
Am 6. und 7. Dezember fand in Moskau die fünfte Heisenbag-Konferenz statt.
Ihr Slogan lautet „Testen. Nicht nur für Tester! “Und während zwei Jahren regelmäßiger Besuche bei den Heisenbags konnte ich (ehemals Java-Entwickler, jetzt technischer Leiter in einem kleinen Unternehmen, das noch nie in der Qualitätssicherung gearbeitet hatte) viel in Tests lernen und viel in unserem Team implementieren. Ich möchte einen subjektiven Rückblick auf die Berichte geben, an die ich mich dieses Mal erinnere.
Haftungsausschluss. Dies ist natürlich nur ein kleiner Teil (8 von 30) der Berichte, die aufgrund meiner persönlichen Vorlieben ausgewählt wurden. Fast alle diese Berichte beziehen sich irgendwie auf Java, und es gibt keinen einzigen über Front-End- und Mobile-Entwicklung. An einigen Stellen werde ich mir eine Polemik mit dem Sprecher erlauben. Wenn Sie an einer vollständigeren und neutraleren Überprüfung interessiert sind, sollte diese traditionell
im Blog des Veranstalters erscheinen. Aber vielleicht ist es für jemanden interessant, sich über die Berichte zu informieren, zu denen er nicht gehen konnte.
Die Fotos im Artikel stammen vom offiziellen Twitter der Konferenz.Baruch Sadogursky. Wir haben DevOps. Lassen Sie uns alle Tester feuern
 (Auf dem Foto - der Hype, als Baruch das Buch Liquid Software verteilte )
(Auf dem Foto - der Hype, als Baruch das Buch Liquid Software verteilte )Baruch Sadogursky, der an Java beteiligt ist und an Konferenzen der JUGRU-Gruppe teilnimmt, muss nicht vorgestellt werden. Er sprach jedoch zum ersten Mal in Heisenbug.
Kurz gesagt - es war ein Überprüfungsbericht über die Hauptideen von DevOps. Das Bedürfnis des Publikums nach solchen Berichten bleibt bestehen, denn auf die Frage "Geben Sie dem Publikum die Definition von DevOps" antworten die Leute immer noch zuallererst: "Dies ist eine solche Person ..."
Aber auch diejenigen, die bereits etwas zu diesem Thema gelernt haben, werden sehr interessant sein, etwas über die Studien des DORA-Verbandes
