Herausforderung
Eine der großen Aufgaben der Anwendung zum Speichern und Analysieren von Einkäufen besteht darin, in der Datenbank nach identischen oder sehr engen Produkten zu suchen, die verschiedene und unverständliche Produktnamen enthalten, die aus Belegen stammen. Es gibt zwei Arten von Eingabeanforderungen:
- Ein bestimmter Name mit Abkürzungen, der nur von Kassierern in einem örtlichen Supermarkt oder begeisterten Käufern verstanden werden kann.
- Eine vom Benutzer in die Suchzeichenfolge eingegebene Abfrage in natürlicher Sprache.
Anfragen der ersten Art kommen in der Regel von den Produkten im Scheck selbst, wenn der Benutzer günstigere Produkte finden muss. Unsere Aufgabe ist es, das ähnlichste Produktanalogon aus dem Scheck in anderen Geschäften in der Nähe auszuwählen. Es ist wichtig, die am besten geeignete Produktmarke und, wenn möglich, das Volumen auszuwählen.
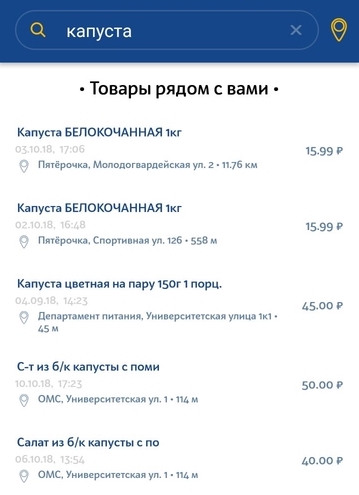
Die zweite Art der Anfrage ist eine einfache Benutzeranfrage zur Suche nach einem bestimmten Produkt im nächstgelegenen Geschäft. Die Anfrage kann eine sehr allgemeine, nicht eindeutige Beschreibung des Produkts sein. Es kann geringfügige Abweichungen von der Anfrage geben. Wenn ein Benutzer beispielsweise nach Milch 3,2% und in unserer Datenbank nur 2,5% Milch sucht, möchten wir immer noch mindestens dieses Ergebnis anzeigen.
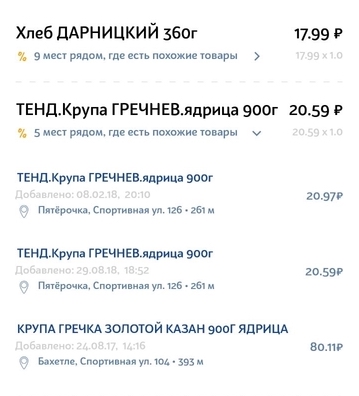
Features Datensatz - Probleme zu lösen
Die Informationen auf dem Produktbeleg sind alles andere als ideal. Es enthält viele nicht immer eindeutige Abkürzungen, Grammatikfehler, Tippfehler, verschiedene Übersetzungen, lateinische Buchstaben in der Mitte des kyrillischen Alphabets und Zeichensätze, die nur für die interne Organisation in einem bestimmten Geschäft sinnvoll sind.
Zum Beispiel kann ein Baby-Apfel-Bananen-Püree mit Hüttenkäse leicht wie folgt auf den Scheck geschrieben werden:

Über Technologie
Elasticsearch ist eine ziemlich beliebte und erschwingliche Technologie zur Implementierung der Suche. Dies ist eine JSON REST API-Suchmaschine, die Lucene verwendet und in Java geschrieben ist. Die Hauptvorteile von Elastic sind Geschwindigkeit, Skalierbarkeit und Fehlertoleranz. Ähnliche Engines werden für komplexe Suchvorgänge in der Datenbank von Dokumenten verwendet. Zum Beispiel eine Suche unter Berücksichtigung der Morphologie der Sprache oder eine Suche nach Geokoordinaten.
Anweisungen zum Experimentieren und Verbessern
Um zu verstehen, wie Sie Ihre Suche verbessern können, müssen Sie das Suchsystem in seine benutzerdefinierten Komponentenkomponenten zerlegen. In unserem Fall sieht die Struktur des Systems so aus.
