Ein Quintett ist eine Möglichkeit, atomare Daten aufzuzeichnen, die ihre Rolle in unserem Leben anzeigen. Quintette können beliebige Daten beschreiben, während jedes von ihnen umfassende Informationen über sich selbst und über Beziehungen zu anderen Quintetten enthält. Es stellt Domain-Begriffe dar, unabhängig von der verwendeten Plattform. Ihre Aufgabe ist es, die Speicherung von Daten zu vereinfachen und die Sichtbarkeit ihrer Präsentation zu verbessern.

Ich werde über einen neuen Ansatz zum Speichern und Verarbeiten von Informationen sprechen und meine Gedanken zur Schaffung einer Entwicklungsplattform in diesem neuen Paradigma teilen.
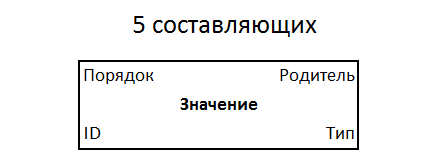
Das Quintett hat Eigenschaften: Typ, Wert, Eltern, Ordnung unter den Brüdern. Mit der Kennung werden nur 5 Komponenten erhalten. Dies ist die einfachste universelle Form der Aufzeichnung von Informationen, ein neuer Standard, der möglicherweise für jeden geeignet ist. Quintette werden in einem Dateisystem einer einzelnen Struktur in einem kontinuierlichen monoton indizierten Informationsfeld gespeichert.
Um Informationen aufzuzeichnen, gibt es unendlich viele Standards, Ansätze und Regeln, deren Kenntnis für die Arbeit mit diesen Aufzeichnungen erforderlich ist. Standards werden separat beschrieben und beziehen sich nicht direkt auf Daten. Bei Quintetten, die eines von ihnen nehmen, können Sie relevante Informationen über Art, Eigenschaften und Regeln der Arbeit mit dem Themenbereich erhalten. Sein Standard ist einheitlich und für alle Bereiche unverändert. Das Quintett ist dem Benutzer verborgen - Metadaten und Daten stehen ihm in der Form zur Verfügung, die vielen bekannt ist.
Ein Quintett ist nicht nur Information, sondern auch ausführbare Befehle. Vor allem aber sind es die Daten, die Sie speichern, aufzeichnen und abrufen möchten. Da sie in unserem Fall direkt adressiert, verbunden und indiziert sind, speichern wir sie in einer Art Datenbank. Um beispielsweise den Prototyp eines Quintett-Datenspeichersystems zu testen, haben wir eine reguläre relationale Datenbank verwendet.
Quintettstruktur
Die Hauptidee dieses Artikels besteht darin, Maschinentypen durch menschliche Begriffe zu ersetzen und Variablen durch Objekte zu ersetzen. Nicht von Objekten, die einen Konstruktor, Destruktor, Schnittstellen und einen Garbage Collector benötigen, sondern von reinen Kristalleinheiten, mit denen ein Kunde arbeitet. Das heißt, wenn der Kunde "Anwendung" sagt, würde das Speichern der
Essenz dieser Informationen auf den Medien nicht das Fachwissen eines Programmierers erfordern.
Es ist nützlich, die Aufmerksamkeit des Benutzers nur auf den Wert des Objekts zu richten, und sein Typ, sein Elternteil, seine Reihenfolge (unter Gleichen in der Unterordnung) und seine Kennung sollten aus dem Kontext ersichtlich oder einfach verborgen sein. Dies bedeutet, dass der
Benutzer überhaupt nichts über Quintette weiß. Er legt einfach seine Aufgabe dar, stellt sicher, dass sie korrekt akzeptiert wird, und beginnt dann mit der Ausführung.
Grundbegriffe
Es gibt eine Reihe von Datentypen, die jeder verstehen kann: Zeichenfolge, Nummer, Datei, Text, Datum usw. Solch eine einfache Menge reicht völlig aus, um das Problem zu formulieren und es und die für seine Implementierung erforderlichen Typen zu „programmieren“. Die durch Quintette dargestellten Grundtypen können folgendermaßen aussehen:

In diesem Fall werden einige Komponenten des Quintetts nicht verwendet, und er wird als Basistyp verwendet. Dies erleichtert die Navigation im Kern des Systems beim Navigieren in Metadaten.
