
Alles begann kitschig - seit einem Jahr zahlt meine Firma eine monatliche Gebühr für einen Dienst, der wusste, wie man eine Region mit Nummernschildern auf dem Foto findet. Diese Funktion wird verwendet, um Zahlen für einige Clients automatisch zu skizzieren.
Und eines schönen Tages eröffnete das Innenministerium der Ukraine den Zugang zum
Fahrzeugregister . Mit dem Nummernschild ist es nun möglich, einige Informationen über das Auto (Marke, Modell, Herstellungsjahr, Farbe usw.) zu überprüfen! Die langweilige Routine der linearen Programmierung ist vor einer neuen Aufgabe verblasst - Zahlen über die gesamte Fotobasis zu lesen und diese Daten mit den vom Benutzer angegebenen zu validieren. Sie selbst wissen, wie es passiert, wenn die Augen aufleuchten - der Anruf wurde angenommen, alle anderen Aufgaben wurden für eine Weile langweilig und eintönig ... Wir machten uns an die Arbeit und erzielten gute Ergebnisse, die wir tatsächlich mit der Community teilen wollten.
Als Referenz: Auf der Website AUTO.RIA.com werden pro Tag etwa 100.000 Fotos hinzugefügt.
Datasaentisten sind seit langem bekannt und in der Lage, solche Probleme zu lösen. Daher haben
dimabendera und
ich diesen Artikel speziell für Programmierer geschrieben. Wenn Sie keine Angst vor dem Ausdruck "Faltungsnetzwerke" haben und wissen, wie man "Hallo Welt" in Python schreibt, sind Sie unter Katze willkommen ...
Wer erkennt noch
Vor einem Jahr habe ich diesen Markt studiert und es stellte sich heraus, dass nicht viele Dienste und Software mit exUSSR-Ländernummern arbeiten können. Nachfolgend finden Sie eine Liste der Unternehmen, mit denen wir zusammengearbeitet haben:
- Es gibt eine Open Source und kommerzielle Version. Die Opensource-Version zeigte eine sehr niedrige Erkennungsrate, außerdem erforderte sie spezifische Abhängigkeiten für ihre Montage und ihren Betrieb (es hat uns nicht besonders gefallen). Die kommerzielle Version bzw. der kommerzielle Service funktioniert gut. Kann mit russischen und ukrainischen Zahlen arbeiten. Die Preise sind moderat - 49 $ / 50.000 Anerkennungen pro Monat. Online-Demo von OpenALPR
- Wir nutzen diesen Service seit ungefähr einem Jahr. Gute Qualität. Er findet das Gebiet mit der Nummer sehr gut. Der Dienst weiß nicht, wie er mit ukrainischen und europäischen Nummern arbeiten soll. Bemerkenswert ist die gute Arbeit mit Bildern von geringer Qualität (im Schnee, Foto mit niedriger Auflösung, ...). Der Preis des Dienstes ist ebenfalls akzeptabel, aber sie zögern, kleine Mengen anzunehmen.
Es gibt viele kommerzielle Systeme mit geschlossener Software, aber wir haben keine gute OpenSource-Implementierung gefunden. In der Tat ist dies sehr seltsam, da die Open-Source-Tools, die der Lösung dieses Problems zugrunde liegen, schon lange existieren.
Welche Werkzeuge werden benötigt, um Zahlen zu erkennen?
Das Finden von Objekten in einem Bild oder in einem Videostream ist eine Aufgabe aus dem Bereich der Bildverarbeitung, die durch verschiedene Ansätze gelöst wird, meist jedoch mit Hilfe sogenannter Faltungs-Neuronaler Netze. Wir müssen nicht nur den Bereich auf dem Foto finden, in dem sich das gewünschte Objekt befindet, sondern auch alle seine Punkte von anderen Objekten oder dem Hintergrund trennen. Diese Art von Aufgabe wird als "Instanzsegmentierung" bezeichnet. Die folgende Abbildung zeigt verschiedene Arten von Computer Vision-Aufgaben.
