
Täglich finden in Badoo 17 Milliarden Veranstaltungen, 60 Millionen Benutzersitzungen und eine Vielzahl virtueller Termine statt. Jedes Ereignis wird übersichtlich in relationalen Datenbanken gespeichert und anschließend in SQL und darüber hinaus analysiert.
Moderne verteilte Transaktionsdatenbanken mit Dutzenden von Terabyte Daten - ein wahres Wunder der Technik. SQL als Verkörperung der relationalen Algebra in den meisten Standardimplementierungen erlaubt es uns jedoch noch nicht, Abfragen in Form von geordneten Tupeln zu formulieren.
Im letzten Artikel einer Reihe über virtuelle Maschinen werde ich über einen alternativen Ansatz zum Finden interessanter Sitzungen sprechen - die reguläre Ausdrucks-Engine ( Pig Match ), die für Ereignissequenzen definiert ist.
Virtuelle Maschine, Bytecode und Compiler sind kostenlos enthalten!
Erster Teil, Einführung
Zweiter Teil, Optimierung
Dritter Teil, angewendet (aktuell)
Über Ereignisse und Sitzungen
Angenommen, wir haben bereits ein Data Warehouse, mit dem Sie die Ereignisse jeder Benutzersitzung schnell und nacheinander anzeigen können.
Wir möchten Sitzungen anhand von Anforderungen wie "Alle Sitzungen zählen, bei denen eine bestimmte Teilsequenz von Ereignissen vorhanden ist", "Teile einer Sitzung, die durch ein bestimmtes Muster beschrieben wurden", "Den Teil der Sitzung zurückgeben, der nach einem bestimmten Muster stattgefunden hat" oder "Zählen, wie viele Sitzungen bestimmte Teile erreicht haben" suchen Vorlage. " Dies kann für eine Vielzahl von Analysetypen nützlich sein: Suche nach verdächtigen Sitzungen, Trichteranalyse usw.
Die gewünschten Teilsequenzen müssen irgendwie beschrieben werden. In ihrer einfachsten Form ähnelt diese Aufgabe dem Auffinden eines Teilstrings in einem Text. Wir wollen ein leistungsfähigeres Werkzeug - reguläre Ausdrücke. Moderne Implementierungen von Engines für reguläre Ausdrücke verwenden am häufigsten (Sie haben es erraten!) Virtuelle Maschinen.
Die Erstellung kleiner virtueller Maschinen zum Abgleichen von Sitzungen mit regulären Ausdrücken wird nachstehend erläutert. Aber zuerst werden wir die Definitionen klarstellen.
Ein Ereignis besteht aus einem Ereignistyp, einer Zeit, einem Kontext und einer Reihe von Attributen, die für jeden Typ spezifisch sind.
Der Typ und der Kontext jedes Ereignisses sind Ganzzahlen aus vordefinierten Listen. Wenn bei den Ereignistypen alles klar ist, ist der Kontext beispielsweise die Nummer des Bildschirms, auf dem das angegebene Ereignis aufgetreten ist.
Ein Ereignisattribut ist eine beliebige Ganzzahl, deren Bedeutung durch den Ereignistyp bestimmt wird. Ein Ereignis hat möglicherweise keine oder mehrere Attribute.
Eine Sitzung ist eine Folge von Ereignissen, die nach Zeit sortiert sind.
Aber kommen wir endlich zur Sache. Das Summen ließ nach, und ich ging auf die Bühne.
