
Bist du bereit für neue Herausforderungen? Wir laden alle Amateure und Profis zur Meisterschaft ein, um hochgeladene Dienste zu entwerfen und zu verwalten.
HighLoad Cup # 2 !
Der Wettbewerb begann im letzten Jahr. Dann wussten wir, dass der HighLoad Cup genau die Meisterschaft ist, die in einer Reihe von Projekten der Mail.Ru Group fehlte. Der erste Pilotwettbewerb wurde von 449 Personen besucht. Sowohl von den Organisatoren als auch von den Teilnehmern gab es viel Code und viel Schweiß (8789 verschiedene Lösungen). Es gab Nuancen in der technischen Implementierung, aber am wichtigsten war, dass es allen gefallen hat! Die Organisatoren verbrachten viele Nächte im Rechenzentrum und mehrere freie Tage im Büro. Wieder bereit dafür! Am Ende des Artikels finden Sie nützliche Materialien von uns und den Teilnehmern, die Ihnen helfen, die Mechanik zu verstehen und einige Best-Practice-Lösungen zu finden.
Diesmal haben sie versucht, ein schwierigeres Geschäft für Sie vorzubereiten. Darüber hinaus haben wir das Publikum erweitert, jetzt können englischsprachige Benutzer am Wettbewerb teilnehmen. Treten Sie der russischsprachigen Community in
Telegram bei . Dort bekommst du viele Einblicke in die Konkurrenz :)
Willkommen an Bord!
Die Mechanik
Im Vergleich zum Vorjahr hat sich im Wettbewerb konzeptionell nichts geändert.
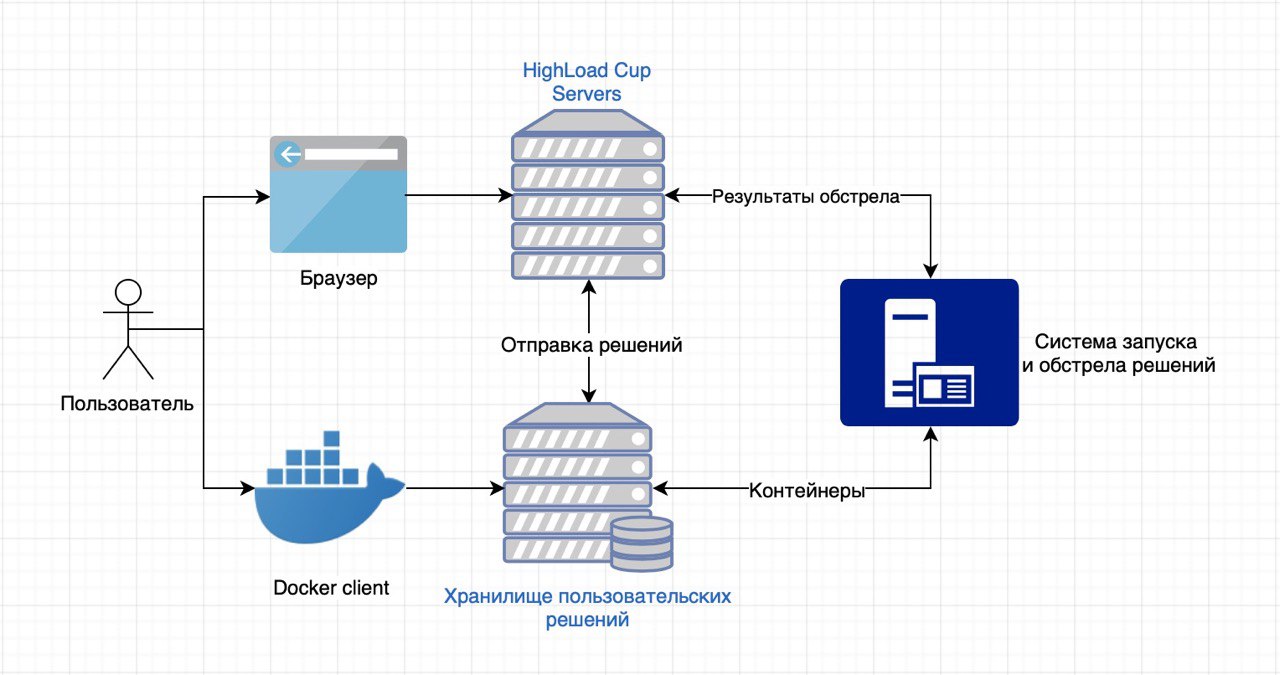
Die Teilnehmer haben die Aufgabe, einen kleinen Webdienst zu erstellen, der mit Daten einer bestimmten Struktur arbeitet und eine API für diese Daten implementiert. Ein Container (Docker) mit dem implementierten Dienst wird auf unsere Server hochgeladen, wo wir ihn starten und mit HTTP-Anforderungen schälen.
