
Im vergangenen Dezember gab es eine
Welle von Neuigkeiten über die unglaubliche Leistung einer neuen Schach-Engine, die das AlphaZero-Unternehmen DeepMind für künstliche Intelligenz einsetzt. Heute haben sie erstaunliche Ergebnisse für eine aktualisierte Version dieser Engine veröffentlicht.
Die Ergebnisse lassen erneut keinen Zweifel daran, dass AlphaZero eine der stärksten Schach-Engines der Welt ist.
Aktualisiert AlphaZero besiegte Stockfish 8 in einem neuen Match mit 1000 Spielen mit dem Ergebnis: 155 Siege, 6 Niederlagen, 839 Unentschieden.
AlphaZero hat auch Stockfish in einer Reihe von Spielen mit ungleicher Zeitkontrolle übertroffen und die traditionelle Engine sogar mit einem Handicap von 10 Mal besiegt.
Laut DeepMind übertraf der neue AlphaZero in weiteren Spielen die „neueste Entwicklungsversion“ von Stockfish am 13. Januar 2018 und zeigte fast identische Ergebnisse wie im Spiel gegen Stockfish 8.
Laut DeepMind hat ihre Engine für maschinelles Lernen auch alle Spiele gegen die "Stockfish-Variante, die ein starkes Debütbuch verwendet" gewonnen. Das Hinzufügen eines Debütbuchs schien Stockfish zu helfen, der schließlich eine bedeutende Anzahl von Spielen gewann, als AlphaZero schwarz spielte, aber nicht genug, um das Match zu gewinnen.
Die Ergebnisse wurden
in einem Artikel in der Zeitschrift Science veröffentlicht und von ausgewählten
Schachmedien zur Verfügung gestellt .
Das Spiel mit 1000 Spielen fand Anfang 2018 statt. Im Match erhielten AlphaZero und Stockfish drei Stunden pro Spiel plus einen Gewinn von 15 Sekunden pro Spielzug. Diese Zeitkontrolle wird wahrscheinlich zu einem der größten Argumente gegen die Ergebnisse des letztjährigen Spiels machen, nämlich dass 2017 eine Zeitkontrolle von einer Minute pro Runde ein starker Vorteil für AlphaZero war.