Vergleiche auf einem Stück Papier
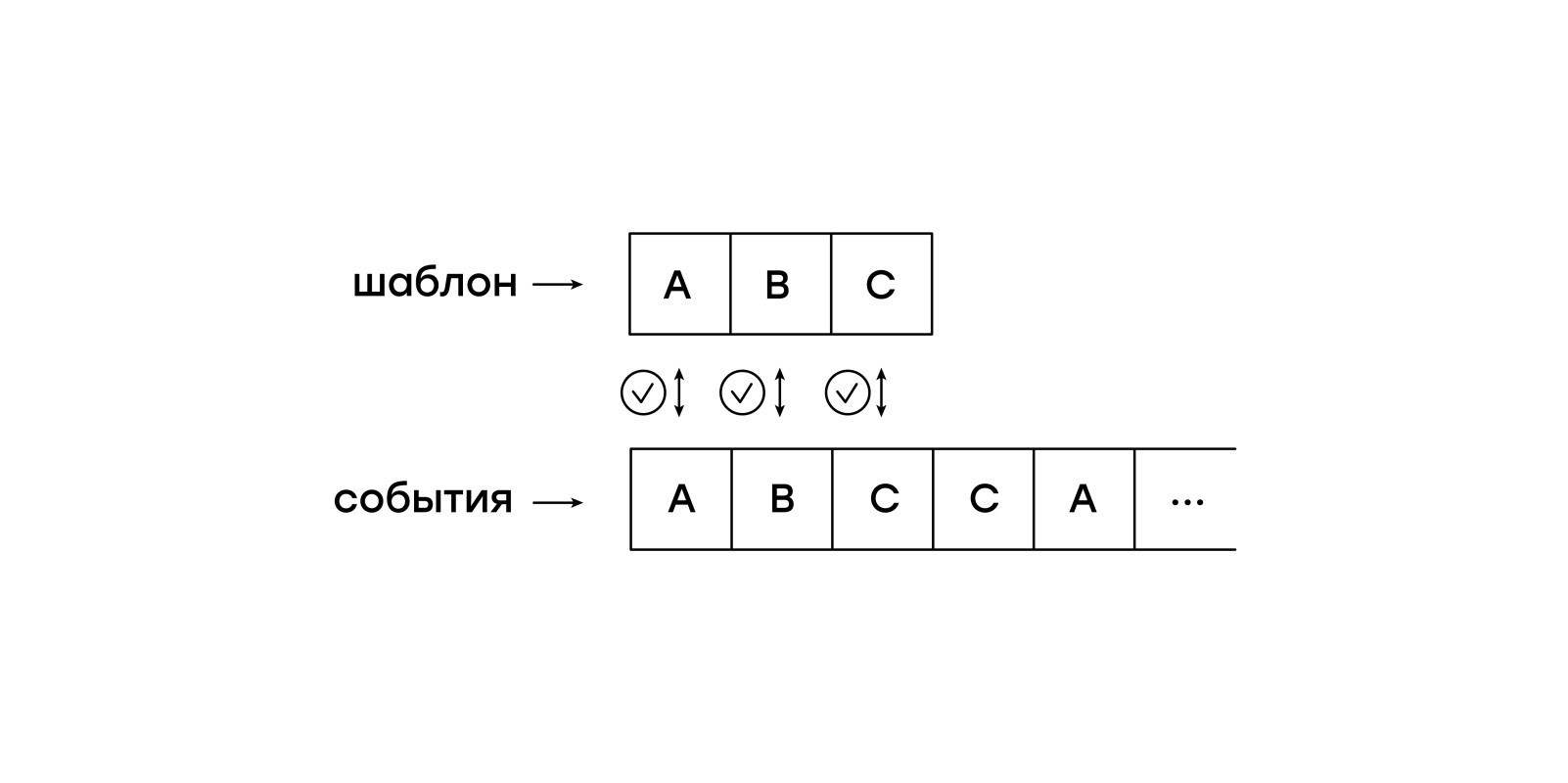
Ein Merkmal dieser virtuellen Maschine ist die Passivität in Bezug auf Eingabeereignisse. Wir möchten nicht die gesamte Sitzung im Speicher behalten und der virtuellen Maschine ermöglichen, unabhängig von Ereignis zu Ereignis zu wechseln. Stattdessen werden Ereignisse nacheinander aus der Sitzung in die virtuelle Maschine eingespeist.
Definieren wir die Schnittstellenfunktionen:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
Wenn mit den Funktionen matcher_create und matcher_destroy alles klar ist, ist matcher_accept einen Kommentar wert. Die Funktion matcher_accept empfängt eine Instanz der virtuellen Maschine und des nächsten Ereignisses (32 Bit, wobei 16 Bit für den Ereignistyp und 16 Bit für den Kontext) und gibt einen Code zurück, in dem erläutert wird, was der Benutzercode als Nächstes tun soll:
typedef enum match_result {
Opcodes der virtuellen Maschine:
typedef enum matcher_opcode {
Die Hauptschleife einer virtuellen Maschine:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
In dieser einfachen Version stimmt unsere virtuelle Maschine das durch Bytecode beschriebene Muster nacheinander mit eingehenden Ereignissen ab. Insofern ist dies einfach kein sehr präziser Vergleich der Präfixe zweier Zeilen: der gewünschten Vorlage und der Eingabezeile.