Lösungen werden uns über einen lokal installierten Docker-Client in einem speziellen Repository gesendet (jedes hat sein eigenes). Anschließend wird der an uns gesendete Service automatisch vom CodeHub-CodeRunner-System überprüft, das von den Mitarbeitern des Mail.Ru Group Technopark Laboratory entwickelt wurde.
Dann beginnen wir, den Container auf einer Testmaschine mit einem Intel Core i7-Prozessor zu „hämmern“. Der Lösung werden 4 Kerne mit 2,4 GHz, 2 GB RAM und 10 GB Festplattenspeicher zugewiesen. Kurz gesagt, mit der Phantom-Engine wird ein „Tank“ gestartet, der auf mehrere Ströme mit einem linear wachsenden Lastprofil feuert. Bevor mit dem Schälen begonnen wird, hat die Lösung des Benutzers einige Minuten Zeit (die genaue Menge hängt von der Aufgabe ab), um die Daten aus der empfangenen JSON-Datei zu verarbeiten. Die korrekte Arbeit mit diesen Daten ist eine notwendige Voraussetzung für den Sieg. Nur zwei, kurz und lang.
Basierend auf den Ergebnissen solcher Angriffe berechnen wir die Anzahl der richtigen und falschen Antworten, den RPS und die Antwortgeschwindigkeit und bilden eine Bewertungstabelle für eine bestimmte Metrik. Der Autor des schnellsten und fehlertolerantesten Dienstes wird der Gewinner sein.
Verwenden Sie jede Web-Technologie, die Sie finden oder entwickeln können. Wählen Sie Ihre eigene Programmiersprache und Ihr eigenes Framework. Es kann nach Ihrem Ermessen C ++, Java + Tomcat, Python + Django, Ruby + RoR, GoLang, JavaScript + NodeJs, Haskell, zumindest Assembler oder etwas anderes sein. Zur Datenspeicherung: MySQL, PostgreSQL, Redis, MongoDB, Caches. Völlige Freiheit!
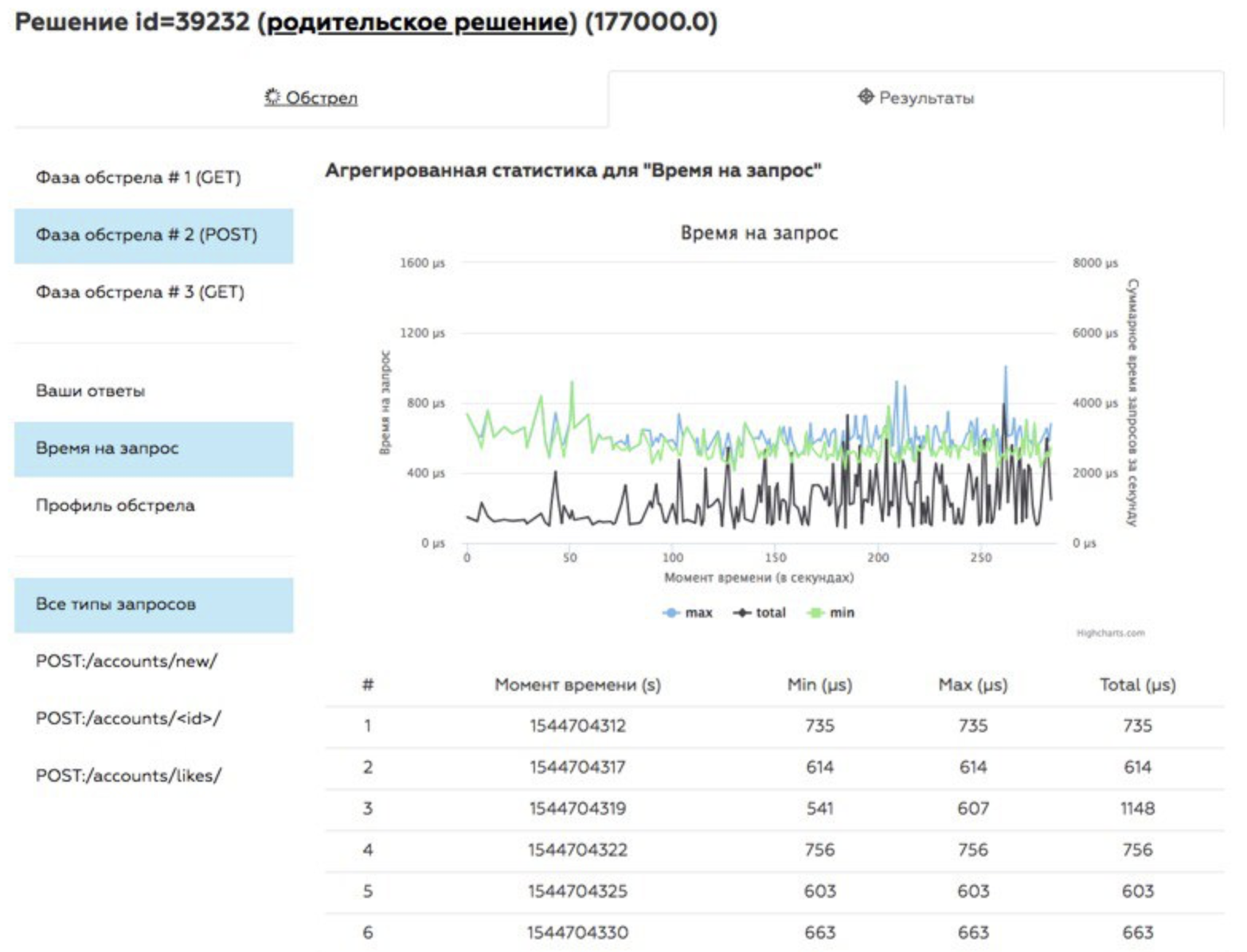
