Haben Sie bemerkt, dass eine Marktnische, die populär geworden ist, Vermarkter aus dem Handel mit Informationssicherheit aus Angst anzieht? Sie überzeugen Sie davon, dass das Unternehmen im Falle eines Cyberangriffs keine der Aufgaben bewältigen kann, um auf den Vorfall zu reagieren. Und hier erscheint natürlich ein freundlicher Assistent - ein Dienstleister, der für einen bestimmten Betrag bereit ist, um den Kunden vor Ärger und Entscheidungen zu bewahren. Wir erklären, warum ein solcher Ansatz nicht nur für den Geldbeutel, sondern auch für das Sicherheitsniveau des Unternehmens gefährlich sein kann, welchen praktischen Nutzen die Einbeziehung eines Dienstleisters bringen kann und welche Entscheidungen immer im Verantwortungsbereich des Kunden bleiben sollten.

Zunächst werden wir uns mit der Terminologie befassen. Wenn es um das Incident Management geht, hört man oft zwei Abkürzungen, SOC und CSIRT, deren Bedeutung wichtig ist, um Marketingmanipulationen zu vermeiden.
SOC (Security Operations Center) - eine Einheit, die sich den operativen Aufgaben der Informationssicherheit widmet. Wenn Menschen über die Funktionen von SOC sprechen, meinen sie meistens die Überwachung und Identifizierung von Vorfällen. In der Regel umfasst die Verantwortung des SOC jedoch alle Aufgaben im Zusammenhang mit Informationssicherheitsprozessen, einschließlich der Reaktion auf und Beseitigung der Folgen von Vorfällen sowie methodischer Aktivitäten zur Verbesserung der IT-Infrastruktur und zur Erhöhung der Unternehmenssicherheit. Gleichzeitig ist SOC häufig eine unabhängige Personaleinheit, der Spezialisten mit unterschiedlichen Profilen angehören.
CSIRT (Cybersecurity Incident Response Team) - eine Gruppe / vorübergehend gebildete Mannschaft oder Einheit, die für die Reaktion auf neu auftretende Vorfälle verantwortlich ist. CSIRT verfügt normalerweise über ein permanentes Rückgrat, das sich aus Fachleuten für Informationssicherheit, Administratoren von SZI und der Forensikgruppe zusammensetzt. Die endgültige Zusammensetzung des Teams wird jedoch jeweils durch den Bedrohungsvektor bestimmt und kann durch den IT-Service, die Eigentümer von Geschäftssystemen und sogar das Management des Unternehmens durch einen PR-Service ergänzt werden (um den negativen Hintergrund in den Medien auszugleichen).
Trotz der Tatsache, dass CSIRT bei seinen Aktivitäten am häufigsten vom NIST-Standard geleitet wird, der einen vollständigen Incident-Management-Zyklus umfasst, liegt der Schwerpunkt im Marketingbereich derzeit häufiger auf Reaktionsaktivitäten, die SOC diese Funktion verweigern und diese beiden Begriffe gegenüberstellen.
Ist das Konzept des SOC in Bezug auf CSIRT weiter gefasst? Meiner Meinung nach ja. Bei seinen Aktivitäten ist der SOC nicht auf Vorfälle beschränkt, sondern kann sich auf Cyber-Intelligence-Daten, Prognosen und Analysen des Sicherheitsniveaus des Unternehmens stützen und umfassendere Sicherheitsaufgaben umfassen.