Präfixe sind Präfixe, aber wir möchten die gewünschten Muster nicht nur am Anfang, sondern auch an einer beliebigen Stelle in der Sitzung finden. Die naive Lösung besteht darin, den Abgleich von jedem Sitzungsereignis neu zu starten. Dies impliziert jedoch die mehrfache Betrachtung jedes Ereignisses und das Essen algorithmischer Babys.
Das Beispiel aus dem ersten Artikel der Serie simuliert praktisch den Neustart eines Matches mithilfe von Rollback (englisches Backtracking). Der Code im Beispiel sieht natürlich schlanker aus als der hier angegebene, aber das Problem ist nicht behoben: Jedes der Ereignisse muss mehrmals überprüft werden.
So kannst du nicht leben.
Ich, ich wieder und ich wieder

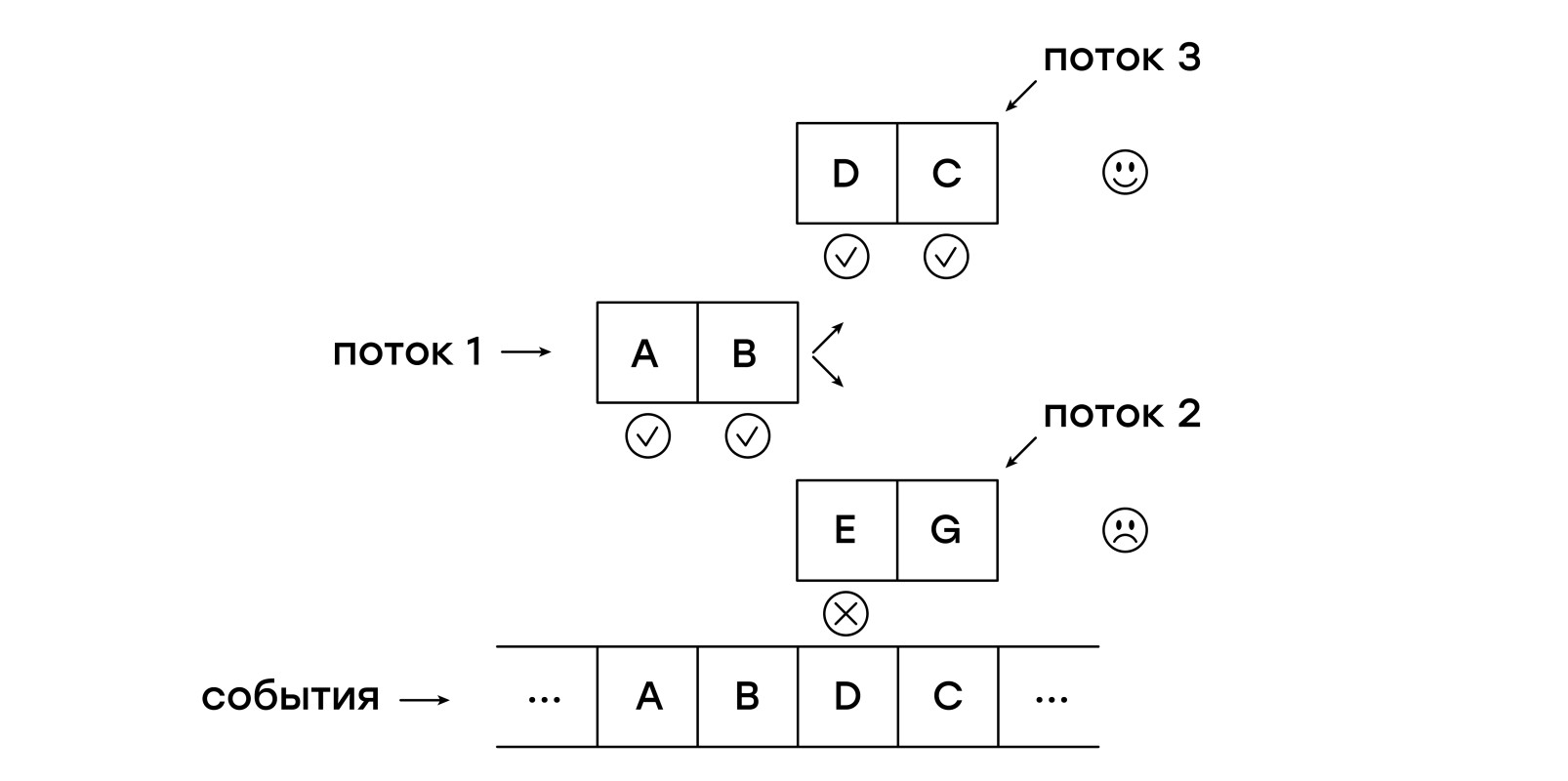
Lassen Sie uns das Problem noch einmal skizzieren: Wir müssen die Vorlage mit eingehenden Ereignissen abgleichen, beginnend mit jedem der Ereignisse, die einen neuen Vergleich starten. Warum machen wir das nicht einfach? Lassen Sie die virtuelle Maschine eingehende Ereignisse in mehreren Threads bearbeiten!
Dazu benötigen wir eine neue Entität - einen Stream. Jeder Thread speichert einen einzelnen Zeiger - auf die aktuelle Anweisung:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
Natürlich werden wir jetzt in der virtuellen Maschine selbst den expliziten Zeiger nicht speichern. Es wird durch zwei Thread-Listen ersetzt (mehr dazu weiter unten):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
Und hier ist die aktualisierte Hauptschleife:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
Bei jedem empfangenen Ereignis fügen wir zuerst einen neuen Thread zur Liste current_threads hinzu und überprüfen die Vorlage von Anfang an. Danach durchlaufen wir die Liste current_threads und folgen jedem Zeiger, indem wir den Anweisungen folgen.
Wenn eine NEXT-Anweisung angetroffen wird, wird der Thread in die Liste next_threads eingefügt, dh er wartet auf den Empfang des nächsten Ereignisses.