Mit drei Stunden plus einer Erhöhung um 15 Sekunden ist ein solches Argument nicht sinnvoll, da dies eine enorme Spielzeit für jede Schachengine darstellt. In Spielen mit ungleichen Zeiten dominierte AlphaZero sogar mit einem Zeitverhältnis von 10 zu 1. Stockfish begann erst mit einem Verhältnis von 30 zu 1 zu gewinnen.
AlphaZero-Ergebnisse in Spielen mit ungleichen Zeiten zeigen, dass es nicht nur viel stärker als jede herkömmliche Schach-Engine ist, sondern auch eine viel effizientere Zugsuche verwendet. Laut DeepMind verwendet AlphaZero die Monte-Carlo-Baumsuche und untersucht etwa 60.000 Positionen pro Sekunde, verglichen mit 60 Millionen bei Stockfish.
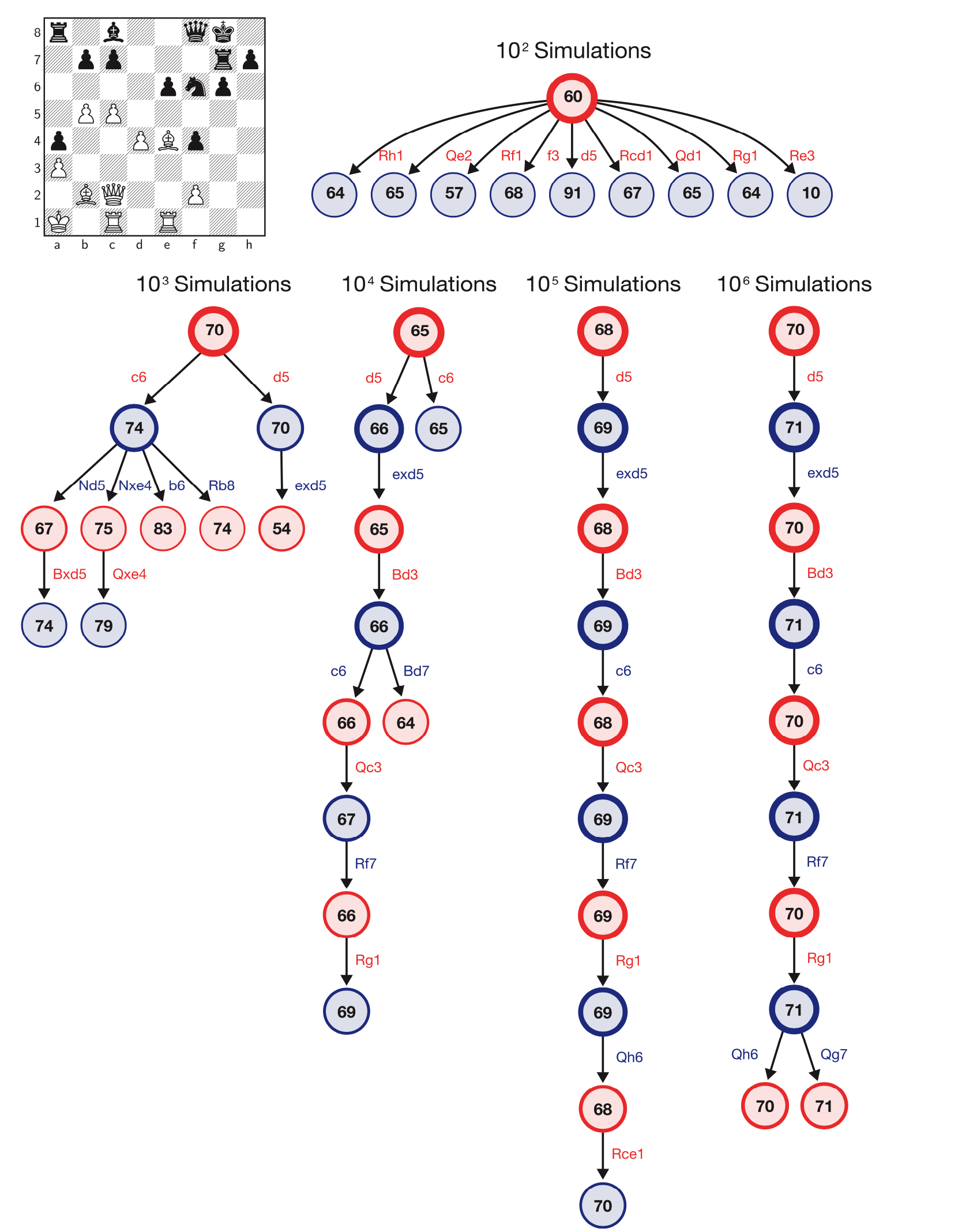 AlphaZero verschiebt die Darstellung des Suchalgorithmus. Bild von DeepMind aus einem Artikel in Science.
AlphaZero verschiebt die Darstellung des Suchalgorithmus. Bild von DeepMind aus einem Artikel in Science.Dem Artikel zufolge ist der aktualisierte AlphaZero-Algorithmus in drei komplexen Spielen identisch: Schach, Shogi und Go. Diese Version von AlphaZero konnte nach stundenlangem Selbsttraining die besten Computer-Engines aller drei Spiele besiegen, beginnend mit einfachen Spielregeln.
DeepMind hat 210 Spiele aus dem Match veröffentlicht, die Sie
hier herunterladen können.
Die neue Version von AlphaZero hat sich darauf trainiert, Schach zu spielen, beginnend mit den Spielregeln, und verwendet maschinelles Lernen, um seine neuronalen Netze ständig zu aktualisieren. Laut DeepMind wurden 5.000 TPUs (Google-Tensorprozessor, spezialisierte integrierte Schaltung für KI) verwendet, um den ersten Satz von Spielen für das unabhängige Spielen zu generieren, und dann wurden 16 TPUs zum Trainieren neuronaler Netze verwendet.
Die gesamte Trainingszeit im Schach dauerte neun Stunden. Laut DeepMind benötigte der neue AlphaZero nur vier Stunden Training, um Stockfish zu übertreffen. In neun Stunden war er dem Schachweltmeister weit voraus.
Für die Spiele selbst verwendete Stockfish 44 Prozessoren, während AlphaZero eine Maschine mit vier TPUs und 44 Prozessorkernen verwendete.
