Gestern erhielt ich einen Brief von einem Zehntklässler aus Sibirien, der Mikroprozessorentwickler werden möchte. In diesem Bereich hat sie bereits einige Ergebnisse erzielt - sie hat die Multiplikationsanweisung zum einfachsten schoolMIPS-Prozessor hinzugefügt, sie für das Intel FPGA MAX10 FPGA synthetisiert, die maximale Frequenz und die gesteigerte Produktivität einfacher Programme ermittelt. All dies tat sie zuerst im Dorf Burmistrovo in der Region Nowosibirsk und dann auf einer Konferenz in Tomsk.
Jetzt zog Dasha Krivoruchko (so heißt die Zehntklässlerin) in ein Moskauer Internat und fragt mich, was sie sonst noch entwerfen soll. Ich denke, dass sie in dieser Phase ihrer Karriere einen Hardwarebeschleuniger für neuronale Netze entwerfen sollte, der auf einem systolischen Array für die Matrixmultiplikation basiert. Verwenden Sie die Verilog-Hardwarebeschreibungssprache und Intel FPGA FPGA, aber nicht billiges MAX10, sondern etwas teureres, um ein großes systolisches Array aufzunehmen.
Vergleichen Sie anschließend die Leistung der Hardwarelösung mit dem Programm, das auf dem schoolMIPS-Prozessor ausgeführt wird, sowie mit dem Python-Programm, das auf dem Desktop-Computer ausgeführt wird. Verwenden Sie als Testfall die Erkennung von Zahlen aus einer kleinen Matrix.

Eigentlich wurden alle Teile dieser Übung bereits von verschiedenen Personen entwickelt, aber der springende Punkt ist, dies in eine einzige, dokumentierte Übung zu fassen, die dann als Grundlage für den Online-Kurs und für praktische Wettbewerbe verwendet werden kann:
1) eNano, die Bildungsabteilung von RUSNANO, die in der Vergangenheit Charles Danchek-Seminare zum Entwurf moderner Elektronik (RTL-zu-GDSII-Route) für Studenten organisiert hat und derzeit an einem Online-Kurs dieser Art (Entwurf von Hardware auf der Ebene von Registerübertragungen + neuronalen Netzen) arbeitet, ist interessiert Lite-Kurs für Fortgeschrittene. Hier sind Charles und ich in ihrem Büro:

2) Die Basis für die Olympischen Spiele könnte an
den NTI-Olympischen Spielen interessiert sein, mit denen ich dieses Problem vor einigen Wochen in Moskau angesprochen habe. Für ein solches Beispiel könnten Teilnehmer an den Olympiaden eine Hardware für verschiedene Aktivierungsfunktionen hinzufügen. Hier sind Kollegen von den NTI-Olympischen Spielen:

Wenn Dasha dies entwickelt, könnte sie ihren gut beschriebenen Beschleuniger theoretisch sowohl in RUSNANO als auch in der NTI-Olympiade vorstellen. Ich denke, es wäre vorteilhaft für die Verwaltung ihrer Schule - es könnte im Fernsehen gezeigt oder allgemein an den Intel FPGA-Wettbewerb gesendet werden. Hier sind ein
paar Russen aus St. Petersburg beim Finale des Intel FPGA-Wettbewerbs in Santa Clara, Kalifornien :

Lassen Sie uns nun über die technische Seite des Projekts sprechen. Die Idee des systolischen Massenbeschleunigers wird in einem Artikel beschrieben, der vom Herausgeber von Khabra Vyacheslav Golovanov
SLY_G übersetzt wurde. Warum sind TPUs für tiefes Lernen so geeignet?So sieht ein Datenfluss-Diagramm für ein neuronales Netzwerk zur einfachen Erkennung aus:

Ein primitives Rechenelement, das Multiplikationen und Additionen durchführt:

Dieses systolische Array für die Matrixmultiplikation ist eine stark pipelinierte Struktur solcher Elemente und lautet:

Im Internet gibt es eine Menge Code auf Verilog und VHDL mit der Implementierung eines systolischen Arrays. Der Code befindet sich beispielsweise
unter diesem Blog-Beitrag :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
Ich stelle fest, dass dieser Code nicht optimiert und im Allgemeinen ungeschickt ist (und sogar unprofessionell geschrieben ist - die Quelle im Beitrag verwendet Blockzuweisungen in @ (posedge clk) - ich habe ihn behoben). Dasha könnte beispielsweise Verilog verwenden, um Konstrukte für eleganteren Code zu generieren.
Zusätzlich zu zwei extremen Realisierungen des neuronalen Netzwerks (auf dem Prozessor und auf dem systolischen Array) könnte Dasha andere Optionen in Betracht ziehen, die schneller als der Prozessor sind, aber nicht so unersättlich wie die Multiplikationsoperationen wie ein systolisches Array. Dies gilt zwar eher nicht für Schüler, sondern für Schüler.
Eine Option ist ein ausführendes Gerät mit einer großen Anzahl parallel funktionierender Funktionsblöcke, wie in einem Out-of-Order-Prozessor:

Eine weitere Option ist das sogenannte Coarse Grained Reconfigurable Array - eine Matrix von Quasi-Prozessor-Elementen, von denen jedes ein kleines Programm hat. Diese Prozessorelemente ähneln im Idealfall FPGA / FPGA-Zellen, arbeiten jedoch nicht mit einzelnen Signalen, sondern mit Gruppen von Bits / Zahlen auf Bussen und Registern - siehe den
Live-Bericht von der Geburt eines großen Spielers in der Hardware-KI, der TensorFlow beschleunigt und mit NVidia konkurriert. " .
Nun der Originalbrief von Dasha:
Guten Tag, Yuri.
2017 habe ich in Ihrem Workshop an Ihrer Schule in LSHUP studiert und im Oktober 2017 an einer Konferenz in Tomsk im Oktober desselben Jahres teilgenommen, bei der es darum ging, die Multiplikationseinheit in den SchooolMIPS-Prozessor einzubetten.
Ich möchte diese Arbeit jetzt fortsetzen. Im Moment habe ich es geschafft, in der Schule die Erlaubnis zu bekommen, dieses Thema als kleine Kursarbeit zu nehmen. Haben Sie die Möglichkeit, mir bei der Fortsetzung dieser Arbeit zu helfen?
PS Da die Arbeit in einem bestimmten Format ausgeführt wird, ist eine Einführung und eine Literaturübersicht zum Thema erforderlich. Bitte geben Sie die Quellen an, aus denen Sie Informationen zur Entwicklungsgeschichte dieses Themas, zu Architekturphilosophien usw. abrufen können, wenn Sie über solche Ressourcen nachdenken.
Außerdem ist es im Moment, in dem ich in Moskau in einem Internat lebe, möglicherweise einfacher, miteinander zu interagieren.
Mit freundlichen Grüßen,
Daria Krivoruchko.
Dasha unterrichtete Verilog und Design auf Registerebene mit Hilfe von mir und dem Buch
„Digitale Schaltkreise und Computerarchitektur“ von David Harris und Sarah Harris . Wenn Sie jedoch ein Schüler / eine Schülerin sind und die Grundkonzepte auf einer sehr einfachen Ebene verstehen möchten, hat der Verlag DMK-Press für Sie eine
russische Übersetzung des japanischen Mangas 2013 über digitale Schaltkreise veröffentlicht, die von Amano Hideharu und Meguro Koji erstellt wurden. Trotz der leichtfertigen Form der Präsentation führt das Buch die logischen Elemente und D-Trigger korrekt ein
und bindet diese dann an die FPGAs :
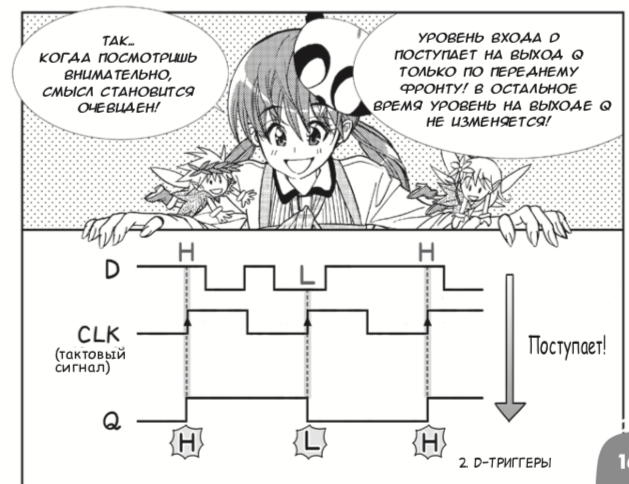
So sah die
Sommerschule für junge Programmierer in der Region Nowosibirsk aus, in der Dasha Verilog, FPGAs, eine Methode zur Entwicklung von Registertransfers (Register Transfer Level - RTL), lernte:


Und hier ist Dashas Rede auf der Konferenz in Tomsk zusammen mit einem anderen Zehntklässler, Arseniy Chegodaev:
Nach Dashas Gespräch mit mir und Stanislav Zhelnio
Sparf , dem Hauptentwickler des SchoolMIPS-Lernprozessorkerns für die Implementierung auf FPGAs:

Das schoolMIPS-Projekt finden Sie unter
https://github.com/MIPSfpga/schoolMIPS . In der einfachsten Konfiguration dieses Trainingsprozessorkerns gibt es in Verilog nur 300 Zeilen, während im industriellen Embedded-Kern der Mittelklasse etwa 300.000 Zeilen vorhanden sind. Trotzdem konnte Dasha spüren, wie die Arbeit von Designern in der Branche aussieht, die den Decoder und das ausführende Gerät auf die gleiche Weise ändern, wenn sie dem Prozessor neue Anweisungen hinzufügen:
Abschließend präsentieren wir Fotos des Dekans der Samara-Universität Ilya Kudryavtsev, der daran interessiert ist, eine Sommerschule und Olympiaden mit FPGA-Prozessoren für zukünftige Bewerber zu schaffen:

Und ein Foto der Mitarbeiter von Zelenograd MIET, die bereits nächstes Jahr eine solche Sommerschule planen:

Sowohl Materialien von RUSNANO als auch die möglichen Materialien der NTI-Olympischen Spiele sowie die Erfolge, die in den letzten Jahren bei der Implementierung von FPGAs und Mikroarchitekturen im Programm des HSE MIEM, der Moskauer Staatsuniversität und von
Kasan Innopolis erzielt wurden, sollten an einem Ort und an einem anderen Ort gut
ankommen .