Wenn das Thread-Muster nicht mit dem empfangenen Ereignis übereinstimmt, wird ein solcher Thread einfach nicht zur Liste next_threads hinzugefügt.
Der MATCH-Befehl beendet die Funktion sofort und meldet einen Rückkehrcode, dass das Muster mit der Sitzung übereinstimmt.
Nach Abschluss des Crawls der Thread-Liste werden die aktuelle und die nächste Liste ausgetauscht.
Eigentlich ist das alles. Wir können sagen, dass wir buchstäblich das tun, was wir wollten: Gleichzeitig überprüfen wir mehrere Vorlagen und starten für jedes Sitzungsereignis einen neuen Übereinstimmungsprozess.
Mehrere Identitäten und Zweige in Vorlagen
Die Suche nach einer Vorlage, die eine lineare Abfolge von Ereignissen beschreibt, ist natürlich nützlich, aber wir möchten vollständige reguläre Ausdrücke erhalten. Und die Flows, die wir in der vorherigen Phase erstellt haben, sind auch hier nützlich.
Angenommen, wir möchten eine Folge von zwei oder drei Ereignissen finden, die für uns von Interesse sind, so etwas wie ein regulärer Ausdruck in Zeilen: "a? Bc". In dieser Reihenfolge ist das Symbol "a" optional. Wie drücke ich es in Bytecode aus? Einfach!
Wir können zwei Threads starten, jeweils einen: mit dem Symbol "a" und ohne. Zu diesem Zweck führen wir eine zusätzliche Anweisung (vom SPLIT-Typ addr1, addr2) ein, die zwei Threads von den angegebenen Adressen aus startet. Neben SPLIT ist JUMP auch für uns nützlich, da die Ausführung einfach mit der im direkten Argument angegebenen Anweisung fortgesetzt wird:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
Die Schleife selbst und der Rest der Anweisungen ändern sich nicht - wir stellen nur zwei neue Handler vor:
Beachten Sie, dass die Anweisungen der aktuellen Liste Threads hinzufügen, dh, sie funktionieren weiterhin im Kontext des aktuellen Ereignisses. Der Thread, in dem der Zweig aufgetreten ist, wird nicht in die Liste der folgenden Threads aufgenommen.
