
Anfang dieser Woche
fand die nächste Veröffentlichung von Kubernetes
statt , die als „engelhaft“ bezeichnet wurde (
1.13) . Dieser Name ist mit der Nummer 113 verbunden, die
als "engelhaft" gilt und laut Kubernetes-Entwicklern "Neuanfang, Transformation und das Ende eines Kapitels vor dem Öffnen neuer" symbolisiert. Ohne weiter auf die Symbolik des Geschehens einzugehen, werden wir gemäß der bereits für unseren Blog etablierten Tradition zum siebten Mal über wichtige Änderungen in der neuen Version von Kubernetes sprechen, die den DevOps- / SRE-Ingenieuren, die mit diesem Produkt arbeiten, gefallen sollen.
Als Informationsquelle haben wir Daten aus
der Kubernetes-Erweiterungsverfolgung , der
CHANGELOG-1.13- Tabelle und verwandten Problemen, Pull-Anfragen und Kubernetes-Verbesserungsvorschlägen (KEP) verwendet.
GA für Kubeadm
Eines der Hauptereignisse der Version Kubernetes 1.13 war die Ankündigung eines stabilen Status (General Availability, GA) für das
Dienstprogramm kubeadm console. Der K8s-Blog hat
diesem Thema sogar eine
separate Veröffentlichung gewidmet. Wie viele wissen, ist kubeadm ein Tool zum Erstellen von Kubernetes-Clustern gemäß den Best Practices des Projekts sowie deren weiterer minimaler Unterstützung. Ein besonderes Merkmal ist, dass Entwickler bestrebt sind, es kompakt und unabhängig vom Anbieter / der Infrastruktur zu halten, ohne Lösungen für Probleme wie Bereitstellungsinfrastrukturen, Netzwerklösungen von Drittanbietern, Add-Ons (Überwachung, Protokollierung usw.) und spezifische Integrationen in die Cloud Anbieter.
Der GA-Status kennzeichnete die Reife von Kubeadm in den folgenden Bereichen:
- Stabile Konsolenschnittstelle, die der Kubernetes-Veralterungsrichtlinie folgt: Befehle und Flags, die in der GA-Version dargestellt werden, müssen mindestens ein Jahr lang unterstützt werden, nachdem sie veraltet sind.
- stabile Implementierung "unter der Haube" aufgrund der Tatsache, dass der Cluster mit Methoden erstellt wird, die sich in naher Zukunft nicht ändern werden: Die
kubeadm join startet so viele statische Pods, Bootstrap-Token werden für die kubeadm join und ComponentConfig wird zum Konfigurieren von Kubelet verwendet. - Konfigurationsschema mit einer neuen API (v1beta1), mit der fast alle Clusterkomponenten deklarativ beschrieben werden können (GitOps ist für mit kubeadm erstellte Cluster möglich) - ein Upgrade auf Version v1 ist ohne oder mit minimalen Änderungen geplant;
- die sogenannten Phasen (oder Toolbox- Schnittstelle) in kubeadm (
kubeadm init phase ), mit denen Sie auswählen können, welche Initialisierungsvorgänge ausgeführt werden sollen; kubeadm upgrade Team garantiert Cluster-Updates zwischen den Versionen 1.10.x, 1.11.x, 1.12.x und 1.13.x (Updates usw., API-Server, Controller Manager und Scheduler).- Standardmäßig sichere Installation von etcd (überall wird TLS verwendet) mit der Möglichkeit, bei Bedarf auf den HA-Cluster zu erweitern.
Es ist auch zu beachten, dass kubeadm Docker 18.09.0 und seine neueren Versionen jetzt korrekt erkennt. Schließlich bitten die Entwickler die Benutzer von kubeadm, an einer kleinen
Online-Umfrage teilzunehmen, in der sie ihre Wünsche zur Nutzung und Entwicklung des Projekts äußern können.
CoreDNS standardmäßig
CoreDNS, das in der Version
Kubernetes 1.11 einen stabilen Status erhielt, ging noch weiter und
wurde zum Standard-DNS-Server in K8s (anstelle der bisher verwendeten kube-dns). Es war geplant, dass dies bereits ab 1.12 geschehen sollte, aber die Entwickler mussten zusätzliche Optimierungen in Bezug auf Skalierbarkeit und Speicherverbrauch vornehmen, die erst mit der aktuellen Version abgeschlossen wurden.