- Die Eingabezeichenfolge für die Suche durchläuft den Analysator, der die Zeichenfolge auf bestimmte Weise in Token aufteilt - Sucheinheiten, die unter den Daten suchen, die auch als Token gespeichert sind.
- Anschließend wird für jedes Dokument in der vorhandenen Datenbank direkt nach diesen Token gesucht. Nachdem ein Token in einem bestimmten Dokument gefunden wurde (das auch in der Datenbank als Satz von Token dargestellt wird), wird seine Relevanz anhand des ausgewählten Ähnlichkeitsmodells berechnet (wir nennen es das Relevanzmodell). Dies kann ein einfaches TF / IDF (Term Frequency - Inverse Document Frequency) sein, oder es können andere komplexere oder spezifischere Modelle sein.
- In der nächsten Phase wird die Anzahl der von jedem einzelnen Token erzielten Punkte auf eine bestimmte Weise aggregiert. Aggregationsparameter werden durch Abfragesemantik festgelegt. Ein Beispiel für solche Aggregationen können zusätzliche Gewichte für bestimmte Token (Mehrwert), Bedingungen für das obligatorische Vorhandensein eines Tokens usw. sein. Das Ergebnis dieser Phase ist Punktzahl - die endgültige Bewertung der Relevanz eines bestimmten Dokuments aus der Datenbank in Bezug auf die ursprüngliche Anforderung.

Vom Suchgerät können drei separat konfigurierbare Komponenten unterschieden werden, in denen Sie jeweils Ihre eigenen Verbesserungsmöglichkeiten und -methoden hervorheben können.
- Analysatoren
- Ähnlichkeitsmodell
- Verbesserungen der Abfragezeit
Als nächstes werden wir jede Komponente einzeln betrachten und spezifische Parametereinstellungen analysieren, die dazu beigetragen haben, die Suche bei Produktnamen zu verbessern.
Verbesserungen der Abfragezeit
Um zu verstehen, was wir an der Anfrage verbessern können, geben wir ein Beispiel für die ursprüngliche Anfrage.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
Wir verwenden den Abfragetyp most_fields, da für das Feld "Produktname" eine Kombination mehrerer Analysatoren erforderlich ist. Mit dieser Art von Abfrage können Sie Suchergebnisse für verschiedene Attribute des Objekts kombinieren, die denselben Text enthalten und auf unterschiedliche Weise analysiert werden. Eine Alternative zu diesem Ansatz besteht darin, die Abfragen best_fields oder cross_fields zu verwenden, die jedoch für unseren Fall nicht geeignet sind, da die Suche unter den verschiedenen Attributen des Objekts berechnet wird (z. B. Name und Beschreibung). Wir stehen vor der Aufgabe, verschiedene Aspekte eines Attributs zu berücksichtigen - den Namen des Produkts.
Was kann konfiguriert werden:
- Gewichtete Kombination verschiedener Analysegeräte.
Anfangs haben alle Suchelemente das gleiche Gewicht - und damit die gleiche Bedeutung. Dies kann durch Hinzufügen des Parameters 'boost' geändert werden, der numerische Werte annimmt. Wenn der Parameter größer als 1 ist, hat das Suchelement einen größeren Einfluss auf die Ergebnisse bzw. weniger als 1 - weniger. - Trennung der Analysatoren in "sollte" und "muss".
Bestimmte Analysatoren müssen nämlich zusammenfallen, und einige sind optional, dh unzureichend. In unserem Fall kann der Zahlenanalysator ein Beispiel für die Vorteile einer solchen Trennung sein. Wenn nur die Nummer im Produktnamen in der Anfrage und der Produktname in der Datenbank übereinstimmen, ist dies keine ausreichende Bedingung für ihre Äquivalenz. Wir wollen solche Produkte nicht als Ergebnis sehen. Wenn die Anfrage "Creme 10%" lautet, möchten wir gleichzeitig, dass alle Cremes mit 10% Fett einen großen Vorteil gegenüber Cremes mit 20% Fett haben. - Der Parameter minimum_should_match. Wie viele Token müssen unbedingt in der Anforderung und dem Dokument aus der Datenbank übereinstimmen? Dieser Parameter arbeitet mit dem Typ unserer Anforderung (most_fields) zusammen und überprüft die Mindestanzahl übereinstimmender Token für jedes der Felder (in unserem Fall für jeden Analysator).