Hintergrund
Aufgrund der analytischen Lücke zwischen dem Benutzer und dem Programmierer tritt in der Phase der Problemstellung eine erhebliche Verformung der Konzepte auf. Das Understatement, die Unverständlichkeit und die unaufgeforderte Initiative machen aus einem einfachen und verständlichen Gedanken des Kunden aus Sicht des Benutzers oft eine logisch unmögliche Mischung.

Der Wissenstransfer muss ohne Verlust oder Verzerrung erfolgen. Darüber hinaus müssen in Zukunft bei der Organisation der Speicherung dieses Wissens die durch das ausgewählte Datenverwaltungssystem auferlegten Einschränkungen beseitigt werden.
So speichern Sie Daten
In der Regel befinden sich auf dem Server viele Datenbanken, von denen jede eine Beschreibung der Entitätsstruktur mit einem bestimmten Satz von Attributen enthält - miteinander verbundene Daten. Sie werden in einer bestimmten Reihenfolge gespeichert, ideal für die Probenahme.
Das vorgeschlagene Informationsspeichersystem ist ein Kompromiss zwischen verschiedenen bekannten Methoden: Spalte, Zeichenfolge und NoSQL. Es wurde entwickelt, um die Aufgaben zu lösen, die normalerweise mit einer dieser Methoden ausgeführt werden.
Zum Beispiel sieht die Theorie der Spaltenbasen schön aus: Wir lesen nur die gewünschte Spalte und nicht alle Datensatzzeilen als Ganzes. In der Praxis ist es jedoch unwahrscheinlich, dass Daten auf den Medien abgelegt werden, sodass sie auf Dutzende verschiedener Abschnitte der Analyse anwendbar sind. Beachten Sie, dass Attribute und analytische Metriken hinzugefügt und entfernt werden können, manchmal schneller als wir diese Spaltenökonomie wiederherstellen können. Ganz zu schweigen von der Tatsache, dass die Daten in der Datenbank angepasst werden können, was aufgrund der unvermeidlichen Fragmentierung auch die Schönheit des Stichprobenplans verletzt.
Metadaten
Wir haben ein Konzept eingeführt - einen Begriff -, um alle Objekte zu beschreiben, mit denen wir arbeiten: Entität, Eigenschaft, Anforderung, Datei usw. Wir werden alle Begriffe definieren, die wir in unserem Themenbereich verwenden. Und mit ihrer Hilfe werden wir alle Entitäten beschreiben, die Details haben, auch in Form von Beziehungen zwischen Entitäten. Zum Beispiel Requisiten - ein Link zu einem Statusverzeichniseintrag. Der Begriff ist in einem Quintett von Daten geschrieben.
Eine Reihe von Begriffsbeschreibungen sind Metadaten, die die Struktur von Tabellen und Feldern in einer regulären Datenbank definieren. Beispielsweise gibt es die folgende Datenstruktur: eine Anwendung ab einem Datum mit Inhalt (Anwendungstext) und einem Status, zu dem Teilnehmer am Produktionsprozess Kommentare hinzufügen, die das Datum angeben. Im traditionellen Datenbankkonstruktor sieht es ungefähr so aus:

Da wir beschlossen haben, alle nicht wesentlichen Details, wie z. B. verbindliche IDs, vor dem Benutzer zu verbergen, wird das Schema etwas vereinfacht: Die Erwähnungen von IDs werden entfernt und die Namen von Entitäten und ihre Schlüsselwerte werden kombiniert.
Der Benutzer "zeichnet" die Aufgabe: eine Anfrage vom heutigen Datum, die einen Status (Referenzwert) hat und zu der Sie Kommentare hinzufügen können, die das Datum angeben:

Jetzt sehen wir 6 verschiedene Datenfelder anstelle von 9, und das gesamte Schema bietet uns die Möglichkeit, 7 statt 13 Wörter zu lesen und zu verstehen. Obwohl dies natürlich weit von der Hauptsache entfernt ist.