Zurück zum NIST-Standard, einem der beliebtesten Ansätze, der das Verfahren und die Phasen des Incident Managements beschreibt. Das allgemeine Verfahren des NIST SP 800-61-Standards ist wie folgt:
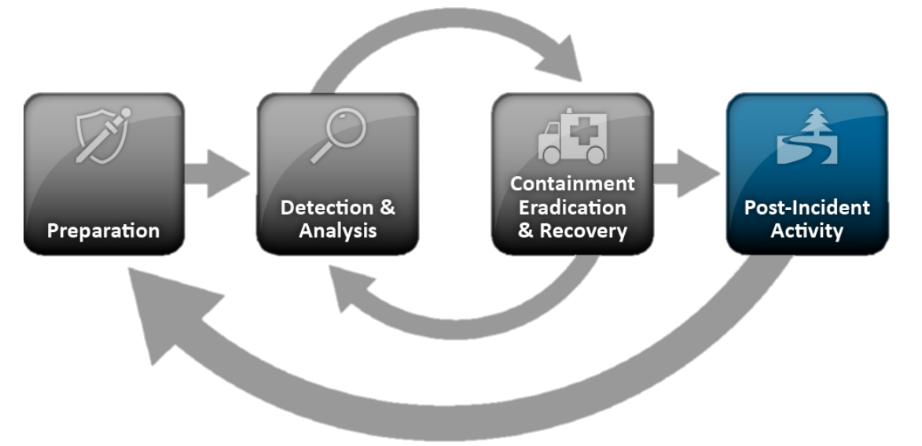
- Vorbereitung:
- Schaffung der technischen Infrastruktur für die Bearbeitung von Vorfällen
- Erstellen Sie Regeln zur Erkennung von Vorfällen
- Identifizierung und Analyse von Vorfällen:
- Überwachung und Identifizierung
- Ereignisanalyse
- Priorisierung
- Alarm
- Lokalisierung, Neutralisierung und Wiederherstellung:
- Lokalisierung von Vorfällen
- Sammlung, Lagerung und Dokumentation von Vorfallzeichen
- Katastrophenschutz
- Wiederherstellung nach einem Vorfall
- Methodische Tätigkeit:
- Zusammenfassung des Vorfalls
- Wissensdatenbank füllen + Bedrohungsintelligenz
- Organisatorische und technische Maßnahmen
Trotz der Tatsache, dass der NIST-Standard der Reaktion auf Vorfälle gewidmet ist, wird ein wesentlicher Teil der Reaktion vom Abschnitt "Erkennung und Analyse von Vorfällen" belegt, in dem die klassischen Aufgaben der Überwachung und Verarbeitung von Vorfällen beschrieben werden. Warum wird ihnen so viel Aufmerksamkeit geschenkt? Um die Frage zu beantworten, schauen wir uns jeden dieser Blöcke genauer an.
Vorbereitung
Die Aufgabe der Identifizierung von Vorfällen beginnt mit der Erstellung und „Landung“ eines Bedrohungsmodells und eines Eindringlingsmodells für die Regeln zur Identifizierung von Vorfällen. Sie können Vorfälle erkennen, indem Sie Informationssicherheitsereignisse (Protokolle) aus verschiedenen Informationsschutz-Tools, Komponenten der IT-Infrastruktur, Anwendungssystemen, Elementen technologischer Systeme (ACS) und anderen Informationsressourcen analysieren. Natürlich können Sie dies manuell mit Skripten und Berichten tun. Für eine effektive Echtzeiterkennung von Vorfällen im Bereich der Informationssicherheit sind jedoch noch spezielle Lösungen erforderlich.
SIEM-Systeme helfen hier, aber ihr Betrieb ist nicht weniger eine Aufgabe als die Analyse von "rohen" Protokollen und in jeder Phase von der Verbindung von Quellen bis zur Erstellung von Vorfallregeln. Schwierigkeiten hängen mit der Tatsache zusammen, dass Ereignisse aus verschiedenen Quellen ein einheitliches Erscheinungsbild haben müssen und die Schlüsselparameter von Ereignissen unabhängig von der Klasse / dem Hersteller des Systems oder der Hardware denselben Ereignisfeldern in SIEM zugeordnet werden müssen.
Die Regeln zur Erkennung von Vorfällen, Listen von Kompromissindikatoren und Trends von Cyber-Bedrohungen bilden den sogenannten „Inhalt“ von SIEM. Es sollte die Aufgaben des Sammelns von Netzwerk- und Benutzeraktivitätsprofilen, Sammeln von Statistiken zu Ereignissen verschiedener Art und Identifizieren typischer Informationssicherheitsvorfälle ausführen. Die Logik zum Auslösen der Regeln zum Erkennen von Vorfällen sollte die bestimmte Infrastruktur und Geschäftsprozesse eines bestimmten Unternehmens berücksichtigen.
