Beginnen wir mit einer Reihe von Artikeln zur Sicherheit von Webanwendungen mit einer Erklärung, was Browser tun und wie sie es tun. Da die meisten Ihrer Kunden über Browser mit Ihrer Webanwendung interagieren, müssen Sie die Grundlagen der Funktionsweise dieser großartigen Programme verstehen.
 Chrom und Luchs
Chrom und LuchsEin Browser ist eine
Rendering-Engine . Seine Aufgabe ist es, eine Webseite herunterzuladen und für Menschen lesbar darzustellen.
Dies ist zwar fast eine kriminelle Vereinfachung, aber im Moment ist dies alles, was wir im Moment wissen müssen.
- Der Benutzer gibt die Adresse in die Eingabezeile des Browsers ein.
- Der Browser lädt das „Dokument“ unter dieser URL herunter und zeigt es an.
Sie sind möglicherweise daran gewöhnt, mit einem der beliebtesten Browser wie Chrome, Firefox, Edge oder Safari zu arbeiten. Dies bedeutet jedoch nicht, dass es keine anderen Browser auf der Welt gibt.
Zum Beispiel ist
lynx ein leichtgewichtiger Befehlszeilen-Textbrowser. Das Herzstück von lynx sind die gleichen Prinzipien, die Sie in allen anderen Mainstream-Browsern finden. Der Benutzer gibt eine Webadresse (URL) ein, der Browser lädt das Dokument herunter und zeigt es an. Der einzige Unterschied besteht darin, dass lynx keine grafische Rendering-Engine verwendet, sondern eine Textoberfläche, dank derer Websites wie Google folgendermaßen aussehen:
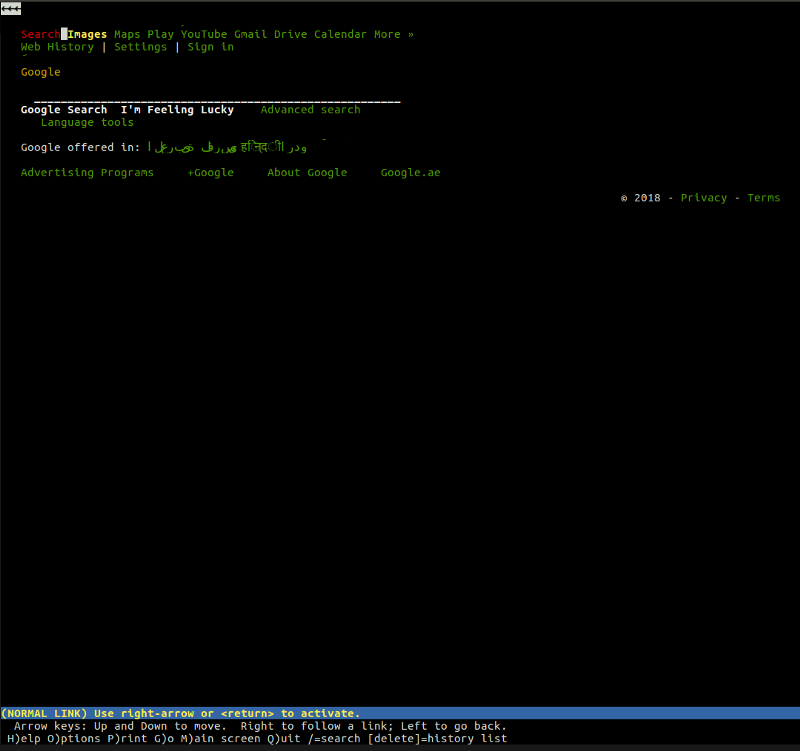
Im Allgemeinen haben wir eine Vorstellung davon, was der Browser tut, aber schauen wir uns die Aktionen, die diese genialen Anwendungen für uns ausführen, genauer an.
Was macht der Browser?