- Parameter Min_score. Schwellenwert-Screening-Dokumente mit unzureichenden Punkten. Der Haken ist, dass keine Höchstgeschwindigkeit bekannt ist. Die resultierende Punktzahl hängt von einer bestimmten Anforderung und einer bestimmten Datenbank von Dokumenten ab. Manchmal kann es 150 und manchmal 2 sein, aber diese beiden Werte bedeuten, dass das Objekt aus der Datenbank für die Anforderung relevant ist. Wir können die Ergebnisse der Ergebnisse verschiedener Abfragen nicht vergleichen.
- Konstante
Nach einer ausreichenden Überwachung der Endwerte der Geschwindigkeit für verschiedene Abfragen können Sie einen ungefähren Rand identifizieren. Danach werden die Ergebnisse für die meisten Abfragen unangemessen. Dies ist die einfachste, aber auch die dümmste Entscheidung, die zu einer Suche von schlechter Qualität führt. - Versuchen Sie, die für eine bestimmte Anforderung erhaltenen Bewertungen zu analysieren, nachdem Sie eine Suche mit minimalem oder null min_score durchgeführt haben.
Die Idee ist, dass Sie nach einem bestimmten Moment einen scharfen Sprung in Richtung abnehmender Geschwindigkeit beobachten können. Es bleibt nur, diesen Sprung zu bestimmen, um rechtzeitig anzuhalten. Ein solcher Ansatz würde bei ähnlichen Abfragen gut funktionieren:
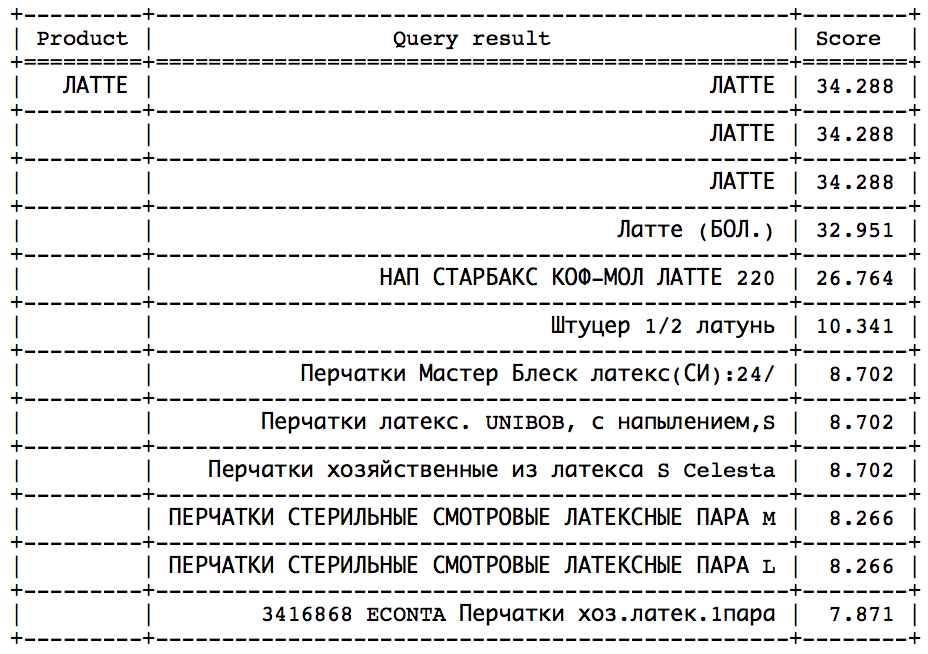
Der Sprung kann durch statistische Methoden gefunden werden. Leider ist dieser Sprung nicht in allen Anfragen vorhanden und leicht zu identifizieren. - Berechnen Sie die ideale Geschwindigkeit und setzen Sie min_score als einen bestimmten Bruchteil des Ideals. Dies kann auf zwei Arten erfolgen:
- Aus der detaillierten Beschreibung der Berechnungen, die Elastic selbst beim Einstellen des Parameters EXPLAIN: True bereitgestellt hat. Dies ist eine schwierige Aufgabe, die ein gründliches Verständnis der von Elastic verwendeten Abfragearchitektur und Berechnungsalgorithmen erfordert.