Die folgenden Quintette werden vom Steuerkern generiert, um diese Struktur zu beschreiben:

Zur Verdeutlichung werden Erklärungen anstelle von grau hervorgehobenen Quintettwerten bereitgestellt. Diese Felder werden nicht ausgefüllt, da alle erforderlichen Informationen durch die verbleibenden Komponenten eindeutig bestimmt werden.
Sehen Sie, wie Quintette zusammenhängen Benutzerdaten
Erwägen Sie, einen solchen Datensatz für die obige Aufgabe zu speichern:

Die Daten selbst werden in Quintetten gemäß der Struktur gespeichert, die die Mitgliedschaft in bestimmten Begriffen in Form eines solchen Satzes angibt:
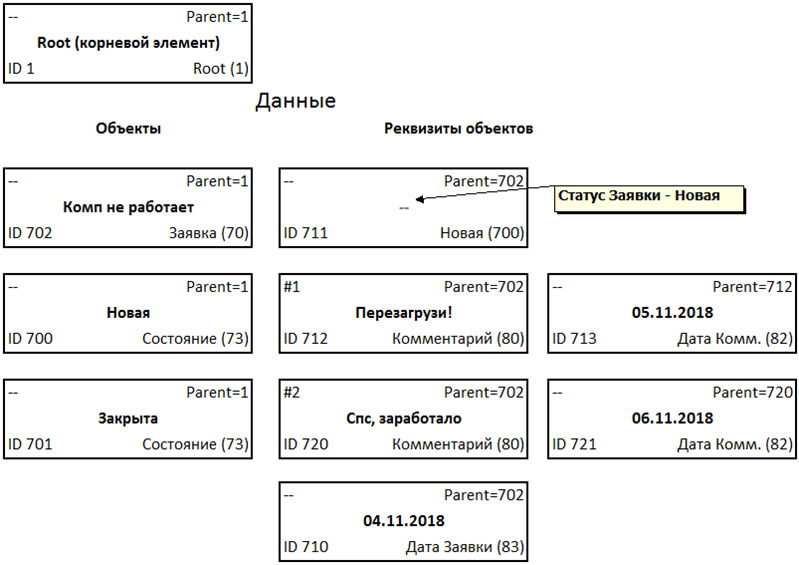
Wir sehen eine vertraute hierarchische Struktur, die mit der Methode Adjacency List gespeichert wird.
Leistung
Das obige Beispiel ist sehr einfach, aber was passiert, wenn die Struktur tausendfach komplexer ist und die Daten Gigabyte groß sind?
Wir werden brauchen:
- Die oben betrachtete hierarchische Struktur ist 1 Stk.
- B-Baum für die Suche nach ID, Eltern und Typ - 3 Stk.
Somit werden alle Datensätze in unserer Datenbank indiziert, einschließlich Daten und Metadaten. Eine solche Indizierung ist erforderlich, um die Eigenschaften einer relationalen Datenbank zu erhalten - dem einfachsten und beliebtesten Tool. Der übergeordnete Index ist tatsächlich zusammengesetzt (übergeordnete ID + Typ). Ein Index nach Typ ist auch zusammengesetzt (Typ + Wert) für die schnelle Suche nach Objekten eines bestimmten Typs.
Mit Metadaten können wir die Rekursion beseitigen: Um beispielsweise alle Details eines bestimmten Objekts zu finden, verwenden wir den Index nach übergeordneter ID. Wenn Sie nach Objekten eines bestimmten Typs suchen müssen, wird ein Index nach Typ-ID verwendet. Ein Typ ist ein Analogon eines Tabellennamens und eines Felds in einem relationalen DBMS.

In jedem Fall scannen wir nicht den gesamten Datensatz, und selbst bei einer großen Anzahl von Werten eines beliebigen Typs kann der gewünschte Wert in wenigen Schritten gefunden werden.
Die Basis für die Entwicklungsplattform
An sich ist eine solche Datenbank für die Anwendungsprogrammierung nicht autark und laut Turing nicht vollständig, wie sie sagen. Wir sprechen hier aber nicht nur über die Datenbank, sondern versuchen alle Aspekte abzudecken: Objekte sind unter anderem beliebige Steuerungsalgorithmen, die gestartet werden können und funktionieren.