Kurz gesagt, der Browser besteht im Wesentlichen aus
- DNS-Auflösung
- HTTP-Austausch
- Rendern
- Zurücksetzen und wiederholen
DNS-Auflösung
Dieser Prozess hilft dem Browser zu wissen, zu welchem Server er eine Verbindung herstellen soll, wenn ein Benutzer eine URL eingibt. Der Browser kontaktiert den DNS-Server und stellt fest, dass
google.com mit den Ziffern
216.58.207.110 übereinstimmt - der IP-Adresse, mit der der Browser eine Verbindung herstellen kann.
HTTP-Austausch
Sobald der Browser feststellt, welcher Server unsere Anfrage bedient, stellt er eine TCP-Verbindung her und beginnt mit dem
HTTP-Austausch . Dies ist nichts anderes als eine Art der Kommunikation zwischen dem Browser und dem Server, den er benötigt, und für den Server ist es die Art, auf Browseranfragen zu antworten.
HTTP ist einfach der Name des beliebtesten Protokolls für die Kommunikation im Netzwerk, und Browser wählen bei der Kommunikation mit Servern meistens HTTP. HTTP-Austausch bedeutet, dass der Client (unser Browser) eine
Anfrage sendet und der Server eine
Antwort sendet.
Nachdem der Browser beispielsweise erfolgreich eine Verbindung zu dem Server hergestellt hat, der
google.com bedient , sendet er eine Anfrage, die so aussieht
GET / HTTP/1.1
Host: google.com
AcceptLassen Sie uns die Abfrage Zeile für Zeile analysieren:
- GET / HTTP / 1.1 : In dieser ersten Zeile fordert der Browser den Server auf, das Dokument vom Speicherort / abzurufen, und fügt dann hinzu, dass der Rest der Anforderung über HTTP / 1.1 erfolgt (oder Sie können auch Version 1.0 oder 2 verwenden).
- Host: google.com : Dies ist der einzige HTTP-Header, der für das HTTP / 1.1-Protokoll erforderlich ist . Da der Server mehrere Domains bedienen kann (google.com, google.co.uk usw.), erwähnt der Client hier, dass die Anfrage für diesen bestimmten Host war.
- Akzeptieren: * / * : Ein optionaler Header, in dem der Browser dem Server mitteilt, dass er jede Antwort akzeptiert. Auf dem Server kann eine Ressource in JSON, XML oder HTML verfügbar sein, sodass er ein beliebiges Format auswählen kann, das er bevorzugt
Nachdem der als
Client fungierende Browser seine Anforderung abgeschlossen hat, sendet der Server eine Antwort. Hier ist die Antwort:
HTTP/1.1 200 OK Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly <!doctype html><html"> ... ... </html>
Wow, diesmal ziemlich viele Informationen, die verdaut werden müssen. Der Server teilt uns mit, dass die Anforderung erfolgreich war (
200 OK ), und fügt der
Antwort mehrere Header hinzu. Sie können beispielsweise herausfinden, welcher Server unsere Anforderung verarbeitet hat (
Server: gws ), wie lautet die
X-XSS- Schutzrichtlinie für diese Antwort usw. weiter und dergleichen.
Im Moment müssen Sie nicht jede Zeile in der Antwort verstehen. Später in dieser Reihe von Veröffentlichungen werden wir mehr über das HTTP-Protokoll, seine Header usw. sprechen.
Im Moment müssen Sie lediglich wissen, dass Client und Server Informationen austauschen und dies über das HTTP-Protokoll tun.
Rendern
Last but not least ist der Rendering-Prozess im Gange. Wie gut ist der Browser, wenn dem Benutzer nur eine Liste lustiger Zeichen angezeigt wird?
<!doctype html><html"> ... ... </html>
Im Hauptteil der
Antwort enthält der Server die Präsentation des angeforderten Dokuments gemäß dem
Content-Type- Header. In unserem Fall wurde der Inhaltstyp auf
text / html festgelegt , daher erwarten wir HTML-Markup in der Antwort - und das finden wir im Hauptteil des Dokuments.
