
DeepMind erstellt wirklich erstaunliche Algorithmen, die in der Lage sind, was Maschinensysteme zuvor nicht erreichen konnten. Insbesondere das neuronale Netzwerk
AlphaGo konnte die besten Spieler der Welt schlagen. Experten zufolge sind die Fähigkeiten des Systems inzwischen so stark gewachsen, dass es nicht einmal sinnvoll ist, zu versuchen, es zu besiegen - das Ergebnis ist vorbestimmt.
Trotzdem hört das Unternehmen hier nicht auf, sondern arbeitet weiter. Dank der Forschung seiner Mitarbeiter wurde
eine verbesserte Version von AlphaGo namens AlphaZero geboren. Wie im Titel angegeben, konnte das System selbst lernen, wie man drei logische Spiele gleichzeitig spielt - Schach, Shogi und Los.
Der Unterschied zwischen der neuen und allen vorherigen Versionen
bestand darin, dass das System selbst fast alles gelernt hat. Sie fing von vorne an und lernte schnell, alle drei Spiele perfekt zu spielen. Niemand hat AlphaZero geholfen - das System hat „alles von selbst“.
Schach war eher im Set enthalten, wie es in der Tradition üblich ist - es ist nicht schwierig, einem Computer das Schachspielen beizubringen, nein. Zum ersten Mal wurde in den 1950er Jahren ein Computersystem ins Spiel gebracht. Dann, bereits in den 60er Jahren, wurde das
Mac Hack IV- Programm entwickelt, das begann, menschliche Rivalen zu schlagen. Im Laufe der Zeit verbesserten sich die Schachprogramme allmählich, und 1997 entwickelte IBM den „Schachcomputer“ Deep Blue, der es schaffte, Großmeister und Weltmeister Garry Kasparov zu schlagen.
Wie er selbst betont, spielen derzeit viele Anwendungen auf einem Smartphone besser Schach als Deep Blue. Nachdem die Entwickler bei der Entwicklung von Systemen, die Schach spielen können, Perfektion erreicht hatten, begannen sie, neue Versionen von Konkurrenten für menschliche Computer zu entwickeln - insbesondere gelang es ihnen, dem Computer das Spielen beizubringen. Zuvor galt dieses Spiel mit einer tausendjährigen Geschichte als eines der unzugänglichsten für das "Verständnis" des Computers. Aber die Zeiten haben sich geändert. Wie oben erwähnt, erreichte AlphaGo ein so hohes Maß an Beherrschung des Go-Spiels, dass eine Person nicht in der Nähe stand.
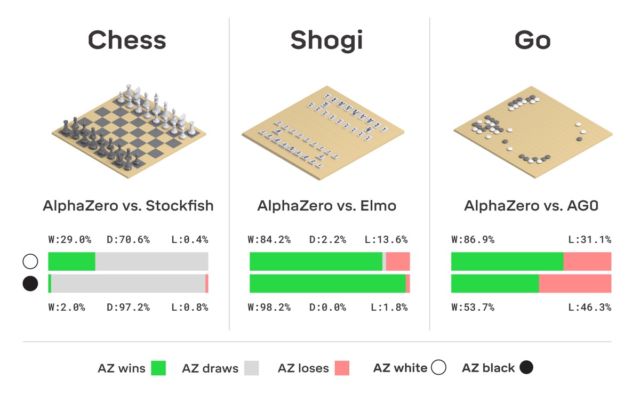
Übrigens hat AlphaGo dieses Jahr ein Update erhalten, dank dessen das neuronale Netzwerk nun verschiedene Strategien zum Spielen lernen kann, ohne menschliches Eingreifen. AlphaGo spielt immer wieder mit sich selbst und verbessert sich. Es ist diese Art von Trainingssystem, das AlphaGos „Nachkomme“ verwendet - das neuronale AlphaZero-Netzwerk. In nur drei Tagen erreichte sie in Go eine solche Meisterschaft, dass sie die Originalversion von AlphaGo mit einer Punktzahl von 100 zu 0 besiegte. Das einzige, was das System anfänglich erhält, sind die Spielregeln.
Hier gibt es keine Fiktion, DeepMind verwendet das bekannte maschinelle Lernsystem zur Verstärkung. Der Computer versucht zu gewinnen, weil er für jeden Sieg eine Belohnung (Punkte) erhält. Darüber hinaus verliert AlphaZero im Lernprozess Millionen von Kombinationen. AlphaZero benötigt nur 0,4 Sekunden, um den nächsten Zug falsch zu berechnen und die Gewinnwahrscheinlichkeit zu bewerten. Was das AlphaGo der ursprünglichen Version betrifft, bestand das neuronale Netzwerk aus zwei Elementen, zwei neuronalen Netzwerken - eines bestimmte die nächste mögliche Bewegung und das zweite berechnete die Wahrscheinlichkeiten.
Um das Master-Level in Go AlphaZero zu erreichen, müssen Sie ungefähr 4,5 Millionen Spiele „scrollen“, wenn Sie mit sich selbst spielen. Aber AlphaGo benötigte 30 Millionen Spiele.
Es ist erwähnenswert, dass AlphaZero speziell für das Spielen von Go entwickelt wurde. Das hat das Unternehmen nicht vergessen. Aber neben go kann das System auch zwei andere Spiele lernen, die oben erwähnt wurden. Das verwendete System ist das gleiche - maschinelles Lernen mit Verstärkung. Es ist erwähnenswert, dass AlphaZero nur mit Aufgaben arbeitet, die eine bestimmte Anzahl von Lösungen haben. Das System benötigt außerdem ein Umgebungsmodell (virtuell).
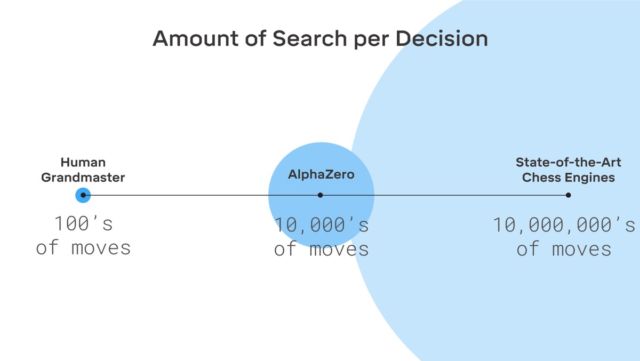
Interessanterweise glaubt Kasparov selbst, dass eine Person viel von Systemen wie AlphaGo bekommen kann - man kann viel von ihnen lernen.
Derzeit stehen die Entwickler vor der Aufgabe, einem Computer beizubringen, besser als jeder andere Spieler Poker zu spielen, und ein System zu entwickeln, das jeden Esportler in einem fairen Kampf schlagen kann. In jedem Fall ist klar, dass neuronale Netze und KI zu viel fähig sind.