devops-research.com zu erfahren, der Prozentsätze verschiedener Arten von manueller Arbeit in Teams mit unterschiedlicher Leistung erhalten hat. Und über die Kurve, die die Liefergeschwindigkeit und -qualität verbindet (irgendwann nimmt die Geschwindigkeit ab, weil wir Zeit brauchen, um "besser zu testen", aber während sich das Team entwickelt, wird die Korrelation direkt):
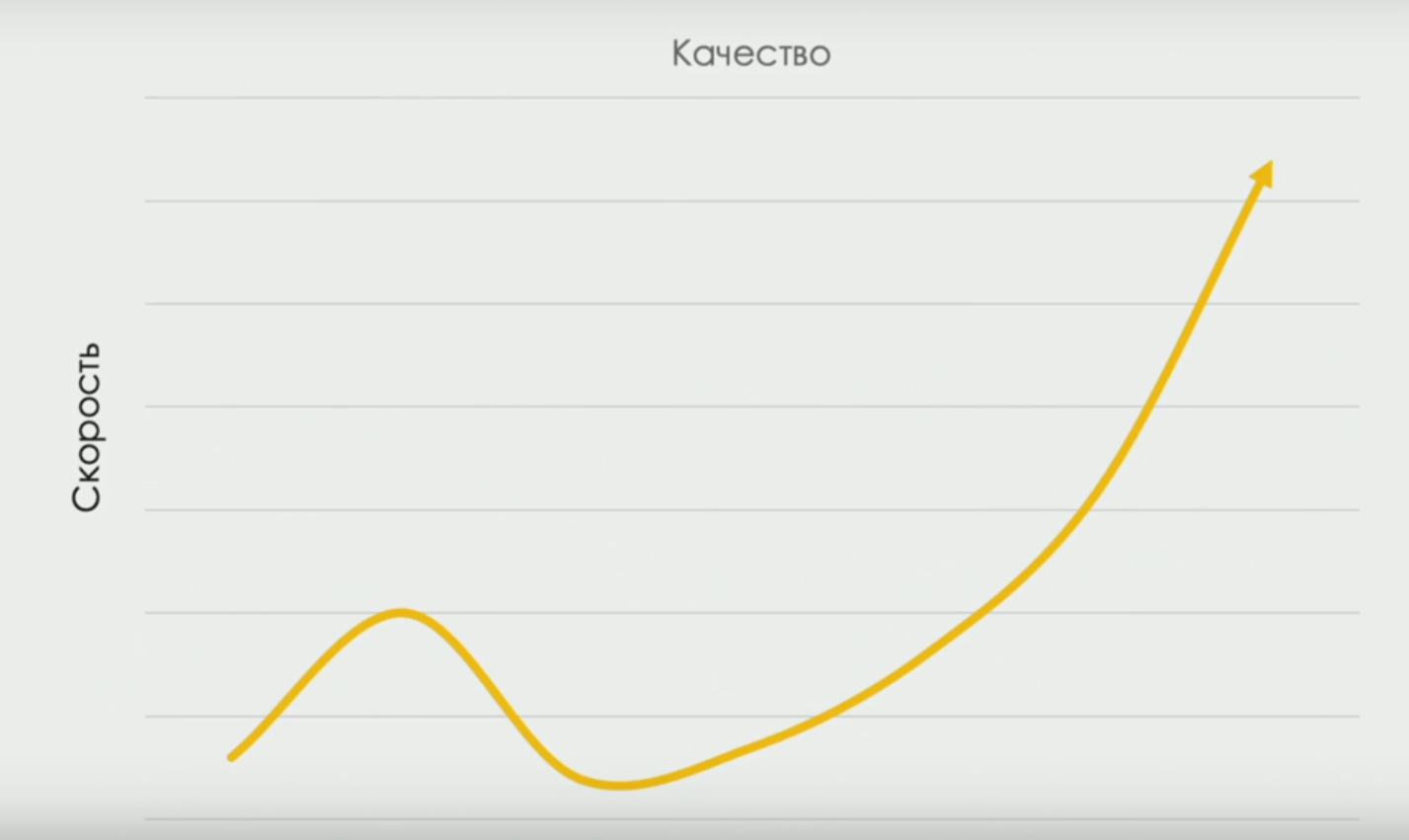
Obwohl der Titel des Berichts provokativ war und im Zeitplan der Bericht mit der Kategorie „wird brennen“ gekennzeichnet war, war sein Inhalt meiner Meinung nach ziemlich Mainstream. Es ging natürlich nicht um die Entlassung von Testern unter den Bedingungen der Devops-Transformation, sondern um eine Änderung der Art der Arbeit von Testern.
Alan Page und Nikolai Alimenkov haben vor einem Jahr viel über diese Dinge gesprochen. Sowohl die sich ändernden Rollen als auch die „horizontale“ Entwicklung von T-förmigen Fähigkeiten wurden vor einem Jahr am Runden Tisch diskutiert, „
was ein Tester 2018 wissen sollte “.
„Wenn du dich nicht ändern willst, gibt es natürlich Arbeit für dich, wenn auch nicht so interessant. Bisher gibt es noch Arbeit für diejenigen, die Systeme unterstützen möchten, die in den 70er Jahren in COBOL geschrieben wurden “, sagte Baruch.
Artyom Eroshenko. Müssen Sie ein Projekt umgestalten? Haben Sie eine Idee!

Artyom ist den Heisenbag-Teilnehmern mit Berichten über das Allure-Berichtssystem vertraut (
hier ist beispielsweise sein Bericht über Allure-Möglichkeiten, der 2018 aus dem vorherigen Heisenbug in St. Petersburg hervorgegangen ist). Allure selbst wurde im Rahmen von Projekten mit Tausenden, Zehntausenden und sogar mehr als Hunderttausenden von Tests geboren und soll die Interaktion zwischen Entwicklern und Testern vereinfachen. Es kann Tests mit externen Ressourcen wie Ticketing-Systemen und Commits im Versionskontrollsystem verknüpfen. Während die Anzahl der Tests in unserem Mikroteam nur um zehn stieg, haben wir die Standardmittel vollständig bewältigt. Als die Anzahl der Tests in einem der Produkte 700 erreichte und die Gesamtaufgabe darin bestand, qualitativ hochwertige Berichte für Kunden zu erstellen, begann ich, mich Allure zuzuwenden.
