Die interne Struktur von Wörterbüchern in Python beschränkt sich nicht nur auf Bucket und privates Hashing. Dies ist eine erstaunliche Welt von gemeinsam genutzten Schlüsseln, Hash-Caching, DKIX_DUMMY und schnellen Vergleichen, die noch schneller durchgeführt werden können (auf Kosten eines Fehlers mit einer ungefähren Wahrscheinlichkeit von 2 ^ -64).
Wenn Sie die Anzahl der Elemente in dem gerade erstellten Wörterbuch nicht kennen, wie viel Speicher für jedes Element aufgewendet wird, warum das Wörterbuch jetzt (ab CPython 3.6) in zwei Arrays implementiert ist und wie es sich auf die Beibehaltung der Einfügereihenfolge bezieht, oder Sie haben die Präsentation von Raymond Hettinger „Modern Python Wörterbücher Ein Zusammenfluss von einem Dutzend großartiger Ideen. " Dann willkommen.
Personen, die mit der Vorlesung vertraut sind, finden jedoch auch einige Details und neue Informationen. Für Neulinge, die mit Bucket und Closed Hashing nicht vertraut sind, ist der Artikel ebenfalls interessant.
Wörterbücher in CPython sind überall, Klassen, globale Variablen, kwargs-Parameter basieren darauf. Der
Interpreter erstellt Tausende von Wörterbüchern , auch wenn Sie selbst Ihrem Skript keine geschweiften Klammern hinzugefügt haben. Um viele angewandte Probleme zu lösen, werden auch Wörterbücher verwendet. Es ist nicht verwunderlich, dass sich ihre Implementierung weiter verbessert und immer mehr zu verschiedenen Tricks wird.
Grundlegende Implementierung von Wörterbüchern (via Hashmap)
Wenn Sie mit der Funktionsweise von Standard-Hashmap und privatem Hashing vertraut sind, können Sie mit dem nächsten Kapitel fortfahren.
Die Idee, die den Wörterbüchern zugrunde liegt, ist einfach: Wenn wir ein Array haben, in dem Objekte derselben Größe gespeichert sind, erhalten wir leicht Zugriff auf das gewünschte Objekt, wenn wir den Index kennen.
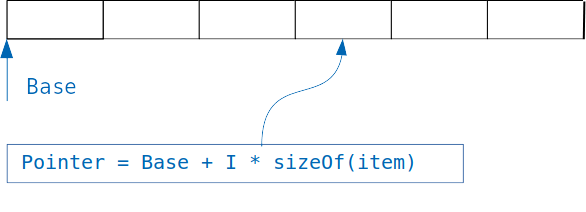
Wir fügen einfach einen Index multipliziert mit der Größe des Objekts zum Versatz des Arrays hinzu und erhalten die Adresse des gewünschten Objekts.
Was aber, wenn wir eine Suche nicht nach einem Ganzzahlindex, sondern nach einer Variablen eines anderen Typs organisieren möchten, um beispielsweise Benutzer an ihrer E-Mail-Adresse zu finden?
Bei einem einfachen Array müssen wir die E-Mails aller Benutzer im Array durchsuchen und mit der Suche vergleichen. Dieser Ansatz wird als lineare Suche bezeichnet und ist offensichtlich viel langsamer als der Zugriff auf das Objekt über den Index.
Die lineare Suche kann erheblich beschleunigt werden, wenn wir die Größe des Bereichs begrenzen, in dem Sie suchen möchten. Dies wird normalerweise erreicht, indem der Rest des
Hashs genommen wird . Das gesuchte Feld ist der Schlüssel.
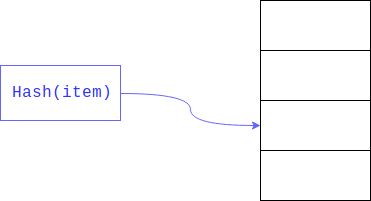
Infolgedessen wird eine lineare Suche nicht über das gesamte große Array, sondern entlang seines Teils durchgeführt.
Aber was ist, wenn dort bereits ein Element vorhanden ist? Dies könnte sehr gut passieren, da niemand garantiert hat, dass die Rückstände aus dem Teilen des Hashs eindeutig sind (wie der Hash selbst). In diesem Fall wird das Objekt am nächsten Index platziert. Wenn es beschäftigt ist, wird es um einen anderen Index verschoben und so weiter, bis es einen freien findet. Beim Abrufen eines Elements werden alle Schlüssel mit demselben Hash angezeigt.