- Mit einem kleinen Trick. Wir erhalten eine Anfrage, fügen unserer Datenbank ein neues Produkt mit demselben Namen hinzu, führen eine Suche durch und erhalten die maximale Geschwindigkeit. Da der Name zu 100% übereinstimmt, ist der resultierende Wert ideal. Diesen Ansatz verwenden wir in unserem System, da Bedenken hinsichtlich der hohen Kosten dieser Operation in Bezug auf die Zeit nicht bestätigt wurden.
- Ändern Sie den Bewertungsalgorithmus, der für den endgültigen Relevanzwert verantwortlich ist. Dies kann die Entfernung zum Geschäft (geben Sie mehr Punkte für Produkte, die näher sind), Produktpreise (geben Sie mehr Punkte für Produkte mit dem wahrscheinlichsten Preis) usw. berücksichtigen.
Analysatoren
Der Analysator analysiert die Eingabezeichenfolge in drei Stufen und gibt Token an den Ausgabe-Sucheinheiten aus:

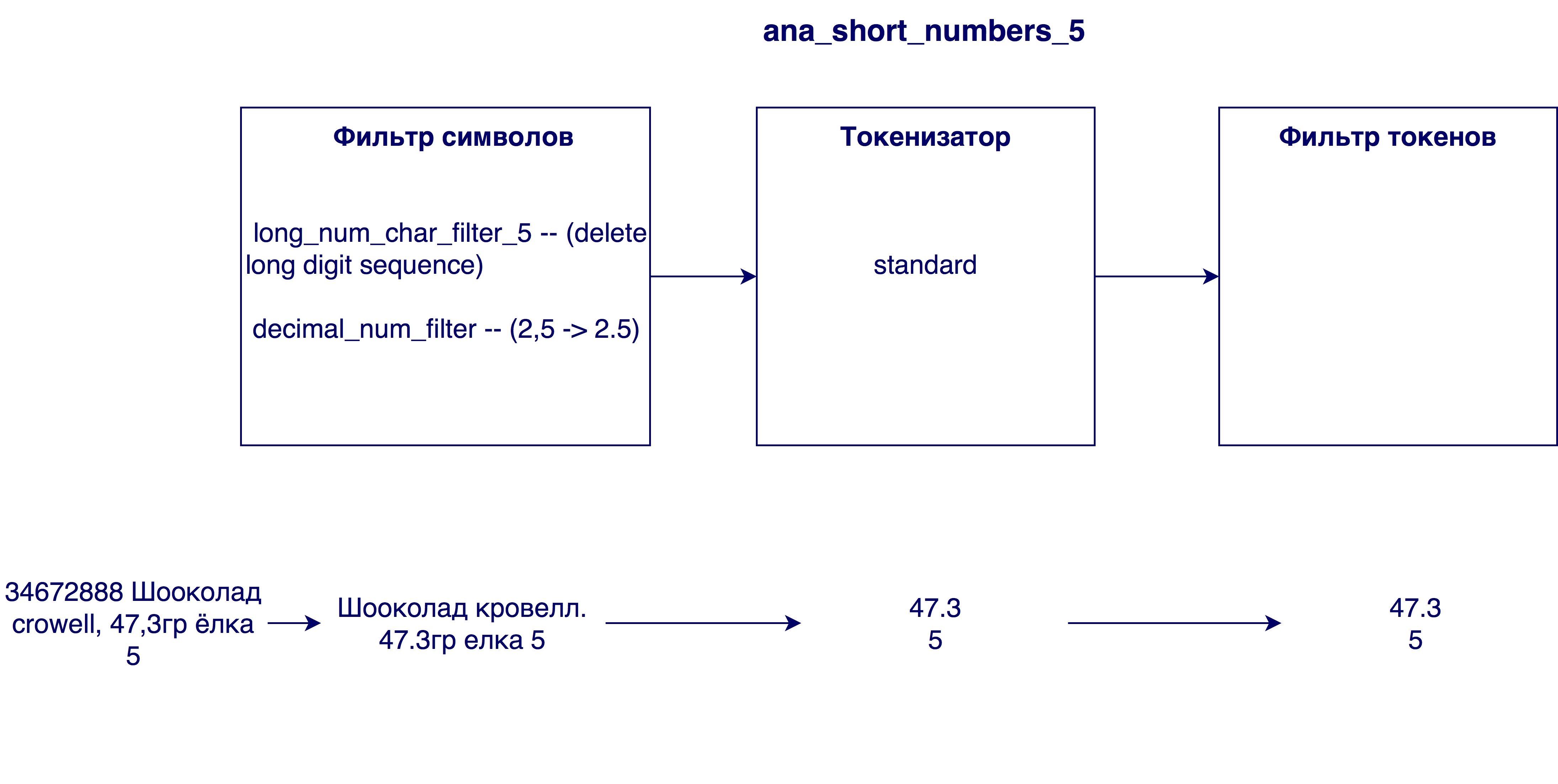
Erstens treten Änderungen auf Zeichenebene der Zeichenfolge auf. Dies kann das Ersetzen, Löschen oder Hinzufügen von Zeichen zu einer Zeichenfolge sein. Dann kommt ein Tokenizer ins Spiel, der die Zeichenfolge in Token aufteilen soll. Der Standard-Tokenizer teilt die Zeichenfolge gemäß Satzzeichen in Token auf. Im letzten Schritt werden die empfangenen Token gefiltert und verarbeitet.
Überlegen Sie, welche Variationen der Schritte in unserem Fall nützlich geworden sind.
Char Filter
- Gemäß den Besonderheiten der russischen Sprache wäre es nützlich, Zeichen wie th und e zu verarbeiten und durch und bzw. e zu ersetzen.