Da es keine Standardinfrastruktur des Unternehmens und der darin stattfindenden Geschäftsprozesse gibt, kann es keinen einheitlichen Inhalt des SIEM-Systems geben. Daher sollten alle Änderungen in der IT-Infrastruktur des Unternehmens sowohl in den Einstellungen und der Optimierung der Sicherheitsausrüstung als auch in SIEM zeitnah berücksichtigt werden. Wenn das System zu Beginn der Bereitstellung von Diensten nur einmal konfiguriert wurde oder einmal im Jahr aktualisiert wird, verringert sich die Wahrscheinlichkeit, dass militärische Vorfälle erkannt und Fehlalarme mehrmals erfolgreich gefiltert werden.
Das Einrichten von Sicherheitsfunktionen, das Verbinden von Quellen mit dem SIEM-System und das Anpassen von SIEM-Inhalten sind daher wichtige Aufgaben bei der Reaktion auf Vorfälle, eine Basis, ohne die es unmöglich ist, weiterzumachen. Wenn der Vorfall nicht rechtzeitig aufgezeichnet wurde und die Phasen der Identifizierung und Analyse nicht durchlaufen hat, sprechen wir schließlich nicht mehr über eine Reaktion, sondern können nur mit den Folgen arbeiten.
Erkennung und Analyse von Vorfällen
Der Überwachungsdienst sollte mit Vorfällen im Echtzeitmodus rund um die Uhr und sieben Tage die Woche arbeiten. Diese Regel ist ebenso wie die Grundlagen der Sicherheit in Blut geschrieben: Etwa die Hälfte der kritischen Cyberangriffe beginnt nachts, sehr oft am Freitag (dies war beispielsweise beim WannaCry-Ransomware-Virus der Fall). Wenn Sie innerhalb der ersten Stunde keine Schutzmaßnahmen ergreifen, kann es schon zu spät kitschig sein. In diesem Fall übertragen Sie einfach alle aufgezeichneten Vorfälle auf den nächsten im NIST-Standard beschriebenen Schritt, d. H. In der Phase der Lokalisierung ist dies unpraktisch, und hier ist der Grund:
- Zusätzliche Informationen über das Geschehen zu erhalten oder ein falsches Positiv herauszufiltern, ist im Stadium der Analyse einfacher und korrekter als die Lokalisierung des Vorfalls. Auf diese Weise können Sie die Anzahl der Vorfälle minimieren, auf die in den nächsten Phasen des Incident Response-Prozesses verwiesen wird, in die übergeordnete Spezialisten einbezogen werden sollten - Incident Management Manager, Reaktionsteams, IT-Systeme und SIS-Administratoren. Es ist logischer, den Prozess so aufzubauen, dass nicht jede Kleinigkeit, einschließlich falsch positiver Ergebnisse, auf die CISO-Ebene eskaliert.
- Die Reaktion und „Unterdrückung“ eines Vorfalls birgt immer Geschäftsrisiken. Das Reagieren auf einen Vorfall kann Arbeiten umfassen, um verdächtigen Zugriff zu blockieren, den Host zu isolieren und zur Führungsebene zu eskalieren. Im Falle eines Fehlalarms wirkt sich jeder dieser Schritte direkt auf die Verfügbarkeit von Infrastrukturelementen aus und zwingt das Incident-Management-Team, seine eigene Eskalation für lange Zeit mit mehrseitigen Berichten und Memos zu „löschen“.
Normalerweise arbeitet die erste Reihe von Ingenieuren rund um die Uhr im Überwachungsdienst, die direkt an der Verarbeitung potenzieller vom SIEM-System erfasster Vorfälle beteiligt sind. Die Anzahl solcher Vorfälle kann mehrere Tausend pro Tag erreichen (wieder - umso mehr bis zur Lokalisierung?), Aber zum Glück passen die meisten von ihnen in bekannte Muster. Um die Verarbeitungsgeschwindigkeit zu erhöhen, können Sie daher Skripte und Anweisungen verwenden, die Schritt für Schritt die erforderlichen Aktionen beschreiben.
Dies ist eine bewährte Methode, mit der die Belastung von Zeile 2 und Zeile 3 von Analysten reduziert werden kann. Sie werden nur die Vorfälle übertragen, die nicht in eines der vorhandenen Skripte passen. Andernfalls wird entweder die Eskalation von Vorfällen in der zweiten und dritten Überwachungslinie 80% erreichen, oder in der ersten Linie müssen teure Spezialisten mit hohem Fachwissen und einer langen Einarbeitungszeit eingesetzt werden.
