Wenn Sie große Datenbanken erweitern und plötzlich auf eine Leistungsobergrenze stoßen, ist es Zeit zu erweitern. Mit der Scale-Out-Erweiterung ist klar: Sie fügen Server hinzu und kennen den Kummer nicht. Mit Scale-up macht es nicht so viel Spaß. Gemäß der leimlosen Standardarchitektur nehmen wir zwei Prozessoren und fügen dann zwei weitere hinzu ... also kommen wir auf acht und das war's. Intel hat es nicht mehr vorausgesehen und auf einem neuen Server gespart.

Aber es gibt eine Alternative - geklebte Architektur. Darin sind Doppelprozessor-Recheneinheiten über Knotensteuerungen miteinander verbunden. Mit ihrer Hilfe steigt der obere Schwellenwert pro Server auf 16 oder mehr Prozessoren. In diesem Beitrag werden wir mehr über die geklebte Architektur im Allgemeinen und deren Implementierung auf unseren Servern sprechen.
Bevor wir zur ehrlichen Architektur übergehen, beschäftigen wir uns aus Gründen der Ehrlichkeit mit den Vor- und Nachteilen von Leimlosigkeit.
Typisch sind Lösungen, die nach einer leimlosen Architektur hergestellt wurden. Die Prozessoren kommunizieren ohne zusätzliches Gerät miteinander, jedoch über den Standard-QPI \ UPI-Bus. Das Ergebnis ist etwas billiger als mit geklebt. Aber nach jeweils acht Prozessoren muss viel Geld ausgegeben werden - um einen neuen Server zu installieren.
 Typische leimlose Architektur
Typische leimlose ArchitekturUnd mit der geklebten Architektur steigt die Obergrenze, wie bereits erwähnt, auf 16 oder mehr Prozessoren pro Server.
Wie die geklebte Bull BCS2-Architektur funktioniert
Die Vorteile der Bull BCS2-Architektur werden durch zwei Komponenten bereitgestellt: Resilient eXternal Node-Controller und Prozessor-Caching. Teams, die mit Prozessoren der Intel Xeon E7-4800 / 8800 v4-Serie kompatibel sind, werden unterstützt.
 Bull BCS2 mit geklebter Architektur. Alle Verbindungen im Server sind hier sichtbar. Jeder BCS-Knoten verfügt über 7 XQPI-Links.
Bull BCS2 mit geklebter Architektur. Alle Verbindungen im Server sind hier sichtbar. Jeder BCS-Knoten verfügt über 7 XQPI-Links.Dank des Caching wird die Interaktion zwischen Prozessoren reduziert - die Prozessoren in jedem Modul haben Zugriff auf einen gemeinsamen Cache. Dadurch wird die RAM-Belastung reduziert. Noda wiederum arbeitet als Verkehrskommutator und löst das Problem der „engen Hälse“ - leitet den Verkehr auf dem am wenigsten genutzten Pfad um.
Infolgedessen verbraucht die Bull BCS2-Architektur nur 5-10% der Intel QPI-Busbandbreite, dem Standard für leimlose Architektur. Die Zugriffsverzögerungen auf den lokalen Speicher sind vergleichbar mit leimlosen 4-Socket-Systemen und 44% weniger als leimlose 8-Socket-Systeme. Gemäß den Spezifikationen beträgt die Gesamtdatenübertragungsgeschwindigkeit des BCS-Knotens 230 GB / s - 25,6 GB / s werden für jeden der 7 Ports erhalten. Die maximale Bandbreite beträgt 300 GB / s.