Dies ist genau der Moment, in dem der Browser seine Fähigkeiten wirklich zeigt. Es liest und analysiert HTML-Code, lädt zusätzliche Ressourcen, die im Markup enthalten sind (zum Beispiel können dort JavaScript-Dateien oder CSS-Dokumente zum Laden angegeben werden) und präsentiert sie dem Benutzer so schnell wie möglich.
Wieder sollte das Endergebnis das sein, was dem durchschnittlichen Vasya zugänglich ist.
Wenn Sie eine detailliertere Erklärung benötigen, was wirklich passiert, wenn wir die Eingabetaste in der Adressleiste des Browsers drücken, würde ich empfehlen, den Artikel
„Was passiert, wenn ...“ zu lesen, ein sehr sorgfältiger Versuch, die Mechanismen zu erklären, die diesem Prozess zugrunde liegen.
Da es in dieser Serie um Sicherheit geht, werde ich einen Hinweis darauf geben, was wir gerade herausgefunden haben: Angreifer können leicht von
Schwachstellen in Bezug auf HTTP-Austausch und -Rendering leben . Sicherheitslücken, böswillige Benutzer und andere fantastische Kreaturen sind an anderer Stelle zu finden. Ein effektiverer Ansatz zur Bereitstellung von Schutz auf den genannten Ebenen ermöglicht es Ihnen jedoch bereits, Ihren Sicherheitsstatus erfolgreich zu verbessern.
Anbieter
Die 4 beliebtesten Browser gehören verschiedenen Anbietern:
- Google Chrome
- Firefox von Mozilla
- Apple Safari
- Microsoft Edge
Die Anbieter kämpfen nicht nur gegeneinander, um ihre Marktdurchdringung zu erhöhen, sondern interagieren auch miteinander, um die Webstandards zu verbessern, die eine Art „Mindestanforderung“ für Browser darstellen.
W3C ist der Eckpfeiler der Standardentwicklung, aber Browser entwickeln häufig ihre eigenen Funktionen, die sich schließlich in Webstandards verwandeln, und Sicherheit ist keine Ausnahme.
Beispielsweise wurden
SameSite-Cookies in Chrome 51 eingeführt, eine Funktion, mit der Webanwendungen eine bestimmte Art von Sicherheitsanfälligkeit, die als CSRF bezeichnet wird, beseitigen konnten (dazu später mehr). Andere Hersteller entschieden, dass dies eine gute Idee war, und folgten diesem Beispiel, was dazu führte, dass der SameSite-Ansatz zum Webstandard wurde: Safari ist derzeit der einzige große Browser
ohne SameSite-Cookie-Unterstützung .

Dies sagt uns zwei Dinge:
- Safari scheint sich nicht genug um die Sicherheit seiner Benutzer zu kümmern (nur ein Scherz: SameSite-Cookies werden in Safari 12 verfügbar sein, das möglicherweise bereits zum Zeitpunkt des Lesens dieses Artikels veröffentlicht wurde.)
- Das Beheben von Sicherheitslücken in einem Browser bedeutet nicht, dass alle Benutzer sicher sind
Der erste Punkt ist ein Schuss auf Safari (wie gesagt, ich mache Witze!), Und der zweite Punkt ist wirklich wichtig. Bei der Entwicklung von Webanwendungen müssen wir nicht nur sicherstellen, dass sie in verschiedenen Browsern gleich aussehen, sondern auch unseren Benutzern auf verschiedenen Plattformen den gleichen Schutz bieten.
Ihre Netzwerksicherheitsstrategie sollte variieren, je nachdem, welche Funktionen der Browser-Anbieter uns zur Verfügung stellt. Die meisten Browser unterstützen derzeit die gleichen Funktionen und weichen selten von ihrer allgemeinen Roadmap ab. Fälle wie der oben genannte treten jedoch weiterhin auf. Dies sollten wir bei der Definition unserer Sicherheitsstrategie berücksichtigen.