Daher werden neben First-Line-Mitarbeitern auch Analysten und Architekten benötigt, die Skripte und Anweisungen erstellen, First-Line-Spezialisten schulen, Inhalte in SIEM erstellen, Quellen verbinden, die Funktionsfähigkeit aufrechterhalten und SIEM in Klassensysteme wie IRP, CMDB und mehr integrieren.
Eine wichtige Überwachungsaufgabe ist die Suche, Verarbeitung und Implementierung verschiedener Reputationsbasen, APT-Berichte, Newsletter und Abonnements im SIEM-System, die letztendlich zu Kompromissindikatoren (IoC) werden. Sie ermöglichen es, verdeckte Angriffe von Angreifern auf die Infrastruktur, Malware, die von Antiviren-Anbietern nicht erkannt wird, und vieles mehr zu identifizieren. Wie beim Verbinden von Ereignisquellen mit dem SIEM-System müssen zum Hinzufügen all dieser Informationen zu Bedrohungen zunächst eine Reihe von Aufgaben gelöst werden:
- Automatisierung des Hinzufügens von Indikatoren
- Bewertung ihrer Anwendbarkeit und Relevanz
- Priorisierung und Berücksichtigung der Veralterung von Informationen
- Und vor allem - ein Verständnis der Schutzmittel, mit denen Sie Informationen zur Überprüfung dieser Indikatoren erhalten können. Wenn bei Netzwerk-Netzwerken alles ganz einfach ist - bei Firewalls und Proxys wird es schwieriger, bei Hosts ist es schwieriger - Hashes zu vergleichen, wie auf allen Hosts laufende Prozesse, Registrierungszweige und auf die Festplatte geschriebene Dateien zu überprüfen?
Oben habe ich nur einen Teil der Aspekte des Prozesses der Überwachung und Analyse von Vorfällen angesprochen, denen sich jedes Unternehmen, das einen Prozess zur Reaktion auf Vorfälle aufbaut, stellen muss. Meiner Meinung nach ist dies die wichtigste Aufgabe im gesamten Prozess, aber gehen wir weiter zur Arbeitseinheit mit bereits aufgezeichneten und analysierten Vorfällen im Bereich der Informationssicherheit.
Lokalisierung, Neutralisierung und Wiederherstellung
Dieser Block ist nach Ansicht einiger Experten für Informationssicherheit der entscheidende Unterschied zwischen dem Überwachungsteam und dem Incident-Response-Team. Schauen wir uns genauer an, was NIST darin steckt.
Lokalisierung von Vorfällen
Laut NIST besteht die Hauptaufgabe im Prozess der Lokalisierung von Vorfällen darin, eine Strategie zu entwickeln, dh Maßnahmen festzulegen, um die Ausbreitung des Vorfalls innerhalb der Infrastruktur des Unternehmens zu verhindern. Der Komplex dieser Maßnahmen kann verschiedene Aktionen umfassen - Isolieren der an dem Vorfall beteiligten Hosts auf Netzwerkebene, Umschalten der Betriebsmodi von Informationsschutz-Tools und sogar Stoppen der Geschäftsprozesse des Unternehmens, um Schäden durch den Vorfall zu minimieren. Tatsächlich ist die Strategie ein Spielbuch, das aus einer Matrix von Aktionen besteht, die von der Art des Vorfalls abhängen.
Die Umsetzung dieser Maßnahmen kann sich auf den Verantwortungsbereich für die Verlagerung des technischen IT-Supports, der Eigentümer und Administratoren von Systemen (einschließlich Geschäftssystemen), eines Drittunternehmens und des Informationssicherheitsdienstes beziehen. Aktionen können manuell von EDR-Komponenten und sogar von selbst geschriebenen Skripten ausgeführt werden, die von Befehlen verwendet werden.