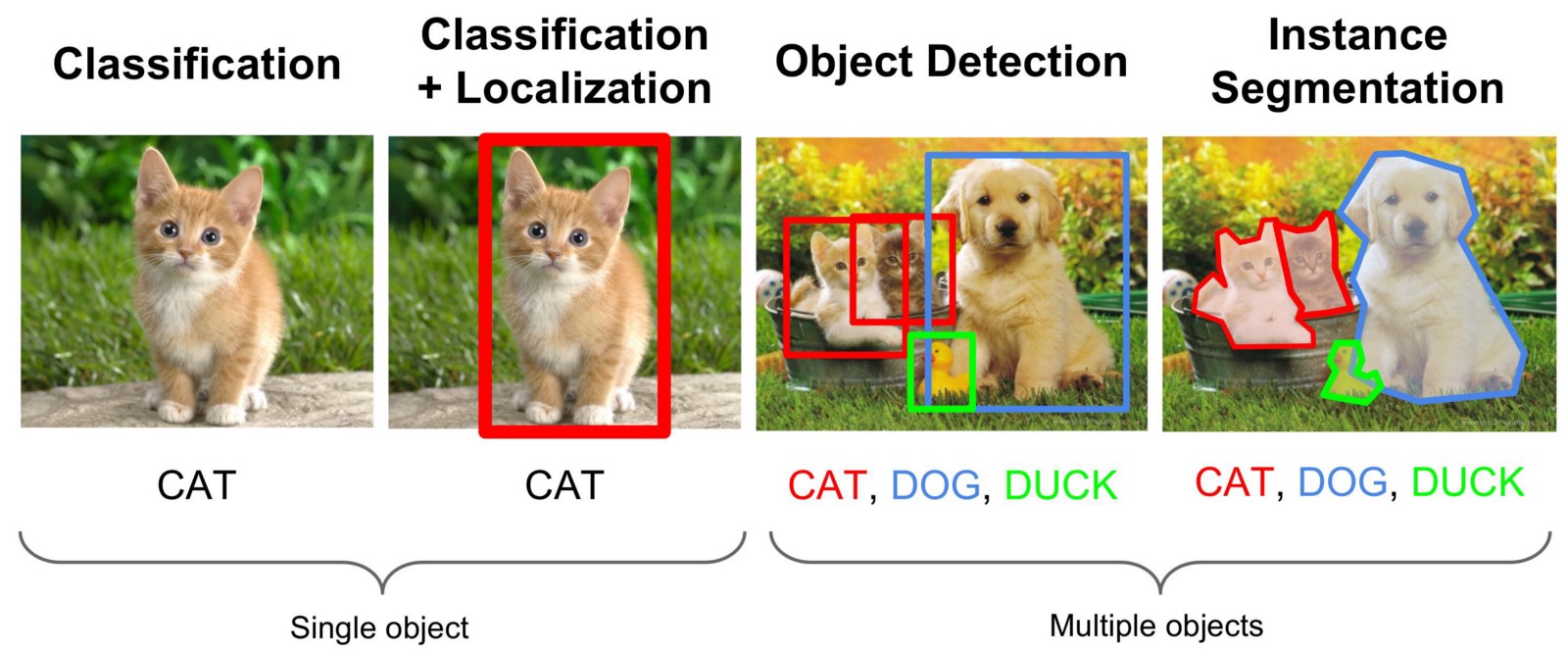
Ich werde nicht viel Theorie darüber schreiben, wie das Faltungsnetzwerk funktioniert, diese Informationen reichen im Netzwerk aus und berichten auf Youtube.
Aus modernen Architekturen von Faltungsarrays für Segmentierungsaufgaben werden häufig Folgendes verwendet:
U-Net oder
Mask R-CNN . Wir haben uns für Mask R-CNN entschieden.
Das zweite Werkzeug, das wir benötigen, ist eine Texterkennungsbibliothek, die mit verschiedenen Sprachen arbeiten kann und die leicht an die Besonderheiten der zu erkennenden Texte angepasst werden kann. Hier ist die Auswahl nicht so groß, am weitesten fortgeschritten ist
Tesseract von Google.
Es gibt auch eine Reihe weniger „globaler“ Tools, mit denen wir den Bereich mit dem Nummernschild normalisieren müssen (bringen Sie es so, dass eine Texterkennung möglich ist). Normalerweise wird opencv für solche Konvertierungen verwendet.
Es wird auch möglich sein, das Land und den Typ zu bestimmen, zu dem das Kennzeichen gehört, so dass wir bei der Nachbearbeitung eine für dieses Land und diese Art von Nummer spezifische Verfeinerungsvorlage anwenden. Zum Beispiel besteht das ukrainische Nummernschild, das ab 2015 in Blau und Gelb gehalten ist, aus der Vorlage „zwei Buchstaben vier Zahlen zwei Buchstaben“.

Darüber hinaus können Sie durch Statistiken über die Häufigkeit von „Besprechungen“ in den Kennzeichen einer bestimmten Kombination von Buchstaben oder Zahlen die Qualität der Nachbearbeitung in „kontroversen“ Situationen verbessern. ""
Nomeroff net
Aus dem Titel des Artikels geht hervor, dass wir alle das Projekt
Nomeroff Net implementiert und benannt
haben . Jetzt arbeitet ein Teil des Codes für dieses Projekt bereits in der Produktion auf
AUTO.RIA.com . Natürlich ist es noch weit von kommerziellen Analoga entfernt, alles funktioniert nur für ukrainische Zahlen. Darüber hinaus wird eine akzeptable Geschwindigkeit nur mit der Unterstützung des Tensorflusses des GPU-Moduls erreicht! Ohne GPU kannst du es auch versuchen, aber nicht auf dem Raspberry Pi :).
