Wir möchten die Geschichte teilen, die bei einem unserer Projekte für das neue Jahr passiert ist. Das Wesentliche des Projekts ist, dass es die Arbeit von Ärzten in medizinischen Einrichtungen automatisiert. Während des Besuchs des Patienten schreibt der Arzt Informationen in den Rekorder, dann wird das Audio transkribiert. Nach dem Transkriptionsprozess - d.h. Umwandlung der Audioaufzeichnung in Text - Ein medizinisches Dokument wird gemäß den einschlägigen Standards erstellt und an die Klinik zurückgesandt, von der die Audioaufzeichnung stammt, wo der sendende Arzt sie empfängt, prüft und genehmigt. Nach bestandener Pflichtprüfung wird das Dokument an die endgültigen Patienten gesendet.
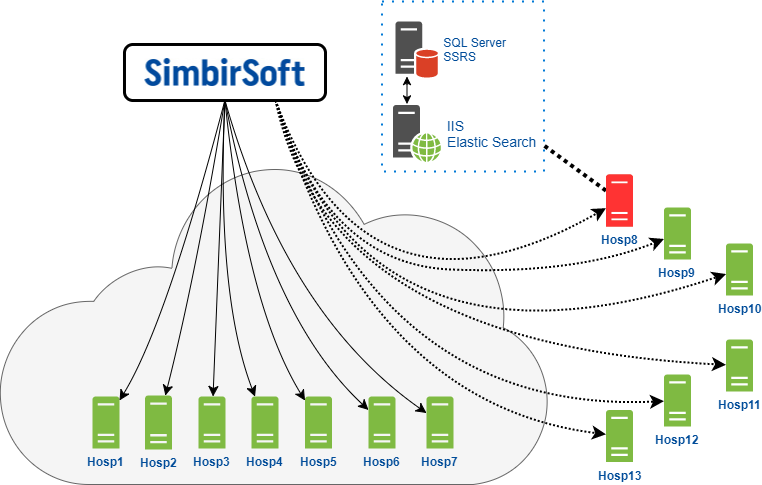
Alle medizinischen Einrichtungen, die das Produkt verwenden, können bedingt in zwei große Gruppen unterteilt werden:
- Hosting im Rechenzentrum unseres Kunden, das für die Leistung der Anwendung sowohl für die Software als auch für die Hardware voll verantwortlich ist. Zum Beispiel, wenn der Speicherplatz knapp wird oder die Serverleistung auf der CPU nicht ausreicht.
- Selbst gehostet: Sie platzieren alle Geräte direkt zu Hause und sind selbst für deren Leistung verantwortlich. Unser Kunde stellt ihnen die Anwendung und deren Unterstützung zur Verfügung.
Auf diese Weise interagiert unser Team mit Endservern, die direkt in der Cloud unseres Kunden gehostet werden.

Wir haben Zugriff auf diese Server, um alle geplanten Arbeiten und Wartungen durchzuführen, die erforderlich sind.
Die zweite Gruppe - selbst gehostete Clients - für sie fungiert die Client-Cloud als Gateway, über das wir eine Verbindung zu diesen Servern herstellen. In diesem Fall haben wir eingeschränkte Rechte. Oft können wir aufgrund von Sicherheitseinstellungen keine Vorgänge ausführen. Wir stellen eine Verbindung zu den Servern über RDP her, das Remotedesktopprotokoll unter Windows. Das alles funktioniert natürlich über ein VPN.
Es ist zu beachten, dass jeder im Diagramm dargestellte Server tatsächlich eine Kombination aus einem Anwendungsserver und einem Datenbankserver ist. Auf dem Datenbankserver sind jeweils das MS SQL Server-DBMS und der SSRS-Berichtsdienst installiert. Darüber hinaus ist die Version von MSSQL Server in allen Kliniken unterschiedlich: 2008, 2012, 2014. Zusätzlich zu den Versionen selbst werden überall verschiedene Service Packs und Patches installiert. Im Allgemeinen ein kompletter Zoo.
Auf dem Anwendungsserver haben wir den IIS- und ElasticSearch-Webserver installiert. ElasticSearch ist eine Suchmaschine, die auch die Volltextsuche implementiert.