- Transliteration durchführen - die Übertragung von Zeichen einer Schrift durch Zeichen einer anderen Schrift. In unserem Fall ist dies die Verarbeitung von Namen, die in lateinischer Sprache geschrieben oder mit beiden Alphabeten gemischt sind. Die Transliteration kann mithilfe des Plug- Ins ( ICU Analysis Plugin ) als Filter für Token implementiert werden ( dh es wird nicht die ursprüngliche Zeichenfolge, sondern die endgültigen Token verarbeitet). Wir haben uns entschlossen, unsere Transliteration zu schreiben, da wir mit dem Algorithmus im Plugin nicht ganz zufrieden waren. Die Idee ist, zuerst die Vorkommen mit vier Zeichensätzen (z. B. „SHCH => u“), dann die Vorkommen mit drei Zeichen usw. zu ersetzen. Die Reihenfolge, in der Symbolfilter verwendet werden, ist wichtig, da das Ergebnis von der Reihenfolge abhängt.
- Ersetzen Sie Latein c, umgeben von Kyrillisch, durch Russisch p. Die Notwendigkeit hierfür wurde nach Analyse der Namen in der Datenbank festgestellt - sehr viele Namen in kyrillischer Sprache enthielten lateinisches c, was kyrillisch c bedeutet. Wenn der Name vollständig lateinisch ist, bedeutet lateinisch C kyrillisch k oder c. Daher muss vor der Transliteration das Zeichen c ersetzt werden.
- Entfernen zu großer Zahlen aus Namen. Manchmal gibt es in den Produktnamen eine interne Identifikationsnummer (z. B. 3387522 K.Ts. Maslo podsoln.raf. 0.9l), die im allgemeinen Fall keine Bedeutung hat.
- Kommas durch Punkte ersetzen. Warum wird das benötigt? Damit sind die Ziffern, zum Beispiel der Fettgehalt von Milch 3.2 und 3.2, gleichwertig
Tokenizer
- Standard-Tokenizer - Trennt Zeilen nach Leerzeichen und Satzzeichen (z. B. "Twix Extra 2" -> "Twix", "Extra", "2").