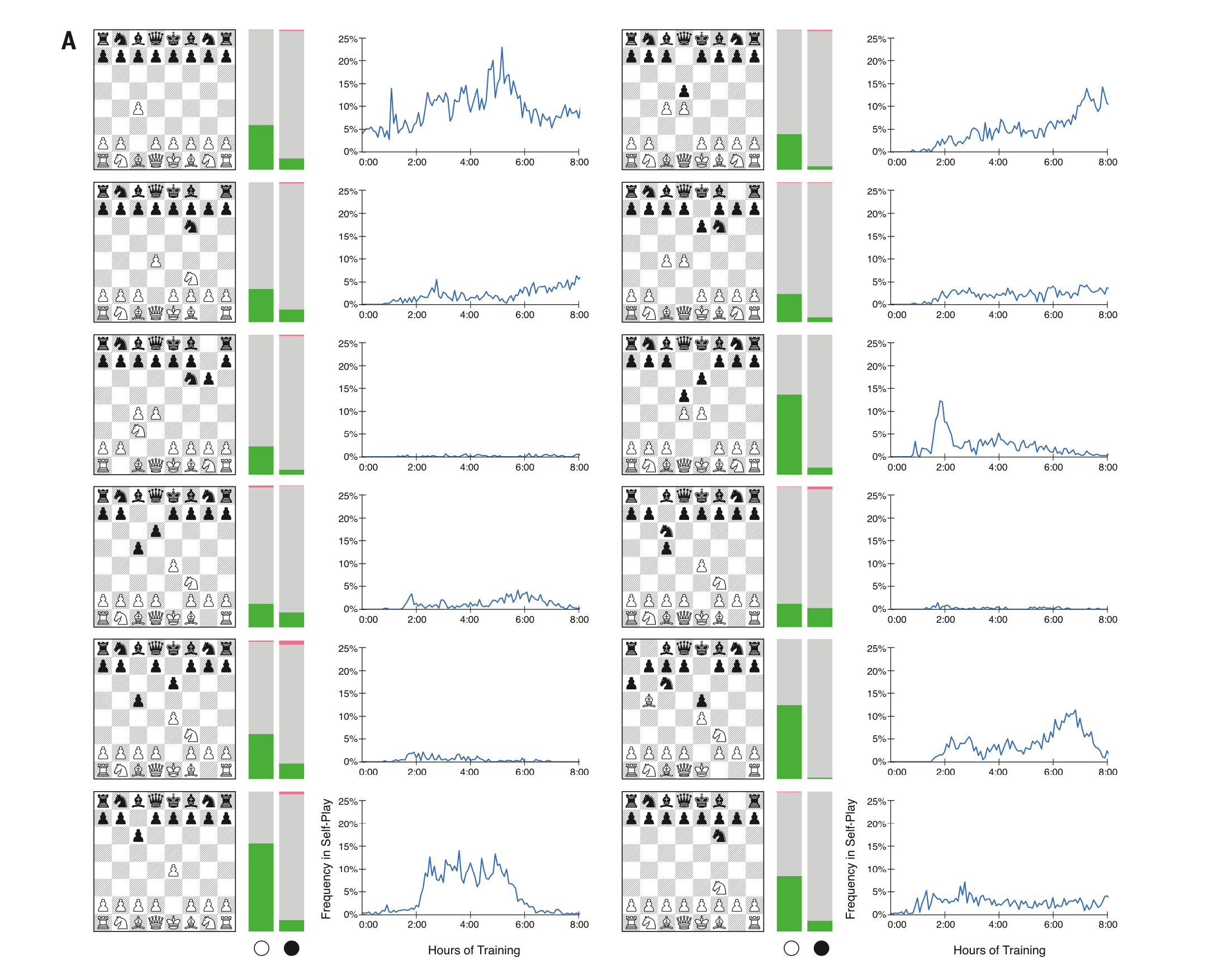 AlphaZero vs. Stockfish führt zu seinen beliebtesten Debüts. Auf der linken Seite spielt AlphaZero Weiß. rechts - schwarz.
AlphaZero vs. Stockfish führt zu seinen beliebtesten Debüts. Auf der linken Seite spielt AlphaZero Weiß. rechts - schwarz.DeepMind selbst hat den einzigartigen Spielstil ihres Programms im Artikel erwähnt:
"In mehreren Spielen hat AlphaZero Figuren für einen langfristigen strategischen Vorteil geopfert, was darauf hindeutet, dass es eine kontextuellere Positionsbewertung als die in früheren Schachprogrammen verwendeten regelbasierten Bewertungen hat", so DeepMind-Forscher.
AI betonte auch, wie wichtig es ist, dieselbe Version von AlphaZero in drei verschiedenen Spielen zu verwenden, und wirbt damit als Durchbruch in der gesamten Spielintelligenz:
"Diese Ergebnisse bringen uns der Erfüllung der langjährigen Ambitionen der künstlichen Intelligenz näher: Ein gemeinsames Spielsystem, das lernen kann, jedes Spiel zu beherrschen", so DeepMind-Forscher.