Das Wesentliche an unserem Produkt ist „Job“. Arbeit ist eine abstrakte Einheit, die alle Informationen miteinander verknüpft, die sich auf die Aufnahme eines bestimmten Patienten beziehen. Diese Informationen umfassen:
- Daten über den Arzt;
- Patientendaten;
- Daten über den Besuch;
- Audiodatei (Rede des Arztes);
- Dokumente (mehrere Versionen);
- Arbeitsverarbeitungsgeschichte;
- Brancheninformationen usw.
Dieses Diagramm zeigt ein vereinfachtes Datenbankschema, anhand dessen Sie die Beziehungen zwischen den Haupttabellen sehen können. Dies ist nur der grundlegende Teil, tatsächlich hat die Datenbank mehr als 200 Tabellen.

Ein wenig über die Klinik, in der sich der Vorfall ereignete:
- 1500-2000 Arbeiten pro Tag;
- 1000+ aktive Benutzer (Ärzte + Sekretäre);
- Selbst gehostet.
DB:
- Größe: 800+ Gb (750K + Werke, 2M + Dokumente);
- DBMS: MS SQL Server 2008 R2;
- Wiederherstellungsmodell: Einfach.
Hier möchte ich eine kleine Erklärung geben. In SQL Server gibt es drei Wiederherstellungsmodelle: einfach, massenprotokolliert und vollständig. Ich werde jetzt nicht über den dritten sprechen, ich werde den ersten und zweiten erklären. Der Hauptunterschied besteht darin, dass im einfachen Modell der Transaktionsverlauf nicht im Protokoll gespeichert wird. Sobald die Transaktion festgeschrieben wurde, wird der Datensatz aus dem Transaktionsprotokoll gelöscht. Bei Verwendung des vollständigen Wiederherstellungsmodus wird der gesamte Verlauf der Datenänderungen in einem Transaktionsprotokoll gespeichert. Was gibt uns das? In einem unvorhergesehenen Fall können wir, wenn wir die Datenbank von Sicherungen zurücksetzen müssen, nicht nur zu einer bestimmten Sicherung zurückkehren, sondern zu jedem Zeitpunkt bis zu einer bestimmten Transaktion, d. H. Wir haben sie gespeichert Bei Sicherungen gibt es nicht nur einen bestimmten Status der Datenbank zum Zeitpunkt der Sicherung, sondern auch eine ganze Historie von Datenänderungen.
Ich denke, es lohnt sich nicht zu erklären, dass der einfache Modus nur in der Entwicklung, auf Testservern und in der Produktion verwendet wird. Auf keinen Fall.
Aber die Klinik hatte offenbar ihre eigenen Gedanken zu diesem Thema;)
Starten Sie
Ein paar Tage später, dem neuen Jahr, bereiten sich alle auf den Urlaub vor, kaufen Geschenke, schmücken Weihnachtsbäume, verbringen Firmenfeiern und warten auf ein langes Wochenende.
22. Dezember (Freitag) 1 Tag
14:31 Der Kunde sagte, dass er den nächsten Tagesbericht nicht erhalten habe. Der Bericht kommt zweimal täglich nach einem Zeitplan per E-Mail an. Er muss das Senden von Daten an ein externes Integrationssystem steuern, was nicht allzu kritisch ist.
Es kann mehrere Gründe geben:
- Probleme mit SMTP, Briefe wurden einfach nicht zugestellt (sie haben beispielsweise das Passwort geändert und niemandem davon erzählt);
- Probleme auf der Serverseite der Berichte;
- Es ist etwas mit der Datenbank passiert.
16:03 Die Klinik ändert manchmal das Passwort in SMTP, ohne dass jemand darüber gewarnt wird. Nachdem wir die aktuellen Aufgaben erledigt haben, überprüfen wir den Bericht ruhig manuell, indem wir ihn über die Weboberfläche starten. Es wird ein Fehler angezeigt, der auf Probleme in der Datenbank hinweist.
Ein Beispiel für den Fehler, den wir beim Starten des Berichts erhalten haben.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
Dies zeigt an, dass die Datenbank Seiten beschädigt hat. Wir hatten ein leichtes Gefühl der Angst.
20:53 Um das Ausmaß des Schadens zu beurteilen, führen wir eine Datenbankprüfung mit dem speziellen Befehl
DBCC CHECKDB durch . Abhängig von der Größe des Schadens kann der Testbefehl eine Weile dauern, daher führen wir den Befehl nachts aus. Hier haben wir Glück, dass dies am Freitagnachmittag passiert ist, das heißt, wir hatten zumindest alle freien Tage, um dieses Problem zu lösen.