Durch das Schälen werden Protokolle und Metriken erhalten, die den Teilnehmern dann in Form von Diagrammen auf der Entscheidungsseite angezeigt werden. Getrennt verfolgt:
- grundlegende Metriken;
- richtige Antwort;
- Reaktionsgeschwindigkeit auf eine Anfrage;
- Anzahl der Antworten pro Sekunde.
Die Bewertung der Lösung wird wie folgt berechnet: Wir nehmen uns die Zeit aller richtigen Antworten, die die API während des Beschusses gegeben hat, und fügen eine Strafzeit für jede falsche Antwort oder Anfrage hinzu, für die wir keine Antwort erhalten konnten (die Strafzeit entspricht immer dem gesamten Zeitlimit für Anfragen). Der Teilnehmer, dessen Gesamtzeit kürzer ist als der anderer, ist höher in der Rangliste und hat die Chance, der Gewinner der Meisterschaft zu werden.
Herausforderung
Unser Team hat lange darüber nachgedacht, welche Aufgabe es in diesem Jahr geben soll. Sie wollten etwas, das die Chancen der Mehrheit ausgleicht (damit einige selbstgemachte Motorräder in C / C ++ nicht gewinnen).
Der Wortlaut lautet wie folgt:
In einer alternativen Realität beschloss die Menschheit, ein globales Suchsystem für die "zweite Hälfte" zu schaffen und zu starten. Es soll die Zahl der Einzelpersonen auf der Welt verringern und zur Schaffung starker Familien beitragen.
Sowohl in Test- als auch in Kampfdaten für verschiedene Beschussvorgänge gibt es Einträge zu einer Entität: Konto. Es beschreibt alle bekannten Informationen über den Benutzer - seinen Namen, Kontakte, Interessen, offenbartes Mitgefühl für andere Benutzer. Die Richtigkeit der bereitgestellten Daten wird gemäß den unten angegebenen Typen und Einschränkungen garantiert. Alle Daten wurden von uns nach bestimmten Gesetzen generiert und erfunden.