Da die in dieser Phase getroffenen Entscheidungen die Geschäftsprozesse des Unternehmens direkt beeinflussen können, bleibt die Entscheidung, in den allermeisten Fällen eine bestimmte Strategie anzuwenden, die Aufgabe eines internen Informationssicherheitsmanagers (häufig unter Einbeziehung von Eigentümern von Geschäftssystemen), und
diese Aufgabe kann nicht ausgelagert werden Firma . Die Rolle des Informationssicherheitsdienstleisters bei der Lokalisierung des Vorfalls beschränkt sich auf die operative Anwendung der vom Kunden gewählten Strategie.
Sammlung, Lagerung und Dokumentation von Vorfallzeichen
Sobald betriebliche Maßnahmen zur Lokalisierung des Vorfalls ergriffen wurden, muss eine gründliche Untersuchung durchgeführt werden, in der alle Informationen gesammelt werden, um das Ausmaß zu beurteilen. Diese Aufgabe ist in zwei Unteraufgaben unterteilt:
- Übertragen zusätzlicher Eingaben an das Überwachungsteam, Verbinden zusätzlicher Quellen von Informationssicherheitsereignissen, die an dem Vorfall beteiligt sind, mit dem Ereigniserfassungs- und Analysesystem.
- Verbinden Sie das Forensik-Team, um Festplatten-Images, Speicherabbilder, Malware-Beispiele und Tools zu analysieren, die von Cyberkriminellen in diesem Vorfall verwendet werden.
Es sollte auch eine Person ernannt werden, die die Aktivitäten aller Einheiten im Rahmen der Untersuchung des Vorfalls koordiniert. Dieser Spezialist sollte über die Befugnisse und Kontakte aller an der Untersuchung beteiligten Mitarbeiter verfügen. Kann ein Auftragnehmer diese Rolle übernehmen? Wahrscheinlicher nein als ja. Es ist logischer, diese Rolle einem Spezialisten oder dem Leiter des Informationssicherheitsdienstes des Kunden anzuvertrauen.
Katastrophenschutz
Nachdem der Koordinator von verschiedenen Abteilungen ein vollständiges Bild des Vorfalls erhalten hat, entwickelt er Maßnahmen, um die Folgen des Vorfalls zu beseitigen. Dieses Verfahren kann Folgendes umfassen:
- Entfernung identifizierter Kompromissindikatoren und Spuren des Vorhandenseins von Malware / Eindringlingen.
- Infizierte Hosts "neu laden" und Benutzerkennwörter ändern.
- Installation der neuesten Updates und Entwicklung von Ausgleichsmaßnahmen zur Beseitigung kritischer Sicherheitslücken, die bei dem Angriff verwendet wurden.
- Ändern der Sicherheitsprofile von GIS.
- Kontrolle über die Vollständigkeit der von den beteiligten Einheiten durchgeführten Aktionen und das Fehlen eines erneuten Kompromisses der Systeme durch Eindringlinge.
Bei der Entwicklung von Maßnahmen empfehlen wir, dass der Koordinator die für bestimmte Systeme zuständigen Fachabteilungen, die Administratoren des Informationssicherheitssystems, die Forensikgruppe und den IS-Vorfallüberwachungsdienst konsultiert. Die endgültige Entscheidung über die Anwendung bestimmter Maßnahmen trifft der Koordinator der Vorfallanalysegruppe.
Wiederherstellung nach einem Vorfall
In diesem Abschnitt spricht NIST tatsächlich über die Aufgaben der IT-Abteilung und des Business Systems Operations Service. Alle Arbeiten beschränken sich auf die Wiederherstellung und Überprüfung der Leistung von IT-Systemen und Geschäftsprozessen des Unternehmens. Es ist nicht sinnvoll, auf diesen Punkt einzugehen, da die meisten Unternehmen mit der Lösung dieser Probleme konfrontiert sind, wenn auch nicht aufgrund von Informationssicherheitsvorfällen, dann zumindest nach Ausfällen, die selbst bei den stabilsten und fehlertolerantesten Systeminstallationen regelmäßig auftreten.
Methodische Tätigkeit
Der vierte Abschnitt der Incident Response-Methodik befasst sich mit der Behebung von Fehlern und der Verbesserung der Sicherheitstechnologien des Unternehmens.