- EdgeNGram-Tokenizer - teilt jedes Wort in Token einer bestimmten Länge (normalerweise einen Zahlenbereich) auf, beginnend mit dem ersten Zeichen (z. B. für N = [3, 6]: "twix extra 2" -> "twee", "tweak", "Twix", "ex", "ext", "ext", "extra")
- Tokenizer für Zahlen - Wählt nur Zahlen aus einer Zeichenfolge aus, indem nach einem regulären Ausdruck gesucht wird (z. B. "twix extra 2 4.5" -> "2", "4.5").
Token-Filter
- Kleinbuchstabenfilter
- Stamming-Filter - führt für jedes Token einen Stamming-Algorithmus durch. Beim Stemming wird die Anfangsform eines Wortes bestimmt (z. B. "Reis" -> "Reis").
- Phonetische Analyse. Dies ist erforderlich, um den Einfluss von Tippfehlern und unterschiedlichen Schreibweisen desselben Wortes auf die Suchergebnisse zu minimieren. Die Tabelle zeigt die verschiedenen verfügbaren Algorithmen für die phonetische Analyse und das Ergebnis ihrer Arbeit in problematischen Fällen. Im ersten Fall (Shampoo / Champagner / Champignon / Champignon) wird der Erfolg durch die Erzeugung verschiedener Codierungen bestimmt, im Übrigen - gleich.

Ähnlichkeitsmodell
Das Relevanzmodell wird benötigt, um zu bestimmen, inwieweit die Übereinstimmung eines Tokens die Relevanz des Objekts aus der Datenbank in Bezug auf die Anforderung beeinflusst. Angenommen, das Token in der Anfrage und das Produkt aus der Datenbank stimmen überein - dies ist sicherlich nicht schlecht, sagt aber wenig über die Konformität des Produkts mit der Anfrage aus. Somit trägt das Zusammentreffen verschiedener Token unterschiedliche Werte. Um dies zu berücksichtigen, wird ein Relevanzmodell benötigt. Elastic bietet viele verschiedene Modelle. Wenn Sie sie wirklich verstehen, können Sie ein sehr spezifisches und geeignetes Modell für einen bestimmten Fall auswählen. Die Auswahl kann auf der Anzahl der häufig verwendeten Wörter (wie das gleiche Token für), einer Bewertung der Wichtigkeit langer Token (länger bedeutet besser? Schlimmer? Egal?), Welche Ergebnisse möchten wir am Ende sehen usw. basieren? Beispiele für Modelle, die in Elastic vorgeschlagen werden, können TF-IDF (das einfachste und verständlichste Modell), Okapi BM25 (erweitertes TF-IDF, das Standardmodell), Abweichung von der Zufälligkeit, Abweichung von der Unabhängigkeit usw. sein. Jedes Modell verfügt auch über anpassbare Optionen. Nach mehreren Experimenten mit dem Modell zeigte das Okapi BM25-Standardmodell das beste Ergebnis, jedoch mit anderen als den vordefinierten Parametern.
Kategorien verwenden
Im Verlauf der Suche wurden sehr wichtige Zusatzinformationen zum Produkt - seiner Kategorie - verfügbar. Weitere Informationen zur Implementierung der Kategorisierung finden Sie im Artikel. Soweit ich weiß, esse ich viele Süßigkeiten oder die Klassifizierung von Waren durch Einchecken in der Anwendung . Bis dahin haben wir unsere Suche nur auf einen Vergleich von Produktnamen gestützt, jetzt ist es möglich geworden, die Kategorie der Anfragen und Produkte in der Datenbank zu vergleichen.