Die folgenden persönlichen Daten sind in einem Kontodatensatz enthalten:
- id - eindeutige externe Kennung des Benutzers. Es wird vom Testsystem installiert und dann zum Überprüfen der Serverantworten verwendet. Typ ist eine 32-Bit-Ganzzahl.
- email - die E-Mail-Adresse des Benutzers. Typ - Unicode-Zeichenfolge mit bis zu 100 Zeichen. Einzigartigkeit garantiert.
- fname und sname - Vor- bzw. Nachname. Typ - Unicode-Zeichenfolgen mit einer Länge von bis zu 50 Zeichen. Felder sind optional und möglicherweise nicht in einem bestimmten Datensatz vorhanden.
- Telefon - Handynummer. Typ ist eine Unicode-Zeichenfolge mit bis zu 16 Zeichen. Das Feld ist optional, die Eindeutigkeit für die angegebenen Werte ist jedoch garantiert. Es ist ziemlich selten gefüllt.
- Sex ist eine Unicode-Zeichenfolge, "m" bedeutet männlich und "f" bedeutet weiblich.
- Geburtsdatum - Geburtsdatum, aufgezeichnet als die Anzahl der Sekunden ab dem Beginn der UNIX-Ära in UTC (mit anderen Worten, dies ist ein Zeitstempel). Begrenzt von unten 01.01.1950, von oben 01.01.2005.
- Land - Land des Wohnsitzes. Typ ist eine Unicode-Zeichenfolge mit einer Länge von bis zu 50 Zeichen. Das Feld ist optional.
- Stadt - Wohnort. Typ ist eine Unicode-Zeichenfolge mit einer Länge von bis zu 50 Zeichen. Das Feld ist optional und wird selten angegeben. Jede Stadt befindet sich in einem bestimmten Land.
In einem Kontodatensatz gibt es außerdem sucherspezifische Felder für die zweite Hälfte:
- Beitritt - Datum der Registrierung im System. Typ - Zeitstempel mit Einschränkungen: von unter 01.01.2011, von über 01.01.2018.
- status - Der aktuelle Status des Benutzers im System. Geben Sie eine Zeile der folgenden Optionen ein: "frei", "beschäftigt", "alles ist kompliziert". Achte nicht auf seltsame Enden :)
- Interessen - Interessen des Benutzers im Alltag. Typ - Ein Array von Unicode-Zeichenfolgen, möglicherweise leer. Zeilen dürfen nicht länger als 100 Zeichen sein.
- Premium - Beginn und Ende des Premium-Zeitraums im System (wenn Benutzer wirklich einen „Seelenverwandten“ finden wollten und für den Service bezahlt haben). In JSON wird dieses Feld durch ein verschachteltes Objekt mit den Start- und Zielfeldern dargestellt, in dem Zeitstempel mit einer unteren Grenze am 01/01/2018 aufgezeichnet werden.
- Likes - Ein Array der bekannten Likes des Benutzers, möglicherweise leer. Alle Sympathien gehen unterschiedlich und jedes repräsentiert ein Objekt aus den folgenden Feldern:
- id - die Kennung eines anderen Kontos, das dem Benutzer gefällt. Das Konto kann immer in den Quelldaten nach ID gefunden werden. Bitte beachten Sie, dass die Daten möglicherweise mehrere Likes mit derselben ID enthalten.
- ts - Zeit, d. h. Zeitstempel, wenn die Sympathie im System aufgezeichnet wurde.
Sie müssen die API implementieren.