Als Ergebnis erhalten wir anstelle komplexer Datenbankstrukturen und separat gespeicherten Quellcodes von Steueralgorithmen ein einheitliches Informationsfeld, das durch das Volumen des Mediums begrenzt und mit Metadaten markiert ist. Die Daten selbst werden dem Benutzer so dargestellt, dass er sie versteht - die Struktur des Themenbereichs und die entsprechenden Einträge darin. Der Benutzer ändert die Struktur und die Daten willkürlich, einschließlich Massenoperationen mit ihnen.
Wir haben nichts Neues erfunden: Alle Daten sind bereits im Dateisystem gespeichert und die Suche in ihnen erfolgt über B-Bäume, im Dateisystem, in den Datenbanken. Wir haben gerade die Darstellung der Daten neu organisiert, um die Arbeit damit einfacher und visueller zu gestalten.
Um mit dieser Datendarstellung arbeiten zu können, benötigen Sie einen sehr kompakten Kern - unsere Datenbank-Engine ist eine Größenordnung kleiner als das Computer-BIOS und kann daher, wenn nicht in Hardware, mindestens so schnell und so schnell wie möglich erstellt werden. Aus Sicherheitsgründen ist es auch schreibgeschützt.
Wenn wir der Assembly meines geliebten .Net eine neue Klasse hinzufügen, können wir den Verlust von 200-300 MB RAM nur für die Beschreibung dieser Klasse beobachten. Diese Megabyte passen nicht in den Cache der richtigen Ebene, was dazu führt, dass das System mit den daraus resultierenden Konsequenzen in Unordnung gerät. Eine ähnliche Situation mit Java. Das Beschreiben derselben Klasse mit Quintetten dauert zehn oder Hunderte von Bytes, da die Klasse nur primitive Tricks für die Arbeit mit Daten verwendet, die dem Kernel bereits bekannt sind.
Umgang mit verschiedenen Formaten: RDBMS, NoSQL, SpaltenbasenDer beschriebene Ansatz deckt zwei Hauptbereiche ab: RDBMS und NoSQL. Bei der Lösung von Problemen, bei denen Säulendatenbanken zum Einsatz kommen, müssen wir dem Kernel mitteilen, dass bestimmte Objekte gespeichert werden sollen, wobei die Optimierung der Massenabtastung der Werte eines bestimmten Datentyps (unser Begriff) berücksichtigt wird. So kann der Kernel Daten auf die rentabelste Weise auf der Festplatte ablegen.
Somit können wir für die Spaltenbasis den von Quintetten belegten Platz erheblich einsparen: Verwenden Sie nur eine oder zwei ihrer Komponenten, um nützliche Daten anstelle von fünf zu speichern, und verwenden Sie den Index nur, um den Beginn der Datenketten anzuzeigen. In vielen Fällen wird nur der Index für Stichproben aus unserer analogen Spaltenbasis verwendet, ohne dass auf die Daten der Tabelle selbst zugegriffen werden muss.
Es sollte beachtet werden, dass die Idee nicht das Ziel hat, alle fortgeschrittenen Entwicklungen aus diesen drei Arten von Datenbanken zu sammeln. Im Gegenteil, die Engine des neuen Systems wird so weit wie möglich reduziert und enthält nur das erforderliche Minimum an Funktionen - alles, was die DDL- und DML-Abfragen in dem hier beschriebenen Konzept abdeckt.
Programmierparadigma
Die Verwendung des beschriebenen Ansatzes ist nicht nur auf Quintette beschränkt, sondern fördert ein anderes Paradigma als das, an das Programmierer gewöhnt sind. Anstelle einer imperativen, deklarativen oder Objektsprache wird die Abfragesprache als dem Menschen vertrauter vorgeschlagen und ermöglicht es uns, die Aufgabe direkt auf den Computer zu übertragen, wobei Programmierer und die undurchdringliche Schicht bestehender Entwicklungsumgebungen umgangen werden.