In diesem Moment war die Situation wie folgt:
23. Dezember (Samstag) 2. Tag
10:02 Uhr morgens stellen wir fest, dass das Überprüfen der Datenbank mit CHECKDB eine Diskette ist - dies lag an einem Mangel an freiem Speicherplatz, weil Während des Überprüfungsprozesses wird die temporäre Tempdb-Datenbank aktiv verwendet, und irgendwann ist der freie Speicherplatz einfach aufgebraucht.
Daher entscheiden wir uns, anstatt die gesamte Datenbank zu überprüfen, sofort einen Tabellenscan zu starten. Verwenden
Sie dazu den Befehl DBCC CHECKTABLE .
10:46 Wir beschließen, mit der JobHistory-Tabelle zu beginnen, die wahrscheinlich beschädigt ist, da sie zum Generieren des Berichts verwendet wurde. Diese Tabelle bewahrt, wie der Name schon sagt, die Geschichte aller Werke, d. H. Übergänge der Arbeit zwischen Stufen.
Führen Sie
DBCC CHECKTABLE ('dbo.JobHistory') aus .
Durch Überprüfen dieser Tabelle werden beschädigte Tabellen in der Datenbank angezeigt, was im Prinzip erwartet wurde.
12:00 Im Moment, wenn die Datenbank das vollständige Wiederherstellungsmodell verwendet, könnten wir die beschädigten Seiten aus der Sicherung wiederherstellen, und das wäre alles vorbei, aber unsere Datenbank befand sich im einfachen Modus. Daher bleibt die einzige Möglichkeit, Schäden zu reparieren, der Start desselben Befehls mit dem speziellen Parameter
REPAIR_ALLOW_DATA_LOSS . Dies kann zu Datenverlust führen.
Wir fangen an. Die Überprüfung endet erneut mit einem Fehler. Wir erhalten die Fehlermeldung, dass die Wiederherstellung dieser Tabelle erst möglich ist, wenn die zugehörigen Tabellen wiederhergestellt sind. Die Verlaufstabelle bezieht sich auf die Arbeitstabelle (Jobs) des Fremdschlüssels. Daher schließen wir, dass auch die Hauptarbeitstabelle (Jobs) beschädigt ist.
13:30 Der nächste Schritt besteht darin, gleichzeitig die Jobs-Tabelle zu überprüfen. Wir hoffen, dass der Schaden im Index und nicht in den Daten enthalten ist. In diesem Fall reicht es aus, den Index für die Datenwiederherstellung einfach neu zu erstellen.
17:33 Nach einer Weile stellen wir fest, dass unser Server über RDP nicht verfügbar ist. Es wurde wahrscheinlich ausgeschaltet, die Überprüfung wurde nicht abgeschlossen, die Arbeit wurde ausgesetzt. Wir informieren die Klinik, dass der Server nicht verfügbar ist. Bitte erhöhen Sie ihn.
Leichte Angst nimmt sehr spezifische Formen an.
24. Dezember (Sonntag) 3. Tag
14:31 Näher am Abendessen wird der Server angehoben, und wir führen die Überprüfung der Jobs-Tabelle erneut durch.
DBCC CHECKTABLE ('dbo.Jobs')16:05 Die Überprüfung ist nicht abgeschlossen, der Server ist nicht verfügbar. Wieder.
Nach einiger Zeit ist der Server wieder nicht verfügbar, bevor wir die Überprüfung der Tabelle abgeschlossen haben. Zu diesem Zeitpunkt führt der IT-Service der Klinik eine Reihe von Serverprüfungen durch. Wir warten auf den Abschluss der Arbeiten.
Aufgrund der Feiertage war die Kommunikation zwischen uns und dem Kunden langsam - wir erwarteten mehrere Stunden lang Antworten auf Fragen.
25. Dezember (Montag - Weihnachten) 4. Tag
16:00 Am nächsten Tag, an dem der Server hochgefahren wurde, hat der Client Weihnachten und wir beginnen erneut mit der Überprüfung der Tabelle. Diesmal schließen wir jedoch Indizes vom Scan aus und lassen nur die Datenprüfung. Und nach einiger Zeit ist der Server wieder nicht verfügbar.
Was ist los?