In diesem Bericht ging es jedoch nicht um Allure, sondern auch um ihn.
Artyom überzeugte die Öffentlichkeit, dass das Schreiben von Plugins für IntelliJ IDEA eine einfache und faszinierende Aktivität ist. Warum sollte dies erforderlich sein? Automatisierung der Massencode-Änderung. Zum Beispiel, um eine große Anzahl von Quellcodes von JUnit4 nach JUnit5 zu übersetzen. Oder von der Verwendung von Allure 1 bis Allure 2. Oder um die Kennzeichnung von Tests mit der Kommunikation mit dem Ticking-System zu automatisieren.
Diejenigen, die mit IDEA arbeiten, wissen, welche Tricks es mit Code machen kann (z. B. automatisch Code mit for-Schleifen in Code mit Java Streams übersetzen und umgekehrt oder Java sofort in Kotlin übersetzen). Umso interessanter war es zu sehen, wie der Schleier der Geheimhaltung über die Code-Transformationen in IDEA geöffnet wird. Wir sind eingeladen, daran teilzunehmen und unsere eigenen Plugins für unsere individuellen Bedürfnisse zu erstellen. Wenn ich das nächste Mal etwas mit einer großen Codebasis tun muss, werde ich mich an diesen Bericht erinnern und sehen, wie er mithilfe eines generischen Plug-Ins in IDEA automatisiert werden kann.
Kirill Merkushev. Java- und Reaktorprojekt - was ist mit Tests?

Dieser Bericht könnte meines Erachtens auf den Joker- oder JPoint Java-Konferenzen stattgefunden haben. Kirill sprach darüber, wie er das
projectreactor.io- Framework in einer Microservice-Architektur mit einem einzelnen Ereignisprotokoll (Kafka) verwendet, ein wenig über die Essenz der Codierung in "reaktiven Streams", einschließlich der Frage, wie Anwendungen, die dieses Framework verwenden, debuggt und getestet werden können.
Das Leben drängt unser Team auch dazu, Architektur mit einem einzigen Ereignisprotokoll zu verwenden, und wir schauen uns auch Kafka an. Für die Verarbeitung von Streaming-Ereignissen experimentieren wir jedoch mit der Kafka Streams-API (bei der meines Erachtens mehr Dinge wie die Stateful-Verarbeitung für den Entwickler sofort transparent implementiert werden) und nicht mit Reactor. Wie immer bei neuen Technologien sind die "Rechen" und "Fallstricke" jedoch nicht im Voraus bekannt. Daher war es wichtig, die Geschichte eines Spezialisten zu hören, der bereits mit Technologie arbeitet.
Leonid Rudenko. Verwalten eines Selenoidclusters mit Terraform

Wenn der vorherige Bericht an eine JPoint-Konferenz erinnerte, dann handelt dieser sicherlich von
DevOops . Leonid sprach darüber, wie man die Terraform-Spezifikationen verwendet, um einen Selenoid-Cluster zu erstellen und zu konfigurieren. Über das, was Selenoid selbst war, gab
es einen Bericht über den Heisenbug im letzten Jahr - es ist ein reichhaltiges verteiltes System, das als elastischer Dienst funktioniert und es Ihnen ermöglicht, eine große Anzahl von Selenium-Tests in verschiedenen Browsern durchzuführen. Wie bei jedem System, das die Bereitstellung auf mehreren Computern erfordert, ist die manuelle Installation von Selenoid schwierig. Hier helfen moderne Configuration-as-Code-Systeme.