Die Unterstützung für kube-dns wird "für mindestens eine nächste Version" fortgesetzt, aber Entwickler sprechen über die Notwendigkeit
, jetzt
mit der Migration auf eine aktuelle Lösung zu beginnen .
Von den Änderungen im Zusammenhang mit dem CoreDNS-Thema in Kubernetes 1.13 kann auch das
NodeLocal DNS Cache- Plugin zur Verbesserung der DNS-Leistung erwähnt werden. Die Verbesserung wird erreicht, indem auf den Clusterknoten ein Agent für den DNS-Cache ausgeführt wird, auf den die Pods dieses Knotens direkt zugreifen. Standardmäßig ist die Funktion deaktiviert. Um sie zu aktivieren, müssen Sie
KUBE_ENABLE_NODELOCAL_DNS=true .
Lagereinrichtungen
In den jüngsten Versionen von Kubernetes wird viel Wert auf die Arbeit mit
Container Storage Interface (CSI) gelegt, die mit der Alpha-Version von CSI in
K8s 1.9 begann und mit der Beta-Version
1.10 fortgesetzt wurde. Wir haben jedoch bereits mehr
als einmal darüber geschrieben . In K8 1.13 wurde ein bedeutender neuer Meilenstein erreicht: Die
CSI-Unterstützung wird für stabil erklärt (GA).
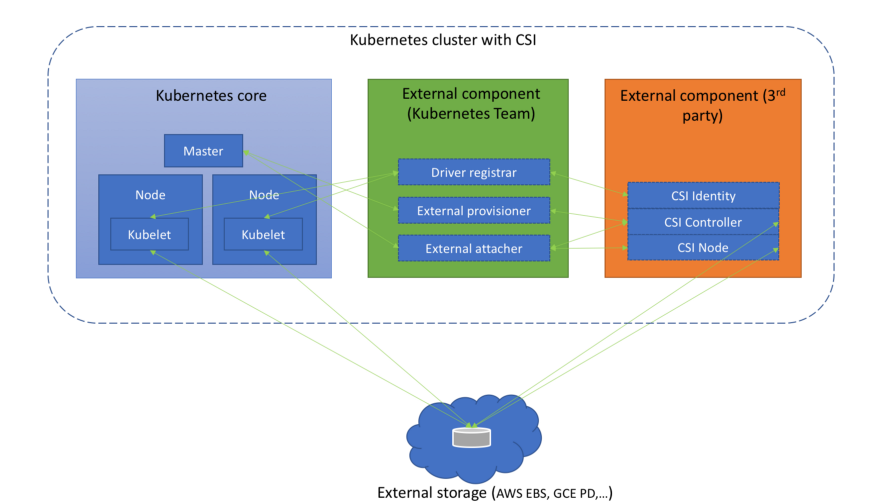 (Diagramm aus dem Artikel „ Grundlegendes zur Container-Speicherschnittstelle “)
(Diagramm aus dem Artikel „ Grundlegendes zur Container-Speicherschnittstelle “)Gleichzeitig wurde die Unterstützung für die CSI-Spezifikation v1.0.0 angezeigt, und die Unterstützung für ältere Versionen des Standards (0.3 und früher) wurde abgelehnt. Dies bedeutet, dass ältere CSI-Treiber ein Upgrade auf CSI 1.0 (und das Wechseln in das neue Registrierungsverzeichnis des Kubelet-Plugins) erfordern, um in Kubernetes 1.15 und älter zu funktionieren. Übrigens ist von den Treibern selbst das
Erscheinungsbild der Alpha-Version der CSI-Schnittstelle zur Verwaltung des Lebenszyklus von AWS EBS-Volumes (Elastic Block Store) zu beachten.
Eine neue Erweiterung des Addon-Managers installiert CRI jetzt automatisch von CSI, wenn mindestens eines der beiden Feature-Gates aktiviert ist:
CSIDriverRegistry und
CSINodeInfo . Es hat den Status der Alpha-Version, ist jedoch nur eine vorübergehende Lösung des Problems, das ausführlich als
CRD-Installationsmechanismus beschrieben wird .
Die auf Topologie basierende Volumenplanung (
Topology Aware Volume Scheduling ), über die wir im Zusammenhang mit der Version
Kubernetes 1.10 gesprochen haben , ist
stabil geworden . Kurz gesagt, der Scheduler berücksichtigt in seiner Arbeit die Einschränkungen der Topologie des Pod-Volumes (z. B. dessen Zone und Knoten).
