
In Fortsetzung unserer praktischen Artikel darüber, wie Sie das Leben in der täglichen Arbeit mit Kubernetes erleichtern können, sprechen wir über zwei Geschichten aus der Arbeitswelt: die Zuweisung einzelner Knoten für bestimmte Aufgaben und die Konfiguration von php-fpm (oder einem anderen Anwendungsserver) für schwere Lasten. Die hier beschriebenen Lösungen erheben nach wie vor keinen Anspruch auf Idealheit, sondern dienen als Ausgangspunkt für Ihre spezifischen Fälle und als Grundlage für Überlegungen. Fragen und Verbesserungen in den Kommentaren sind willkommen!
1. Die Zuordnung einzelner Knoten für bestimmte Aufgaben
Wir erstellen einen Kubernetes-Cluster auf virtuellen Servern, Clouds oder Bare-Metal-Servern. Wenn Sie die gesamte Systemsoftware und die Clientanwendungen auf denselben Knoten installieren, treten wahrscheinlich folgende Probleme auf:
- Die Client-Anwendung beginnt plötzlich, aus dem Speicher zu "lecken", obwohl ihre Grenzen sehr hoch sind.
- Komplexe einmalige Anfragen an Loghouse, Prometheus oder Ingress * führen zu OOM, wodurch die Clientanwendung darunter leidet.
- Ein Speicherverlust aufgrund eines Fehlers in der Systemsoftware beendet die Clientanwendung, obwohl die Komponenten möglicherweise nicht logisch miteinander verbunden sind.
* Unter anderem war es für ältere Versionen von Ingress relevant, als aufgrund der großen Anzahl von Websocket-Verbindungen und des ständigen Nachladens von Nginx „hängende Nginx-Prozesse“ auftraten, die sich auf Tausende beliefen und eine enorme Menge an Ressourcen verbrauchten.Der eigentliche Fall ist die Installation von Prometheus mit einer großen Anzahl von Metriken, bei denen beim Anzeigen des "schweren" Dashboards, in dem eine große Anzahl von Anwendungscontainern dargestellt wird, aus denen jeweils Diagramme erstellt werden, der Speicherverbrauch schnell auf ~ 15 GB anstieg. Infolgedessen könnte der OOM-Killer auf das Host-System "kommen" und andere Dienste beenden, was wiederum zu einem "unverständlichen Verhalten der Anwendungen im Cluster" führte. Und aufgrund der hohen CPU-Auslastung der Clientanwendung ist es einfach, eine instabile Verarbeitungszeit für Ingress-Abfragen zu erhalten ...
Die Lösung setzte sich schnell durch: Es war notwendig, einzelne Maschinen für verschiedene Aufgaben zuzuweisen. Wir haben 3 Haupttypen von Aufgabengruppen identifiziert:
- Fronten , an denen wir nur Ingresss platzieren, um sicherzustellen, dass keine anderen Dienste die Verarbeitungszeit von Anforderungen beeinflussen können;
- Systemknoten , auf denen wir VPNs , Loghouse , Prometheus , Dashboard, CoreDNS usw. Bereitstellen;
- Knoten für Anwendungen - in der Tat, wo Clientanwendungen eingeführt werden. Sie können auch für Umgebungen oder Funktionen zugewiesen werden: dev, prod, perf, ...
Lösung
Wie setzen wir das um? Sehr einfach: zwei native Kubernetes-Mechanismen. Der erste ist
nodeSelector , um den gewünschten Knoten auszuwählen, auf den die Anwendung gehen soll, basierend auf den auf jedem Knoten
installierten Beschriftungen.
kube-system-1 wir haben einen
kube-system-1 Knoten. Wir fügen ein zusätzliches Etikett hinzu:
$ kubectl label node kube-system-1 node-role/monitoring=
... und in
Deployment , das auf diesen Knoten ausgerollt werden soll, schreiben wir:
nodeSelector: node-role/monitoring: ""
Der zweite Mechanismus sind
Verschmutzungen und Toleranzen . Mit seiner Hilfe weisen wir ausdrücklich darauf hin, dass auf diesen Maschinen nur Container gestartet werden können, die diesen Makel tolerieren.
Zum Beispiel gibt es eine
kube-frontend-1 Maschine, auf der wir nur Ingress rollen werden. Fügen Sie diesem Knoten Taint hinzu:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... und bei
Deployment schaffen wir Toleranz:
tolerations: - effect: NoExecute key: node-role/frontend
Bei Kops können einzelne Instanzgruppen für die gleichen Anforderungen erstellt werden:
$ kops create ig --name cluster_name IG_NAME
... und Sie erhalten so etwas wie diese Instanzgruppenkonfiguration in kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
Daher fügen Knoten aus dieser Instanzgruppe automatisch eine zusätzliche Bezeichnung und einen zusätzlichen Makel hinzu.