In jedem Bullion S-Server befindet sich ein solcher Schalter auf dem Motherboard. Eine XQPI-Verbindung (16 Sockets) entspricht in Bezug auf die Geschwindigkeit zehn 10-GigE-Ports.
 Range Bullion S.
Range Bullion S.In Konfigurationen auf 4 und 8 Prozessoren ist der Unterschied zwischen geklebter und leimloser Architektur vernachlässigbar. Die Situation ändert sich jedoch, wenn auf 16 Prozessoren umgeschaltet wird. Wir erinnern uns, dass Sie dafür leichtsinnig bereits zwei Server benötigen. Und auf dem Bullion S-Server mit geklebter Architektur bricht alles so ein:
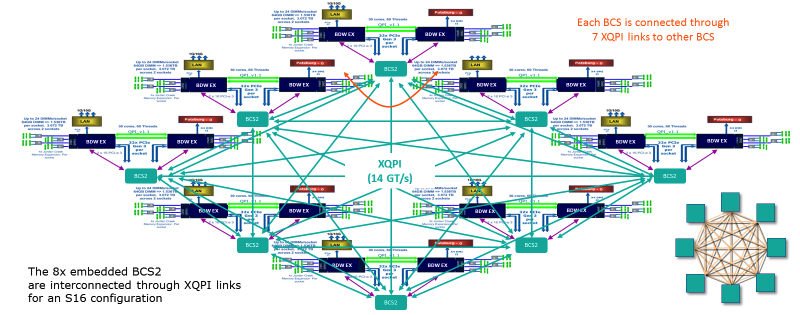 Die Dual-Prozessor-Module sind über ein XQPI-Netzwerk mit einem Durchsatz von 14 GT / s (Milliarden von Transaktionen pro Sekunde) miteinander verbunden.
Die Dual-Prozessor-Module sind über ein XQPI-Netzwerk mit einem Durchsatz von 14 GT / s (Milliarden von Transaktionen pro Sekunde) miteinander verbunden.Die Steckplätze bieten Platz für alle Prozessoren der E7-Familie, mit Ausnahme von E7-8893, die nur in Konfigurationen mit zwei Prozessoren verwendet werden können. Im Vergleich zum Zugriff auf den lokalen Speicher erreicht die Verzögerung des NUMA-Systems innerhalb des Moduls etwa x1,5 und zwischen den Modulen etwa x4. Der Host-Controller verwaltet die Hardware-Partition und ermöglicht das Erstellen von bis zu 8 separaten Partitionen, die auf dem Betriebssystem in Bullion S-Servern ausgeführt werden.
Dadurch können wir bis zu 384 Prozessorkerne auf einem Server hosten. In Bezug auf RAM beträgt die Obergrenze hier 384 DDR4-Module mit 64 GB. Insgesamt erhalten wir 24 Terabyte.
Die beschriebene Konfiguration ist für unsere Arbeitspferde - Bullion S-Server - relevant. Darüber hinaus verfügen wir über die BullSequana S-Reihe, die bis zu 32 physische Prozessoren auf der Basis der Intel Purley-Plattform und der Skylake- und Cascadelake-Architekturen enthalten kann (Q1 2019).
Integrationsbeispiele
Bullion S wurde für anspruchsvolle Aufgaben entwickelt - SAP HANA, Oracle, MS SQL, Datalake (Cloudera-zertifiziert nach BullSequana S), Virtualisierung / VDI auf VMware und hyperkonvergente Lösungen auf Basis von VMware vSAN. Teilweise auf den Bullion S-Servern hat Siemens die weltweit größte SAP-HANA-Plattform geschaffen. PWC basiert ebenfalls auf Bullion S und hat eine riesige Lösung für Hadoop und Analytics entwickelt. Insgesamt setzen weltweit rund 300 Unternehmen Bull-Lösungen ein.
Damit Sie die Funktionen unserer Server herausfinden können, präsentieren wir einen Plan für die Migration einer Oracle-Datenbank von Power auf x86 in den Filialen eines russischen Telekommunikationsbetreibers:

Fazit
Dank des Prozessor-Caching können Prozessoren dank der geklebten Architektur direkt mit anderen Prozessoren im Knoten kommunizieren. Und schnelle Links - verlangsamen Sie nicht, wenn Sie mit anderen Clustern interagieren. Heute passen bis zu 16 Prozessoren (384 Kerne) und bis zu 24 TB RAM in einen Bullion S-Server. Der Skalierungsschritt besteht aus zwei Prozessoren - dies erleichtert die Verteilung der finanziellen Belastung beim Erstellen einer IT-Infrastruktur.
In zukünftigen Materialien planen wir, unsere Server detaillierter zu analysieren. Gerne beantworten wir Ihre Fragen in den Kommentaren.