- Eine Liste der Benutzer abrufen: / accounts / filter /
Diese API-Methode soll zur Suche nach Benutzern in zuvor bekannten oder gewünschten Feldern verwendet werden. Zum Beispiel wollte jemand alle Menschen eines bestimmten Alters und Geschlechts in einer bestimmten Stadt leben sehen. - Benutzer gruppieren : / accounts / group /
Diese API-Methode soll zum Erstellen von Berichten über den Betrieb des Systems verwendet werden. Die zur Gruppierung verwendeten Felder werden in den durch Kommas getrennten GET-Parameterschlüsseln übergeben. Sie sind nicht so zahlreich wie in der Benutzerfilteranforderung. Es gibt nur fünf Felder für die Gruppierung - Geschlecht, Status, Interessen, Land, Stadt. - Kompatibilitätsempfehlungen: / accounts / id / empfehle /
Diese Abfrage wird verwendet, um in den angegebenen Benutzerdaten nach der "zweiten Hälfte" zu suchen. Die Anfrage übergibt die ID des Benutzers, für den diejenigen gesucht werden, die nach Status, Alter und Interessen am besten geeignet sind. Die Entscheidung sollte die Kompatibilität nur mit dem anderen Geschlecht überprüfen (wir sind nicht gegen sexuelle Minderheiten und verurteilen Diskriminierung, es ist einfach passiert :)). Wenn das Land oder die Stadt mit den Land- bzw. Stadtschlüsseln in der GET-Anforderung übertragen wird, müssen Sie nur unter denen suchen, die am angegebenen Ort leben. - Übereinstimmende ähnliche Likes: / accounts / id / suggest /
Diese Art der Abfrage ähnelt der vorherigen insofern, als es auch um die Suche nach "Seelenverwandten" geht. Die ID des Benutzers, für den wir einen Seelenverwandten suchen, wird ebenfalls gesendet. Der Parameter limit GET wird verwendet. Unterschiede in der Umsetzung: Wir suchen Menschen wie das gleiche Geschlecht mit ähnlichen „Likes“ und bieten diejenigen an, die sie kürzlich selbst mochten. Wenn die Anfrage den GET-Parameter des Landes oder der Stadt erhält, müssen Sie nur an einem bestimmten Ort nach „ähnlichen Sympathien“ suchen.
Es ist nicht möglich, alles in einem Artikel zu erzählen. Detaillierte Regeln werden am Starttag (heute) auf der Meisterschaftswebsite und im
GitHub- Repository veröffentlicht, aber jetzt wissen Sie, was Sie erwartet.
Zeitplan
Ja, wir wissen, dass die Feiertage (mit den kommenden), also wird die Meisterschaft sehr lang sein :)
- Beta-Test (Ergebnisse werden nicht berücksichtigt): Beginn am 13. Dezember um 19:00 Uhr, Ende am 21. Dezember um 19:00 Uhr.
- Qualifikationsrunde: vom 21. Dezember 19:00 bis 31. Januar 19:00.
- Endrunde: bis 5. Februar.
Während des Betatests können sich die Regeln und Bedingungen der Aufgabe ändern (bei Vorhandensein von Fehlern und aus anderen Gründen).
Qualifikationsrunde - die Regeln ändern sich nicht.
Die Endrunde ist vollautomatisch, aber vorher wählen die Finalisten (N Benutzer, die die Ergebnisse der Qualifikationsrunde bestanden haben und mindestens 50 Personen) eine Lösung, auf die in mehreren Wellen geschossen wird. Das Ergebnis ergibt sich aus dem besten Ergebnis für alle Wellen.
Geschenke
Erster Platz ist das brandneue MacBook Air.
Zweiter und dritter Platz - Apple iPad.
Vierter, fünfter und sechster Platz - Samsung Gear S3.
Der Teilnehmer hat das Recht, im Gegenzug ein weiteres Geschenk von gleichem Wert anzufordern. Alle Teilnehmer, die sich für das Finale qualifiziert haben, erhalten Marken-T-Shirts unserer Meisterschaft.
Gemeinschaft
Wenn Sie in unseren
Telegramm- Chatroom gehen, ist es unwahrscheinlich, dass Sie ihn bereits verlassen. Wir warten auf Sie und viel Glück!
Danksagung
Dieser Artikel behandelt keine Systemaktualisierungsprobleme. Wir haben viel Arbeit geleistet, um Infrastrukturfehler zu beseitigen, alle
Probleme der Teilnehmer auf GitHub überprüft, bereits etwas implementiert und es in die TODO-Liste für das nächste Jahr aufgenommen. Ich möchte Maxim
@ xammi- Kislenko, Ilya
@liofz Lebedev, Eugene
@gunicorn Ivanov, Irina
@aithelle Lukyanova , Vasily
@vasidmi Dmitriev und dem gesamten Team, das an dem Wettbewerb teilgenommen hat, einschließlich der gesamten Meisterschaftsgemeinschaft, meinen
tiefen Dank
aussprechen . Vielen Dank!
Nützliche Literatur zu den Ergebnissen des HighLoad Cup 2017