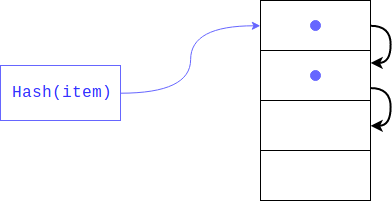
Diese Art von Hashing wird als privat bezeichnet. Wenn das Wörterbuch nur wenige freie Zellen enthält, droht eine solche Suche zu einer linearen zu degenerieren, sodass wir alle Gewinne verlieren, für die das Wörterbuch erstellt wurde. Um dies zu vermeiden, hält der Interpreter das Array 1/2 - 2/3 gefüllt. Wenn nicht genügend freie Zellen vorhanden sind, wird ein neues Array erstellt, das doppelt so groß ist wie das vorherige, und Elemente aus dem alten werden jeweils auf das neue übertragen.
Was tun, wenn der Artikel gelöscht wurde? In diesem Fall wird eine leere Zelle im Array gebildet und der Suchalgorithmus kann nicht nach Schlüssel unterscheiden. Diese Zelle ist leer, weil ein Element mit einem solchen Hash nicht im Wörterbuch enthalten war oder weil es gelöscht wurde. Um Datenverlust beim Löschen zu vermeiden, ist die Zelle mit einem speziellen Flag (DKIX_DUMMY) gekennzeichnet. Wenn dieses Flag während einer Elementsuche auftritt, wird die Suche fortgesetzt, die Zelle wird als beschäftigt betrachtet. Wenn sie eingefügt wird, wird die Zelle überschrieben.
Implementierungsfunktionen in Python
Jedes Element des Wörterbuchs muss einen Link zum Zielobjekt und zum Schlüssel enthalten. Der Schlüssel muss für die Kollisionsverarbeitung gespeichert werden, das Objekt - aus offensichtlichen Gründen. Da sowohl der Schlüssel als auch das Objekt einen beliebigen Typ und eine beliebige Größe haben können, können wir sie nicht direkt in der Struktur speichern, sie liegen im dynamischen Speicher und Verknüpfungen zu ihnen werden in der Struktur des Listenelements gespeichert. Das heißt, die Größe eines Elements muss der Mindestgröße von zwei Zeigern entsprechen (16 Byte auf 64-Bit-Systemen). Der Interpreter speichert jedoch auch den Hash. Dies geschieht, um ihn nicht bei jeder Vergrößerung des Wörterbuchs neu zu berechnen. Anstatt den Hash aus jedem Schlüssel auf eine neue Weise zu berechnen und den Rest der Division durch die Anzahl der Buckets zu nehmen, liest der Interpreter einfach den bereits gespeicherten Wert. Was aber, wenn das Schlüsselobjekt geändert wird? In diesem Fall muss der Hash neu berechnet werden und der gespeicherte Wert ist falsch? Eine solche Situation ist unmöglich, da veränderbare Typen keine Wörterbuchschlüssel sein können.
Die Struktur des Wörterbuchelements ist wie folgt definiert:
typedef struct { Py_hash_t me_hash;
Die Mindestgröße des Wörterbuchs wird durch die PyDict_MINSIZE-Konstante deklariert, die 8 beträgt. Die Entwickler haben entschieden, dass dies die optimale Größe ist, um unnötige Speicherverschwendung zum Speichern leerer Werte und Zeit für die dynamische Erweiterung des Arrays zu vermeiden. Daher haben Sie beim Erstellen eines Wörterbuchs (bis Version 3.6) mindestens 8 Elemente im Wörterbuch benötigt * 24 Byte in der Struktur = 192 Byte (dies berücksichtigt nicht die verbleibenden Felder: die Kosten der Wörterbuchvariablen selbst, den Zähler für die Anzahl der Elemente usw.)
Wörterbücher werden auch zum Implementieren von benutzerdefinierten Klassenfeldern verwendet. Mit Python können Sie die Anzahl der Attribute dynamisch ändern. Diese Dynamik erfordert keine zusätzlichen Kosten, da das Hinzufügen / Entfernen eines Attributs im Wesentlichen der entsprechenden Operation im Wörterbuch entspricht. Eine Minderheit der Programme verwendet diese Funktionalität, die meisten sind jedoch auf Felder beschränkt, die in __init__ deklariert sind. Jedes Objekt muss jedoch sein eigenes Wörterbuch mit seinen Schlüsseln und Hashes speichern, obwohl sie mit anderen Objekten übereinstimmen. Eine logische Verbesserung ist hier die Speicherung gemeinsam genutzter Schlüssel an nur einem Ort, genau das, was im
PEP 412 - Key-Sharing Dictionary implementiert wurde. Die Möglichkeit, das Wörterbuch dynamisch zu ändern, ist nicht verschwunden: Wenn die Reihenfolge oder die Anzahl der Schlüssel geändert wird, wird das Wörterbuch von den Teilungsschlüsseln in die regulären Schlüssel konvertiert.