In diesem Moment schleichen sich Gedanken ein, dass dies nicht nur ein Zufall ist, und es besteht der Verdacht, dass es sich um eine Beschädigung auf Eisenebene handeln könnte (eine Festplatte ist gefallen). Wir gehen davon aus, dass sich fehlerhafte Sektoren auf der Festplatte befinden. Wenn der Scan versucht, Daten aus diesen Sektoren zu lesen, stürzt das System ab. Wir informieren unseren Kunden über unsere Annahme.
Der Client führt eine Festplattenprüfung auf dem Hostcomputer durch.
17:19 Der IT-Service der Klinik hat gemeldet, dass die Datei der virtuellen Maschine beschädigt ist - das ist schlecht! (
Wir können noch nicht arbeiten und warten auf ein Signal, wenn sie das Problem beheben, und wir können unsere Arbeit fortsetzen.
26. Dezember (Dienstag) Tag 5
14:05 Der IT-Klinikdienst startet einen weiteren Prozess zur Wiederherstellung von Datenträgern. Uns wurde gesagt, dass wir CHECKTABLE parallel ausführen können, um die Tabelle zu überprüfen. Wir starten den Test erneut - die virtuelle Maschine stürzt erneut ab, wir informieren den Client, dass die Datei der virtuellen Maschine immer noch beschädigt ist.
Heutzutage ist die gesamte Kommunikation mit dem Kunden sehr langsam, mit einer enormen Zeitverzögerung aufgrund der Feiertage.
27. Dezember (Mittwoch) Tag 6
14:00 Wir starten die Festplattenprüfung unter Windows -
checkdisk in der virtuellen Maschine - es wurden keine Probleme festgestellt.
Die Datenbank befindet sich im einfachen Modus, sodass die Wahrscheinlichkeit, die aktuelle Datenbank mit den DBMS-Tools zu reparieren, auf Null sinkt, da Wir können einzelne beschädigte Seiten nicht wiederherstellen.
Wir fangen an, die Option eines Rollbacks und der Wiederherstellung der Datenbank aus der Sicherung in Betracht zu ziehen.
Wir überprüfen die Datenbanksicherungen und stellen fest, dass die Sicherungen nicht mit den DBMS-Mitteln erstellt wurden. Die letzte Sicherung erfolgte im Jahr 2014, d. H. Es gibt keine Sicherungen der Datenbank. Warum sie dies nicht getan haben, ist ein separates Problem. Es liegt in der Verantwortung der Klinik, die Effizienz und Sicherheit der Datenbank sicherzustellen.
Es besteht eine hohe Wahrscheinlichkeit, dass die Wiederherstellung der aktuellen Datenbank nicht funktioniert. Wir beginnen, andere Optionen für das Rollback in Betracht zu ziehen.
Lassen Sie uns die Situation mit Backups in der Klinik genauer untersuchen.
Die Situation mit Backups:
- Es gibt keine Datenbanksicherungen (!!!)
- Es gibt keine Schnappschüsse der virtuellen Maschine (!?)
- Es gibt jedoch Festplattensicherungen (full + inc)
Die Datenbank befindet sich auf Datenträger D. Sie haben wöchentliche vollständige Sicherungen und tägliche inkrementelle Sicherungen durchgeführt.
- jeden Freitag um 20:00 Uhr vollständige Sicherung
- jeden Tag inkrementelle Sicherung
- Es gibt eine vollständige Sicherung vom 15. und 22 ..
- Es gibt tägliche Backups bis zum 21 ..
Das heißt, Im Prinzip können wir auf den Zustand zurücksetzen, bevor das Problem auftritt.
Wir warten auf ein Update von der Klinik, um das Rollback der Datenbank aus dem Backup zu starten.
Gleichzeitig schickte die Klinik eine Anfrage an den Eisenlieferanten (HP), die als „dringend“ gekennzeichnet war.
28. Dezember (Donnerstag) Tag 7
13:13 Der IT-Service der Klinik beginnt mit der Einrichtung einer neuen virtuellen Maschine Es ist nicht möglich, den Schaden in der Datei der alten virtuellen Maschine zu beheben.
19:09 Eine neue virtuelle
Maschine ist mit installiertem SQL Server verfügbar.
Der nächste Schritt besteht darin, die Datenbank aus der Festplattensicherung wiederherzustellen. Zunächst beschließen wir, zum 22. Tag zurückzukehren, wenn das Problem weiterhin besteht, und dann zum 21., 20. usw. zurückzukehren, bis wir zu einem funktionierenden Zustand gelangen.