Die in
Kubernetes 1.9 eingeführte
Möglichkeit, Block-Raw-Geräte (kein Netzwerk) als persistente Volumes zu verwenden, wurde in die Beta-Version
übersetzt und ist jetzt standardmäßig aktiviert.
Wir schließen das Thema Speicher mit der Tatsache ab, dass die Unterstützung für GCERegionalPersistentDisk
als stabil
deklariert wird .
Clusterknoten
Die Alpha-Version der
Unterstützung für Geräteüberwachungs-Plugins von Drittanbietern wurde eingeführt. Die Idee hinter dieser Initiative ist es, gerätespezifisches Wissen
aus dem Baum von Kubelet herauszuholen. Clusteradministratoren erhalten Metriken, die von Geräte-Plugins auf Containerebene gemeldet werden, und Hersteller können diese Metriken erstellen, ohne Änderungen am Kubernetes-Kern vornehmen zu müssen. Details zur Implementierung finden Sie im Vorschlag, der als
Kubelet-Metadaten-API bezeichnet wird .
Der als stabil
deklarierte Kubelet Plugin Watcher (auch als Kubelet Device Plugin Registration bekannt) ermöglicht Plug-Ins auf Knotenebene (Geräte-Plug-Ins, CSI und CNI), mit Kubelet über sich selbst zu kommunizieren.
Eine neue Funktion im Alpha-Status ist
NodeLease . Wenn früher der „Herzschlag“ eines Knotens von NodeStatus bestimmt wurde, ist jedem Knoten mit einer neuen Funktion ein
Lease Objekt zugeordnet (im
kube-node-lease Namespace), das vom Knoten regelmäßig aktualisiert wird. "Pulse" wird jetzt durch beide Parameter eingestellt: den alten NodeStatus, der nur bei Änderungen oder durch ein festes Timeout (standardmäßig einmal pro Minute) an den Master gemeldet wird, und ein neues Objekt (es wird häufig aktualisiert). Da dieses Objekt sehr klein ist, werden Skalierbarkeit und Leistung erheblich verbessert. Die Autoren machten sich daran, einen neuen „Impuls“ zu erstellen, nachdem sie Cluster mit einer Größe von mehr als 2000 Knoten getestet hatten, die während ihrer Arbeit an den Grenzen von etcd liegen könnten. Weitere Einzelheiten finden Sie in
KEP-0009 .
type Lease struct { metav1.TypeMeta `json:",inline"` // Standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata // +optional ObjectMeta metav1.ObjectMeta `json:"metadata,omitempty"` // Specification of the Lease. // More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status // +optional Spec LeaseSpec `json:"spec,omitempty"` } type LeaseSpec struct { HolderIdentity string `json:"holderIdentity"` LeaseDurationSeconds int32 `json:"leaseDurationSeconds"` AcquireTime metav1.MicroTime `json:"acquireTime"` RenewTime metav1.MicroTime `json:"renewTime"` LeaseTransitions int32 `json:"leaseTransitions"` }
(Die kompakte Spezifikation des neuen Objekts zur Darstellung des "Impulses" des Knotens - Lease - ist identisch mit LeaderElectionRecord )Sicherheit
Die Alpha-Version von
Dynamic Audit Control folgt den Ideen von Dynamic Admission Control und bietet eine dynamische Konfiguration erweiterter Überwachungsfunktionen. Dazu können Sie jetzt (dynamisch) einen Webhook registrieren, der einen Strom von Ereignissen empfängt. Die Notwendigkeit dieser Funktion wird durch die Tatsache erklärt, dass die Kubernetes-Überwachung sehr leistungsstarke Funktionen bietet, diese jedoch schwer zu konfigurieren sind und für jede Konfigurationsänderung immer noch ein Neustart des Apiservers erforderlich ist.
Die Datenverschlüsselung in etcd (siehe offizielle Dokumentation ) wurde vom experimentellen Status in die Beta übertragen.
kind: EncryptionConfiguration apiVersion: apiserver.config.k8s.io/v1 resources: - resources: - secrets providers: - identity: {} - aesgcm: keys: - name: key1 secret: c2VjcmV0IGlzIHNlY3VyZQ== - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - aescbc: keys: - name: key1 secret: c2VjcmV0IGlzIHNlY3VyZQ== - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - secretbox: keys: - name: key1 secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
(Eine Beispielkonfiguration mit verschlüsselten Daten ist der Dokumentation entnommen.)Unter den weniger bedeutenden Innovationen in dieser Kategorie:
- Jetzt kann Apiserver so konfiguriert werden , dass Anforderungen abgelehnt werden, die nicht in Überwachungsprotokolle gelangen können .