Leonid gab einen ziemlich detaillierten Überblick über die Funktionen von Terraform - ein System, das den meisten Zuschauern wahrscheinlich unbekannt war, aber der DevOps-Automatisierung bereits bekannt war (zum Beispiel gab es auf der Devoops-2018-Konferenz
einen ausgezeichneten Bericht von Anton Babenko über Best Practices für die Erstellung und Pflege von Code auf Terraform). Außerdem wurde gezeigt, wie Terraform-Skripte verwendet werden, um die Parameter von Docker-Containern mit Selenoid für jede der Maschinen im Cluster und die Parameter der virtuellen Cluster-Maschinen selbst zu beschreiben.
Obwohl der von Leonid betrachtete spezielle Fall sicherlich die Aufgabe des Einsatzes von Selenoid erleichtern kann, stimme ich dem Redner nicht in allen Punkten zu. Im Wesentlichen wird Terraform für zwei verschiedene Aufgaben verwendet: Erstellen und Konfigurieren von Ressourcen. Dies führt dazu, dass Leonid gezwungen ist, Terraform einmal auszuführen, um virtuelle Maschinen zu erstellen, und erneut, damit jede der virtuellen Maschinen Docker-Container auf ihnen erstellt. Meiner Meinung nach löst Terraform, das das Problem der Ressourcenerstellung gut löst, das Konfigurationsproblem nicht sehr gut. Es wäre möglich, die Multiplikation von Terraform-Projekten und deren wiederholtes Starten mit speziellen Konfigurationssystemen, beispielsweise Ansible, oder anderen Lösungen zu vermeiden.
Im Allgemeinen ist dieser Bericht als "Bildungsprogramm" für Tester im Bereich Infrastruktur als Kodex sehr nützlich.
Andrey Markelov. Eleganter Integrationstest des Microservice Zoos mit TestContainers und JUnit 5 am Beispiel der globalen SMS-Plattform

Und nochmal zu Microservices! In diesem Gespräch ging es darum, wie Tests ausgeführt werden, bei denen mehrere Dienste gleichzeitig gestartet und interagiert werden müssen. Als Grundlage der Lösung wurde JUnit5 mit seinem
Erweiterungssystem und dem bekannten (und ausgezeichneten) TestContainer-Framework vorgeschlagen (siehe beispielsweise den
letztjährigen Bericht von Sergey Egorov ).
Wenn Sie etwas in Java schreiben und immer noch nicht wissen, was TestContainer sind, empfehle ich Ihnen dringend, es zu studieren. Mit TestContainers können mithilfe der Docker-Technologie direkt im Testcode echte Datenbanken und andere Dienste abgerufen, über das Netzwerk verbunden und als Ergebnis Integrationstests in der Umgebung durchgeführt werden, die zum Zeitpunkt des Starts und der Zerstörung der Tests unmittelbar danach erstellt wurde. Gleichzeitig funktioniert alles direkt über Java-Code, stellt eine Verbindung als Maven-Abhängigkeit her und erfordert keine Installation von Docker auf dem Computer / CI-Server des Entwicklers. Wir verwenden TestContainer seit über einem Jahr.
Andrei zeigte ein beeindruckendes Beispiel dafür, wie Sie die Konfiguration der Testumgebung für End-to-End-Tests mithilfe von JUnit5-Erweiterungen, benutzerdefinierten Anmerkungen und TestContainern angeben können. Schreiben Sie beispielsweise Anmerkungen über Ihren Test (bedingter Code).
@Billing @Messaging
wir können relativ gesehen schreiben
@Test void systemIsDoingRightThings(BillingService b, MessagingService m) {...}
in die Parameter, über die Java-Schnittstellen geleitet werden, über die Sie mit realen Diensten kommunizieren können, die in Containern (vom Testentwickler unbemerkt) ausgelöst werden.
Diese Beispiele sehen sehr elegant aus. Für mich als aktiven Benutzer von TestContainers und JUnit 5 sind sie verständlich und relativ einfach zu implementieren.
Im Allgemeinen bleibt bei diesem Ansatz die große Frage ungelöst, da die Art und Weise der Konfiguration der Test- und Produktionssysteme grundlegend anders ist.