Um Kollisionen zu vermeiden, beträgt das maximale „Laden“ des Wörterbuchs 2/3 der aktuellen Größe des Arrays.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Somit tritt die erste Erweiterung auf, wenn das 6. Element hinzugefügt wird.
Es stellt sich heraus, dass das Array während des Programmbetriebs ziemlich entladen ist, wobei die Hälfte bis ein Drittel der Zellen leer bleiben, was zu einem erhöhten Speicherverbrauch führt. Um diese Einschränkung zu umgehen und wenn möglich nur die erforderlichen Daten zu speichern, wurde eine neue
Ebene der Array-
Abstraktion hinzugefügt.
Anstatt ein spärliches Array zu speichern, zum Beispiel:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
Ab Version 3.6 sind die Wörterbücher wie folgt organisiert:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
Das heißt, Es werden nur die Datensätze gespeichert, die wirklich erforderlich sind. Sie werden in einem separaten Array aus der Hash-Tabelle entfernt, und nur die Indizes der entsprechenden Datensätze werden in der Hash-Tabelle gespeichert. Wenn das Array anfangs 192 Bytes benötigt hat, sind es jetzt nur noch 80 (3 * 24 Bytes für jeden Datensatz + 8 Bytes für Indizes). Kompression bei 58% erreicht. [2]
Die Größe eines Elements in Indizes ändert sich ebenfalls dynamisch. Anfangs entspricht sie einem Byte, dh das gesamte Array kann in einem Register abgelegt werden. Wenn der Index beginnt, in 8 Bit zu passen, erweitern sich die Elemente auf 16 und dann auf 32 Bit. Es gibt spezielle Konstanten DKIX_EMPTY und DKIX_DUMMY für leere bzw. gelöschte Elemente. Eine Indexerweiterung auf 16 Byte erfolgt, wenn das Wörterbuch mehr als 127 Elemente enthält.
Neue Objekte werden zu Einträgen hinzugefügt, dh wenn das Wörterbuch erweitert wird, müssen sie nicht verschoben werden. Sie müssen lediglich die Größe der Indizes erhöhen und sie mit Indizes überfüllen.
Beim Durchlaufen eines Wörterbuchs wird das Indexarray nicht benötigt, die Elemente werden nacheinander aus Einträgen zurückgegeben, weil Elemente werden jedes Mal am Ende von Einträgen hinzugefügt. Das Wörterbuch speichert automatisch die Reihenfolge des Auftretens von Elementen. Somit haben wir nicht nur den für die Speicherung des Wörterbuchs erforderlichen Speicher reduziert, sondern auch eine schnellere dynamische Erweiterung und Beibehaltung der Reihenfolge der Schlüssel erhalten. Das Reduzieren des Arbeitsspeichers ist an sich gut, kann aber gleichzeitig die Leistung steigern, da mehr Datensätze in den Prozessor-Cache gelangen.
CPython-Entwickler mochten diese Implementierung so sehr, dass Wörterbücher jetzt erforderlich sind, um die Einfügereihenfolge nach Spezifikation beizubehalten. Wenn früher die Reihenfolge der Wörterbücher bestimmt wurde, d.h. Es wurde streng durch einen Hash definiert und war von Anfang bis Anfang unverändert. Dann wurde ein wenig Zufälligkeit hinzugefügt, damit die Schlüssel jedes Mal anders werden. Jetzt müssen die Wörterbuchschlüssel die Reihenfolge beibehalten. Wie viel dies notwendig war und was zu tun ist, wenn eine noch effektivere Implementierung des Wörterbuchs erscheint, aber die Einfügereihenfolge nicht beibehält, ist unklar.
Es gab jedoch Anforderungen, einen Mechanismus zum Beibehalten der Deklaration von Attributen in
Klassen und in
kwargs zu implementieren, und diese Implementierung ermöglicht es Ihnen, diese Probleme ohne spezielle Mechanismen zu schließen.
So sieht es im
CPython-Code aus :
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
Die Iteration ist jedoch komplizierter als Sie zunächst vielleicht denken. Es gibt zusätzliche Überprüfungsmechanismen, bei denen das Wörterbuch während der Iteration nicht geändert wurde. Eine davon ist eine 64-Bit-
Version des Wörterbuchs , in der jedes Wörterbuch gespeichert ist.