PodSecurityPolicy Objekte PodSecurityPolicy mit Unterstützung der MayRunAs Regel für die Optionen fsGroup und supplementalGroups hinzugefügt, mit der der Bereich der zulässigen Gruppenkennungen (GIDs) für Pods / Container definiert werden kann, ohne die Standard-GID zu erzwingen. Darüber hinaus ist mit PodSecurityPolicy die RunAsGroup-Strategie jetzt bei der Spezifikation von RunAsGroup , d. H. Sie können die Haupt-GID für Container steuern.- Für kube-scheduler haben wir den vorherigen unsicheren Port (10251) durch den neuen sicheren Port (10259) ersetzt und standardmäßig aktiviert. Wenn keine zusätzlichen Flags angegeben sind, werden beim Laden selbstsignierte Zertifikate dafür im Speicher erstellt.
CLI
Der
kubectl diff ,
der den Unterschied zwischen der lokalen Konfiguration und der aktuellen Beschreibung des Arbeitsobjekts anzeigt (funktioniert und rekursiv für Verzeichnisse mit Konfigurationen), hat den Beta-Status erhalten.
Tatsächlich "prognostiziert"
diff die Änderungen, die mit dem
kubectl apply , und eine weitere neue Funktion wird
verwendet -
APIServer DryRun . Sein Kern - Leerlaufstart - sollte aus dem Namen ersichtlich sein, und eine detailliertere Beschreibung finden Sie in der
Kubernetes-Dokumentation . Übrigens wurde in Release 1.13 auch die DryRun-Funktion auf die Beta-Version „aktualisiert“ und standardmäßig aktiviert.
Ein weiterer Fortschritt in der Beta-Phase der Konsolenwelt von Kubernetes hat sich auf den
neuen Plugin-Mechanismus ausgewirkt . Unterwegs
korrigierten sie die Reihenfolge der Ausgabe von Plugins (
kubectl plugin list ) und entfernten die zusätzliche Sortierung von dort.
Zusätzlich wurde die Ausgabe der verwendeten
kurzlebigen Speicherressourcen zum
kubectl describe node hinzugefügt , und dem
kubectl describe pod wurden Volumina des
projizierten Typs hinzugefügt .
Andere Änderungen
Die
Taint Based Eviction Scheduler-Funktion wurde in den Beta-Status konvertiert und ist nach einer
langen Entwicklungspause standardmäßig aktiviert. Der Zweck besteht darin, Knoten (über NodeController oder Kubelet) automatisch Fehler hinzuzufügen, wenn bestimmte Bedingungen auftreten, wie z. B.
node.kubernetes.io/not-ready , die dem
NodeCondition Wert in
Ready=False .
Eine Anmerkung zu kritischen Pods für den Betrieb des Clusters -
critical-pod - ist veraltet. Stattdessen wird vorgeschlagen,
Prioritäten zu verwenden
(in der Beta mit Kubernetes 1.11) .
Für AWS wurde zum ersten Mal (als Teil der Alpha-Versionen) Folgendes verfügbar:
- Integration für AWS ALB (Application Load Balancer) mit Kubernetes Ingress-Ressourcen - aws-alb-ingress-controller (das Projekt wurde ursprünglich von Ticketmaster und CoreOS erstellt, um das erste in die AWS-Cloud zu migrieren);
- AWSs externes CCM (Cloud Controller Manager) - Cloud-Provider-aws , das für den Start von Controllern mit Cloud-spezifischen Provider-Funktionen (AWS) verantwortlich ist.
SIG Azure hat zusätzliche Unterstützung für Azure Disk (Ultra SSD-, Standard SSD- und Premium Azure-Dateien) implementiert und die
ressourcenübergreifenden Knoten auf Beta umgestellt. Darüber hinaus können CNI-Plugins für Windows jetzt DNS in einem Container konfigurieren.
Kompatibilität
- Die etcd- Version ist 3.2.24 (hat sich seit Kubernetes 1.12 nicht geändert).
- Verifizierte Versionen von Docker - 1.11.1, 1.12.1, 1.13.1, 17.03, 17.06, 17.09, 18.06 (ebenfalls nicht geändert).
- Go- Version - 1.11.2 stimmt mit dem unterstützten Minimum überein.
- Die CNI- Version ist 0.6.0.
- Die CSI- Version ist 1.0.0.
- Die CoreDNS- Version ist 1.2.6.
PS
Lesen Sie auch in unserem Blog: