Wir bei X5 verarbeiten viele Daten in einem ERP-System. Es wird angenommen, dass uns sonst niemand in SAP ERP und SAP BW in Russland verarbeitet. Aber es gibt noch einen anderen Punkt: Die Anzahl der Operationen und die Belastung dieses Systems nehmen rapide zu. 3 Jahre lang haben wir um die Leistung unseres ERP-Schwergewichts „gekämpft“, viele Zapfen bekommen und mit welchen Methoden sie behandelt wurden, sagen wir unter dem Schnitt.

ERP X5
Jetzt betreibt X5 mehr als 13.000 Geschäfte. Die meisten Geschäftsprozesse eines jeden von ihnen durchlaufen ein einziges ERP-System. Jedes Geschäft kann zwischen 3.000 und 30.000 Produkte haben, was zu Problemen mit der Systemlast führt, weil Prozesse der regelmäßigen Neuberechnung von Preisen durchlaufen sie in Übereinstimmung mit Beförderungen und gesetzlichen Anforderungen sowie der Berechnung der Wiederauffüllung von Lagerbeständen. All dies ist von entscheidender Bedeutung. Wenn nicht rechtzeitig berechnet wird, welche Waren in welcher Menge morgen in das Geschäft geliefert werden sollen oder welcher Preis für die Waren gelten soll, finden Käufer in den Regalen nicht das, wonach sie gesucht haben, oder können die Waren nicht zum Preis der aktuellen Aktion kaufen Aktien. Im Allgemeinen ist das ERP-System neben der Bilanzierung von Finanztransaktionen für einen Großteil des Alltags in jedem Geschäft verantwortlich.
Einige Leistungsmerkmale eines ERP-Systems. Die Architektur ist klassisch, dreistufig mit serviceorientierten Elementen: Darüber hinaus haben wir mehr als 5.000 Kunden und Terabyte an Informationsflüssen aus Filialen und Distributionszentren in der Anwendungsschicht - SAP ABAP mit mehr als 10.000 Prozessen und schließlich Oracle Database mit mehr als 100 TB Daten. Jeder ABAP-Prozess ist eine bedingt virtuelle Maschine, auf der ABAP-Geschäftslogik mit einem eigenen DBSL- und SQL-Dialekt, Caching, Speicherverwaltung, ORM usw. ausgeführt wird. Jeden Tag erhalten wir mehr als 15 TB Änderungen im Datenbankprotokoll. Die Laststufe beträgt 500.000 Anforderungen pro Sekunde.
Diese Architektur ist eine heterogene Umgebung. Jede der Komponenten ist plattformübergreifend. Wir können sie auf verschiedene Plattformen verschieben, die optimalen auswählen usw.
Die Tatsache, dass das ERP-System 365 Tage im Jahr 24 Stunden am Tag unter Last steht, fügt dem Feuer Treibstoff hinzu. Verfügbarkeit - 99,9% der Zeit während des ganzen Jahres. Die Ladung ist in Tag- und Nachtprofile und Hauswirtschaft in der Freizeit unterteilt.
Das ist aber noch nicht alles. Das System hat einen engen und engen Freigabezyklus. Es werden über 2.000 Chargenwechsel pro Jahr durchgeführt. Dies kann eine neue Schaltfläche und schwerwiegende Änderungen in der Logik von Geschäftsanwendungen sein.

Infolgedessen ist es ein großes und hoch ausgelastetes, aber gleichzeitig stabiles, vorhersehbares und wachstumsfähiges System, das Zehntausende von Geschäften beherbergen kann. Das war aber nicht immer der Fall.
2014. Bifurkationspunkt
Um in das praktische Material einzutauchen, müssen Sie bis 2014 zurückgehen. Dann gab es die schwierigsten Aufgaben, um das System zu optimieren. Es gab ungefähr 5.000 Geschäfte.
Das System befand sich zu diesem Zeitpunkt in einem solchen Zustand, dass die meisten kritischen Prozesse nicht skalierbar waren und nicht angemessen auf die wachsende Last (dh das Erscheinen neuer Geschäfte und Waren) reagierten. Außerdem wurde zwei Jahre zuvor ein teures Hi-End gekauft, und für einige Zeit war ein Upgrade nicht Teil unserer Pläne. Darüber hinaus standen die Prozesse in ERP bereits kurz vor dem Verstoß gegen SLA. Der Anbieter kam zu dem Schluss, dass die Belastung des Systems nicht skalierbar ist. Niemand wusste, ob sie mindestens + 10% des Lastanstiegs aushalten konnte. Und es war geplant, innerhalb von drei Jahren doppelt so viele Geschäfte zu eröffnen.
Es war unmöglich, das ERP-System einfach mit neuem Eisen zu versorgen, und es würde nicht helfen. Daher haben wir uns zunächst entschlossen, eine Softwareoptimierungstechnik in den Release-Zyklus aufzunehmen und die Regel zu befolgen: Das lineare Lastwachstum im Verhältnis zum Wachstum der Lasttreiber ist der Schlüssel zur Vorhersagbarkeit und Skalierbarkeit.
Was war die Optimierungstechnik? Dies ist ein zyklischer Prozess, der in mehrere Phasen unterteilt ist:
- Überwachung (Ermittlung von Engpässen im System und Ermittlung der Hauptverbraucher von Ressourcen)
- Analyse (Profilierung von Verbraucherprozessen, Identifizierung von Strukturen mit dem größten und nichtlinearen Einfluss auf die Last)
- Entwicklung (Verringerung des Einflusses von Strukturen auf die Last, Erreichen einer linearen Last)
- Testen in einer Qualitätsbewertungsumgebung oder Implementierung in einer produktiven Umgebung
Als nächstes wurde der Zyklus wiederholt.
Dabei haben wir festgestellt, dass die aktuellen Überwachungstools es uns nicht ermöglichen, Top-Verbraucher, Engpässe und ressourcenhungrige Prozesse schnell zu identifizieren. Um dies zu beschleunigen, haben wir die elastischen Such- und Grafana-Tools ausprobiert. Zu diesem Zweck entwickelten sie unabhängig voneinander Kollektoren, die von Standardüberwachungstools in Oracle / SAP / AIX / Linux Metriken auf die elastische Suche übertrugen und eine Echtzeitüberwachung des Systemzustands ermöglichten. Darüber hinaus bereicherten sie die Überwachung mit ihren benutzerdefinierten Metriken, z. B. Antwortzeit und Durchsatz bestimmter SAP-Komponenten oder Layout von Lastprofilen für Geschäftsprozesse.
Code- und Prozessoptimierung
Erstens sorgten sie für eine geringere Auswirkung von Engpässen auf die Geschwindigkeit für eine reibungslosere Lastversorgung des Systems.
Die meisten Geschäftsprozesse in unserem ERP-System, wie z. B. die regelmäßige Preisgestaltung oder die Bestandsauffüllungsplanung, sind die schrittweise Verarbeitung einer großen Datenmenge (für alle Waren und alle Filialen). Um die Verarbeitung im Rahmen derart schwieriger Aufgaben zu implementieren, haben wir einmal einen eigenen Batch-Parallel-Processing-Dispatcher entwickelt (im Folgenden als Load Scheduler bezeichnet). In diesem Fall wird in Form eines Pakets ein separat durchgeführter Verarbeitungsschritt für ein separates Geschäft dargestellt.
Anfänglich war die Logik des Schedulers so, dass zuerst die Pakete der ersten Verarbeitungsstufe für alle Speicher ausgeführt wurden, dann die Pakete der zweiten Stufe usw. Das heißt, das System führte gleichzeitig Prozesse aus, die denselben Lasttyp erzeugten und die Verschlechterung bestimmter Ressourcen verursachten (Eingabe-Ausgabe in die Datenbank oder CPU auf Anwendungsservern usw.).
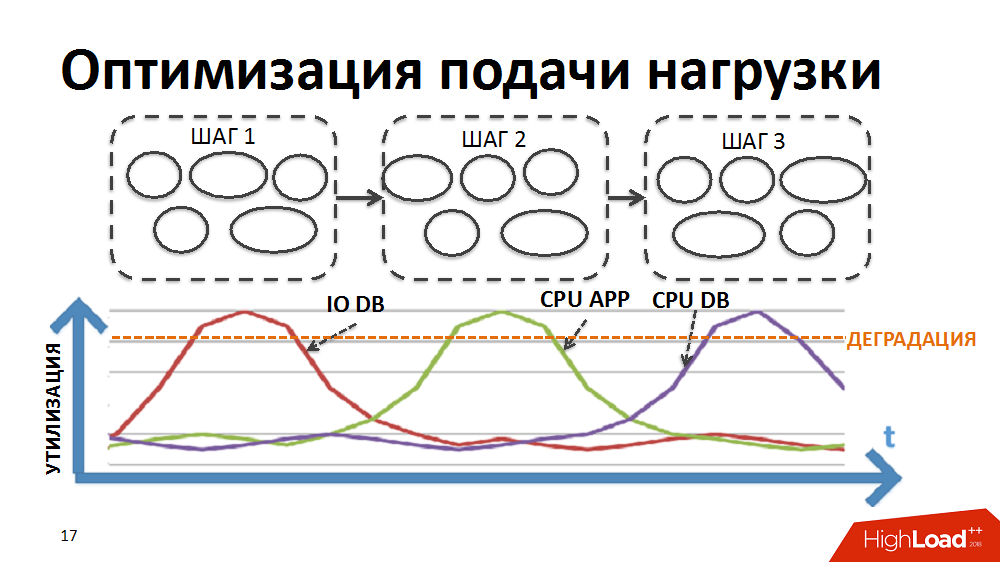
Wir haben die Logik des Schedulers so umgeschrieben, dass die Paketkette für jedes Geschäft separat gebildet wurde und die Priorität beim Starten neuer Pakete nicht nach Stufen, sondern nach Geschäften erstellt wurde.
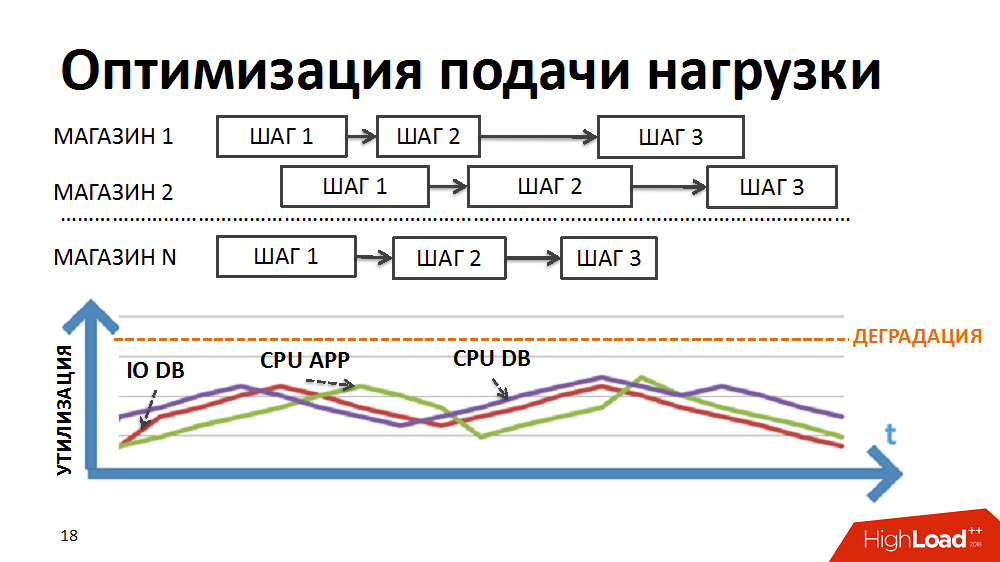
Aufgrund der unterschiedlichen Dauer der Pakete für verschiedene Filialen und der kontrollierten großen Anzahl gleichzeitig ausgeführter Prozesse im Rahmen der Aufgaben des Load Scheduler haben wir die gleichzeitige Ausführung heterogener Prozesse, eine reibungslosere Beladung der Load und die Beseitigung einiger Engpässe erreicht.
Dann begannen sie, einzelne Designs zu optimieren. Jedes einzelne Paket wurde überprüft, profiliert und nicht optimale Designs zusammengestellt und Ansätze angewendet, um sie zu optimieren. Anschließend wurden diese Ansätze in die Vorschriften des Entwicklers aufgenommen, um ein unerwünschtes Lastwachstum während der Entwicklung des Systems zu verhindern. Einige von ihnen:
- Übermäßige Belastung der CPU von Anwendungsservern (Wird häufig durch nichtlineare Algorithmen im Programmcode generiert, z. B. die gute alte lineare Suche in Schleifen oder nichtlineare Suchalgorithmen für Schnittpunkte von Sätzen ungeordneter Elemente usw. ... Es wurde durch Ersetzen durch lineare Algorithmen behandelt: Ersetzen der linearen Suche in Schleifen durch Binär; Um nach Schnittpunkten von Mengen zu suchen, verwenden wir lineare Algorithmen, Vorbestellungselemente usw.)
- Identische Aufrufe der Datenbank mit denselben Bedingungen innerhalb desselben Prozesses führen häufig zu einer übermäßigen CPU-Auslastung der Datenbank (dies wird behandelt, indem die Ergebnisse des ersten Beispiels im Programmspeicher oder auf der Ebene des Anwendungsservers zwischengespeichert werden und zwischengespeicherte Daten für nachfolgende Beispiele verwendet werden).
- Häufige Join-Anforderungen (es ist natürlich besser, sie auf Datenbankebene auszuführen, aber manchmal haben wir uns erlaubt, sie in einfache Beispiele aufzuteilen, deren Ergebnis zwischengespeichert wird, und die Klebelogik an die Anwendung zu übertragen. In diesen Fällen ist es besser, den Anwendungsserver und nicht die Datenbank aufzuwärmen. )
- Starke Join-Anforderungen führen zu vielen E / A.
Über letzteres im Detail. In diesem Fall wurde das Datenmodell in eine weniger normale Form übersetzt. Ein klassisches Beispiel ist eine Auswahl von Buchhaltungsbelegen für ein bestimmtes Datum für ein einzelnes Geschäft. Viele Mitarbeiter fordern es an. Die Haupttabelle (Überschriften-Tabelle) speichert die Daten der Dokumente in der Positionstabelle - das Geschäft und die Waren. Die häufigsten Abfragen sind eine Auswahl aller Dokumente für ein bestimmtes Geschäft für ein bestimmtes Datum. Bei dieser Anforderung gibt der Filter nach Datum in der Überschriften-Tabelle 500.000 Datensätze an, der Filter nach Speicher - die gleiche Menge. Gleichzeitig haben wir nach dem Aufkleben eines separaten Geschäfts zum richtigen Datum eine Laufzeit von 3.000. Unabhängig davon, aus welcher Tabelle wir Daten filtern und kleben, erhalten wir immer viele unerwünschte E / A.
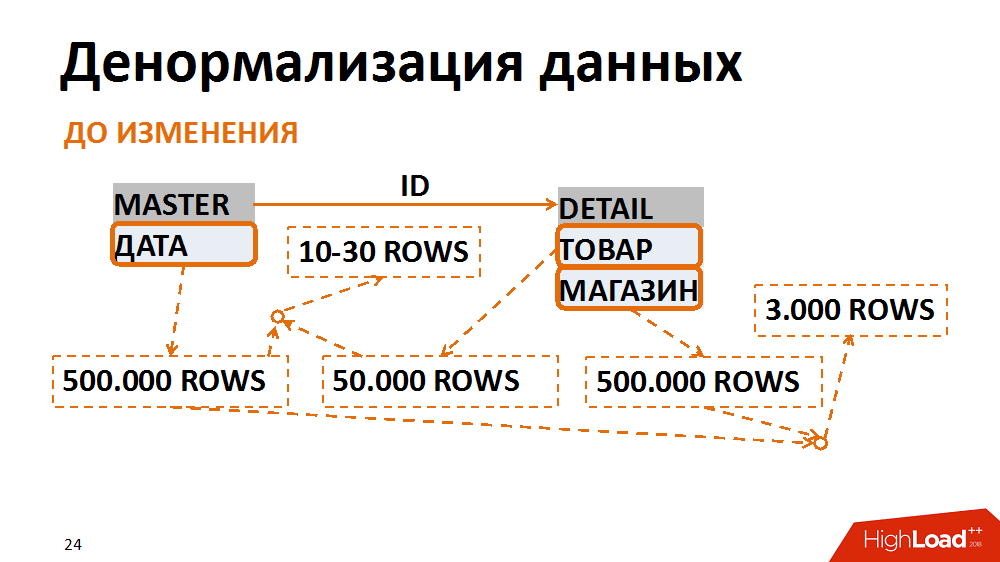
Dies kann vermieden werden, indem die Daten in einer weniger normalen Form dargestellt werden. In einem Fall wurde das Datumsfeld in der Positionstabelle dupliziert, beim Erstellen von Dokumenten ausgefüllt, die Indizes für die Schnellsuche gesammelt und bereits nach der Positionstabelle gefiltert. Nachdem wir unbedeutende Gemeinkosten für das Speichern eines neuen Felds und neuer Indizes geopfert haben, haben wir die Anzahl der Eingabe- / Ausgabeoperationen, die durch problematische Abfragen generiert wurden, mehrmals reduziert.