2. Konfigurieren von php-fpm für schwere Lasten
Es gibt eine Vielzahl von Servern, auf denen Webanwendungen ausgeführt werden: php-fpm, gunicorn und dergleichen. Ihre Verwendung in Kubernetes bedeutet, dass Sie immer über verschiedene Dinge nachdenken sollten:
- Es ist ungefähr zu verstehen, wie viele Arbeiter wir bereit sind, in php-fpm in jedem Container zuzuweisen. Zum Beispiel können wir 10 Mitarbeiter für die Verarbeitung eingehender Anforderungen zuweisen, weniger Ressourcen für Pods zuweisen und anhand der Anzahl der Pods skalieren - dies ist eine gute Vorgehensweise. Ein anderes Beispiel ist, 500 Arbeiter für jeden Pod zuzuweisen und 2-3 solcher Pods in Produktion zu haben ... aber das ist eine ziemlich schlechte Idee.
- Lebendigkeits- / Bereitschaftstests sind erforderlich, um den korrekten Betrieb jedes Pods zu überprüfen, und falls der Pod aufgrund von Netzwerkproblemen oder aufgrund des Datenbankzugriffs „ hängen bleibt“ (möglicherweise gibt es eine Ihrer Optionen und Gründe). In solchen Situationen müssen Sie den problematischen Pod neu erstellen.
- Es ist wichtig, Anforderungen explizit zu registrieren und Ressourcen für jeden Container zu begrenzen, damit die Anwendung nicht "fließt" und nicht beginnt, alle Dienste auf diesem Server zu beschädigen.
Lösungen
Leider
gibt es keine Silberkugel , mit der Sie sofort verstehen können, wie viele Ressourcen (CPU, RAM) eine Anwendung möglicherweise benötigt. Eine mögliche Option besteht darin, den Ressourcenverbrauch zu beobachten und jedes Mal die optimalen Werte auszuwählen. Um ungerechtfertigte OOM-Kill'ov- und Drosselungs-CPUs zu vermeiden, die den Service stark beeinträchtigen, können Sie Folgendes anbieten:
- Fügen Sie die richtigen Lebendigkeits- / Bereitschaftstests hinzu, damit wir sicher sein können, dass dieser Container ordnungsgemäß funktioniert. Höchstwahrscheinlich handelt es sich um eine Serviceseite, die die Verfügbarkeit aller Infrastrukturelemente überprüft (damit die Anwendung im Pod funktioniert) und einen 200-OK-Antwortcode zurückgibt.
- Wählen Sie die Anzahl der Mitarbeiter, die Anfragen bearbeiten, richtig aus und verteilen Sie sie richtig.
Zum Beispiel haben wir 10 Pods, die aus zwei Containern bestehen: nginx (zum Senden von Statik- und Proxy-Anforderungen an das Backend) und php-fpm (eigentlich das Backend, das dynamische Seiten verarbeitet). Der Php-fpm-Pool ist für eine statische Anzahl von Workern konfiguriert (10). Somit können wir in einer Zeiteinheit 100 aktive Anfragen an Backends verarbeiten. Lassen Sie jede Anfrage von PHP in 1 Sekunde verarbeitet werden.
Was passiert, wenn 1 weitere Anfrage in einem bestimmten Pod eintrifft, in dem derzeit 10 Anfragen aktiv verarbeitet werden? PHP kann es nicht verarbeiten und Ingress sendet es, um es erneut mit dem nächsten Pod zu versuchen, wenn es sich um eine GET-Anforderung handelt. Wenn eine POST-Anforderung aufgetreten ist, wird ein Fehler zurückgegeben.
Und wenn wir berücksichtigen, dass wir während der Verarbeitung aller 10 Anfragen einen Scheck von kubelet (Liveness Probe) erhalten, endet dieser mit einem Fehler und Kubernetes beginnt zu glauben, dass etwas mit diesem Container nicht stimmt, und beendet ihn. In diesem Fall enden alle Anforderungen, die im Moment verarbeitet wurden, mit einem Fehler (!). Zum Zeitpunkt des Neustarts des Containers gerät er aus dem Gleichgewicht, was zu einer Erhöhung der Anforderungen für alle anderen Backends führt.