Schließlich betrachten wir den Mechanismus zur Lösung von Kollisionen. Die Sache ist, dass in Python Hash-Werte leicht vorhersehbar sind:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
Und da beim Erstellen eines Wörterbuchs aus diesen Hashes der Rest der Division verwendet wird, bestimmen sie tatsächlich, in welchen Bucket der Datensatz verschoben wird, nur die letzten paar Bits des Schlüssels (wenn es sich um eine Ganzzahl handelt). Sie können sich eine Situation vorstellen, in der viele Objekte in benachbarte Eimer gelangen möchten. In diesem Fall müssen Sie viele Objekte betrachten, die bei der Suche nicht am richtigen Ort sind. Um die Anzahl der Kollisionen zu verringern und die Anzahl der Bits zu erhöhen, die bestimmen, in welchen Bucket der Datensatz gehen soll, wurde der folgende Mechanismus implementiert:
Störung ist eine ganzzahlige Variable, die durch einen Hash initialisiert wird. Es ist zu beachten, dass bei einer großen Anzahl von Kollisionen dieser auf Null zurückgesetzt wird und der folgende Index nach der Formel berechnet wird:
j = (5 * j + 1) % n
Beim Extrahieren eines Elements aus dem Wörterbuch wird dieselbe Suche durchgeführt: Der Index des Steckplatzes, in dem sich das Element befinden soll, wird berechnet. Wenn der Steckplatz leer ist, wird die Ausnahme "Wert nicht gefunden" ausgelöst. Wenn sich in diesem Steckplatz ein Wert befindet, müssen Sie überprüfen, ob der Schlüssel mit dem gesuchten übereinstimmt. Dies ist möglicherweise nicht möglich, wenn eine Kollision auftritt. Der Schlüssel kann jedoch fast jedes Objekt sein, einschließlich eines Objekts, für das der Vergleichsvorgang viel Zeit in Anspruch nimmt. Um einen langen Vergleichsvorgang zu vermeiden, werden in Python verschiedene Tricks verwendet:
Zunächst werden Zeiger verglichen. Wenn der Schlüsselzeiger des gewünschten Objekts gleich dem Zeiger des gesuchten Objekts ist, dh auf denselben Speicherbereich zeigt, gibt der Vergleich sofort true zurück. Das ist aber noch nicht alles. Wie Sie wissen, müssen gleiche Objekte gleiche Hashes haben, was bedeutet, dass Objekte mit unterschiedlichen Hashes nicht gleich sind. Nach dem Überprüfen der Zeiger werden Hashes überprüft. Wenn sie nicht gleich sind, wird false zurückgegeben. Und nur wenn die Hashes gleich sind, wird ein ehrlicher Vergleich aufgerufen.
Wie hoch ist die Wahrscheinlichkeit eines solchen Ergebnisses? Bei 2 ^ -64 können Sie natürlich aufgrund der einfachen Vorhersagbarkeit des Hash-Werts ein solches Beispiel leicht aufgreifen, aber in Wirklichkeit kommt diese Überprüfung nicht oft auf wie viel? Raymond Hettinger stellte den Interpreter zusammen, indem er die letzte Vergleichsoperation mit einer einfachen Rückgabe true änderte. Das heißt, Der Interpreter betrachtet Objekte als gleich, wenn ihre Hashes gleich sind. Dann setzte er automatisierte Tests vieler populärer Projekte auf diesem Dolmetscher durch, die erfolgreich endeten. Es mag seltsam erscheinen, Objekte mit gleichen Hashes als gleich zu betrachten, ihren Inhalt nicht zusätzlich zu überprüfen und sich ausschließlich auf den Hash zu verlassen, aber Sie tun dies regelmäßig, wenn Sie die Git- oder Torrent-Protokolle verwenden. Sie betrachten Dateien (Dateiblöcke) als gleich, wenn ihre Hashes gleich sind, was durchaus zu Fehlern führen kann. Ihre Ersteller (und wir alle) hoffen jedoch, dass es erwähnenswert ist, dass die Wahrscheinlichkeit einer Kollision äußerst gering ist.
Jetzt sollten Sie endlich die Struktur des Wörterbuchs verstehen, die so aussieht:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
Zukünftige Änderungen
Im vorherigen Kapitel haben wir uns überlegt, was bereits implementiert wurde und von jedem in seiner Arbeit verwendet werden kann. Die Verbesserungen beschränken sich jedoch natürlich nicht auf: Pläne für Version 3.8 enthalten
Unterstützung für umgekehrte Wörterbücher . In der Tat verhindert nichts, anstatt vom Anfang eines Arrays von Elementen zu iterieren und Indizes zu erhöhen, beginnend mit dem Ende und abnehmenden Indizes.
Zusätzliche Materialien
Für ein tieferes Eintauchen in das Thema wird empfohlen, sich mit den folgenden Materialien vertraut zu machen:
- Aufzeichnung des Berichts am Anfang des Artikels
- Vorschlag für eine neue Wörterbuchimplementierung
- Wörterbuch-Quellcode in CPython