Wurden Sie jemals gebeten, die Menge von etwas basierend auf den Daten in der Datenbank für den letzten Monat zu berechnen, das Ergebnis nach einigen Werten zu gruppieren und alles nach Tag / Stunde aufzuschlüsseln?
Wenn ja - dann stellen Sie sich schon vor, dass Sie so etwas schreiben müssen, nur schlimmer
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
Von Zeit zu Zeit tauchen eine Vielzahl solcher Anfragen auf, und wenn Sie es einmal aushalten und helfen, werden leider in Zukunft Rechtsmittel eingelegt.
Solche Anforderungen sind jedoch insofern schlecht, als sie zur Laufzeit gut Systemressourcen verbrauchen und es so viele Daten geben kann, dass selbst ein Replikat für solche Anforderungen schade ist (und seine Zeit).
Aber was ist, wenn ich sage, dass Sie direkt in PostgreSQL eine Ansicht erstellen können, die im laufenden Betrieb nur neue eingehende Daten in einer direkt ähnlichen Abfrage wie oben berücksichtigt?
Also - es kann die Erweiterung PipelineDB machen
Demo von ihrer Website, wie es funktioniert PipelineDB war zuvor ein separates Projekt, ist jetzt jedoch als Erweiterung für PG 10.1 und höher verfügbar.
Und obwohl die angebotenen Möglichkeiten schon lange in anderen Produkten bestehen, die speziell für die Erfassung von Echtzeitmetriken entwickelt wurden, hat PipelineDB ein bedeutendes Plus: eine niedrigere Einstiegsschwelle für Entwickler, die SQL bereits kennen.
Vielleicht ist es für einige nicht wesentlich. Persönlich bin ich nicht zu faul, alles auszuprobieren, was zur Lösung eines bestimmten Problems geeignet erscheint, aber ich werde nicht sofort eine neue Lösung für alle Fälle verwenden. Daher möchte ich in diesem Artikel nicht unbedingt alles löschen und PipelineDB sofort installieren. Dies ist nur eine Übersicht über die Hauptfunktionen das Ding kam mir neugierig vor.
Im Allgemeinen verfügen sie über eine gute Dokumentation, aber ich möchte meine Erfahrungen darüber teilen, wie Sie dieses Geschäft in der Praxis ausprobieren und die Ergebnisse an Grafana weitergeben können.
Um den lokalen Computer nicht zu verschmutzen, stelle ich alles im Docker bereit.
Verwendete Bilder:
postgres:latest ,
grafana/grafanaInstallieren Sie PipelineDB auf Postgres
Führen Sie auf einer Maschine mit Postgres nacheinander Folgendes aus:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Öffnen
postgresql.conf Datei postgresql.conf in einem beliebigen Editor - Suchen Sie den Schlüssel
shared_preload_libraries , kommentieren Sie ihn aus und legen Sie den Wert für pipelinedb - Schlüssel
max_worker_processes auf 128 gesetzt (Empfehlungsdocks) - Starten Sie den Server neu
Erstellen eines Streams und einer Ansicht in PipelineDB
Nach dem Neustart pg - beobachten Sie die Protokolle, damit es so etwas gibt - Die Datenbank, in der wir arbeiten werden:
CREATE DATABASE testpipe; - Erstellen einer Erweiterung:
CREATE EXTENSION pipelinedb; - Das Interessanteste ist jetzt, einen Stream zu erstellen. Darin müssen Sie Daten für die weitere Verarbeitung hinzufügen:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
Tatsächlich ist es dem Erstellen einer normalen Tabelle sehr ähnlich. Sie können nicht einfach Daten aus diesem Stream mit einer einfachen select - Sie benötigen eine Ansicht - eigentlich wie man es erstellt:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Sie werden als kontinuierliche Ansichten bezeichnet und standardmäßig materialisiert, d. H. unter Wahrung des Staates.
Die WITH übergibt zusätzliche Parameter.
In meinem Fall bedeutet ttl = '3 month' , dass Sie nur Daten für die letzten 3 Monate speichern und das Datum / die Uhrzeit aus Spalte M entnehmen müssen M Der Hintergrund- reaper Prozess reaper nach veralteten Daten und löscht sie.
Für diejenigen, die sich nicht auskennen, gibt die Minutenfunktion ein Datum / eine Uhrzeit ohne Sekunden zurück. Somit haben alle Ereignisse, die in einer Minute aufgetreten sind, aufgrund der Aggregation dieselbe Zeit. - Eine solche Ansicht ist fast eine Tabelle, da der Index nach Datum für die Stichprobe nützlich ist, wenn viele Daten gespeichert sind
create index on viewflow (m desc, action);
PipelineDB verwenden
Denken Sie daran: Fügen Sie Daten in den Stream ein und lesen Sie sie aus der abonnierten Ansicht
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
Ich führe die Anfrage manuell aus Zuerst beobachte ich, wie sich die Daten in der 46. Minute ändern
Sobald der 47. kommt, hört der vorherige auf zu aktualisieren und die aktuelle Minute beginnt zu ticken.
Wenn Sie auf den Abfrageplan achten, können Sie die Originaltabelle mit Daten sehen
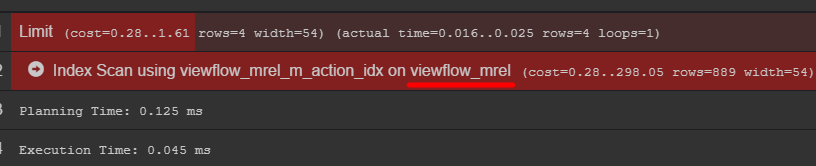
Ich empfehle, dorthin zu gehen und herauszufinden, wie Ihre Daten tatsächlich gespeichert sind
C # Ereignisgenerator using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Fazit in Grafana
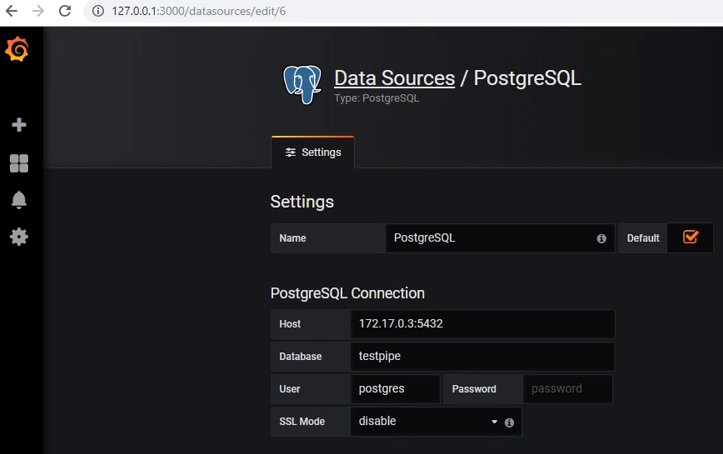
Um Daten von Postgres zu erhalten, müssen Sie die entsprechende Datenquelle hinzufügen:
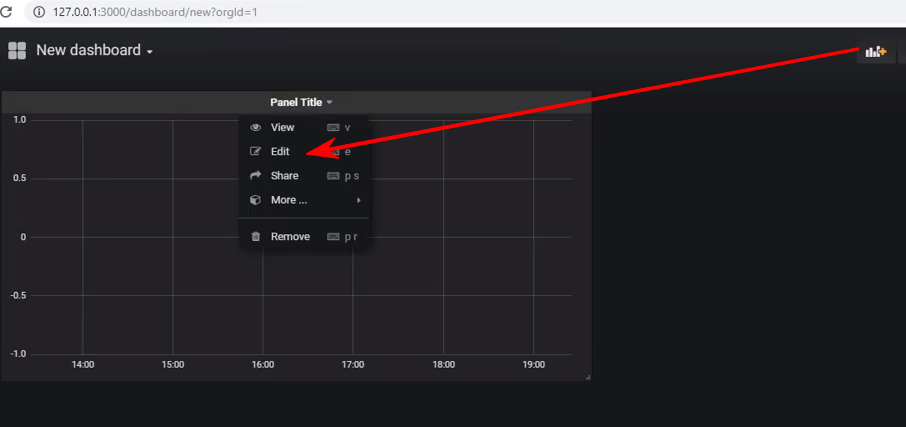