Das Erstaunlichste an dieser virtuellen Maschine mit regulären Ausdrücken ist, dass unsere Threads und dieses Anweisungspaar ausreichen, um fast alle Konstruktionen auszudrücken, die beim Abgleichen von Zeichenfolgen allgemein akzeptiert werden.
Regelmäßige Ausdrücke zu Ereignissen
Jetzt, da wir eine geeignete virtuelle Maschine und Tools dafür haben, können wir uns tatsächlich mit der Syntax für unsere regulären Ausdrücke befassen.
Die manuelle Aufzeichnung von Opcodes für ernstere Programme wird schnell müde. Das letzte Mal habe ich keinen vollwertigen Parser erstellt, aber der echte Benutzer hat die Funktionen seiner Raddsl- Bibliothek am Beispiel der PigletC - Minisprache gezeigt . Ich war so beeindruckt von der Kürze des Codes, dass ich mit Hilfe von raddsl einen kleinen Compiler mit regulären Ausdrücken von Zeichenfolgen in hundert oder zweihundert in Python schrieb. Der Compiler und seine Gebrauchsanweisung befinden sich auf GitHub. Das Ergebnis des Compilers in Assemblersprache wird von einem Dienstprogramm verstanden, das zwei Dateien liest (ein Programm für eine virtuelle Maschine und eine Liste von Sitzungsereignissen zur Überprüfung).
Zunächst beschränken wir uns auf die Art und den Kontext des Ereignisses. Die Art des Ereignisses wird durch eine einzelne Zahl angegeben. Wenn Sie einen Kontext angeben müssen, geben Sie ihn über einen Doppelpunkt an. Das einfachste Beispiel:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
Nun ein Beispiel mit Kontext:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
Aufeinanderfolgende Ereignisse müssen irgendwie getrennt sein (z. B. durch Leerzeichen):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
Vorlage interessanter:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
Achten Sie auf die Zeilen, die mit einem Doppelpunkt enden. Dies sind Tags. Der SPLIT-Befehl erstellt zwei Threads, die die Ausführung von den Bezeichnungen L0 und L1 fortsetzen, und JUMP am Ende des ersten Ausführungszweigs fährt einfach bis zum Ende des Zweigs fort.
Sie können wahrheitsgemäßer zwischen Ausdrucksketten wählen, indem Sie Teilsequenzen in Klammern gruppieren:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
Ein beliebiges Ereignis wird durch einen Punkt angezeigt:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
Wenn wir zeigen wollen, dass die Teilsequenz optional ist, setzen wir ein Fragezeichen danach:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
Natürlich sind auch mehrere reguläre Wiederholungen (Plus oder Sternchen) in regulären Ausdrücken üblich:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
Hier führen wir den SPLIT-Befehl einfach viele Male aus und starten bei jedem Zyklus neue Threads.
Ähnlich mit einem Sternchen:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

Perspektive
Andere Erweiterungen der beschriebenen virtuellen Maschine können nützlich sein.
Zum Beispiel kann es einfach erweitert werden, indem Ereignisattribute überprüft werden. Für ein reales System nehme ich an, eine Syntax wie "1: 2 {3: 4, 5:> 3}" zu verwenden, was bedeutet: Ereignis 1 in Kontext 2 mit Attribut 3 mit Wert 4 und Attributwert 5 größer als 3. Attribute hier Sie können es einfach in einem Array an die Funktion matcher_accept übergeben.
Wenn Sie auch das Zeitintervall zwischen Ereignissen an matcher_accept übergeben, können Sie der Vorlagensprache eine Syntax hinzufügen, mit der Sie die Zeit zwischen Ereignissen überspringen können: "1 mindelta (120) 2", was bedeutet: Ereignis 1, dann ein Zeitraum von mindestens 120 Sekunden, Ereignis 2 In Kombination mit der Beibehaltung einer Teilsequenz können Sie so Informationen zum Benutzerverhalten zwischen zwei Teilsequenzen von Ereignissen sammeln.