Mögliche Optionen für die Verwendung dieser Informationen sind eine obligatorische Übereinstimmung im Kategoriefeld (formatiert als Ergebnisfilter), ein zusätzlicher Vorteil in Form von Punkten für Waren mit derselben Kategorie (wie bei Zahlen) und die Sortierung der Ergebnisse nach Kategorien (zuerst Übereinstimmung, dann alle anderen). In unserem Fall hat die letzte Option am besten funktioniert. Dies liegt daran, dass unser Kategorisierungsalgorithmus zu gut ist, um die zweite Methode zu verwenden, und nicht gut genug, um die erste zu verwenden. Wir sind zuversichtlich genug in den Algorithmus und möchten, dass die Kategorieübereinstimmung ein großer Vorteil ist. Wenn Sie der Geschwindigkeit zusätzliche Punkte hinzufügen (zweite Methode), werden Waren mit derselben Kategorie in die Liste aufgenommen, verlieren jedoch immer noch gegen einige Waren, die namentlich besser übereinstimmen. Die erste Methode passt jedoch auch nicht zu uns, da noch Fehler bei der Kategorisierung möglich sind. Manchmal enthält die Anforderung nicht genügend Informationen, um die Kategorie korrekt zu bestimmen, oder es befinden sich zu wenige Produkte in dieser Kategorie im unmittelbaren Umkreis des Benutzers. In diesem Fall möchten wir weiterhin Ergebnisse mit einer anderen Kategorie anzeigen, die jedoch nach Produktnamen relevant sind.
Die zweite Methode ist ebenfalls gut, da sie die Geschwindigkeit der Produkte infolge der Suche nicht „beeinträchtigt“ und es Ihnen ermöglicht, die berechnete Mindestgeschwindigkeit ohne Hindernisse weiter zu verwenden.
Die spezifische Implementierung der Sortierung ist in der endgültigen Abfrage zu sehen.
Endmodell
Die Auswahl des endgültigen Suchmodells umfasste die Generierung verschiedener Suchmaschinen, deren Bewertung und Vergleich. Am häufigsten basierte der Vergleich auf einem der Parameter. Angenommen, wir müssten in einem bestimmten Fall die beste Größe für den EdgeNgram-Tokenizer berechnen (dh den effektivsten Bereich von N auswählen). Zu diesem Zweck haben wir dieselben Suchmaschinen mit nur einem Unterschied in der Größe dieses Bereichs generiert. Danach konnte der beste Wert für diesen Parameter ermittelt werden.
Die Modelle wurden unter Verwendung der nDCG-Metrik (normalisierter diskontierter kumulativer Gewinn) bewertet, einer Metrik zur Bewertung der Rankingqualität. Vordefinierte Abfragen wurden an jedes Suchmodell gesendet, wonach die nDCG-Metrik basierend auf den empfangenen Suchergebnissen berechnet wurde.
Analysatoren, die das endgültige Modell eingegeben haben:



Als Relevanzmodell wurde das Standardmodell (Okapi - BM25) mit dem Parameter b = 0,5 gewählt. Der Standardwert ist 0,75. Dieser Parameter zeigt, inwieweit die Länge des Produktnamens die Variable tf (Termhäufigkeit) normalisiert. Eine kleinere Zahl funktioniert in unserem Fall besser, da ein langer Name sehr oft die Bedeutung eines einzelnen Wortes nicht beeinflusst. Das heißt, das Wort „Schokolade“ im Namen „Schokolade mit zerkleinerten Haselnüssen in einer Packung mit 25 Stück“ verliert nicht an Wert, da der Name lang genug ist.