Es war der 28. Tag auf dem Hof, wir waren auf der Firmenfeier und hier erfahren sie, dass die Klinik Probleme mit der Wiederherstellung von Backups hat, weil BACKUPs LEER sind!
Hier sind die Neuigkeiten!
Wenn Sie eine Sicherung von Laufwerk D ab dem 21. wiederherstellen, stellt sich heraus, dass es wie alle anderen leer ist. Es werden direkte Shredder-Backups erhalten - sie scheinen vorhanden zu sein, sind es aber gleichzeitig nicht. Es ist nicht ganz klar, wie dies überhaupt passiert ist, aber soweit wir verstehen konnten, ist der Punkt nicht genügend Speicherplatz zum Speichern von Festplattensicherungen. Sie haben 500 GB Backups für die Speicherung zugewiesen, aber zum Zeitpunkt des Vorfalls wog die Datenbank bereits 800 GB, sodass die Sicherung im Prinzip nicht erfolgreich sein konnte. Das heißt, Backups wurden regelmäßig gemäß dem Zeitplan erstellt, aber aufgrund von Platzmangel endeten sie mit einem Fehler und waren dementsprechend leer, und der IT-Service der Klinik hatte nicht einmal die Idee, zu überprüfen, ob alles in Ordnung mit ihnen war. Nicht so.
29. Dezember (Freitag) Tag 8
13:11 Diskussion weiterer Aktionen. Mögliche Optionen:
- Beim Versuch, Datenbankdateien (.ldf + .two-Dateien) zu kopieren, sind die Erfolgschancen sehr gering.
- Der Versuch, die Datenbank zu sichern, ist wiederum sehr unwahrscheinlich.
- Replikation konfigurieren - funktioniert möglicherweise.
Auf dem neuen Server wurde ein 1-TB-Laufwerk zugewiesen, was offensichtlich nicht ausreicht, wenn wir versuchen, von diesem Server aus zu sichern und wiederherzustellen Im schlimmsten Fall nehmen Sicherungen ohne Komprimierung so viel Speicherplatz ein wie die ursprüngliche Datenbank, d. h. 800 GB.
Bitte fügen Sie Orte auf dem neuen Server hinzu und fahren Sie mit dem Kopieren der Datenbankdateien fort.
Auf dem neuen Server wurde eine Datenbank erstellt und das Datenbankschema wiederhergestellt - dies ermöglicht zumindest die Verarbeitung neuer Arbeiten. Die Klinik wird zumindest in der Lage sein, neue Patienten mit einem solchen System aufzunehmen.
14:36 Daher fahren wir mit Option Nummer eins fort, obwohl wir nicht viel Erfolg erwarten.
Stoppen Sie SQL Server, kopieren Sie die Datendatei (mdf) und das Protokoll (ldf).
16:13 Nach der Hälfte der Protokolldatei wurde sie erfolgreich kopiert (48 GB), und 50 GB der Datendatei wurden bereits kopiert (795 von 846 GB übrig). Bei dieser Geschwindigkeit dauert es ungefähr 12 Stunden, bis die Kopie fertig ist.
16:30 Der alte Datenbankserver wurde beim Kopieren der Datei ausgeschaltet, was durchaus zu erwarten ist.
17:09 Daher fahren wir mit der nächsten Option fort - dem Einrichten der Replikation, während wir angeben können, welche Daten repliziert werden sollen. Das heißt, wir können zuerst absichtlich beschädigte Tabellen ausschließen und zuerst die unbeschädigten Daten kopieren und dann die problematischen Tabellen in Teilen übertragen. Leider funktioniert diese Option auch nicht, da wir aufgrund von Datenbankbeschädigungen nicht einmal eine Publikation mit bestimmten Tabellen erstellen können.
Wir erwägen auch Datenübertragungsoptionen.
20:01 Infolgedessen beginnen wir einfach, Daten vom alten auf den neuen Server zu übertragen, indem wir sie in Prioritätsreihenfolge importieren und exportieren.
21:35 Zuerst die kritischsten Daten, dann archiviert und weniger kritisch (~ 300 GB). In der ersten Exportwelle blieben weniger als 300 GB Daten übrig. Die Dokumententabelle (300 GB) ist ebenfalls ausgeschlossen. Wir beginnen nachts mit dem Kopieren.