In unserem Fall sollten wir wissen, dass wir unsere Safari-Benutzer gefährden, wenn wir beschließen, CSRF-Angriffe nur mit SameSite-Cookies zu neutralisieren. Und das sollten auch unsere Benutzer wissen.
Und zu guter Letzt müssen Sie sich daran erinnern, dass Sie entscheiden können, ob Sie die Browserversion unterstützen möchten oder nicht: Die Unterstützung für jede Browserversion ist unpraktisch (denken Sie an Internet Explorer 6). Trotzdem ist die zuverlässige Unterstützung mehrerer neuerer Versionen der wichtigsten Browser normalerweise eine gute Lösung. Wenn Sie jedoch nicht vorhaben, auf einer bestimmten Plattform Schutz zu bieten, ist es sehr ratsam, dass Ihre Benutzer darüber Bescheid wissen.
Tipp für Profis : Sie sollten Ihre Benutzer niemals dazu ermutigen, veraltete Browser zu verwenden oder diese aktiv zu unterstützen. Selbst wenn Sie alle erforderlichen Vorsichtsmaßnahmen getroffen haben, haben andere Webentwickler dies nicht getan. Ermutigen Sie die Benutzer, die neueste unterstützte Version eines ihrer Hauptbrowser zu verwenden.
Anbieter oder Standardfehler?
Die Tatsache, dass ein normaler Benutzer mithilfe von Client-Software (Browser) eines Drittanbieters auf unsere Anwendung zugreift, fügt eine weitere Ebene hinzu, die den Weg zum bequemen und sicheren Surfen im Internet erschwert: Der Browser selbst kann eine Quelle für eine Sicherheitslücke sein.
Anbieter bieten Sicherheitsforschern, die möglicherweise nach Schwachstellen im Browser selbst suchen, normalerweise Belohnungen (auch als Bug Bounties bezeichnet). Diese Fehler beziehen sich nicht auf Ihre Webanwendung, sondern darauf, wie der Browser die Sicherheit unabhängig verwaltet.
Mit
dem Chrome-Prämienprogramm können Sicherheitsforscher beispielsweise
das Chrome- Sicherheitsteam kontaktieren, um entdeckte Schwachstellen zu melden. Wenn die Tatsache der Sicherheitsanfälligkeit bestätigt wird, wird ein Fix ausgegeben und in der Regel ein Sicherheitshinweis veröffentlicht, und der Forscher erhält eine (normalerweise finanzielle) Belohnung aus dem Programm.
Unternehmen wie Google haben viel Kapital in ihre Bug Bounty-Programme investiert, da dies es Unternehmen ermöglicht, viele Forscher anzuziehen, und ihnen finanzielle Vorteile verspricht, wenn sie Probleme mit der getesteten Software finden.
Jeder gewinnt das Bug Bounty-Programm: Der Anbieter schafft es, die Sicherheit seiner Software zu erhöhen, und die Forscher werden für ihre Ergebnisse bezahlt. Wir werden diese Programme später diskutieren, da ich glaube, dass die Initiativen von Bug Bounty einen separaten Abschnitt in der Sicherheitslandschaft verdienen.
Jake Archibald ist ein Google Advocate , der eine Sicherheitsanfälligkeit entdeckt hat, die mehrere Browser betrifft. Er dokumentierte seine Bemühungen, dies zu erkennen, den Prozess der Kontaktaufnahme mit verschiedenen von der Sicherheitsanfälligkeit betroffenen Anbietern und die Reaktion der Anbietervertreter in einem interessanten Blog-Beitrag , den Sie unbedingt lesen sollten.
Entwickler-Browser
Inzwischen sollten wir ein sehr einfaches, aber ziemlich wichtiges Konzept verstanden haben: Browser sind nur HTTP-Clients, die für einen „durchschnittlichen“ Internetbenutzer erstellt wurden.
Browser sind definitiv leistungsfähiger als ein einfacher HTTP-Client für jede Plattform (denken Sie beispielsweise daran, dass NodeJS
von 'http'
abhängig ist ), aber letztendlich sind sie „nur“ das Produkt der natürlichen Entwicklung einfacher HTTP-Clients.