2015. Das Problem eines Dienstes
Eineinhalb Jahre lang haben wir das System hervorragend optimiert. Es ist vorhersehbarer geworden. Die Pläne, die Anzahl der Filialen zu verdoppeln, blieben jedoch relevant, sodass die Herausforderungen weiterhin vor uns lagen.
Auf dem Weg nach oben stießen wir auf verschiedene Engpässe. Zum Beispiel stellten sie Ende 2015 fest, dass sie sich in der Leistung eines Kerndienstes der Plattform ausgeruht hatten. Dies ist ein logischer Sperrdienst von SAP ABAP. Aus diesem Grund würde das System dem Wachstum der Last eindeutig nicht standhalten. Am Horizont zeichneten sich große Geldverluste ab.
Zur Verdeutlichung besteht die Aufgabe des Dienstes darin, die logische Transaktionalität auf die Ebene des Anwendungsservers zu bringen. In ABAP kann eine einzelne Transaktion mehrere Schritte in verschiedenen Workflows durchlaufen. Damit die Transaktion abgeschlossen werden kann, gibt es einen Sperrdienst und zugehörige Mechanismen. Die darin enthaltenen Sperr- und Entsperrvorgänge erfolgen schnell, sind jedoch atomar und können nicht getrennt werden. Es gab ein Problem mit der synchronen E / A.
Der Service wurde etwas beschleunigt, nachdem die SAP-Entwickler einen speziellen Patch veröffentlicht hatten. Wir haben den Service auf eine andere Hardware umgestellt und an den Systemeinstellungen gearbeitet, aber dies war immer noch nicht genug. Die Obergrenze des Passdienstes lag bei ungefähr 7.000 Operationen pro Sekunde, und wir brauchten lange Zeit bereits 10.000.
Nach dem synthetischen Belastungstest wurde festgestellt, dass die Verschlechterung nicht linear ist und wir uns dennoch an der Grenze der Serviceleistung befinden, oberhalb derer sich die inakzeptable Verschlechterung des gesamten ERP-Systems manifestiert. Wiederholte Anrufe bei den Entwicklern haben nur zu einem enttäuschenden Urteil geführt - der Service funktioniert ordnungsgemäß, wir benötigen in der aktuellen Lösungsarchitektur einfach zu viel. Selbst wenn wir uns sofort verpflichten würden, die gesamte Architektur der Lösung zu wiederholen, würden wir mehrere Monate brauchen, um die Funktionsfähigkeit des aktuellen Systems aufrechtzuerhalten.
Eine der ersten Möglichkeiten, um die Lebensdauer eines Sperrdienstes zu verlängern, besteht darin, die E / A zu beschleunigen und in das Dateisystem zu schreiben. Was? Experimente mit einer Alternative zu AIX. Übertrug den Dienst auf Linux auf der leistungsstärksten Power-Maschine und gewann viel Reaktionszeit. Der Dienst mit eingeschaltetem Dateisystem verhielt sich genauso wie auf Aix mit deaktiviertem Dateisystem. Dann haben wir diesen Code auf eines der x86_64-Blades übertragen und eine noch fantastischere, sanft abfallende Leistungskurve als zuvor erhalten. Es sah lustig aus.
Es ist davon auszugehen, dass die Entwickler unter AIX und Linux im letzten Test etwas anderes gemacht haben, aber auch hier hat sich die Prozessorarchitektur ausgewirkt.
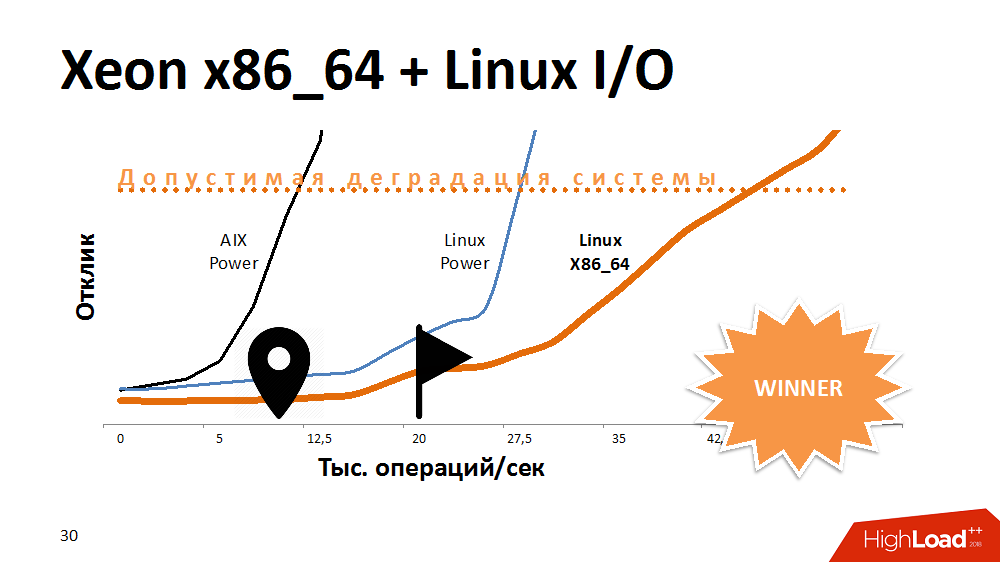
Was war die Schlussfolgerung? Einige Plattformen eignen sich ideal für Multithread-Datenbanken und bieten sowohl Leistung als auch Fehlertoleranz. Ein Prozessor mit einer anderen Architektur kann jedoch bestimmte Aufgaben besser bewältigen. Wenn Sie zu Beginn einer Lösung eine plattformübergreifende Aufgabe aufgeben, können Sie in Zukunft Platz für Manöver verlieren.
Trotzdem haben wir dieses Problem herausgefunden und der Service begann 3-4 mal schneller zu arbeiten, was für ein sehr langes Wachstum ausreicht.
2016. DB-CPU-Engpass
Buchstäblich ein halbes Jahr später traten exotische Probleme mit der CPU in der Datenbank auf. Es scheint klar zu sein, dass mit zunehmender Last der Verbrauch an Prozessorressourcen zunimmt. Aber SysTime begann, das meiste davon aufzunehmen, und es gab eindeutig ein Problem im Kernel. Sie begannen zu verstehen, synthetische Belastungstests durchzuführen und stellten fest, dass unser Durchsatz 300.000 Operationen pro Sekunde betrug, d. H. Milliarden Anfragen pro Stunde und dann Verschlechterung.
Als Ergebnis kamen wir zu dem Schluss, dass die perfekte Anfrage eine ist, die es nicht gibt. Wir haben unsere Optimierungstechnik um neue Ansätze erweitert und eine Prüfung des ERP-Systems durchgeführt: Wir haben begonnen, nach Abfragen zu suchen, beispielsweise mit geringer Effizienz (100.000 Auswahlen - als Ergebnis von 100 Zeilen oder 0 im Allgemeinen) -, um sie zu wiederholen. Wenn die "leeren" Anforderungen nicht entfernt werden können, lassen Sie sie gegebenenfalls in den "negativen Cache" wechseln. Wenn viele Anfragen nach denselben Produktdaten parallel verarbeitet werden, lassen Sie sie den Anwendungsserver und nicht die Datenbank quälen, wir zwischenspeichern sie. Wir „vergrößern“ auch eine große Anzahl häufiger Einzelabfragen zu einem Schlüssel im Rahmen eines Prozesses und ersetzen ihn durch seltenere Auswahlen für einen Teil eines Schlüssels. Um beispielsweise die Last in der Verarbeitungskette zu verteilen, können verschiedene Schritte auf verschiedenen Anwendungsservern ausgeführt werden. Das ist gut, aber in verschiedenen Phasen können sie dasselbe von der Basis verlangen. Lassen Sie dann den ersten Schritt nach dem Starten des Anwendungs-Cache einen Teil der Anforderungen, und es bleibt dort, um den Rest der Kette zu beenden.

Mit Hilfe solcher Tricks haben wir überall ein wenig gewonnen, aber am Ende haben wir die Basis ernsthaft entladen. Das System wurde zum Leben erweckt. In der Zwischenzeit kamen wir zu Aix.
Andere Experimente ergaben, dass es eine Leistungsobergrenze gibt - die bereits erwähnten 300.000 Datenbankaufrufe pro Sekunde. Die Wurzel des Problems war die Leistung der Netzwerkschnittstelle, die eine Obergrenze hatte - etwa 300.000 Pakete pro Sekunde in eine Richtung. Als sich die Decke näherte, wuchs die Zeit der Systemaufrufe. Wie sich später herausstellte, war es auch ein Erbe des AIX-Kernel-Netzwerkstapels.
Im Allgemeinen hatten wir nie Probleme mit der Latenz, der Kern des Netzwerks war produktiv, alle Kabel wurden zu einem großen unzerstörbaren Kanal auf einer Schnittstelle zusammengebaut. Wir haben eine Problemumgehung vorgenommen: Wir haben das gesamte Netzwerk zwischen Anwendungsservern und der Datenbank in Gruppen auf verschiedenen Schnittstellen aufgeteilt. Infolgedessen kommunizierte jede Gruppe von Anwendungsservern über eine eigene separate Schnittstelle mit der Datenbank. Die maximale Leistung jeder Schnittstelle wurde geringfügig reduziert, aber insgesamt haben wir das Netzwerk auf 1 Million Pakete pro Sekunde in eine Richtung übertaktet.
Und das Prinzip "Die beste Anfrage ist die, die es nicht gibt" wurde dem Talmud für Entwickler hinzugefügt, damit dies beim Schreiben von Code berücksichtigt wird.
2017. Live zum Upgrade
Nun, die letzte Phase der Wiederherstellung unseres Systems ist 2017 vergangen. Alles, was blieb, war, bis zum Upgrade einiges zu leben, und es war notwendig, die SLA für nichts zu halten. Der Code wurde optimiert, aber wir haben festgestellt, dass die Prozesse umso langsamer funktionieren, je höher die Auslastung der Datenbank-CPU ist, obwohl die Auslastungsspanne 10 bis 20% betrug. Anfangs wurde geschätzt, dass 100% doppelt so viel sind wie 50%. Und wenn es eine Reserve von 10-20% gibt, sind dies 10-20%. Tatsächlich erhöhte sich bei einer Last über 67-80% die Dauer der Aufgaben nichtlinear, d.h. Amdahls Gesetz hat funktioniert. Das System hatte eine Parallelisierungsgrenze, und als diese überschritten wurde und eine zunehmende Anzahl von Prozessoren in die Arbeit einbezogen wurde, nahm die Leistung jedes einzelnen Prozessors ab.
Zu dieser Zeit verwendeten wir 125 physische oder 500 logische Prozessoren, wobei Multithreading auf AIX-Ebene in Betracht gezogen wurde. Was würden Sie vorschlagen? Upgrade? Noch vor dem Ende der Koordinierung war es notwendig, mehrere Monate durchzuhalten und das SLA nicht fallen zu lassen.
Irgendwann stellten sie fest, dass herkömmliche Prozessorauslastungsmetriken für uns keine Indikatoren sind - sie zeigen nicht den tatsächlichen Beginn der Verschlechterung. Für eine realistische Einschätzung des Systemzustands haben wir begonnen, die integrierte Metrik - das Ergebnis eines synthetischen Tests - als Metrik für die Leistung des Datenbankprozessors zu verwenden. Einmal pro Minute führten sie einen synthetischen Test durch, maßen seine Dauer und zeigten diese Metrik auf unseren Monitoren an. Und sie reagierten, wenn die Metrik über den deklarierten kritischen Punkt stieg. Wir haben die Last unserer Lastplaner etwas gehalten, damit sie im Bereich „maximales Drehmoment“ der Datenbank verbleibt.
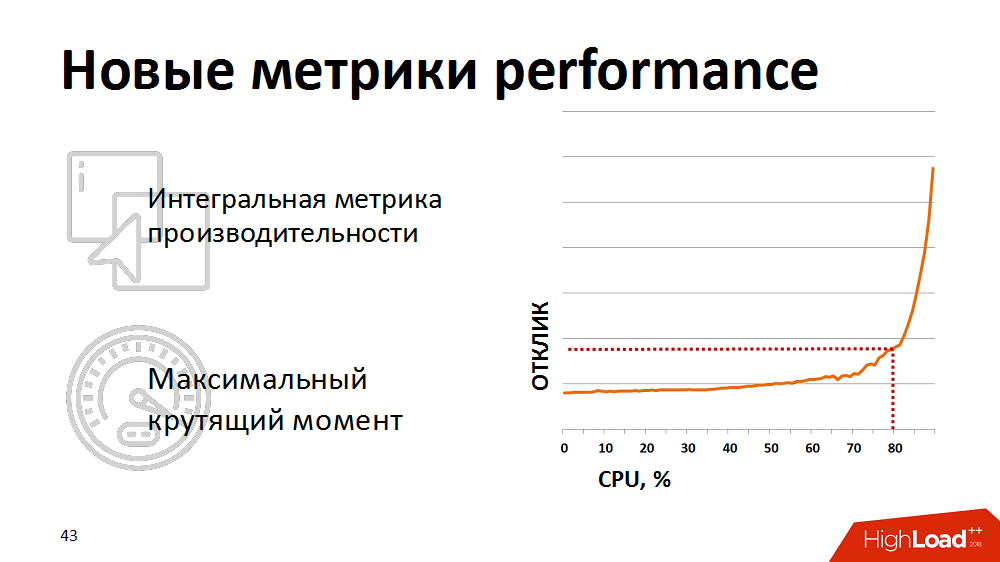
Die manuelle Steuerung war jedoch unwirksam und wir waren es leid, nachts aufzuwachen. Dann haben wir den Lastplaner umgeschrieben, damit er Feedback zu den aktuellen Leistungsmetriken erhält. Wenn die Metriken den gelben Schwellenwert überschritten (siehe Abbildung), wurde die Planung von Paketen mit niedriger Priorität eingefroren und nur geschäftskritische Prozesse erhielten Priorität. So konnten wir automatisch die Intensität der Belastung steuern und die Ressourcen effizient nutzen. Und das Interessanteste ist, dass wir, wenn wir das System in derselben Zone mit maximalem Drehmoment innerhalb von 80% der Last halten, die Gesamtzeit für die Ausführung von Geschäftsprozessen reduzieren konnten, weil Jeder Thread begann viel schneller zu arbeiten.
Ein paar Tipps für diejenigen, die mit hoch geladenem ERP arbeiten
- Es ist sehr wichtig, die Leistung von Systemen zu Beginn eines Projekts zu überwachen, insbesondere anhand ihrer eigenen Metriken.
- Stellen Sie eine lineare Zunahme der Last im Verhältnis zur Zunahme der Anzahl der Lasttreiber sicher (in unserem Fall waren dies Waren und Geschäfte).
- Beseitigen Sie nichtlineare Konstruktionen im Code und verwenden Sie das Caching, um identische Datenbankabfragen zu entfernen.
- Wenn Sie die Last von der Datenbank-CPU auf die Anwendungsserver-CPU übertragen müssen, können Sie Join-Anforderungen in einfache Beispiele aufteilen.
- Denken Sie bei allen Optimierungen daran, dass eine schnelle Anfrage gut und eine schnelle und häufige Anfrage manchmal schlecht ist.
- .
- , ; “ ” .
Highload , .
, , SAP #ITX5, #ITX5
SAP.