Die Implementierung von Quick Releases in der Produktion ohne Angst, alles zu beschädigen, ist nur möglich, wenn während des End-to-End-Tests nicht nur das gesamte System getestet wurde, sondern auch die Art und Weise, es zu konfigurieren. Wenn wir das Systembereitstellungsskript während des Entwicklungs- und Testprozesses wiederholt ausführen würden, hätten wir keinen Zweifel daran, dass dieses Skript auch beim Start in der Produktion funktionieren würde. Die Rolle des Codes, der die Testumgebung im Beispiel von Andrey konfiguriert, wird durch Anmerkungen ausgeführt. Aber in der Produktion legen wir das System mit einem völlig anderen Code an - Ansible, Kubernetes, alles -, der in keiner Weise an solchen Systemtests beteiligt ist. Und dies schränkt diese Tests ein, die nicht vollständig durchgängig sind.
Andrey Glazkov. Testsysteme mit externen Abhängigkeiten: Probleme, Lösungen, Mountebank

Für diejenigen, für die das Thema dieses Berichts relevant ist, empfehle ich dringend, dass Sie sich auch eine
brillante Präsentation von Andrei Solntsev über einen prinzipiellen Ansatz zum Testen von Systemen ansehen, die von externen Diensten abhängen. Solntsev spricht sehr überzeugend über die Notwendigkeit, externe System-Mocks für umfassende Tests zu verwenden. Und Andrei Glazkov beschreibt in seinem Bericht eines der Systeme für eine solche Benetzung - Mountebank, geschrieben in NodeJS.
Sie können Mountebank als Server anheben und die Antworten auf Anfragen über das Netzwerk auf ähnliche Weise „trainieren“, wie wir beim Schreiben von Unit-Tests Schnittstellen-Mocks „trainieren“. Der einzige Unterschied besteht darin, dass es sich um einen Mock eines Netzwerkdienstes handelt. Ein merkwürdiger Fall bei der Verwendung von Mountebank ist die Möglichkeit, es als Proxy zu verwenden und einige Anfragen an ein echtes externes System zu senden.
Es sollte hier angemerkt werden, dass ich Java-Entwicklern (und Andrei, die im Diskussionsbereich zustimmten) empfehlen würde, sich auch mit der WireMock-Bibliothek zu befassen, die in Java erstellt wurde und im eingebetteten Modus ausgeführt werden kann, d. H. Direkt aus den Tests ohne Installation Entweder Dienste für den Computer des Entwicklers oder für den CI-Server (obwohl er auch als eigenständiger Server verwendet werden kann). WireMock unterstützt wie Mountebank den Proxy-Modus. Wir haben einige positive Erfahrungen mit WireMock gemacht.
Der Vorteil von Mountebank ist jedoch die Unterstützung von Protokollen niedrigerer Ebene (WireMock funktioniert nur für HTTP) und die Fähigkeit, in einem „Zoo“ verschiedener Technologien zu arbeiten (es gibt Bibliotheken für verschiedene Sprachen für Mountebank).
Kirill Tolkachev. Testen und Weinen mit dem Spring Boot Test

Und wieder Java, Microservices und JUnit 5. Kirill ist ein weiterer Sprecher der Joker- und JPoint-Konferenzen, die der Java-Community bekannt sind und zum ersten Mal bei Heisenbug sprachen.
Dieser Bericht ist eine modifizierte Version des letztjährigen
Spring Curse- Berichts mit Beispielen, die für JUnit5 und Spring Boot 2 geändert wurden. Verschiedene praktische Probleme im Zusammenhang mit der Konfiguration von Spring Boot-Tests in Komponenten- / Mikroservice-Tests werden eingehend untersucht. Ich war zum Beispiel beeindruckt von dem Beispiel, die leere
@SpringBootConfiguration StopConfiguration an der richtigen Stelle im
@SpringBootConfiguration StopConfiguration zu verwenden, um den Konfigurationsscanprozess zu stoppen, sowie von der Möglichkeit,
@MockBean und
@SpyBean anstelle von Mocks zu verwenden. Wie andere Berichte von Cyril und Evgeny Borisov ist dies Material, auf das im Rahmen der praktischen Anwendung des Frühlingsrahmens zurückgegriffen werden kann.