30. Dezember (Samstag) Tag 9
15:00 Wir übertragen weiterhin Daten. Die Jobs-Tabelle ist überhaupt nicht verfügbar. Die meisten Tabellen wurden zu diesem Zeitpunkt kopiert.
Aber ohne
Jobs ist alles nutzlos, da es die Hauptverbindung zwischen allen Daten darstellt und ihnen aus geschäftlicher Sicht Bedeutung und Wert verleiht. Ohne sie haben wir nur einen unterschiedlichen Datensatz, den wir einfach nicht verwenden können.
Zu diesem Zeitpunkt ist auch die Wiederherstellung des Datenbankschemas abgeschlossen.
Die Folgen des Vorfalls:Zu diesem Zeitpunkt haben wir einen großen Verlust an Live-Daten.
Das heißt, Formal haben wir einige Daten in der Datenbank, aber tatsächlich gibt es keine Möglichkeit, sie zu verwenden oder zu verbinden, sodass wir über den vollständigen Datenverlust sprechen können.
Datenverlust bei mehr als 750.000 Patientenaufnahmen.
Das ist wirklich traurig!
- Dies ist ein schwerer Schlag für den Ruf unserer Kunden, der sich als große Probleme für sie im Geschäftsleben herausstellen kann, wenn sie neue Verträge abschließen und neue Kunden finden.
- Der Verlust so vieler Daten für die Klinik kann zu ernsthaften Problemen und Geldstrafen führen, weil Dies sind vertrauliche Daten, die medizinische Vertraulichkeit enthalten und im wahrsten Sinne des Wortes vom Leben der Menschen abhängen.
Wir begannen zu überlegen, was wir in dieser Situation tun können. Sie begannen, das System nach Knochen zu sortieren, um Hinweise zu finden.
15:16 Wenn wir alle Aspekte des Systems analysieren, verstehen wir, dass wir versuchen können, die fehlenden Daten aus dem ElasticSearch-Index zu extrahieren. Die Sache ist, dass aufgrund der falschen Konfiguration der ElasticSearch-Indizes nicht nur die Felder gespeichert werden, in denen die Volltextsuche durchgeführt wird, sondern im Allgemeinen alles, dh tatsächlich eine vollständige Kopie der Daten, und wir können theoretisch Daten daraus extrahieren über Werke und legen Sie sie zurück in unsere Datenbank. Es ist zu hoffen, dass die Daten weiterhin wiederhergestellt werden können.
Ein Fehler, dem Sie ein Denkmal setzen können!
 18:00
18:00 Ein Dienstprogramm wurde schnell geschrieben, um die Daten zu extrahieren. Nach einigen Stunden stellen wir sicher, dass der Ansatz funktioniert und die Daten wiederhergestellt werden können.
20:00 Die Wiederherstellung der Arbeit von ElasticSearch mit Hilfe eines schriftlichen Dienstprogramms hat begonnen. Der Ansatz hat funktioniert, wir können die Daten auf der Arbeit wiederherstellen. Parallel dazu extrahieren wir für jede Arbeit die neuesten Versionen des Dokuments.
31. Dezember (Sonntag - Neujahr) Tag 10
14:09 In der Nacht wurden 188 811 Werke restauriert.
20:13 Angesichts unseres Erfolgs beschließt die Klinik, die Übertragung des Servers an den HP Service zu verschieben, um uns Zeit zu geben, die maximalen Daten vom alten Server zu extrahieren.
Mit solchen Neuigkeiten haben wir das neue Jahr gefeiert))
01. Januar (Montag) 11. Tag
11:23 Vorbereitung zum Starten des Systems nach dem Vorfall:
- IIS auf dem App-Server neu konfiguriert;
- alle erforderlichen Dienste für die Arbeit mit dem neuen Datenbankserver neu konfiguriert;
- Trigger, gespeicherte Prozeduren, wiederhergestellte Funktionen.
14:28 Dann begannen sie, die Tabelle der Dokumente zu kopieren, die aufgrund der Größe bei der ersten Übertragung übersprungen wurde.
- Der alte DB-Server wird wieder heruntergefahren. Offensichtlich ist auch die Tabelle "Dokumente" beschädigt. Damit werden alle Patienteninformationen gespeichert. Glücklicherweise ist es nicht vollständig beschädigt, wir können Anfragen an es stellen, und wenn eine Anfrage an uns einen beschädigten Datensatz zurückgibt, stürzt der Server in diesem Moment ab und fährt herunter. Wir können einige der Daten extrahieren.
