
Jeden Tag suchen eineinhalb Millionen Menschen in Ozon nach einer Vielzahl von Produkten, und für jedes von ihnen sollte der Dienst ähnliche (wenn der Staubsauger noch einen leistungsstärkeren benötigt) oder verwandte Produkte (wenn für den singenden Dinosaurier Batterien benötigt werden) auswählen. Wenn es viele Arten von Waren gibt, hilft das Word2Vec-Modell, das Problem zu lösen. Wir verstehen, wie es funktioniert und wie man Vektordarstellungen für beliebige Objekte erstellt.
Motivation
Um das Modell zu erstellen und zu trainieren, verwenden wir die Einbettungstechnik, die für maschinelles Lernen Standard ist, wenn sich jedes Objekt in einen Vektor fester Länge verwandelt und enge Vektoren geschlossenen Objekten entsprechen. Fast alle bekannten Modelle erfordern, dass die Eingabedaten eine feste Länge haben, und ein Satz von Vektoren ist eine einfache Möglichkeit, sie in diese Form zu bringen.
Eine der ersten Einbettungsmethoden ist word2vec. Wir haben diese Methode für unsere Aufgabe angepasst, wir verwenden Produkte als Wörter und Benutzersitzungen als Sätze. Wenn Ihnen alles klar ist, können Sie die Ergebnisse durchblättern.
Als nächstes werde ich über die Architektur des Modells und dessen Funktionsweise sprechen. Da es sich um Waren handelt, müssen wir lernen, wie man solche Beschreibungen erstellt, die einerseits genügend Informationen enthalten und andererseits für den Algorithmus des maschinellen Lernens verständlich sind.
Auf der Website hat jedes Produkt eine Karte. Es besteht aus einem Titel, einer Textbeschreibung, Spezifikationen und Fotos. Zu unserer Verfügung stehen auch Daten zur Interaktion der Benutzer mit dem Produkt: Ansichten, Hinzufügen zum Warenkorb oder Favoriten werden in den Protokollen gespeichert.
Es gibt zwei grundlegend verschiedene Möglichkeiten, eine Vektorbeschreibung eines Produkts zu erstellen:
- Verwendung von Inhalten - Faltungs-Neuronale Netze zum Extrahieren von Merkmalen aus Fotos, wiederkehrenden Netzen oder einer Wortsammlung zur Analyse einer Textbeschreibung;
- Verwendung von Daten zu Benutzerinteraktionen mit dem Produkt: Welche Produkte und wie oft sie zusammen mit den Daten in den Warenkorb schauen / hinzufügen.
Wir werden uns auf die zweite Methode konzentrieren.
Daten für das Prod2Vec-Modell
Lassen Sie uns zunächst herausfinden, welche Daten wir verwenden. Wir verfügen über alle Klicks von Benutzern auf der Website, sie können in Benutzersitzungen unterteilt werden - Sequenzen von Klicks mit Intervallen von nicht mehr als 30 Minuten zwischen benachbarten Klicks. Zum Trainieren des Modells verwenden wir Daten aus etwa 100 Millionen Benutzersitzungen, in denen wir jeweils nur Produkte anzeigen und dem Warenkorb hinzufügen möchten.
Ein Beispiel für eine echte Benutzersitzung:

Jedes Produkt in der Sitzung entspricht seinem Kontext - alle Produkte, die der Benutzer in dieser Sitzung zum Warenkorb hinzugefügt hat, sowie Produkte, die damit angezeigt werden. Das prod2vec-Modell basiert auf der Annahme, dass ähnliche Produkte meist ähnliche Kontexte haben.
Zum Beispiel:

Wenn die Annahme zutrifft, haben beispielsweise Fälle für dasselbe Telefonmodell ähnliche Kontexte (dasselbe Telefon). Wir werden diese Hypothese testen, indem wir Produktvektoren konstruieren.
Modell Prod2Vec
Wenn wir die Konzepte eines Produkts und seinen Kontext vorstellen, beschreiben wir das Modell selbst. Dies ist ein neuronales Netzwerk mit zwei vollständig verbundenen Schichten. Die Anzahl der Eingaben der ersten Schicht entspricht der Anzahl der Produkte, für die wir Vektoren erstellen möchten. Jedes Produkt am Eingang wird durch einen Vektor von Nullen mit einer einzelnen Einheit codiert - der Stelle dieses Produkts im Wörterbuch.
Die Anzahl der Neuronen am Ausgang der ersten Schicht entspricht der Dimension der Vektoren, die wir erhalten möchten, zum Beispiel 64. Am Ausgang der letzten Schicht gibt es wiederum eine Anzahl von Neuronen, die der Anzahl der Waren entspricht.

Wir werden das Modell trainieren, um den Kontext vorherzusagen und das Produkt zu kennen. Diese Architektur heißt Skip-Gramm (ihre Alternative ist CBOW, wo wir das Produkt entsprechend seinem Kontext vorhersagen). Während des Trainings werden Waren an den Eingang geliefert, und es wird erwartet, dass Waren aus ihrem Kontext ausgegeben werden (ein Vektor von Nullen mit einer Einheit an der entsprechenden Stelle).
Im Wesentlichen handelt es sich hierbei um eine Klassifizierung mit mehreren Klassen, und der Verlust der Kreuzentropie kann zum Trainieren des Modells verwendet werden. Für ein Wort-Wort-Paar aus dem Kontext wird wie folgt geschrieben:
L=−pc+ log sumVi=1exp(pi)
wo pc - Netzwerkvorhersage für das Produkt aus dem Kontext, V - die Gesamtzahl der Waren pi - Netzwerkvorhersage für das Produkt i .
Nach dem Training des Modells können wir die zweite Schicht verwerfen - es wird nicht benötigt, um Vektoren zu erhalten. Die Gewichtsmatrix der ersten Schicht (Größe der Anzahl der Waren x 64) ist ein Wörterbuch der Warenvektoren. Jedes Produkt entspricht einer Zeile einer Matrix der Länge 64 - dies ist der dem Produkt entsprechende Vektor, der in anderen Algorithmen verwendet werden kann.
Dieses Verfahren funktioniert jedoch nicht für eine große Anzahl von Produkten. Und wir haben sie, erinnern Sie sich, eineinhalb Millionen.
Warum Prod2Vec nicht funktioniert
- Die Verlustfunktion enthält viele Operationen zum Aufnehmen des Exponenten - dies ist eine lange und instabile rechnerische.
- Infolgedessen werden Gradienten für alle Netzwerkgewichte berücksichtigt - und es können zig Millionen sein.
Um diese Probleme zu lösen, ist die negative Stichprobenmethode geeignet, mit der wir dem Netzwerk beibringen, nicht nur den Kontext für das Produkt vorherzusagen, sondern auch nicht die Produkte vorherzusagen, die nicht genau im Kontext sind. Dazu müssen wir negative Beispiele generieren - wählen Sie für jedes Produkt diejenigen aus, die nicht vorhergesagt werden müssen. Und hier hilft uns die Verfügbarkeit einer großen Menge an Waren. Wenn wir ein zufälliges Paar für ein Produkt auswählen, haben wir eine sehr geringe Wahrscheinlichkeit, dass es sich als Produkt aus dem Kontext herausstellt.
Als Ergebnis generieren wir für jedes Produkt im Kontext zufällig 5-10 Produkte, die nicht im Kontext enthalten sind. Darüber hinaus werden die Waren nicht gleichmäßig verteilt, sondern proportional zur Häufigkeit ihres Auftretens.
Die Verlustfunktion ähnelt jetzt der bei der binären Klassifizierung verwendeten. Für ein Wort-Wort-Paar aus dem Kontext sieht es so aus:
L=− log sigma(uTwOvwI)− sumwn log sigma(−uTwnvwI)
In dieser Notation uwO bezeichnet eine Spalte der Gewichtsmatrix der zweiten Schicht, die dem Produkt aus dem Kontext entspricht, uwn - das gleiche für ein zufällig ausgewähltes Produkt, vwI - die Zeile der Gewichtsmatrix der ersten Schicht, die dem Hauptprodukt entspricht (dies ist genau der Vektor, den wir dafür erstellen). Funktion sigma(x)= frac11+exp(−x) .
Der Unterschied zur vorherigen Version besteht darin, dass nicht alle Netzwerkgewichte bei jeder Iteration aktualisiert werden müssen, sondern nur diejenigen, die einer kleinen Anzahl von Produkten entsprechen (das erste Produkt ist dasjenige, für das wir eine Vorhersage treffen, der Rest ist entweder ein Produkt aus seinem Kontext oder zufällig ausgewählt ) Gleichzeitig haben wir bei jeder Iteration eine große Anzahl exponentieller Captures entfernt.
Eine andere Technik, die wiederum die Qualität des resultierenden Modells verbessert, ist die Unterabtastung. In diesem Fall nehmen wir absichtlich weniger häufig gefundene Waren zum Training, um das beste Ergebnis für seltene Waren zu erzielen.
Ergebnisse
Verwandte Produkte
Wir haben also gelernt, wie man Vektoren für Waren erhält. Jetzt müssen wir die Angemessenheit und Anwendbarkeit unseres Modells überprüfen.
Das folgende Bild zeigt das Produkt und seine nächsten Nachbarn im Kosinusmaß der Nähe.
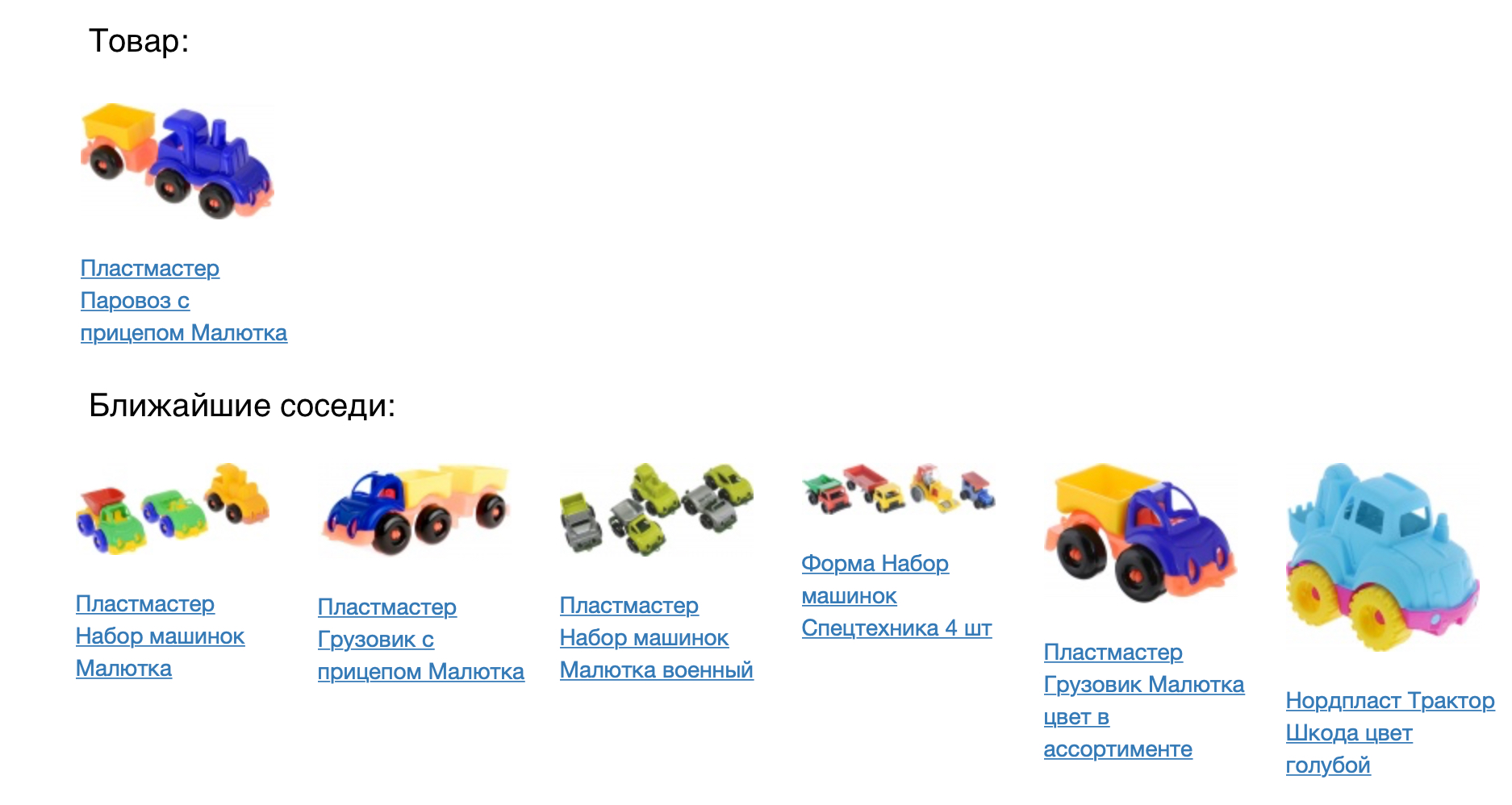
Das Ergebnis sieht gut aus, aber Sie müssen numerisch überprüfen, wie gut unser Modell ist. Zu diesem Zweck haben wir es auf die Aufgabe der Produktempfehlungen angewendet. Für jedes Produkt empfehlen wir, in einem konstruierten Vektorraum zu kommen. Wir haben das prod2vec-Modell mit einem viel einfacheren Modell verglichen, basierend auf Statistiken gemeinsamer Ansichten und dem Hinzufügen von Artikeln zum Warenkorb. Für jedes Produkt in der Sitzung wurde eine Liste mit 7 Empfehlungen erstellt. Die Kombination aller empfohlenen Produkte in der Sitzung wurde mit dem verglichen, was eine Person tatsächlich zum Warenkorb hinzugefügt hat. Mit prod2vec haben wir in mehr als 40% der Sitzungen mindestens ein Produkt empfohlen, das dann in den Warenkorb gelegt wurde. Zum Vergleich zeigt ein einfacherer Algorithmus eine Qualität von 34%.
Die resultierende Vektorbeschreibung ermöglicht es uns nicht nur, nach den nächsten zu suchen (was durch ein einfacheres Modell erfolgen kann, wenn auch mit schlechterer Qualität). Wir können überlegen, welche interessanten Nebenwirkungen mit unserem Modell gezeigt werden können.
Vektorarithmetik
Um zu veranschaulichen, dass die Vektoren die wahre Bedeutung von Waren tragen, können wir versuchen, Vektorarithmetik für sie zu verwenden. Wie im Lehrbuchbeispiel zu word2vec (König - Mann + Frau = Königin) können wir uns beispielsweise fragen, welches Produkt ungefähr so weit vom Drucker entfernt ist wie der Staubbeutel vom Staubsauger. Der gesunde Menschenverstand schreibt vor, dass es sich um eine Art Verbrauchsmaterial handeln sollte, nämlich eine Patrone. Unser Modell kann solche Muster erfassen:

Visualisierung des Produktraums
Um die Ergebnisse besser zu verstehen, können wir den Vektorraum von Waren in der Ebene visualisieren und die Dimension auf zwei reduzieren (in diesem Beispiel haben wir t-SNE verwendet).

Es ist deutlich zu sehen, dass verwandte Produkte Cluster bilden. Zum Beispiel sind Cluster mit Textilien für das Schlafzimmer, männliche und weibliche Kleidung, Schuhe deutlich sichtbar. Wir stellen erneut fest, dass dieses Modell nur auf der Grundlage der Geschichte der Benutzerinteraktionen mit Waren erstellt wurde. Wir haben beim Training nicht die Ähnlichkeit von Bildern oder Textbeschreibungen verwendet.
Anhand der Abbildung des Raums können Sie auch sehen, wie Sie mithilfe des Modells Zubehör für Waren auswählen können. Dazu müssen Sie Waren aus dem nächstgelegenen Cluster entnehmen, z. B. Sportartikel für T-Shirts und Mützen für warme Pullover empfehlen.
Pläne
Wir führen jetzt das Modell prod2vec in der Produktion ein, um Produktempfehlungen zu berechnen. Die erhaltenen Vektoren können auch als Merkmale für andere Algorithmen für maschinelles Lernen verwendet werden, an denen unser Team beteiligt ist (Prognose der Nachfrage nach Waren, Rangfolge in Suche und Katalogen, persönliche Empfehlungen).
In Zukunft planen wir, die auf der Site erhaltenen Einbettungen in Echtzeit zu implementieren. Für alle angesehenen Waren befinden sich die nächsten in der Sitzung, was sich sofort in der personalisierten Lieferung widerspiegelt. Wir planen auch, die Bildanalyse und Ähnlichkeitsanalyse gemäß der Vektorbeschreibung in unser Modell zu integrieren, wodurch die Qualität der resultierenden Vektoren erheblich verbessert wird.
Wenn Sie wissen, wie man das am besten macht (oder neu macht), kommen Sie zu Besuch (und arbeiten Sie noch besser).
Referenzen:
- Mikolov, Tomas et al. "Verteilte Darstellungen von Wörtern und Phrasen und deren Zusammensetzung." Fortschritte in neuronalen Informationsverarbeitungssystemen. 2013.
- Grbovic, Mihajlo et al. "E-Commerce in Ihrem Posteingang: Produktempfehlungen im Maßstab." Tagungsband der 21. ACM SIGKDD International Conference on Knowledge Discovery und Data Mining. ACM, 2015.
- Grbovic, Mihajlo und Haibin Cheng. "Personalisierung in Echtzeit mithilfe von Einbettungen für das Suchranking bei Airbnb." Vorträge der 24. Internationalen ACM SIGKDD-Konferenz zu Knowledge Discovery & Data Mining. ACM, 2018.