Andrey Karpov. Was können statische Analysatoren, was Programmierer und Tester nicht

Statische Code-Analyse ist eine gute Sache. Gemäß den Kanonen von Continuous Delivery sollte dies die allererste Phase der Lieferpipeline sein, in der Code mit Problemen herausgefiltert wird, die durch "Lesen" des Codes erkannt werden können. Die statische Analyse ist gut, weil sie schnell (viel schneller als Tests) und billig ist (es erfordert keine zusätzlichen Anstrengungen des Teams in Form von Schreibtests: Alle Prüfungen wurden bereits von den Autoren des Analysators geschrieben).
Andrey Karpov, einer der Gründer des PVS-Studio-Projekts (den Habr-Lesern mit seinem
Blog vertraut), erstellte einen Bericht über Beispiele dafür, welche Fehler in der Code-Analyse bekannter Produkte mit PVS-Studio gefunden wurden. PVS Studio selbst ist ein polyglottes Produkt und unterstützt C, C ++, C # und in jüngerer Zeit Java.
Trotz der Tatsache, dass die obigen Beispiele interessant waren und die Nützlichkeit ihrer statischen Analyse offensichtlich ist, hatte Andreys Bericht meiner Meinung nach Mängel.
Erstens wurde der Bericht ausschließlich auf der Grundlage des PVS-Studio-Produkts erstellt (für das laut Sprecher „der durchschnittliche Preis 10.000 USD beträgt“). Erwähnenswert ist jedoch, dass es in vielen Sprachen tatsächlich viele entwickelte statische OpenSource-Analysesysteme gibt. Allein in Java haben der kostenlose Checkstyle und SpotBugs (der Nachfolger des eingefrorenen FindBugs-Projekts) sowie der IntelliJ IDEA-Analysator, der separat von der IDE gestartet werden kann und einen Bericht erhalten hat, enorme Fortschritte erzielt.
Zweitens scheint es mir, wenn ich von statischer Analyse spreche, immer erwähnenswert zu sein, die grundlegenden Einschränkungen dieser Methode zu erwähnen. Nicht jeder hat an der Universität die Theorie der Algorithmen durchgearbeitet und ist beispielsweise mit dem „Problem des Herunterfahrens“ vertraut.
Und schließlich wurden die Probleme bei der Einführung statischer Analysen in die vorhandene Codebasis überhaupt nicht angesprochen, was viele immer noch daran hindert, Analysegeräte regelmäßig in Projekten einzusetzen. Zum Beispiel haben wir den Analysator in einem großen Legacy-Projekt ausgeführt und 100.500 Vorings gefunden. Es gibt keine Zeit und Mühe, sie direkt vor Ort zu reparieren, und eine massive Änderung des Codes ist ein Risiko. Was tun damit, wie kann die statische Analyse als Qualitätsgatter funktionieren? Dieses Problem wurde im Diskussionsbereich mit Andrei erörtert, dieses Problem wurde jedoch im Bericht selbst nicht berücksichtigt.
Generell wünsche ich Andrey und seinem Team viel Erfolg. Ihr Produkt ist interessant und die Idee, seine Nische in diesem Bereich zu besetzen, ist sehr mutig.
***.
Vielleicht sage ich nichts über die letzten Keynotes des ersten und zweiten Tages: Beide waren Copyright-Shows, die Sie nur ansehen müssen. Über sie zu sprechen ist wie in Worten nacherzählen, zum Beispiel eine Aufführung einer Rockband.
In meinem Bericht vor einem
Jahr habe ich bereits versucht, die allgemeine Atmosphäre der Konferenz zu vermitteln, und darüber gesprochen, was in den Diskussionsbereichen, beim Mittagessen und auf der Party passiert, damit ich mich nicht wiederhole.
Abschließend möchte ich den Organisatoren für eine weitere wunderschön abgehaltene Konferenz danken. Soweit ich weiß, hat das Interesse an der Konferenz die Erwartungen leicht übertroffen, es gab einige Überbuchungen und nicht einmal jeder hatte genug Souvenirs. Aber sicher hatte jeder wichtigere Dinge: interessante Berichte, Diskussionsraum, Essen und Trinken. Ich freue mich auf neue Treffen!