Alle Materialien für unser Projekt: markierte Datensätze und trainierte Modelle , die wir mit Genehmigung von RIA.com unter einer Creative Commons CC BY 4.0-Lizenz veröffentlicht haben
Was brauchen wir?
- Python3
- opencv-python Version 3.4 oder höher
- Frische Maske RCNN , Tesseract
- Über den pip3-Paketmanager müssen Sie mehrere Module auf Python3 installieren. Diese werden in einer separaten Datei "require.txt" aufgeführt
Dmitry und ich laufen alle auf Fedora 28, ich bin sicher, dass alles auf jeder anderen Linux-Distribution installiert werden kann. Ich möchte diesen Beitrag nicht in Anweisungen zum Installieren und Konfigurieren von Tensorflow verwandeln, wenn Sie versuchen möchten und etwas nicht funktioniert - fragen Sie in den Kommentaren, ich werde antworten und es Ihnen sagen.
Um die Installation zu beschleunigen, planen wir, eine Docker-Datei zu erstellen - erwarten Sie in den nächsten Updates des Projekts.
Nomeroff Net "Hallo Welt"
Versuchen wir etwas zu erkennen. Wir klonen ein
Repository mit Code von
Github . Wir laden in den Modellordner
trainierte Modelle zum Suchen und Klassifizieren von Zahlen herunter und passen die Variablen leicht an die Position der Ordner an.
UPD: Dieser Code ist veraltet. Er funktioniert nur
in der 0.1.0-Verzweigung .
Die neuesten Beispiele finden Sie hier :
Alles ist zu erkennen:
import os import sys import json import matplotlib.image as mpimg
Online-Demo
Sie haben eine
einfache Demo für diejenigen entworfen, die dies alles nicht installieren und ausführen möchten :). Seien Sie nachsichtig und geduldig mit der Geschwindigkeit des Skripts.
Wenn Sie Beispiele für ukrainische Zahlen benötigen (um die Funktionsweise von Korrekturalgorithmen zu überprüfen), nehmen Sie ein Beispiel
aus diesem Ordner.Was weiter
Ich verstehe, dass das Thema sehr nisch ist und bei einer Vielzahl von Programmierern wahrscheinlich kein großes Interesse hervorruft. Außerdem sind Code und Modelle in Bezug auf Erkennungsqualität, Geschwindigkeit, Speicherverbrauch usw. immer noch recht „roh“. Es besteht jedoch weiterhin die Hoffnung, dass es Enthusiasten geben wird Wer sich für Schulungsmodelle für seine Bedürfnisse interessiert, sein Land, der Ihnen hilft und Ihnen sagt, wo es Probleme gibt, und zusammen mit uns das Projekt nicht schlechter macht als kommerzielle Kollegen.
Bekannte Probleme
- Das Projekt enthält keine Dokumentation, nur grundlegende Codebeispiele.
- Als Erkennungsmodul wird der universelle OCR-Tesseract ausgewählt, der viel lesen kann, aber viele Fehler macht. Bei der Erkennung ukrainischer Zahlen wird dort ein spezielles Korrektursystem geschrieben, das einige der Fehler bisher kompensiert, aber es besteht die Vermutung, dass hier noch viel mehr getan werden kann.
- "Quadratische" Zahlen (Nummernschilder mit einem Verhältnis von 1: 2) sind ziemlich selten und wir haben gerade erst begonnen, uns mit ihnen zu befassen, daher wird es mehr Fehler mit ihnen geben.
- Manchmal findet unser Modell anstelle eines Nummernschilds Verkehrsschilder mit dem Namen des Dorfes, ein Armaturenbrett in der Kabine und andere Artefakte.
- Bei schlechter Qualität der Zahl oder niedriger Auflösung wird ein Bereich von 4 Punkten nicht vollständig bestimmt
Ankündigung
Wenn es für jemanden interessant sein wird, werden wir im zweiten Teil darüber sprechen, wie und wie Sie Ihren Datensatz markieren und wie Sie Ihre Modelle trainieren, die für Ihre Inhalte besser geeignet sind (Ihr Land, Ihre Fotogröße). Wir werden auch darüber sprechen, wie Sie Ihren eigenen Klassifikator erstellen. So können Sie beispielsweise feststellen, ob die Nummer auf dem Foto skizziert ist.
Einige Beispiele im Jupyter-Notizbuch:
Nützliche Links