Für die Erstellung eines Vorfallberichts, das Ausfüllen der Wissensdatenbank und der TI ist in der Regel das Forensikteam in Verbindung mit dem Überwachungsdienst verantwortlich. Wenn zu diesem Zeitpunkt keine Lokalisierungsstrategie für diesen Vorfall entwickelt wurde, ist deren Schreiben in diesem Block enthalten.
Nun, es ist offensichtlich, dass ein sehr wichtiger Punkt bei der Arbeit an Fehlern darin besteht, eine Strategie zu entwickeln, um ähnliche Vorfälle in Zukunft zu verhindern:
- Ändern der Architektur der IT-Infrastruktur und des vorhandenen GIS.
- Die Einführung neuer Tools für die Informationssicherheit.
- Einführung in den Prozess des Patch-Managements und der Überwachung von Informationssicherheitsvorfällen (falls nicht vorhanden).
- Korrektur von Geschäftsprozessen des Unternehmens.
- Zusätzliches Personal in der Abteilung für Informationssicherheit.
- Änderung der Autorität von Mitarbeitern der Informationssicherheit.
Rolle des Dienstanbieters
Somit kann die mögliche Teilnahme des Dienstanbieters an verschiedenen Phasen der Reaktion auf Vorfälle in Form einer Matrix dargestellt werden:
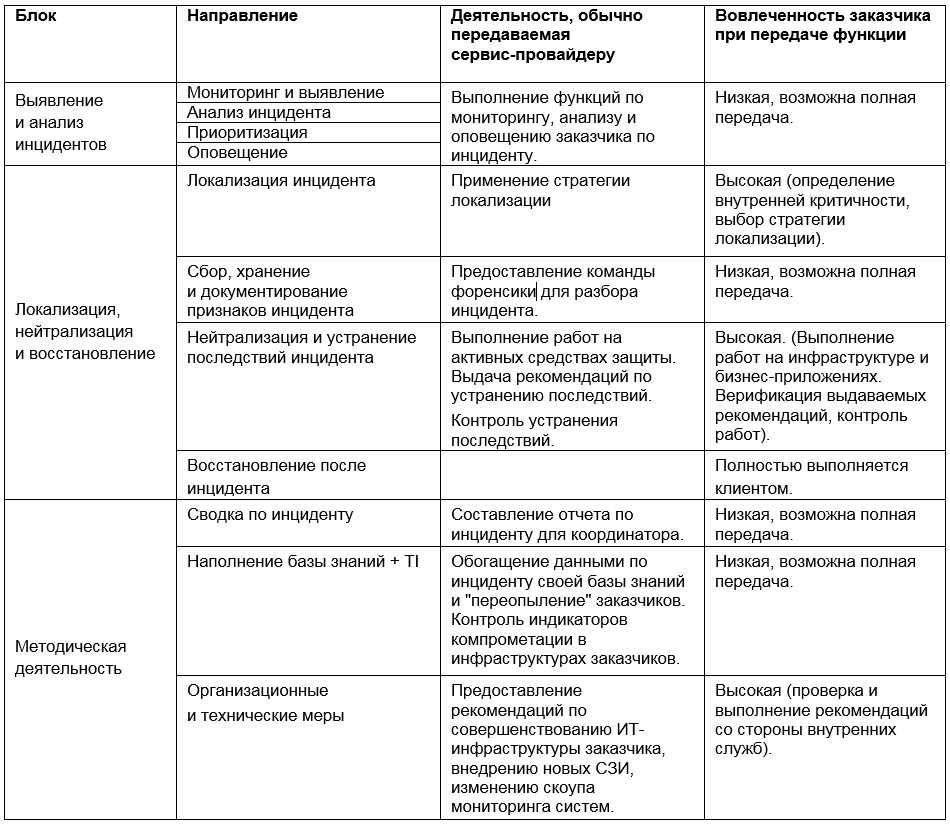
Die Auswahl von Tools und Ansätzen für das Incident Management ist eine der schwierigsten Aufgaben der Informationssicherheit. Die Versuchung, den Versprechen eines Dienstleisters zu vertrauen und ihm alle Funktionen zu geben, kann groß sein. Wir empfehlen jedoch eine fundierte Einschätzung der Situation und ein Gleichgewicht zwischen dem Einsatz interner und externer Ressourcen - im Interesse der Wirtschaftlichkeit und der Prozesseffizienz.