Die letzte Abfrage sieht folgendermaßen aus:
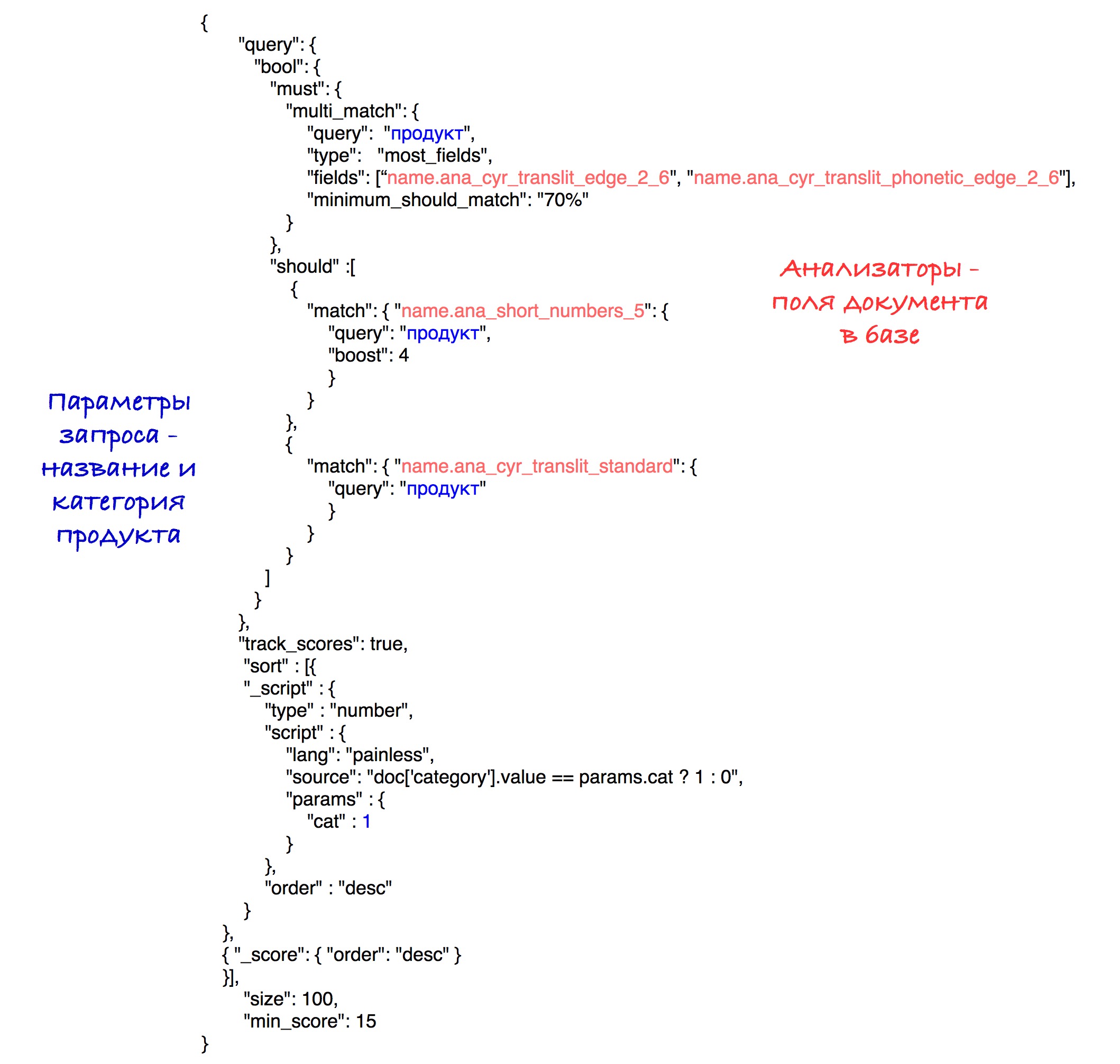
Experimentell wurde die beste Kombination von Analysatoren und Gewichten gefunden.
Als Ergebnis der Sortierung gehen Produkte mit derselben Kategorie an den Anfang der Ergebnisse und dann an alle anderen. Die Sortierung nach der Anzahl der Punkte (Geschwindigkeit) wird in jeder Teilmenge gespeichert.
Der Einfachheit halber wird der Schwellenwert für die Geschwindigkeit in dieser Anforderung auf 15 gesetzt, obwohl wir in unserem System den zuvor beschriebenen berechneten Parameter verwenden.
In der Zukunft
Es gibt Überlegungen, die Suche zu verbessern, indem eines der peinlichsten Probleme in unserem Algorithmus gelöst wird, nämlich die Existenz einer Million und eine andere Möglichkeit, ein Wort mit 5 Buchstaben zu verkürzen. Es kann durch die anfängliche Verarbeitung von Namen gelöst werden, um Abkürzungen aufzudecken. Eine Möglichkeit, dies zu lösen, besteht darin, zu versuchen, den abgekürzten Namen aus unserer Datenbank mit einem der Namen aus der Datenbank mit den „richtigen“ vollständigen Namen zu vergleichen. Diese Entscheidung stößt auf ihre endgültigen Hindernisse, scheint jedoch eine vielversprechende Änderung zu sein.