Natürlich ist in den meisten Fällen weiterhin ein Übersetzer von einer freien Benutzersprache in eine Sprache mit klaren Anforderungen erforderlich.Dieses Thema wird in separaten Artikeln mit Beispielen und bestehenden Entwicklungen ausführlicher beschrieben.
Kurz gesagt, es funktioniert wie folgt:
- Wir haben einmal mit Quintetten primitive Datentypen beschrieben: Zeichenfolge, Nummer, Datei, Text und andere, und auch den Kernel geschult, um mit ihnen zu arbeiten. Die Schulung beschränkt sich auf die korrekte Darstellung von Daten und die Implementierung einfacher Operationen mit ihnen.
- Jetzt beschreiben wir in Quintetten Benutzerbegriffe (Datentypen) - in Form von Metadaten. Die Beschreibung besteht darin, für jeden Benutzertyp einen primitiven Datentyp anzugeben und die Unterordnung zu bestimmen.
- Geben Sie die Quintette der Daten gemäß der in den Metadaten angegebenen Struktur ein. Jedes Quintett von Daten enthält einen Link zu seinem Typ und übergeordneten Element, sodass Sie es schnell im Data Warehouse finden können.
- Die Kernaufgaben bestehen darin, Daten abzurufen und einfache Operationen mit ihnen durchzuführen, um beliebig komplexe Algorithmen zu implementieren, die vom Benutzer beschrieben werden.
- Der Benutzer verwaltet Daten und Algorithmen über eine visuelle Oberfläche, die sowohl die erste als auch die zweite visuell darstellt.
Die Vollständigkeit des gesamten Systems wird durch die Verkörperung der Grundanforderungen sichergestellt: Der Kernel kann sequentielle Operationen ausführen, bedingt verzweigen, Datensätze verarbeiten und die Arbeit stoppen, wenn ein bestimmtes Ergebnis erreicht wird.
Für eine Person ist der Vorteil beispielsweise die Einfachheit der Wahrnehmung, anstatt einen Zyklus mit Variablen zu deklarieren
for (i=0; i<length(A); i++) if A[i] meets a condition do something with A[i]
eine menschenfreundlichere Konstruktion wird verwendet, wie
with every A, that match a condition, do something
Wir träumen davon, von den Feinheiten der Implementierung eines Informationssystems auf niedriger Ebene zu abstrahieren: Schleifen, Konstruktoren, Funktionen, Manifeste, Bibliotheken - all dies nimmt im Gehirn eines Programmierers zu viel Platz ein und lässt wenig Raum für kreative Arbeit und Entwicklung.
Skalieren
Eine moderne Anwendung ist ohne Skalierungsmittel nicht denkbar: Eine unbegrenzte Möglichkeit zur Erweiterung der Ladekapazität eines Informationssystems ist erforderlich. Bei dem beschriebenen Ansatz stellt sich heraus, dass die Skalierung angesichts der extrem einfachen Datenorganisation nicht komplizierter organisiert ist als in vorhandenen Architekturen.
Im obigen Beispiel mit Anwendungen können Sie sie beispielsweise nach ihrer ID trennen, um die ID mit festen hohen Bytes für verschiedene Server zu generieren. Das heißt, wenn 32 Bit für die ID-Speicherung verwendet werden, geben die höchstwertigen zwei, drei, vier oder mehr Bits je nach Bedarf den Server an, auf dem diese Anwendungen gespeichert sind. Somit verfügt jeder Server über einen eigenen ID-Pool.
Der Kern eines einzelnen Servers kann unabhängig von anderen Servern funktionieren, ohne etwas darüber zu wissen. Beim Erstellen einer Anwendung wird dem Server mit der minimalen Anzahl verwendeter IDs eine hohe Priorität eingeräumt, um eine gleichmäßige Lastverteilung zu gewährleisten.
Angesichts einer begrenzten Anzahl möglicher Variationen von Anforderungen und Antworten mit einer einzigen Datenorganisation benötigen Sie einen relativ kompakten Dispatcher, der Anforderungen auf Server verteilt und deren Ergebnisse aggregiert.