Klar
Angenommen, wir haben 2 Pods, für die jeweils 10 PHP-Fpm-Worker konfiguriert sind. Hier ist ein Diagramm, das Informationen während der "Ausfallzeit" anzeigt, d. H. Wenn der einzige, der php-fpm anfordert, der php-fpm-Exporteur ist (wir haben jeweils einen aktiven Mitarbeiter):
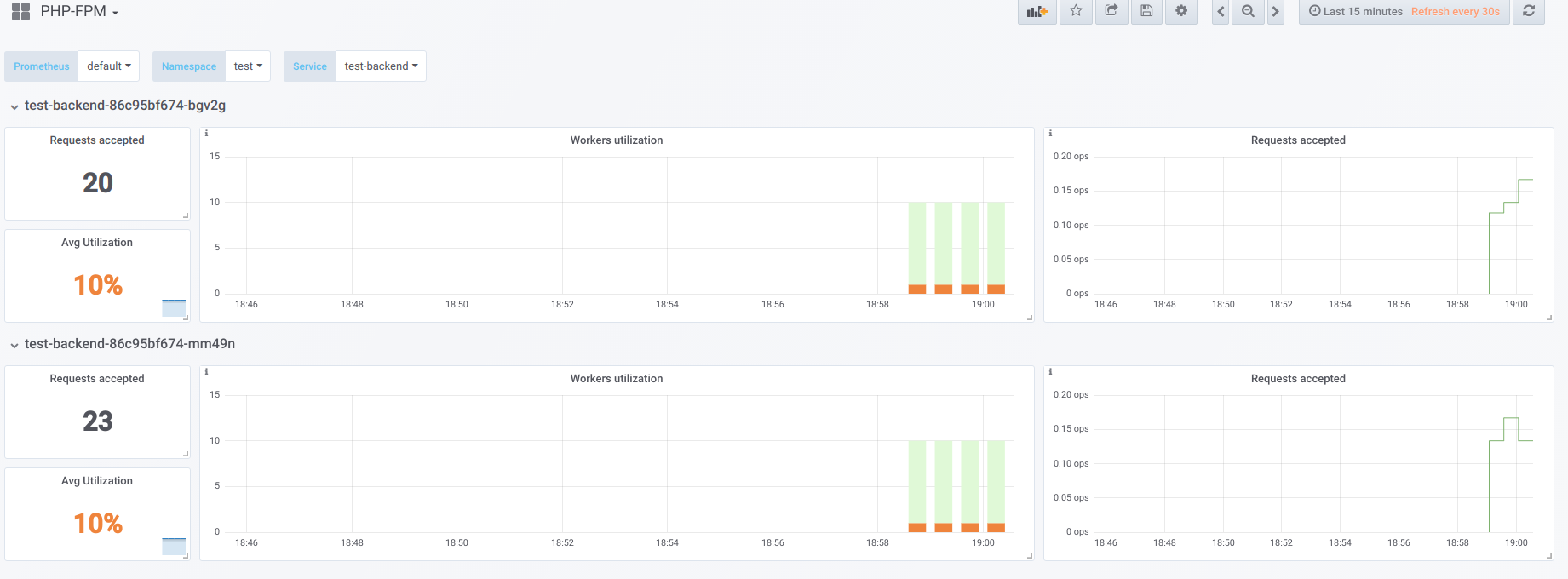
Starten Sie nun den Start mit Parallelität 19:
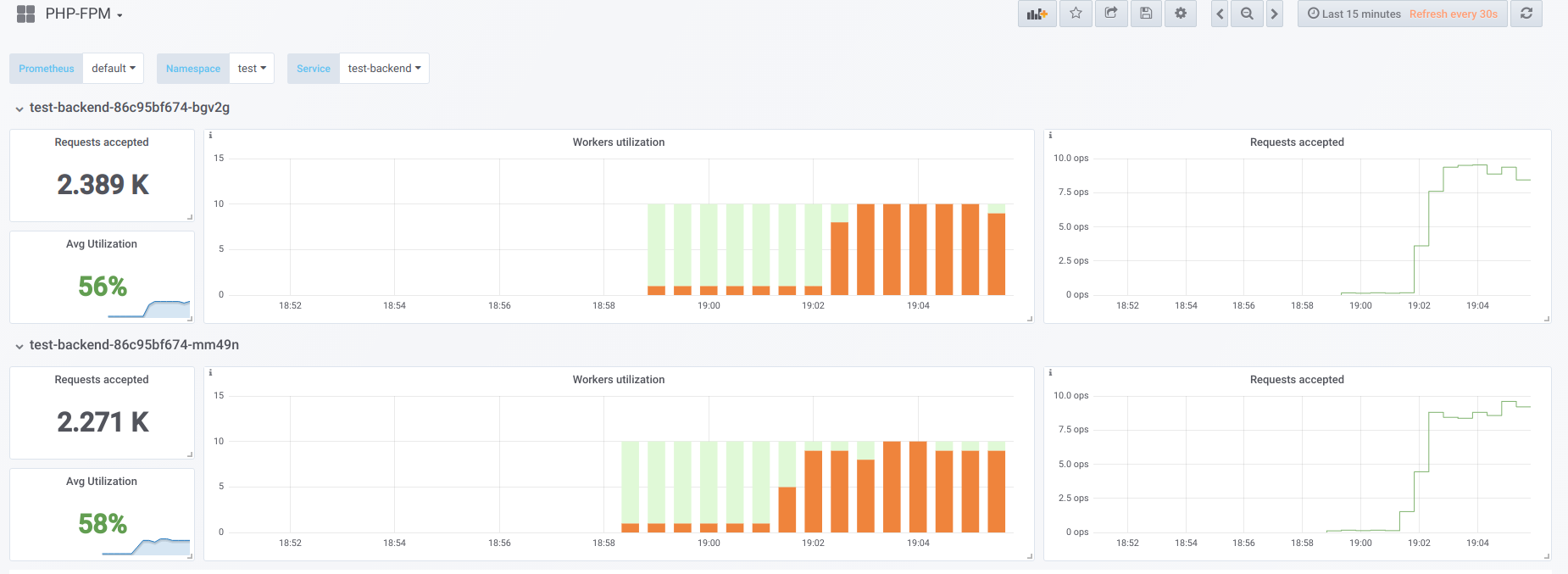
Versuchen wir nun, die Parallelität höher zu machen, als wir es können (20) ... sagen wir 23. Dann sind alle PHP-Fpm-Mitarbeiter damit beschäftigt, Client-Anfragen zu verarbeiten:

Vorkers reichen nicht mehr aus, um eine Lebendigkeitsprobe zu verarbeiten. Daher sehen wir dieses Bild im Kubernetes-Dashboard (oder
describe pod ):

Wenn nun einer der Pods neu gestartet wird, tritt ein
Lawineneffekt auf : Anforderungen fallen auf den zweiten Pod, der sie ebenfalls nicht verarbeiten kann, weshalb wir eine große Anzahl von Fehlern von Clients erhalten. Nachdem die Pools aller Container voll sind, ist es problematisch, den Service zu erhöhen - dies ist nur durch einen starken Anstieg der Anzahl der Pods oder Arbeiter möglich.
Erste Option
In einem Container mit PHP können Sie 2 fpm-Pools konfigurieren: einen für die Verarbeitung von Clientanforderungen und einen für die Überprüfung der „Überlebensfähigkeit“ des Containers. Dann müssen Sie auf dem Nginx-Container eine ähnliche Konfiguration vornehmen:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
Alles, was bleibt, ist das Senden des Liveness-Samples zur Verarbeitung an den als
backend-status Upstream.
Nachdem der Liveness-Test separat verarbeitet wurde, treten bei einigen Clients immer noch Fehler auf, aber es gibt zumindest keine Probleme beim Neustart des Pods und beim Trennen des Restes der Clients. Dadurch werden wir die Anzahl der Fehler erheblich reduzieren, auch wenn unsere Backends die aktuelle Last nicht bewältigen können.
