versionierung von DataFlow gibt es einen separaten
NiFi-Registrierungsdienst . Durch das Einrichten erhalten Sie die Möglichkeit, Änderungen zu verwalten. Sie können lokale Änderungen ausführen, ein Rollback durchführen oder eine frühere Version herunterladen.
 Menü zur Versionskontrolle
Menü zur VersionskontrolleIn NiFi können Sie den Zugriff auf die Weboberfläche und die Trennung von Benutzerrechten steuern. Die folgenden Authentifizierungsmechanismen werden derzeit unterstützt:
Die gleichzeitige Verwendung mehrerer Mechanismen gleichzeitig wird nicht unterstützt. Um Benutzer im System zu autorisieren, werden FileUserGroupProvider und LdapUserGroupProvider verwendet. Lesen Sie hier mehr darüber.
Wie gesagt, NiFi kann im Cluster-Modus arbeiten. Dies bietet Fehlertoleranz und ermöglicht eine horizontale Lastskalierung. Es gibt keinen statisch festen Masterknoten. Stattdessen wählt
Apache Zookeeper einen Knoten als Koordinator und einen als primären Knoten aus. Der Koordinator erhält Informationen über seinen Status von anderen Knoten und ist für deren Verbindung und Trennung vom Cluster verantwortlich.
Der Primärknoten wird verwendet, um isolierte Prozessoren zu starten, die nicht auf allen Knoten gleichzeitig ausgeführt werden sollten.
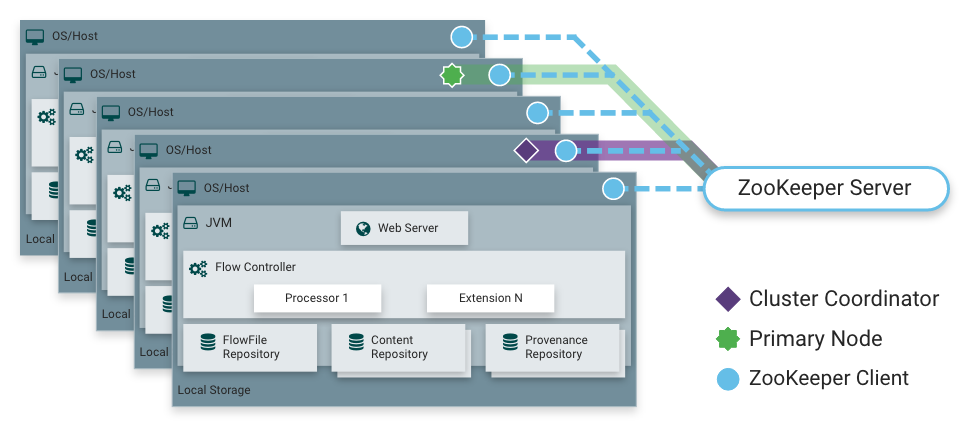 NiFi-Betrieb in einem Cluster
NiFi-Betrieb in einem Cluster Lastverteilung nach Clusterknoten am Beispiel des PutHDFS-Prozessors
Lastverteilung nach Clusterknoten am Beispiel des PutHDFS-ProzessorsEine kurze Beschreibung der NiFi-Architektur und -Komponenten
 NiFi-Instanzarchitektur
NiFi-InstanzarchitekturNiFi basiert auf dem Konzept der „Flow Based Programming“ (
FBP ). Hier sind die grundlegenden Konzepte und Komponenten, auf die jeder Benutzer stößt:
FlowFile - eine Entität, die ein Objekt mit Inhalten aus null oder mehr Bytes und den entsprechenden Attributen darstellt. Dies können entweder die Daten selbst (z. B. der Kafka-Nachrichtenfluss) oder das Ergebnis des Prozessors (z. B. PutSQL) sein, der keine Daten als solche enthält, sondern nur die als Ergebnis der Abfrage generierten Attribute. Attribute sind FlowFile-Metadaten.
FlowFile Processor ist genau die Essenz, die die grundlegende Arbeit in NiFi erledigt. Ein Prozessor hat in der Regel eine oder mehrere Funktionen für die Arbeit mit FlowFile: Erstellen, Lesen / Schreiben und Ändern von Inhalten, Lesen / Schreiben / Ändern von Attributen, Routing. Beispielsweise empfängt der ListenSyslog-Prozessor Daten mithilfe des Syslog-Protokolls und erstellt FlowFiles mit den Attributen syslog.version, syslog.hostname, syslog.sender und anderen. Der RouteOnAttribute-Prozessor liest die Attribute der Eingabe-FlowFile und beschließt, diese abhängig von den Werten der Attribute an die entsprechende Verbindung mit einem anderen Prozessor umzuleiten.
Verbindung - Ermöglicht die Verbindung und Übertragung von flowFile zwischen verschiedenen Prozessoren und einigen anderen NiFi-Einheiten. Connection stellt die FlowFile in eine Warteschlange und leitet sie dann an die Kette weiter. Sie können konfigurieren, wie FlowFiles aus der Warteschlange ausgewählt werden, ihre Lebensdauer, maximale Anzahl und maximale Größe aller Objekte in der Warteschlange.
Prozessgruppe - Eine Reihe von Prozessoren, deren Verbindungen und anderen DataFlow-Elementen. Es ist ein Mechanismus zum Organisieren vieler Komponenten in einer logischen Struktur. Erleichtert das Verständnis von DataFlow. Eingabe- / Ausgabeports werden zum Empfangen und Senden von Daten von Prozessgruppen verwendet. Lesen Sie hier mehr über ihre Verwendung.
Im FlowFile-Repository speichert NiFi alle Informationen, die es über jede vorhandene FlowFile im System kennt.
Inhalts-Repository - das Repository, in dem sich der Inhalt aller FlowFiles befindet, d. H. die übertragenen Daten selbst.
Provenienz-Repository - Enthält eine Geschichte zu jeder FlowFile. Jedes Mal, wenn ein Ereignis mit FlowFile auftritt (Erstellung, Änderung usw.), werden die entsprechenden Informationen in dieses Repository eingegeben.
Webserver - Bietet eine Webschnittstelle und eine REST-API.
Fazit
Mit NiFi konnte Rostelecom den Mechanismus für die Bereitstellung von Daten an Data Lake auf Hadoop verbessern. Im Allgemeinen ist der gesamte Prozess bequemer und zuverlässiger geworden. Heute kann ich mit Zuversicht sagen, dass NiFi sich hervorragend zum Herunterladen auf Hadoop eignet. Wir haben keine Probleme bei der Bedienung.
NiFi ist übrigens Teil der Hortonworks-Datenflussverteilung und wird von Hortonworks selbst aktiv entwickelt. Er hat auch ein interessantes Apache MiNiFi-Teilprojekt, mit dem Sie Daten von verschiedenen Geräten sammeln und in DataFlow in NiFi integrieren können.
Zusätzliche Informationen zu NiFi
Vielleicht ist das alles. Vielen Dank für Ihre Aufmerksamkeit. Schreiben Sie in die Kommentare, wenn Sie Fragen haben. Ich werde sie gerne beantworten.