Andere nützliche Dinge, die relativ einfach hinzuzufügen sind, sind: Beibehalten von Teilsequenzen regulärer Ausdrücke, Trennen von gierigen und gewöhnlichen Sternchen- und Plus-Operatoren usw. In Bezug auf die Theorie der Automaten ist unsere virtuelle Maschine ein nicht deterministischer endlicher Automat, für dessen Implementierung es nicht schwierig ist, solche Dinge zu tun.
Fazit
Unser System wurde für schnelle Benutzeroberflächen entwickelt, daher ist die Sitzungsspeicher-Engine selbst geschrieben und speziell für den Durchgang durch alle Sitzungen optimiert. Alle Milliarden von Ereignissen, die in Sitzungen aufgeteilt wurden, werden auf einem einzelnen Server in Sekundenschnelle mit Mustern verglichen.
Wenn die Geschwindigkeit für Sie nicht so kritisch ist, kann ein ähnliches System als Erweiterung für ein Standard-Datenspeichersystem wie eine herkömmliche relationale Datenbank oder ein verteiltes Dateisystem konzipiert werden.
Übrigens ist in den neuesten Versionen des SQL-Standards bereits eine ähnliche Funktion wie im Artikel beschrieben erschienen, und einzelne Datenbanken ( Oracle und Vertica ) haben sie bereits implementiert. Yandex ClickHouse implementiert seinerseits eine eigene SQL-ähnliche Sprache, verfügt jedoch auch über ähnliche Funktionen .
Ich möchte von Ereignissen und regulären Ausdrücken ablenken und wiederholen, dass die Anwendbarkeit virtueller Maschinen viel umfassender ist, als es auf den ersten Blick erscheinen mag. Diese Technik ist in allen Fällen geeignet und weit verbreitet, in denen klar zwischen den Grundelementen, die die System-Engine versteht, und dem "vorderen" Subsystem, dh einer DSL- oder Programmiersprache, unterschieden werden muss.
Dies schließt eine Reihe von Artikeln über die verschiedenen Verwendungszwecke von Bytecode-Interpreten und virtuellen Maschinen ab. Ich hoffe, den Lesern von Habr hat die Serie gefallen und natürlich beantworte ich gerne alle Fragen zum Thema.
Bytecode-Interpreter für Programmiersprachen sind ein spezifisches Thema, und es gibt relativ wenig Literatur dazu. Ich persönlich mochte Ian Craigs Buch Virtual Machines, obwohl es weniger die Implementierung von Interpreten als vielmehr abstrakte Maschinen beschreibt - mathematische Modelle, die verschiedenen Programmiersprachen zugrunde liegen.
Im weiteren Sinne widmet sich ein weiteres Buch virtuellen Maschinen - „Virtuelle Maschinen: Flexible Plattformen für Systeme und Prozesse“ („Virtuelle Maschinen: Vielseitige Plattformen für Systeme und Prozesse“). Dies ist eine Einführung in die verschiedenen Anwendungen der Virtualisierung, die die Virtualisierung von Sprachen, Prozessen und Computerarchitekturen im Allgemeinen abdeckt.
Die praktischen Aspekte der Entwicklung von Engines für reguläre Ausdrücke werden in der populären Compilerliteratur selten diskutiert. Das Pig Match und das Beispiel aus dem ersten Artikel basieren auf Ideen aus einer erstaunlichen Artikelserie von Russ Cox, einem der Entwickler der Google RE2-Engine.
Die Theorie der regulären Ausdrücke wird in allen akademischen Lehrbüchern über Compiler vorgestellt. Es ist üblich, sich auf das berühmte „Drachenbuch“ zu beziehen, aber ich würde empfehlen, mit dem obigen Link zu beginnen.
Während ich an diesem Artikel arbeitete, verwendete ich zuerst ein interessantes System für die schnelle Entwicklung von Compilern für Python raddsl , das zum Stift des Benutzers true-grue gehört (danke, Peter!). Wenn Sie vor der Aufgabe stehen, eine Sprache als Prototyp zu erstellen oder schnell eine Art DSL zu entwickeln, sollten Sie darauf achten.