Dementsprechend signalisieren wir dem Client, dass er den Server anhebt, und bereiten gleichzeitig die neue Datenbank für den Start des Systems vor.
18:01 Wiederherstellung aller Integritätsbeschränkungen nach der Übertragung des Hauptteils der Daten.
22:02 Wiederherstellung der Einschränkungen abgeschlossen. Wir haben einfach die Rohdaten maximal übertragen. Das Vorhandensein von Integritätsbeschränkungen würde unsere Aufgabe erheblich erschweren.
02. Januar (Dienstag) Tag 12
05:52 Der alte DB-Server wurde beim Kopieren des Dokuments wieder ausgeschaltet. Er wird umgehend erzogen, damit wir weiterarbeiten können.
09:00 Es konnten ca. 200.000 Dokumente stapelweise wiederhergestellt werden (ca. 20%).
Wir haben verschiedene Wiederherstellungsmethoden verwendet: Sortieren nach verschiedenen Spalten, um Daten vom Ende oder Anfang der Tabelle zu erhalten, bis wir auf einen beschädigten Teil der Tabelle stoßen.
13:42 Beginn des Kopierens von Archivierungsarbeiten in der Tabelle - zum Glück ist es nicht beschädigt.
17:08 Alle Archivarbeiten wurden wiederhergestellt (491 380 Stück).
Das System ist startbereit: Benutzer können neue Arbeiten erstellen und verarbeiten.
Leider können Sie aufgrund einer teilweisen Beschädigung der Dokumententabelle nicht einfach alle Daten von ihr übertragen, wie bei anderen Tabellen, weil Der Tisch ist teilweise beschädigt. Wenn Sie versuchen, alle Daten abzurufen, stürzt die Anforderung daher ab, wenn Sie versuchen, beschädigte Seiten zu lesen. Daher extrahieren wir die Daten punktweise mit verschiedenen Sortierungen und Stichprobengrößen:
- Sortieren nach verschiedenen Feldern (ID, DateTime);
- Sortieren Sie aufsteigend, absteigend;
- Arbeiten Sie mit kleinen Gruppen von Linien (1000, 100);
- Jobs nach ID abrufen.
03. Januar (Mittwoch) Tag 13
08:58 Fortsetzung des Prozesses zum Wiederherstellen von Dokumenten. Dokumente wurden nur für aktive, unvollständige Arbeiten wiederhergestellt. Zu diesem Zeitpunkt arbeiten 1000 (aktiv) ohne Dokumente.
11:38 Alle SQL-Jobs wurden migriert
13:17 5 funktioniert ohne Dokumente, 231 keine Arbeit, aber es gibt eine Audiodatei, die Sie neu synchronisieren müssen.
04. Januar (Donnerstag) Tag 14
Die manuelle Wiederherstellung und Überprüfung der verbleibenden Arbeiten hat begonnen.
Das System arbeitet und überwacht und behebt Fehler online.
05. Januar (Freitag) Tag 15
Bericht Migration zu SSRS geplant.
Eine Übertragung auf einen neuen Server ist nicht möglich, da Die Klinik hat eine ältere Version von SQL Server installiert und es funktioniert nicht, die Datenbank vom alten Server zu übertragen.
Optionen:
- Aktualisieren Sie SQL Server von 2008 auf 2008 R2.
- Konfigurieren Sie alles von Grund auf neu.
Es wurde beschlossen, auf das SQL Server-Update zu warten.
09:21 Hintergrund Die Wiederherstellung von Dokumenten für abgeschlossene Arbeiten hat begonnen - der Prozess ist lang und wird mehrere Tage dauern.
13:28 Änderung der Priorität der Wiederherstellung von Dokumenten durch Abteilungen.
18:18 Die Klinik gewährte Zugriff auf SMTP, Mail-Setup
Ergebnis:
- Fast alle Daten wurden wiederhergestellt (nur 5 Jobs gingen verloren);
- Es wurden Empfehlungen zur Datenbankwartung herausgegeben, um solche Situationen zu verhindern.
- Datenbanksicherungen werden mit SQL Server konfiguriert.
- Zusätzliche Überwachung von Backups unsererseits, Warnungen im Fehlerfall.