Für Entwickler ist unser HTTP-Client wahrscheinlich
cURL von Daniel Stenberg, einem der beliebtesten Programme, die Webentwickler täglich verwenden. Es ermöglicht uns, einen HTTP-Austausch im laufenden Betrieb durchzuführen, indem wir eine HTTP-Anfrage über unsere Befehlszeile senden:
$ curl -I localhost:8080 HTTP/1.1 200 OK server: ecstatic-2.2.1 Content-Type: text/html etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" last-modified: Fri, 20 Jul 2018 11:20:35 GMT cache-control: max-age=3600 Date: Fri, 20 Jul 2018 11:21:02 GMT Connection: keep-alive
Im obigen Beispiel haben wir ein Dokument bei
localhost angefordert
: 8080 / , und der lokale Server hat es erfolgreich beantwortet.
Anstatt den Antworttext in die Befehlszeile zu entladen, haben wir das Flag
-I verwendet, das cURL mitteilt, dass wir nur an den Antwortheadern interessiert sind. Wenn wir noch einen Schritt weiter gehen, können wir dem Befehl cURL ein wenig mehr Informationen geben, einschließlich der tatsächlichen Anforderung, die er ausführt, damit wir den gesamten HTTP-Austausch besser untersuchen können. Die Option, die wir verwenden sollten:
-v (
ausführlich , mehr):
$ curl -I -v localhost:8080 * Rebuilt URL to: localhost:8080/ * Trying 127.0.0.1... * Connected to localhost (127.0.0.1) port 8080 (#0) > HEAD / HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK HTTP/1.1 200 OK < server: ecstatic-2.2.1 server: ecstatic-2.2.1 < Content-Type: text/html Content-Type: text/html < etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" < last-modified: Fri, 20 Jul 2018 11:20:35 GMT last-modified: Fri, 20 Jul 2018 11:20:35 GMT < cache-control: max-age=3600 cache-control: max-age=3600 < Date: Fri, 20 Jul 2018 11:25:55 GMT Date: Fri, 20 Jul 2018 11:25:55 GMT < Connection: keep-alive Connection: keep-alive < * Connection #0 to host localhost left intact
Ungefähr die gleichen Informationen sind in gängigen Browsern über ihre DevTools verfügbar.
Wie wir gesehen haben, sind Browser nichts anderes als anspruchsvolle HTTP-Clients. Natürlich fügen sie eine Vielzahl von Funktionen hinzu (z. B. Verwaltung von Anmeldeinformationen, Lesezeichen, Verlauf usw.), aber die Wahrheit ist, dass sie als HTTP-Clients für Menschen geboren wurden. Dies ist wichtig, da Sie in den meisten Fällen keinen Browser benötigen, um die Sicherheit Ihrer Webanwendung zu überprüfen, wenn Sie sie nur „rauchen“ und die Antwort anzeigen können.
Und das Letzte, was ich beachten möchte: Der
Browser kann alles sein. Wenn Sie eine mobile Anwendung haben, die APIs über HTTP verwendet, ist diese Anwendung Ihr Browser. Sie wird einfach von Ihnen in einer individuellen Reihenfolge konfiguriert, die nur einen bestimmten Typ von HTTP-Antworten (von Ihrer eigenen API) erkennt.
HTTP-Tauchen
Wie bereits erwähnt, werden wir die Phasen des
HTTP-Austauschs und
-Renderings am detailliertesten behandeln, da sie die größte Anzahl
von Angriffsvektoren für Angreifer bereitstellen.
Im
nächsten Artikel werden wir uns das HTTP-Protokoll genauer ansehen und versuchen zu verstehen, welche Maßnahmen wir ergreifen sollten, um die Sicherheit des HTTP-Austauschs zu gewährleisten.
Die Übersetzung wurde von EDISON Software , einem professionellen Website-Entwicklungsunternehmen für Großkunden, sowie von C # - und .NET-Webentwicklung unterstützt .