Erstellen Sie ein neues Dashboard und fügen Sie ein Bedienfeld vom Typ Diagramm hinzu. Anschließend müssen Sie mit der Bearbeitung des Bedienfelds beginnen:
Weiter - Wählen Sie eine Datenquelle aus, wechseln Sie in den SQL-Abfrageschreibmodus und geben Sie Folgendes ein:
select m as time,
Und dann erhalten Sie natürlich einen normalen Zeitplan, wenn Sie den Ereignisgenerator gestartet haben
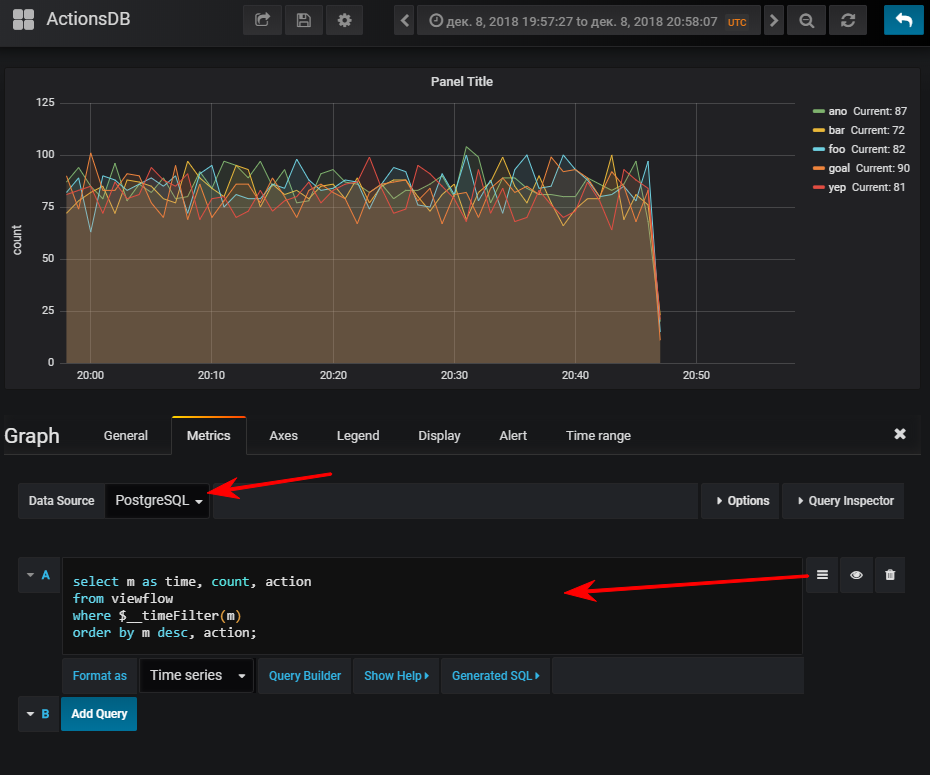
Zu Ihrer Information: Ein Index kann sehr wichtig sein. Obwohl seine Verwendung vom Volumen der resultierenden Tabelle abhängt. Wenn Sie vorhaben, eine kleine Anzahl von Zeilen in kurzer Zeit zu speichern, kann sich sehr leicht herausstellen, dass der seq-Scan billiger ist und der Index nur zusätzliche Zeilen hinzufügt. Laden beim Aktualisieren von Werten
Ein Stream kann mehrere Ansichten abonnieren.
Angenommen, ich möchte sehen, wie viele API-Methoden von Perzentilen ausgeführt werden
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
Ich mache den gleichen Trick mit Grafana und bekomme: Insgesamt
Im Allgemeinen funktioniert das Ding, es hat sich gut verhalten, ohne sich zu beschweren. Obwohl unter dem Docker, war das Herunterladen der Demo-Datenbank im Archiv (2,3 GB) etwas langwierig.
Ich möchte darauf hinweisen, dass ich keine Stresstests durchgeführt habe.
Offizielle DokumentationKann interessant sein