Diese Option ist natürlich besser als nichts, aber sie ist auch schlecht, weil mit dem Hauptpool etwas passieren kann, was wir über die Verwendung des Lebendigkeitstests nicht wissen werden.
Zweite Option
Sie können auch das nicht sehr beliebte Nginx-Modul namens
Nginx-Limit-Upstream verwenden . Dann werden wir in PHP 11 Worker angeben und im Container mit nginx eine ähnliche Konfiguration vornehmen:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
Auf der Frontend-Ebene begrenzt nginx die Anzahl der Anforderungen, die an das Backend gesendet werden (10). Ein interessanter Punkt ist, dass ein spezielles Backlog erstellt wird: Wenn die 11. Anforderung für nginx vom Client stammt und nginx feststellt, dass der PHP-Fpm-Pool ausgelastet ist, wird diese Anforderung für 5 Sekunden in das Backlog gestellt. Wenn während dieser Zeit php-fpm nicht freigegeben wurde, wird Ingress erst dann aktiv, wodurch die Anforderung an einen anderen Pod wiederholt wird. Dies glättet das Bild, da wir immer 1 freien PHP-Mitarbeiter für die Verarbeitung eines Liveness-Samples haben - wir können den Lawineneffekt vermeiden.
Andere Gedanken
Für vielseitigere und schönere Möglichkeiten zur Lösung dieses Problems lohnt es sich, in Richtung
Envoy und seiner Analoga zu schauen.
Im Allgemeinen empfehle ich dringend, fertige
Exporteure mit der Konvertierung von Daten aus der Software in das Prometheus-Format zu beauftragen, damit Prometheus eine klare Beschäftigung von Arbeitnehmern hat, was wiederum dazu beiträgt, das Problem schnell zu finden (und darüber zu informieren).
PS
Andere aus dem K8s Tipps & Tricks-Zyklus:
Lesen Sie auch in unserem Blog: