Bei Rostelecom verwenden wir Hadoop, um Daten, die aus mehreren Quellen heruntergeladen wurden, mithilfe von Java-Anwendungen zu speichern und zu verarbeiten. Wir sind jetzt zu einer neuen Version von hadoop mit Kerberos-Authentifizierung übergegangen. Beim Umzug bin ich auf eine Reihe von Problemen gestoßen, einschließlich der Verwendung der YARN-API. Die Arbeit von Hadoop mit der Kerberos-Authentifizierung verdient einen separaten Artikel. In diesem Artikel wird jedoch auf das Debuggen von Hadoop MapReduce eingegangen.

Bei der Ausführung von Aufgaben im Cluster wird der Start des Debuggers dadurch erschwert, dass wir nicht wissen, welcher Knoten diesen oder jenen Teil der Eingabedaten verarbeitet, und unseren Debugger nicht im Voraus konfigurieren können.
Sie können das bewährte
System.out.println("message") . Aber wie analysiert man die Ausgabe von
System.out.println("message") die über diese Knoten verteilt ist?
Wir können Nachrichten an den Standardfehlerstrom ausgeben. Alles geschrieben in stdout oder stderr,
wird an die entsprechende Protokolldatei gesendet, die sich auf der Webseite mit den erweiterten Aufgabeninformationen oder in den Protokolldateien befindet.
Wir können auch Debugging-Tools in unseren Code aufnehmen, Aufgabenstatusmeldungen aktualisieren und benutzerdefinierte Zähler verwenden, um das Ausmaß der Katastrophe zu verstehen.
Die Hadoop MapReduce-Anwendung kann in allen drei Modi, in denen Hadoop arbeiten kann, debuggt werden:
- Standalone
- pseudoverteilter Modus
- vollständig verteilt
Im Detail werden wir uns auf die ersten beiden konzentrieren.
Pseudo-verteilter Modus
Der pseudoverteilte Modus wird verwendet, um einen realen Cluster zu simulieren. Und es kann zum Testen in einer Umgebung verwendet werden, die so produktiv wie möglich ist. In diesem Modus arbeiten alle Hadoop-Dämonen auf einem Knoten!
Wenn Sie über einen Entwicklungsserver oder eine andere Sandbox verfügen (z. B. eine virtuelle Maschine mit einer angepassten Entwicklungsumgebung wie Hortonworks Sanbox mit HDP), können Sie das Steuerungsprogramm mithilfe von Remote-Debugging-Tools debuggen.
Um mit dem Debuggen zu beginnen, müssen Sie den Wert der Umgebungsvariablen
YARN_OPTS . Das Folgende ist ein Beispiel. Zur Vereinfachung können Sie die Datei startWordCount.sh erstellen und die erforderlichen Parameter hinzufügen, um die Anwendung zu starten.
`./startWordCount.sh` nun das Skript
`./startWordCount.sh` , wird eine Meldung
`./startWordCount.sh` Listening for transport dt_socket at address: 6000
Die IDE muss weiterhin für das Remote-Debugging konfiguriert werden. Ich benutze Intellij IDEA. Gehen Sie zum Menü Ausführen -> Konfigurationen bearbeiten ... Fügen Sie eine neue
Remote Konfiguration hinzu.
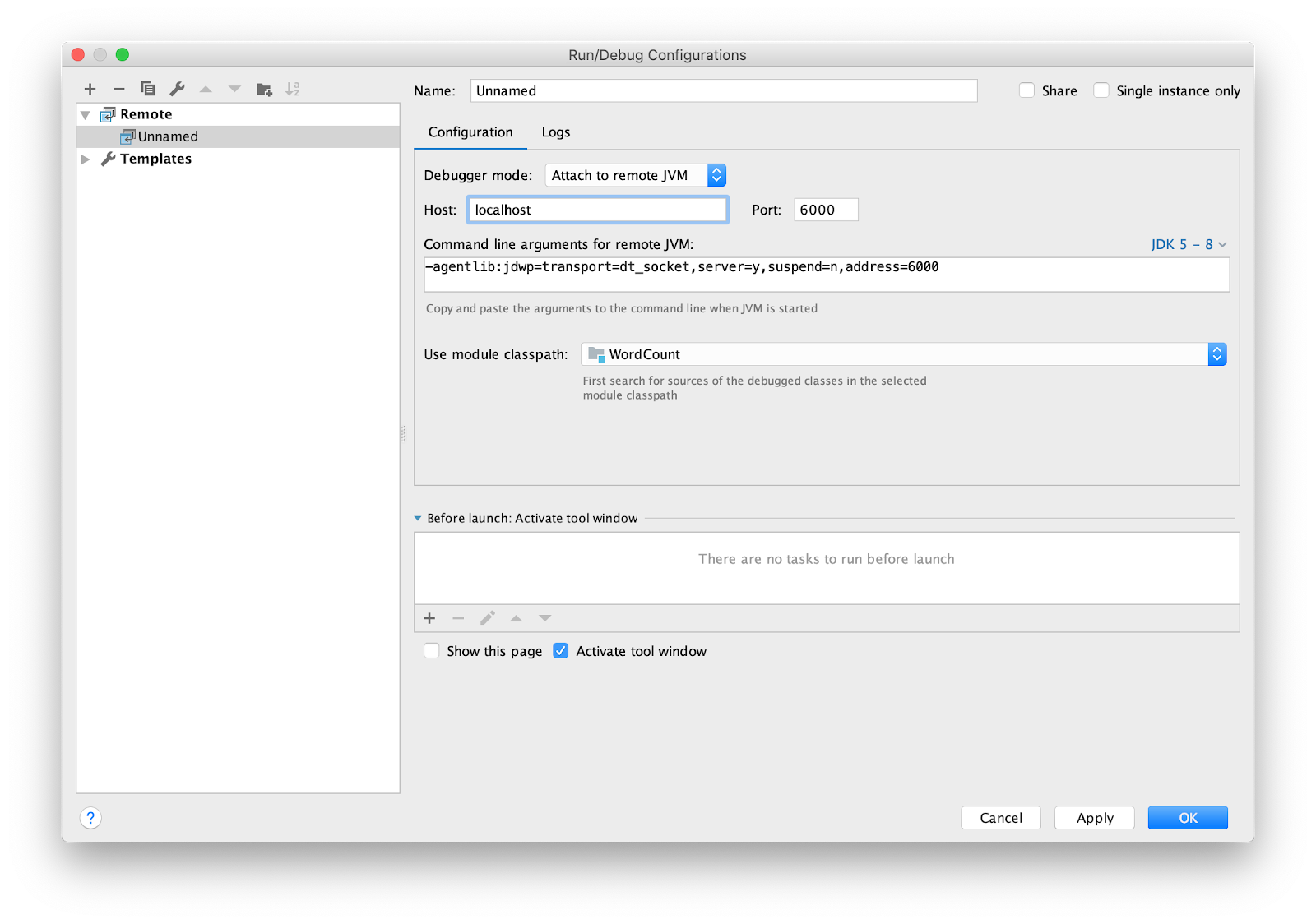
Setzen Sie den Haltepunkt auf main und führen Sie ihn aus.
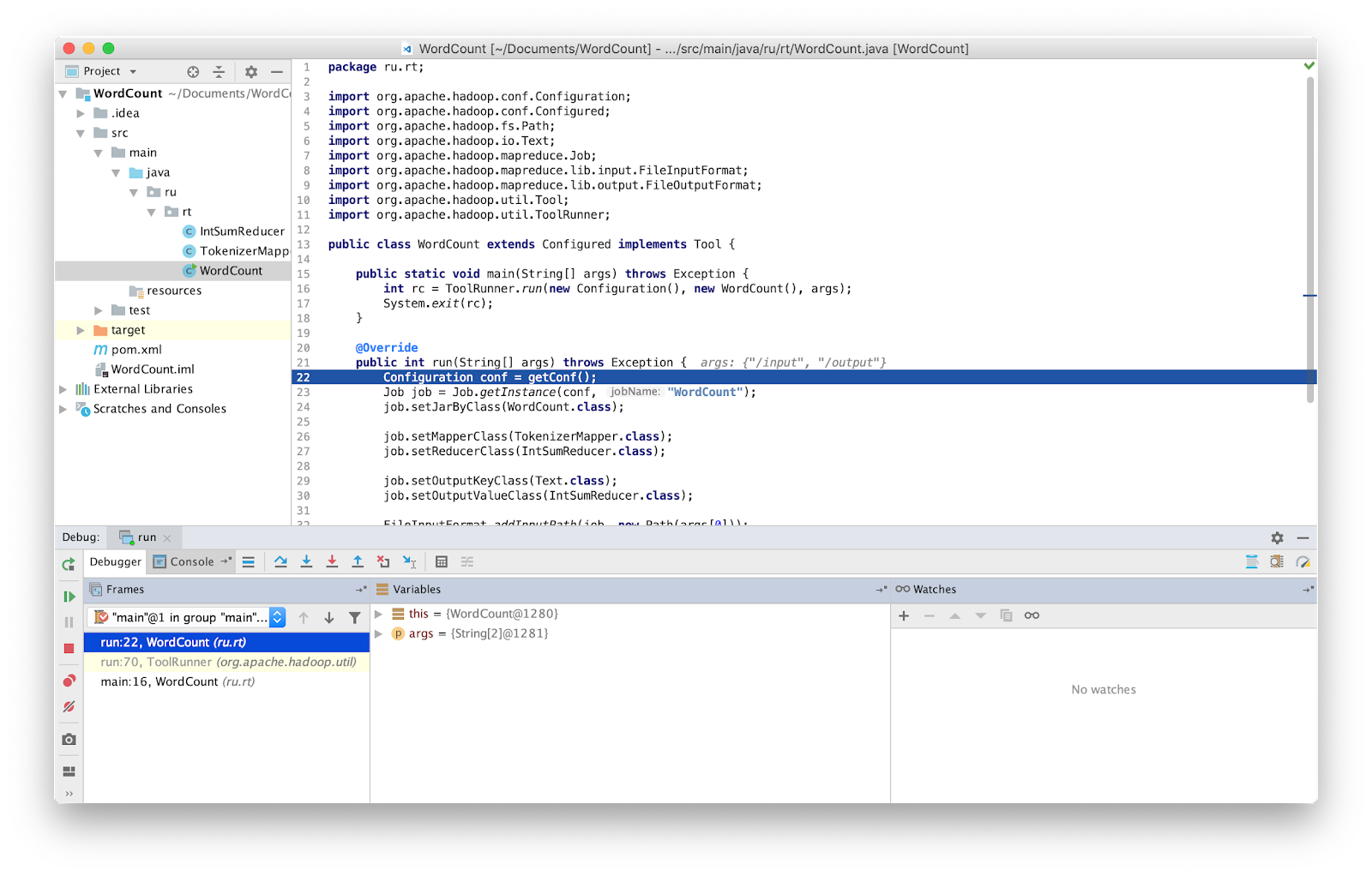
Das war's, jetzt können wir das Programm wie gewohnt debuggen.
ACHTUNG Sie müssen sicherstellen, dass Sie mit der neuesten Version des Quellcodes arbeiten. Wenn nicht, können Unterschiede in den Zeilen auftreten, in denen der Debugger stoppt.
In früheren Versionen von Hadoop wurde eine spezielle Klasse bereitgestellt, mit der Sie eine fehlgeschlagene Aufgabe neu starten konnten - isolationRunner. Die Daten, die den Fehler verursacht haben, wurden unter der in der Hadoop-Umgebungsvariablen mapred.local.dir angegebenen Adresse auf der Festplatte gespeichert. Leider wird diese Klasse in neueren Versionen von Hadoop nicht mehr angeboten.
Standalone (lokaler Start)
Standalone ist der Standardmodus, in dem Hadoop arbeitet. Es eignet sich zum Debuggen, wenn HDFS nicht verwendet wird. Mit einem solchen Debugging können Sie die Eingabe und Ausgabe über das lokale Dateisystem verwenden. Der Standalone-Modus ist normalerweise der schnellste Hadoop-Modus, da er das lokale Dateisystem für alle Eingabe- und Ausgabedaten verwendet.
Wie bereits erwähnt, können Sie Debugging-Tools in Ihren Code einfügen, z. B. Zähler. Zähler werden durch die Java-
Enumeration definiert . Der Aufzählungsname definiert den Namen der Gruppe, und die Aufzählungsfelder bestimmen die Namen der Zähler. Ein Zähler kann zur Bewertung eines Problems hilfreich sein.
und kann als Ergänzung zur Debug-Ausgabe verwendet werden.
Erklärung und Verwendung des Zählers:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
Verwenden Sie zum Inkrementieren des Zählers die Methode
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
Nachdem MapReduce erfolgreich abgeschlossen wurde, zeigt die Aufgabe die Zähler am Ende an.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
Fehlerhafte Daten können in stderr oder stdout ausgegeben oder zur weiteren Analyse mithilfe der
MultipleOutputs Klasse in hdfs geschrieben werden. Die empfangenen Daten können im Standalone-Modus oder beim Schreiben von Komponententests an den Eingang der Anwendung übertragen werden.
Hadoop verfügt über die MRUnit-Bibliothek, die in Verbindung mit Test-Frameworks (z. B. JUnit) verwendet wird. Beim Schreiben von Komponententests überprüfen wir, ob die Funktion am Ausgang das erwartete Ergebnis liefert. Wir verwenden die MapDriver-Klasse aus dem MRUnit-Paket, in deren Eigenschaften wir die getestete Klasse festlegen. Verwenden Sie dazu die
withMapper() -Methode, die Eingabewerte
withInputValue() und das erwartete Ergebnis
withOutput() oder
withMultiOutput() wenn mehrere Ausgaben verwendet werden.
Hier ist unser Test.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
Vollverteilter Modus
Wie der Name schon sagt, ist dies ein Modus, in dem die gesamte Leistung von Hadoop genutzt wird. Das gestartete MapReduce-Programm kann auf 1000 Servern ausgeführt werden. Das Debuggen des MapReduce-Programms ist immer schwierig, da Mapper auf verschiedenen Computern mit unterschiedlichen Eingabedaten ausgeführt werden.
Fazit
Wie sich herausstellte, ist das Testen von MapReduce nicht so einfach, wie es auf den ersten Blick scheint.
Um Zeit bei der Suche nach Fehlern in MapReduce zu sparen, habe ich alle oben aufgeführten Methoden verwendet und empfehle jedem, sie auch anzuwenden. Dies ist besonders nützlich bei großen Installationen, z. B. bei Rostelecom.